

OData(02) - Irony构建OData文法,悲剧的Babelua
OData(02) - Irony构建OData文法,悲剧的Babelua
之前提到要实现OData协议,如果你之前没了解过OData那么也想不到在URL这有限的字符串中会有如此复杂的一个协议,复杂到用一般的解析手段根本不可能完成分析工作。
OData协议简单介绍
OData协议官方网址如下所示:
http://www.odata.org/
OData协议主要分为下面几个部分:
- 协议正文:主要定义了HTTP通讯中请求和响应的格式、数据模型及元数据模型。
- URL约定:请求时的URL格式,主要定义了各种查询的URL格式,这个约定还有一个补充协议主要是针对数据聚合查询。
- 数据往返格式:主要就是XML和JSON这两种
主要就是上面这些,然而最为复杂的是第二部分,URL约定还有专门的ABNF定义,主体的定义就有1000多行了,所以想要成功的完整分析OData的URL就需要一个小型的编译过程才行,实现编译过程第一步就是进行词法分析、语法分析这些工作,包含微软官方的OData实现也是这么干的,有兴趣朋友可以去阅读官方代码,在NET中能实现这个功能的框架我选是Irony这个框架,对于我而言选它是有历史原因。
国产免费项目的悲剧【Babelua】
Babelua是一个用于编辑、调试Lua脚本的Visual Stuido扩展,支持VS2013到VS2015现在还能下载到https://marketplace.visualstudio.com/items?itemName=babestudio.BabeLua,在2015年的时候也算比较出名了,这个插件一共有三名作者,开始由另一个同事写的初版,然后我接手后和另一个C++高手重写了整个项目,我主要开发语言服务编辑功能像自动补全,代码格式化等VS实现部分,而他主要是对接调试器。这里还需要提到的是这个项目的组织者也就是我们当时的上司,由于这个完全免费的原因还有在当时具有完备编辑调试Lua代码的工具本来就比较少,所以也很快在国内外出现不少用户,这算是成绩吧,不过在我接手后这个项目没有真正公开源代码,所以也不能算开源项目。
当时Python语言在VS中还是以扩展形式安装,而且Babelua也是模仿Python for Visual Studio这个插件开发,我其实是想把Babelua的功能提升到Python扩展这个水平。很可惜这个项目是一个公司行为,由于没有任何实质的产出,估计我上司也承受了很大的公司压力,不能投入资源去做这件事情,最终也随着我和那位C++大神的离开,Babelua停止了开发维护工作最终而不了了之,到现在已有3年了吧。
今天再回头看只能感慨,太可惜了本来一个很好的项目就这么结束了。
Irony实现文法
Irony这个框架是我在Babelua中用于分析Lua源代码,我们也用过10W+行的项目去长期测试过这个框架的性能及稳定性都是非常好的,不过这方面资料太少了,大多数文章都是在说编译原理的一些概念,能结合实际说明的文章简直就像大熊猫难找。这里就结合Irony框架来实际说明一下文法构建。下文中提到的编译概念就不一一说明了,相信有很多文章都会有。
分析的一般过程
