

tcpip详解-读书笔记
TCP/IP详解 卷一 第一版读书笔记
第一章:
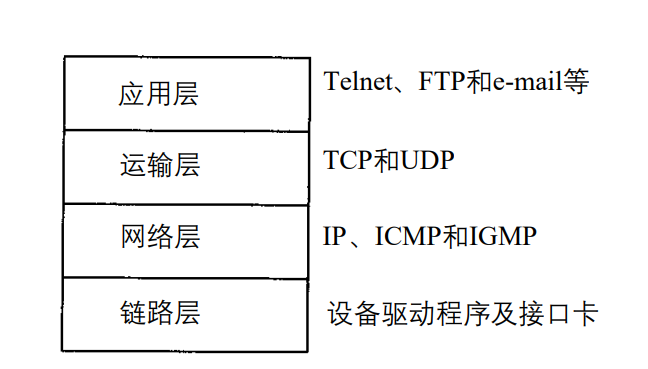
应用层关心是应用程序的细节,而不是数据在网络中对的传输活动,下三层对应用程序一无所知,但他们要处理所有的通信细节。
七层代理可以根据应用层信息转发到对应后端服务器,而四层代理只可以进行简单的负载均衡。
TCP/IP协议族是一组不同协议组成的协议族,TCP与IP只是其中两种协议而已。
端系统和中间系统
端系统:客户端与服务端
中间系统:路由器,交换机等
应用层和运输层使用端到端协议
网络层使用逐跳协议,两个端系统,和每个中间件系统都要使用它。
网络层IP提供了不可靠的服务,TCP在不可靠的IP层上提供了一个可靠的运输层。
为实现可靠服务,TCP采用了超时重传、发送和接收端到端的确认分组等机制。
