倍增的应用-LCA与st表
倍增,好像大概就是1-2-4-8的样子,这样增长的时间复杂度是log级别的
1. ST表
区间最值,是一种可以重复贡献的问题,因为一个点被计算多次并不会影响它所在区间的最大值,这很好理解
如果想做到O(1)查询区间最值,就需要预处理出数组
很容易想到O(n3)的朴素暴力,枚举左右端点,然后遍历区间记录最值到max数组里
再可用递推的思想想到O(n2)做法,若max[i][j]表示i-r之间的最大值,则max[i][j]=max(max[i][j-1],a[i])
至此,递推算是走到头了,我们需要一种O(nlogn)的算法,它就是ST表
①. 区间的划分
在之前的递推中,我们选择用左右端点来表达一个区间,在转移的时候,将新的一个点加入区间
有没有别的表达方式呢?
在ST表算法中,只会表达长度为2n的区间。st[i][j]表示 以i为左端点,长度为2j 区间的最值,其右端点经过计算可得 i+2j-1
为什么要这么做呢?这样不是不能记录所有区间了吗?
但2j区间有什么好处?显然的,一个2j区间可被分成两个等长的2j-1区间
两个?二分?log2!
这就能体现出ST表预处理时,为什么复杂度是nlogn级别的。
转移方程很好写,以最大值为例
st[i][j]=max(st[i][j-1],st[i+(1<<(j-1))][j-1])
因为前文说过,st[i][j]右端点为i+2j-1,那么它右侧区间的左端点就是i+2j
且1<<n=2n
所以转移方程的含义就是:一个区间的最值,等于它左右两个区间最值的最值
特别的,st[i][0]区间只包含a[i]自身,所以st[i][0]=a[i]
预处理代码
for(int i=1;i<=n;i++){
st[i][0]=read();
}
for(int j=1;j<=20;j++){
for(int i=1;i+(1<<j)-1<=n;i++){
st[i][j]=max(st[i][j-1],st[i+(1<<(j-1))][j-1]);
}
}有一些细节
在双层枚举的时候要先枚举j(次数),因为如果先枚举端点,对于每个端点枚举次数时,右半部分的区间最值是未知的
比如如果先枚举端点到1,枚举j到2
那么此时已知值是所有的st[i][0],st[1][1]
但st[1][2]=max(st[1][1],st[2][1])
发现了吗?st[2][1]未知
如果先枚举次数到2,端点到1
那么此时已知值是所有的st[i][0],st[i][1]
st[1][2]=max(st[1][1],st[2][1])
全部已知
(说白了就是从小往大枚举,不然你怎么用一个区间最值转移出它二倍长区间的最值)
其次就是枚举i的边界问题,边界条件不是i<=n,因为i是左端点,要保证右端点<=n,所以条件是i+(1<<j)-1<=n
再然后就是j的范围,在这个题目里是20,那么怎么计算呢?
我们记n最大值为MAXN,那么很显然,区间的长度不能超过n
也就是不能超过2log2(n)+1的长度(log2向下取整,例如(int)log2(7)=2,而7显然是<=23的)
如果要用计算器估测某个题中j的范围,可以用换底公式得到 j∈[0,l(gn/lg2)+1],j∈N*
②. 查询
解决完了预处理的问题,如何查询呢?
题目可不仁慈,给的区间大部分长度都不能写成2n的形式,怎么办?
区间最值是一种可重复贡献的问题,与区间和不同,区间和一个点加两次会出错,但取两次最值不会
所以,区间是可以重叠的
如果查询区间 [l,r] 的最值,我们先记 k=log2(r-l+1),也就是区间长度的log2下取整,这样,2k<=r-l+1,不会越界
那么左端点向右2k长的区间,和右端点向左2k长的区间,两个区间一定覆盖了整个 [l,r]
如何证明?如果这两个区间完全没有重叠,长度会达到2*2k=2k+1,而因为k>=log2(r-l+1)(因为向下取整了),所以k+1>log2(r-l+1),又有2k+1>2log2(r-l+1),即2k+1>r-l+1
但是我们都是记录的左端点,第一个区间好说,第二个区间怎么办?