分析源代码就是要将文本转成编译器可操作的数据其实就是对象,例如 1+1 这个字符串被分析后就是一个二元操作对象,左表达式是常量1,左表达式也是常量1。编译分析的一般过程如下所式:
词法分析 -> 语法分析 -> 语义分析 -> 生成中间代码
这个过程中各个阶段的产物如下所示:
单词 -> 语法分析树 -> 抽象语法树 -> 中间代码
上面说的这些还是过于理论化了,如果按Irony实现过程而言各个阶段的产物如下所示:
Token -> ParseTreeNode -> AstNode -> LINQ表达式
下面我们用个简单的实例来说明
简单文法示例
如果你想创建一个自己的编程语言,需要创建一个方法类,继承自Irony.Parsing.Grammar,然后在构造函数中声明文法内容即可,下面用Irony中的示例代码来说明,如果你有详细看过龙书的话会发现下面这个例子就是该书中example 4.46的例子。
public GrammarEx446() {
NonTerminal S = new NonTerminal("S");
NonTerminal L = new NonTerminal("L");
NonTerminal R = new NonTerminal("R");
Terminal id = new IdentifierTerminal("id");
S.Rule = L + "=" + R | R;
L.Rule = "*" + R | id;
R.Rule = L;
Root = S;
}
Irony框架还提供了一个文法浏览及验证工具如下图所示,当你加载写好的DLL会自动出现你所定义的终结符、非终结符、产生式及转换状态等,同时可以测试验证文法的正确性。
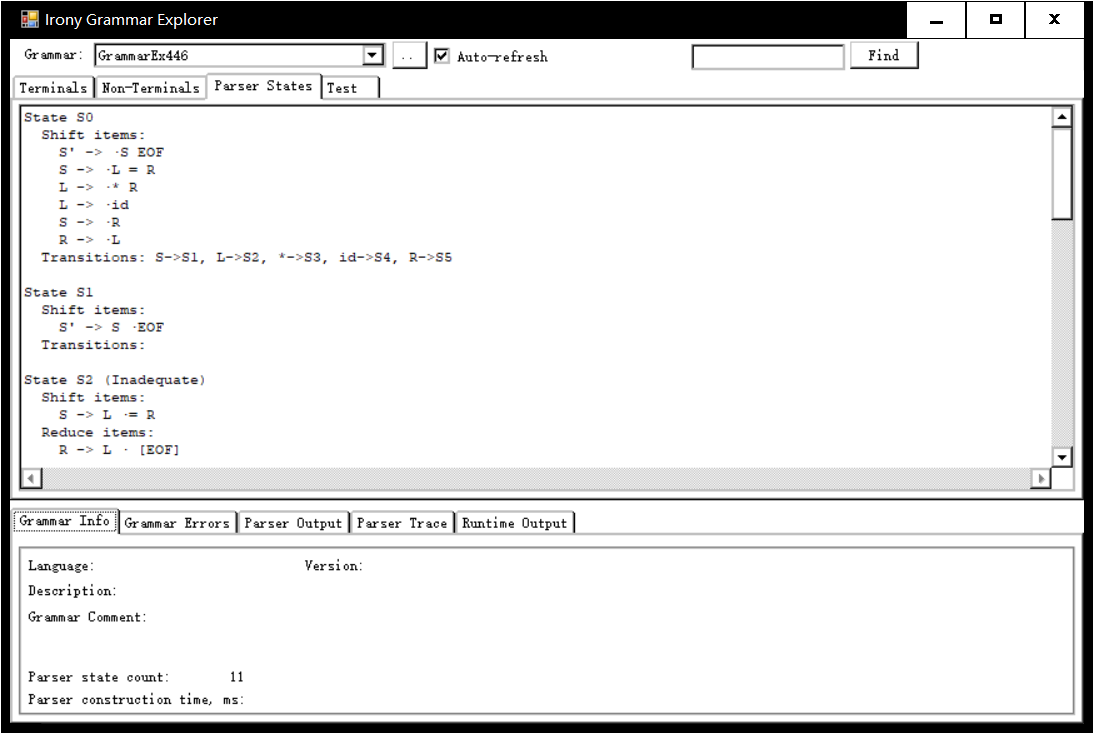
使用Irony创建文法就是在声明终结符、非终结符及非终结符的规则,按龙书中的理论来说就是构造有穷自动机,当然是指导Irony引擎工作的有穷自动机规则,每个非终结符结点都会定义一条展开子节点的规则,当我们解析任何一份正确源代码在任何一个非终结点上都可以进行无二义性的展开子节点,就算我们成功构造了该语言的文法了。
文法冲突
在Irony框架的帮助下,我们可以忽略词法分析这个过程,这个由框架实现了,我们只需要关注文法规则就好,如上面例子所示,Irony构造规则的代码和原始BNF语言非常接近了,下面我们摘一段OData的ABNF原文给大家参考。
queryOptions = queryOption *( "&" queryOption )
queryOption = systemQueryOption
/ aliasAndValue
/ customQueryOption
由于这些因素,所以可以很快的构造出文法,例如我只花了一周时间就实现了OData主要及扩展的文法,但是当这些文法规则复杂到一定程度时,你会发现会出现很多冲突,这也是实际中实现一个文法的主要工作,解决文法冲突,这里列出几种常见的情况及解决方案。下面是OData的文法文档地址:
odata-abnf-construction-rules
http://docs.oasis-open.org/odata/odata/v4.0/cs01/abnf/odata-abnf-construction-rules.txt