1.3 TCP/IP的分层
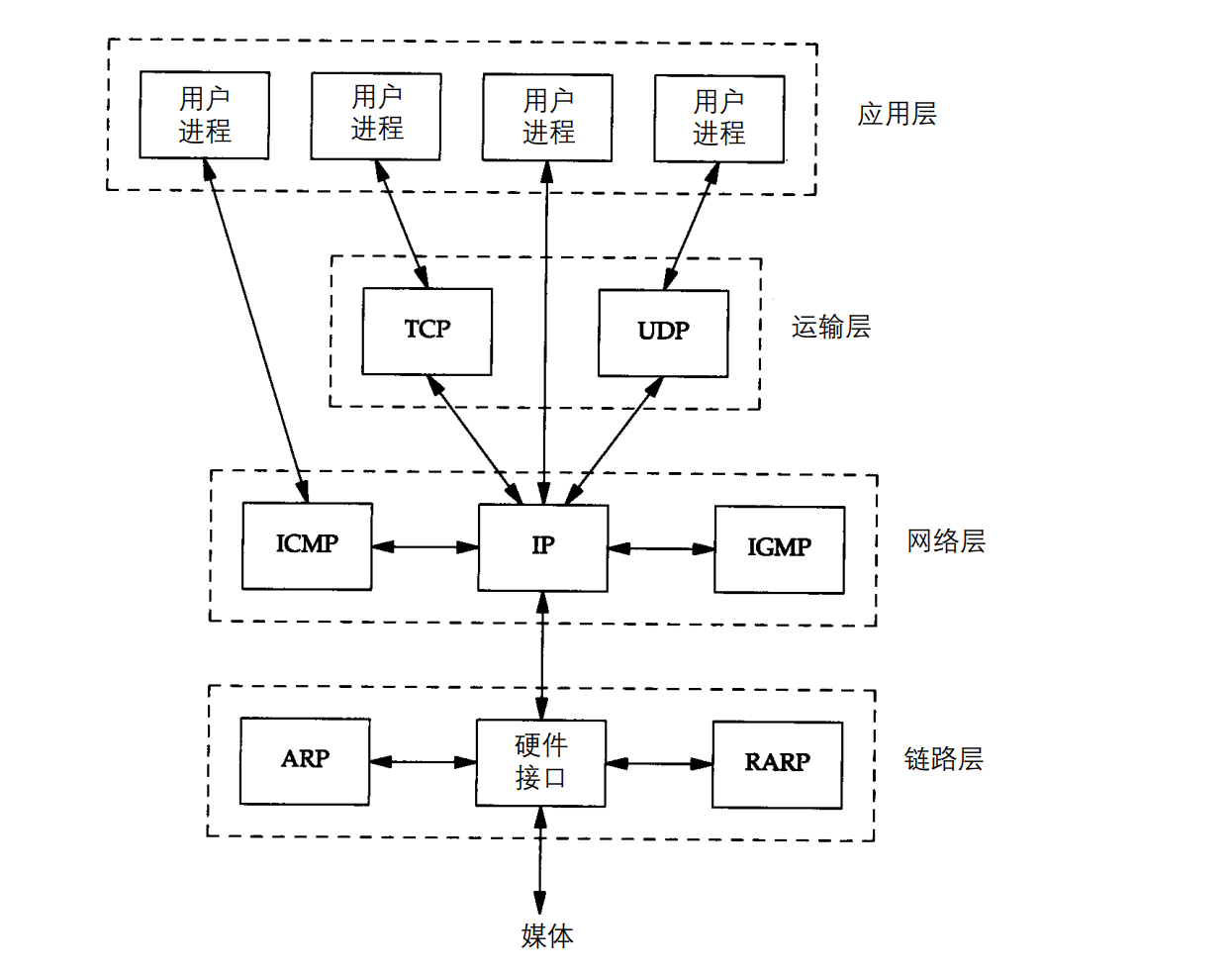
TCP应用:telnet、Rlogin、FTP、SMTP
UDP应用:DNS、TFTP、BOOTP、SNMP
ICMP是ip协议的附属协议,主流诊断工具,Ping和Traceroute都使用了ICMP
IGMP是internet组管理协议,使用UDP数据报多播到多个主机