我们设区间左端点为x,右端点已知,为r
由小学数学可知,r=x+2k-1,移项得x=r-2k+1
至此,查询代码也很好写了
完整代码(模板题Luogu P3865)
// Problem: P3865 【模板】ST 表
// Contest: Luogu
// URL: https://www.luogu.com.cn/problem/P3865
// Memory Limit: 125 MB
// Time Limit: 800 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
#define INF 0x7fffffff
#define MAXN 100500
#define MAXM 10003
using namespace std;
inline int read()
{
int x=0,f=1;char ch=getchar();
while (ch<'0'||ch>'9'){if (ch=='-') f=-1;ch=getchar();}
while (ch>='0'&&ch<='9'){x=x*10+ch-48;ch=getchar();}
return x*f;
}
int st[MAXN][21];
int n,m;
int ask(int l,int r){
int k=log2(r-l+1);
return max(st[l][k],st[r-(1<<k)+1][k]);
}
int main(){
n=read(),m=read();
for(int i=1;i<=n;i++){
st[i][0]=read();
}
for(int j=1;j<=20;j++){
for(int i=1;i+(1<<j)-1<=n;i++){
st[i][j]=max(st[i][j-1],st[i+(1<<(j-1))][j-1]);
}
}
while(m--){
int l=read(),r=read();
printf("%d\n",ask(l,r));
}
return 0;
}2. LCA
在树上求最小公共祖先的算法,与st表类似
①. 预处理
我们要记录了一个节点的2n级祖先,用fa[i][j]表示节点i的2j级祖先,显然有fa[i][0]就是i的父节点
同时记录每个节点的深度,用depth[i]表示节点i的深度,规定根节点的深度为1,它的孩子深度为2,以此类推
以上均可以用一次dfs遍历实现
void dfs(int now,int fath){
if(fath!=-1){
fa[now][0]=fath,depth[now]=depth[fath]+1;
for(int i=1;i<=log2(depth[now]);i++){
fa[now][i]=fa[fa[now][i-1]][i-1];
}
}
for(int i=0;i<e[now].size();i++){
if(e[now][i].v!=fath) dfs(e[now][i].v,now);
}
}如果这个节点是根节点,那么无需更新其depth与fa
如果不是,那么需要更新
先记录fa[now][0]=fath,depth[now]=depth[fath]+1,很好理解,不再赘述
然后是更新fa的过程
我们需要更新的是f[now][i],那我们就需要确定i的枚举顺序和枚举范围
因为0已经更新,所以i的下界是1,上界是log2(depth[now])
推导:设上界为x,则2x=depth[now],所以x=log2(depth[now])
推到顺序则是从小到大,由转移方程可知,此时是用两段更新一段更大的,所以由小向大
转移方程可以表达为:一个节点的2i级父节点,等于它2i-1级父节点的2i-1级父节点
然后遍历出边继续dfs即可
②. LCA查询
记两个点为x,y,大概的思想是两个点同时倍增地往上跳,直到找到LCA,但有很多细节
首先给定的两个节点深度不一定谁大,所以假定depth[x]>=depth[y]
if(depth[x]<depth[y]) swap(x,y);再次,如果两个节点深度不同,同时上跳有可能会相互错过,所以我们要把它们跳到同一深度,又因为depth[x]>=depth[y],所以让x上跳
每次让x变成它的2log2(depth[x]-depth[y])级父节点,因为log2向下取整,所以不可能跳过y的深度,取log的操作可以让每一次跳跃都是尽可能最远的
推导:假定数组下标可以为浮点数,那么设fa[x][m]=y,即depth[x]-2m=depth[y],化简得到m=log2(depth[x]-depth[y]),而下标只能是int,向下取整,所以实际上m<=log2(depth[x]-depth[y]),需要多次跳跃
有个细节是必须加上强制类别转换(int),因为log2()返回值是浮点数
while(depth[x]>depth[y]){