odata-aggregation-abnf
http://docs.oasis-open.org/odata/odata-data-aggregation-ext/v4.0/cs02/abnf/odata-aggregation-abnf.txt
1. 文法冲突之空白字符
像C#、Java中都是以空白字符做为默认的分词字符,不过在OData中是基于URL的,所以原文中声明空白字符、%20及%09都算空白字符,如下所示:
OWS = *( SP / HTAB / "%20" / "%09" ) ; "optional" whitespace
RWS = 1*( SP / HTAB / "%20" / "%09" ) ; "required" whitespace
BWS = OWS ; "bad" whitespace
这里我实践过,如果按原文的意思去构造会大大增加文法规则的复杂程度,Irony默认也是跳过空白字符。
2. 文法冲突之重复引用冲突
原始的文法是为比较准确的描述出OData的各个元素在文法中的出现位置及组合方式,总而言之如果你完全按原文的定义来写肯定无法实现,如下所示:
navigationProperty = entityNavigationProperty / entityColNavigationProperty
entityNavigationProperty = odataIdentifier
entityColNavigationProperty = odataIdentifier
上面这段需要合并成下面这一句话,因为人为意识可以知道navigationProperty这个非终结点代表这两种元素,不过对于机器而言navigationProperty的产生式中有两条路,而这两条路对代表一个终点,所以它不知道应该走哪条路,所以产生二义性。
navigationProperty = odataIdentifier
这只是一个复杂例子的缩影,实例中情况可能是这样的,这样必然会冲突。
A = B | C
C = D E
D = B
3. 文法冲突之重复元素
在文法定义中会有下面这种情况,这表示 queryOptions 是由一个 queryOption 或多个由 “&” 分割的 queryOption 元素组成的,这里Irony有两个很有用的函数 MakeStarRule 与 MakePlusRule 这两个分别对应了BNF中 * 和 1* 这两个操作符。
queryOptions = queryOption *( "&" queryOption )
queryOption = systemQueryOption
/ aliasAndValue
/ customQueryOption
这里有个陷阱,如果你声明一个 MakeStarRule 规则,在另一个地方引用它为空则会引发冲突如下代码所示,这时改成 MakePlusRule 即可,
NonTerminal A = new NonTerminal("A");
NonTerminal B = new NonTerminal("B");
Terminal id = new IdentifierTerminal("id")
A.Rule = ToTerm("+") + B.Q();