ARP(地址解析协议)与RARP(逆地址解析协议)
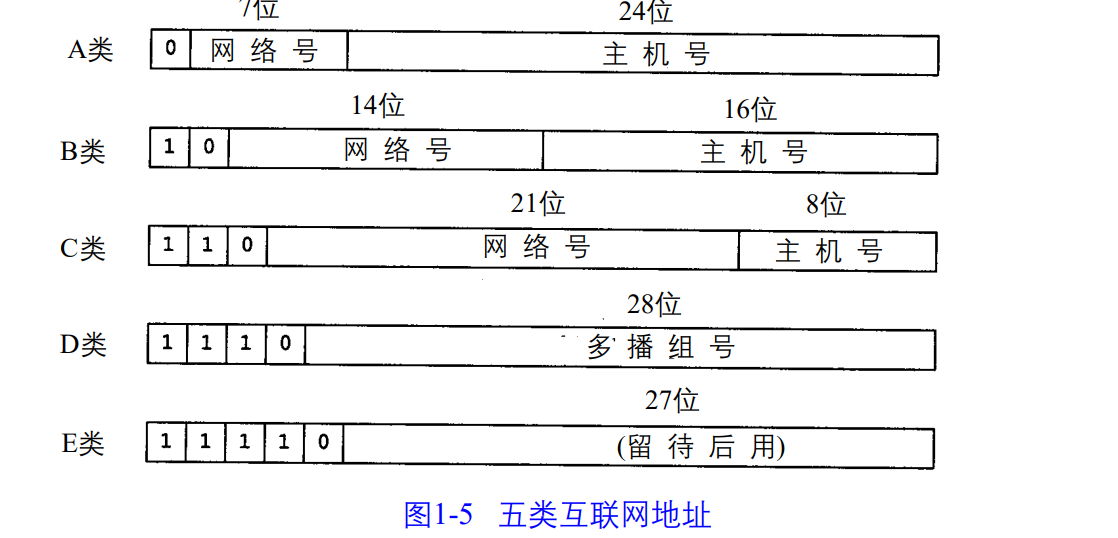
1.4 互联网地址
1.5域名系统
域名系统是一个分布的数据库,提供IP地址和主机名之间的映射关系
1.6封装
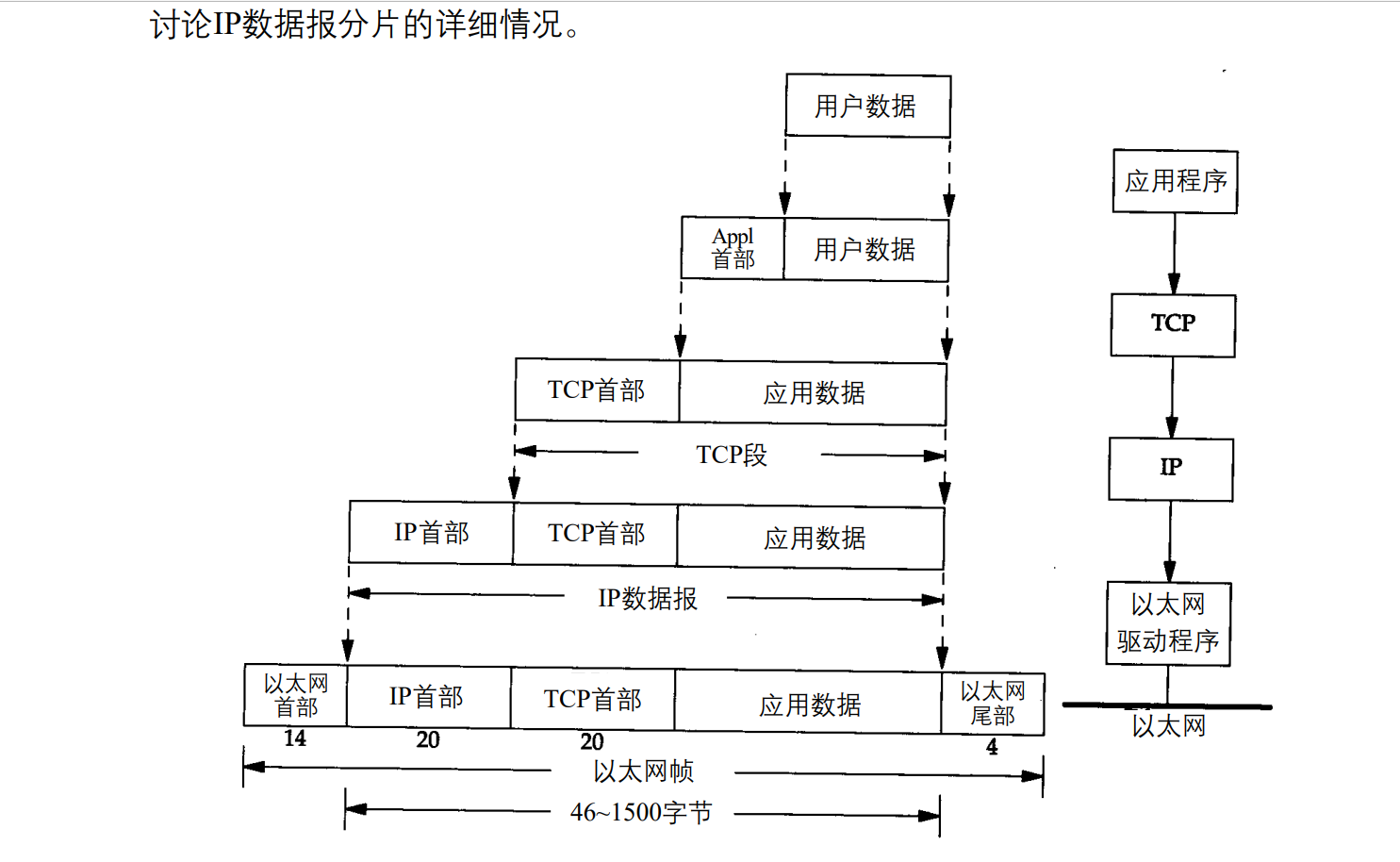