x=fa[x][(int)log2(depth[x]-depth[y])];
}此时会可能有depth[x]=depth[y],说明x跳到了y上,即y是x的祖先,return y即可
if(x==y) return y;再往后就是LCA的核心:一起跳跃
考虑一件事,我们不能让两个点直接跳到LCA上,因为两个节点的LCA“相等”,无法区别它们LCA的祖先是否是它们的LCA
例如
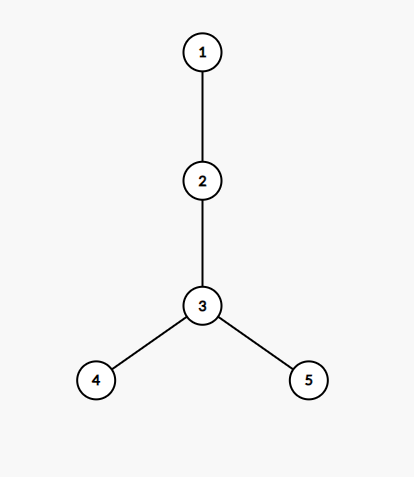
假如现在从45同时跳跃,跳到了2,那么我们是不能确定2是4和5的LCA的,如果向下寻找,nlogn的复杂度就被破坏
所以最理想的情况是我们能让它们跳到LCA的孩子上,这样输出它们之一的父节点就是LCA
而且注意到,任何一个距离都可以通过多次长度为2n的跳跃达到目的,原理是二进制
比如要跳跃7格,7的二进制位111,那只需要1,2,4的跳跃各一次即可,对应的次方即为0,1,2
并且我们要从大到小枚举这个次方,因为程序中是没有距LCA距离的二进制的,如果从小往大跳,发现跳不到需要回溯会破坏复杂度,而从大往小跳,如果跳过了,不跳就可以
这么说也许比较抽象,我们举例说明
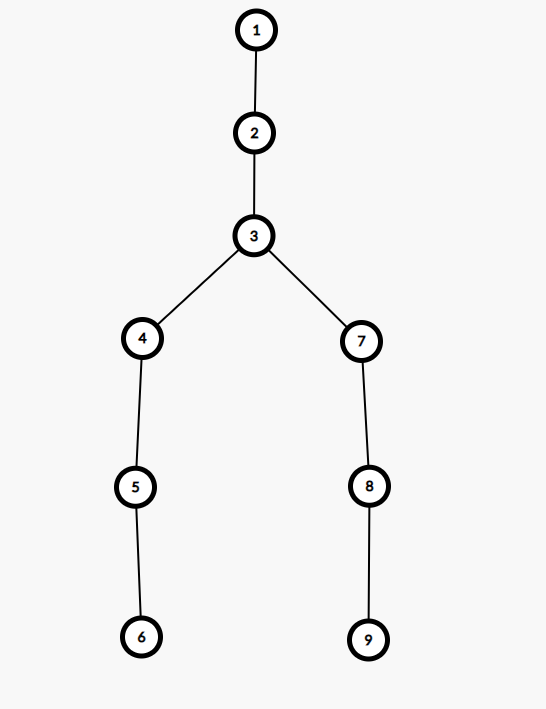
我们现在跳跃6 9节点,通过图我们知道LCA是3,距LCA孩子的距离是2,二进制10,跳一个2即可
如果我们从小向大枚举,先跳1,因为不能重复跳一个数,又跳不到LCA的孩子,我们只能回溯,而如果二进制是1000……,回溯就会发生很多次
如果从大往小枚举,最远最远,它们的LCA也才是根节点,所以i的上界是log2(depth[x])(已经证明过)
对于这个图,i的上界是2,我们先尝试跳跃22,发现两个节点都跳到了2,但我们不能确定2就是它们的LCA,事实上也确实不是
再尝试跳跃21,发现两个节点分别跳到了4和7,不一样,所以可以跳,跳过去,但我们依然不能确定这就是LCA的孩子,虽然它们已经是了
再尝试跳跃20,发现两个节点又到一起了,不跳
最后,两个节点都跳到了LCA的孩子上,return fa[x][0]或fa[y][0]均可
推导:已证任何深度都可通过若干次2n次跳跃达到
完整代码(模板题Luogu P3379)
// Problem: P3379 【模板】最近公共祖先(LCA)
// Contest: Luogu
// URL: https://www.luogu.com.cn/problem/P3379
// Memory Limit: 512 MB
// Time Limit: 2000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
#define INF 0x7fffffff
#define MAXN 500050
#define MAXM 500050
using namespace std;
int n,m,s;
struct E{
int u,v;
};
vector<E> e[MAXM];
int depth[MAXN],fa[MAXN][21];
void dfs(int now,int fath){
if(fath!=-1){
fa[now][0]=fath,depth[now]=depth[fath]+1;
for(int i=1;i<=log2(depth[now]);i++){
fa[now][i]=fa[fa[now][i-1]][i-1];
}
}
for(int i=0;i<e[now].size();i++){
if(e[now][i].v!=fath) dfs(e[now][i].v,now);
}
}
int LCA(int x, int y){
if(depth[x]<depth[y]) swap(x,y);
while(depth[x]>depth[y]){
x=fa[x][(int)log2(depth[x]-depth[y])];
}
if(x==y) return y;
for(int i=log2(depth[x]);i>=0;i--){
if(fa[x][i]!=fa[y][i]){
x=fa[x][i],y=fa[y][i];
}
}
return fa[x][0];
}
int main(){
cin>>n>>m>>s;
for(int i=1;i<n;i++){
int a,b;
cin>>a>>b;
e[a].push_back((E){a,b});
e[b].push_back((E){b,a});
}
depth[s]=1;
dfs(s,-1);
while(m--){
int l,r;
cin>>l>>r;
cout<<LCA(l,r)<<endl;
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号