B.Rule = MakeStarRule(B, ToTerm(","), id);
this.Root = A;
对于可重复元素规则是发生冲突的比较多的地方,具体只能实际情况对待。
4. 文法冲突之强制移入或归约
文法冲突发生时通过规则自动决定不了接下来的行为是移入还是归约,这个时候可以调用方法强制执行ReduceHere,PreferShiftHere,ReduceIf,ShiftIf,不过还有更复杂的情况发生,例如C#语言中的终结符号 “<" , 这个符号可以表示小于或小于等于以及泛型声明的开始,这里框架根据优先预读的规则可以判断出小于及小于等于的冲突,不过对于泛型而言这时需要向后预读若干个字符如果发现成对的“>”出现则表示为泛型定义,否则为小于号,使用CustomActionHere 这个函数可以自定义代码干预解析行为。
5. 文法冲突之解决不了的冲突
其实理论上是不存在解决不了的冲突,可能是因为复杂度和代价的原因导致不值得去解决这个冲突,这里我们可以修改规则放宽要求而在语法分析解决可以通过,可以把这个验证工作放到语义分析阶段去做。
以上是我分享一些创建文法解决冲突的一些方式。
完整的OData文法实现
目前已经实现了整个 OData URL约定,并通过官方文档的所有示例测试,如下图所示。
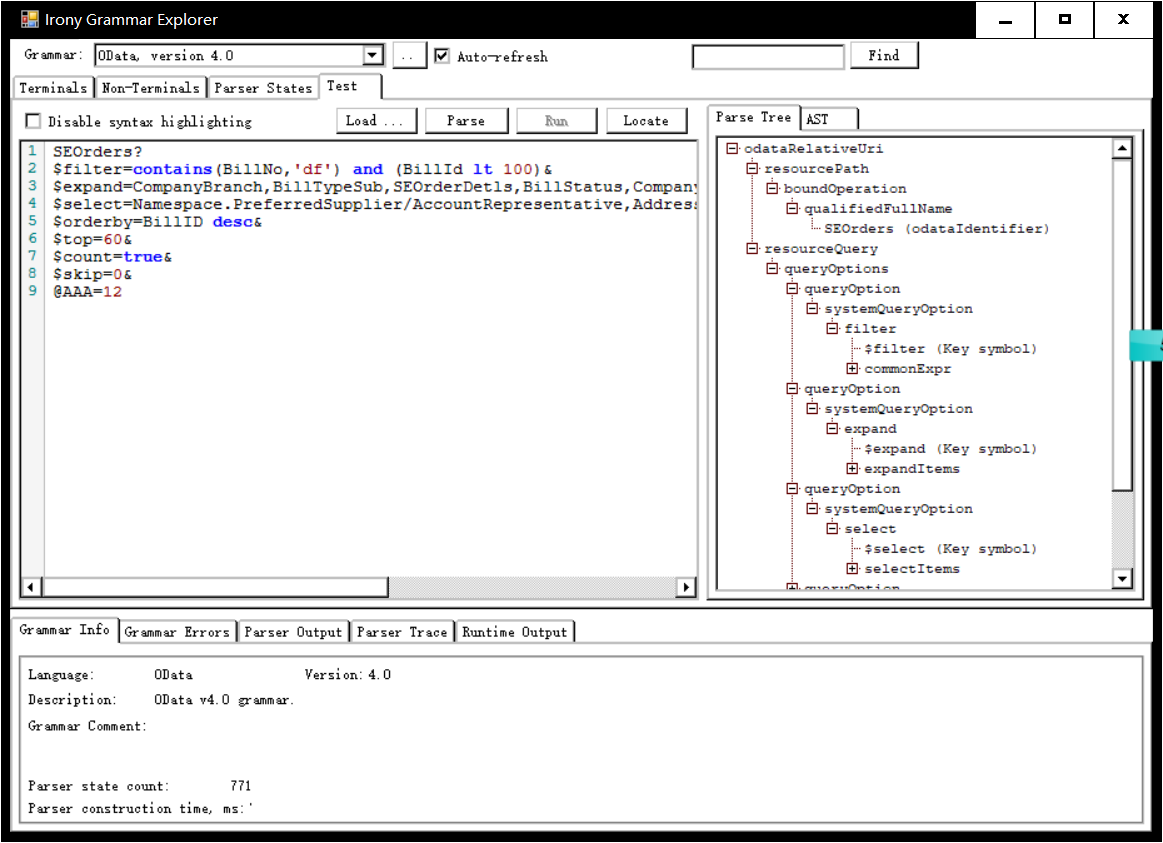
以下为文法的实现代码,欢迎大家指正错误。
文法实现代码
https://github.com/CarefreeXT/OData/blob/master/src/Caredev.OData/Core/UriParser/ODataGrammar.cs
单元测试代码
https://github.com/CarefreeXT/OData/blob/master/test/Caredev.OData.Tests.AspNet/ODataGrammarTest.cs
OData项目及进程
我们的目标其实是要是实现整个OData协议,其中最强大的部分就是要尽可能支持OData协议转换为ORM可识别的LINQ表达式,用于自动翻译成SQL语句,这里我们不考虑对性能有极端要求的项目,其深远的意义我在 OData(01) - 使用OData高效构建后台服务 已说明,这里的工作原理如下所示,目前看来能够高度支持微软标准LINQ翻译SQL的ORM框架也就Entity Framework、Entity Framework Core、Mego三种,因此其他的暂时就不在考虑范围内。
URL -> 词法分析 -> 语法分析 -> 语义分析 -> LINQ表达式 -> ORM -> Database
正因如此,我们创建了Github项目 Caredev.OData。目前已经完成前面两项最困难的工作,这里先列出项目进程,欢迎大家提出意见,谢谢支持。
- OData文法定义实现(已完成)
- OData抽象语法树实现(已完成)
- ASP.NET及ASP.NET Core 路由实现(已完成)
- 实现OData批量提交(进行中)
- 语法树编译LINQ查询表达式
- 支持Entity Framework、Entity Framework Core、Mego三种ORM框架
- 支持OData Aggregation Url