UDP与TCP数据基本一致,唯一不d同是UDP传给IP信息
安源称为UDP数据报,UDP首部长为8字节(TCP为20字节)
IP在首部存入一个长度为8bit的数值,称为协议域。1-ICMP,2-IGMP,6-TCP,17-UDP
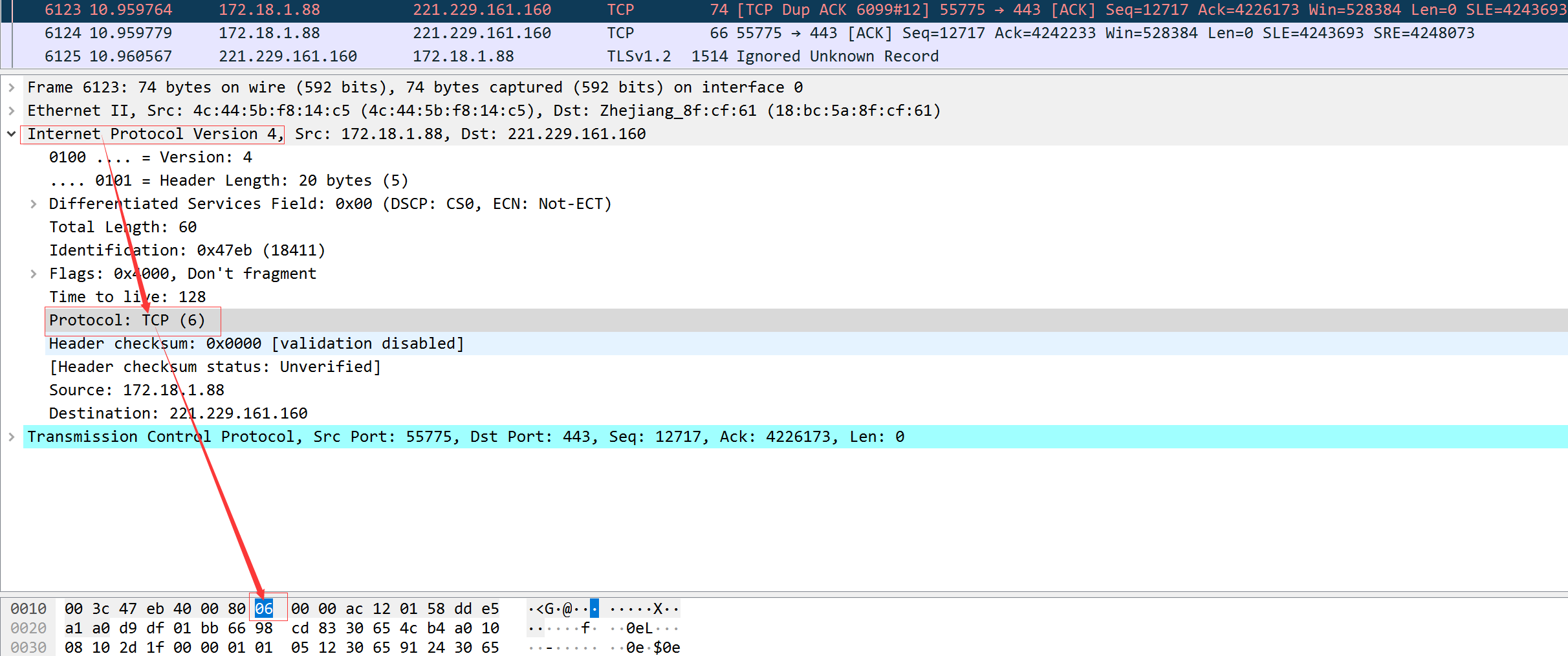
这里的06是十六进制数,转为8bit为00000110,即为06
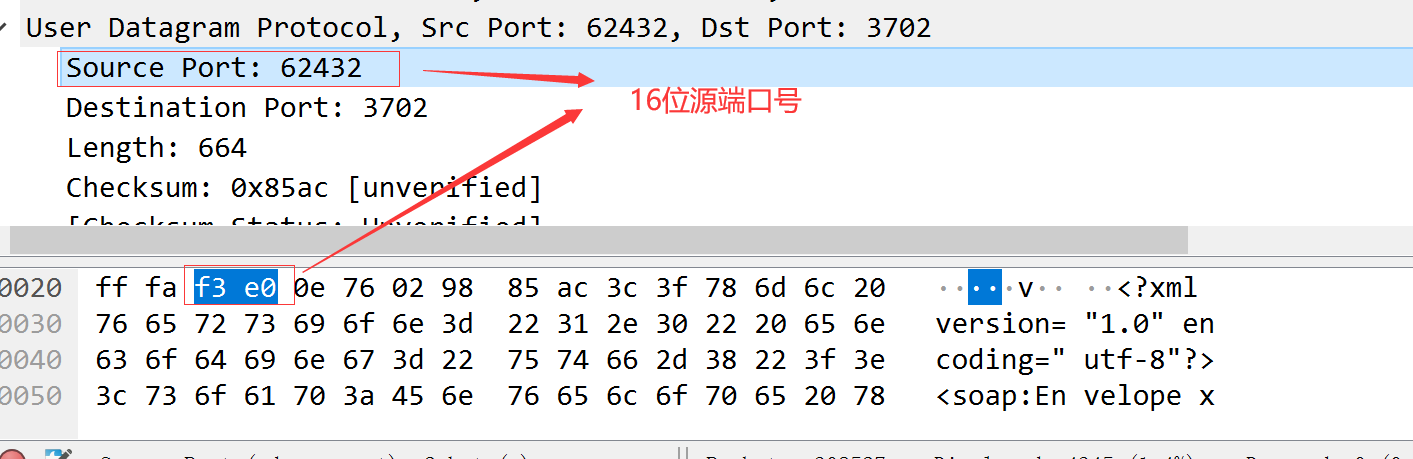
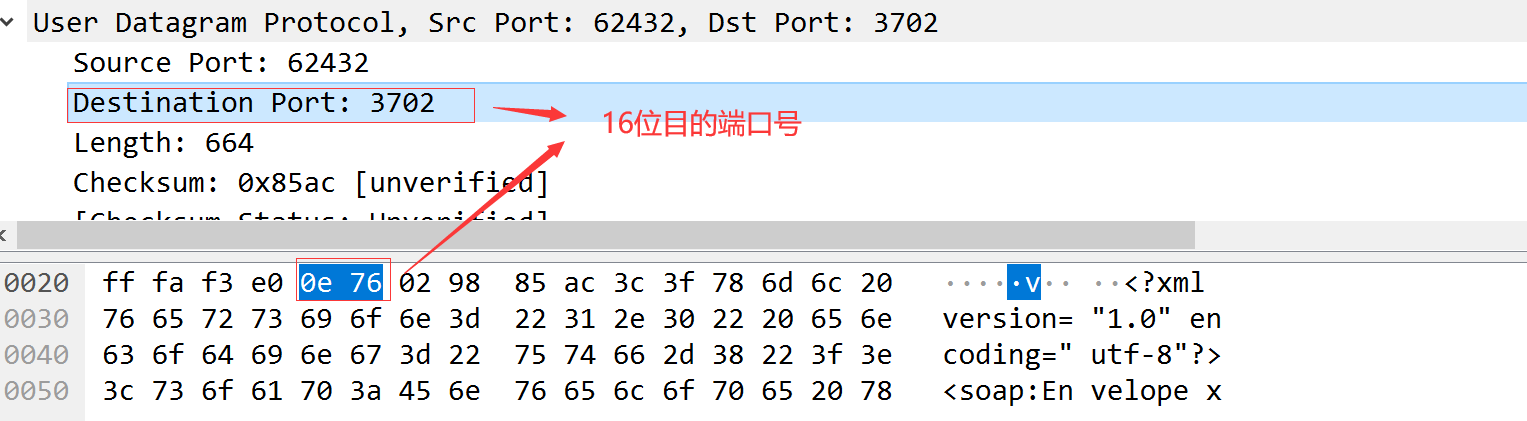
TCP和UDP都把源端口号和目的端口号分别存入报文首部中。TCP与UDP都用一个16bit的端口号表示不同的应用程序。
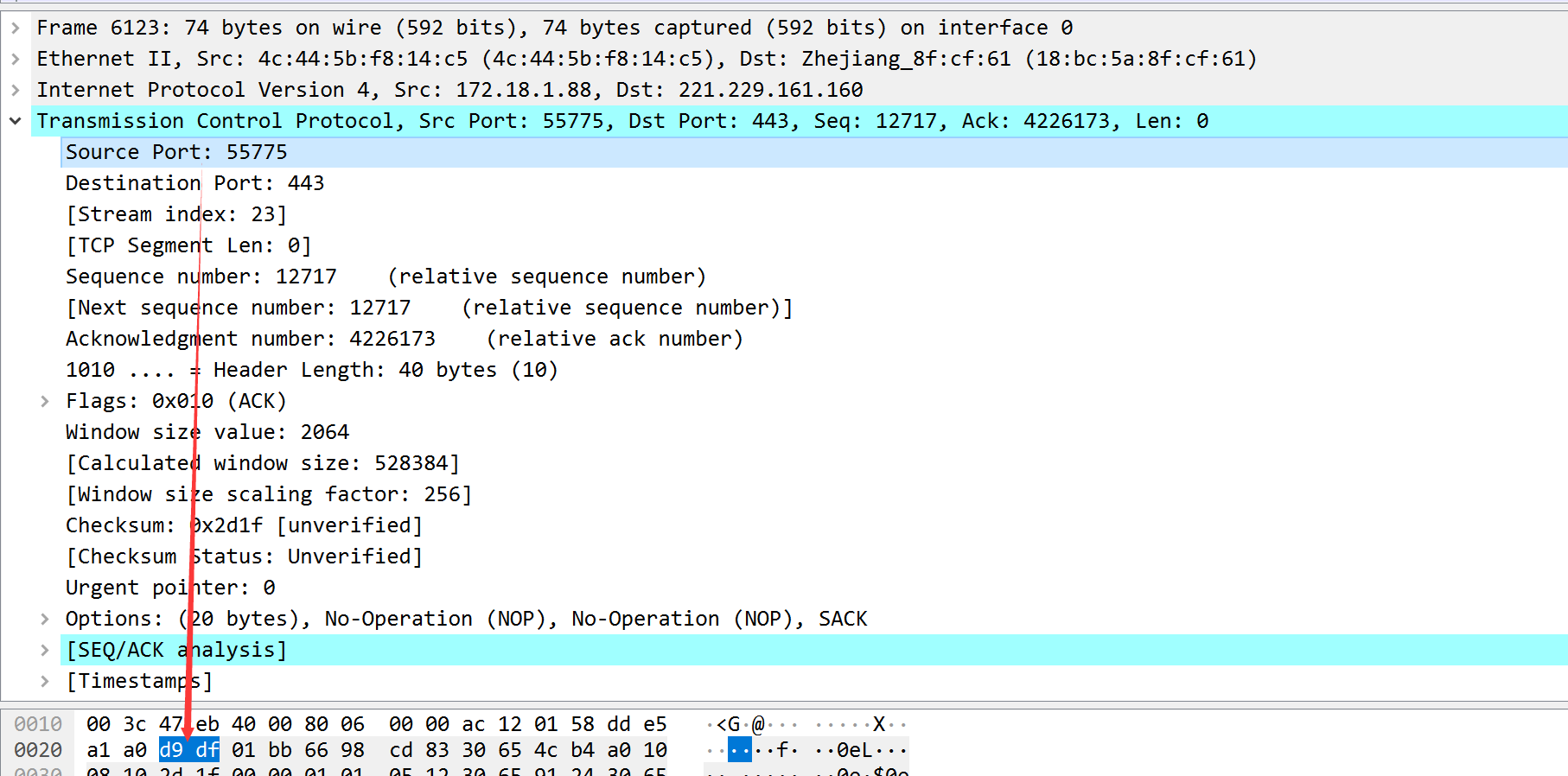
一个TCP报文中的源端口号信息。
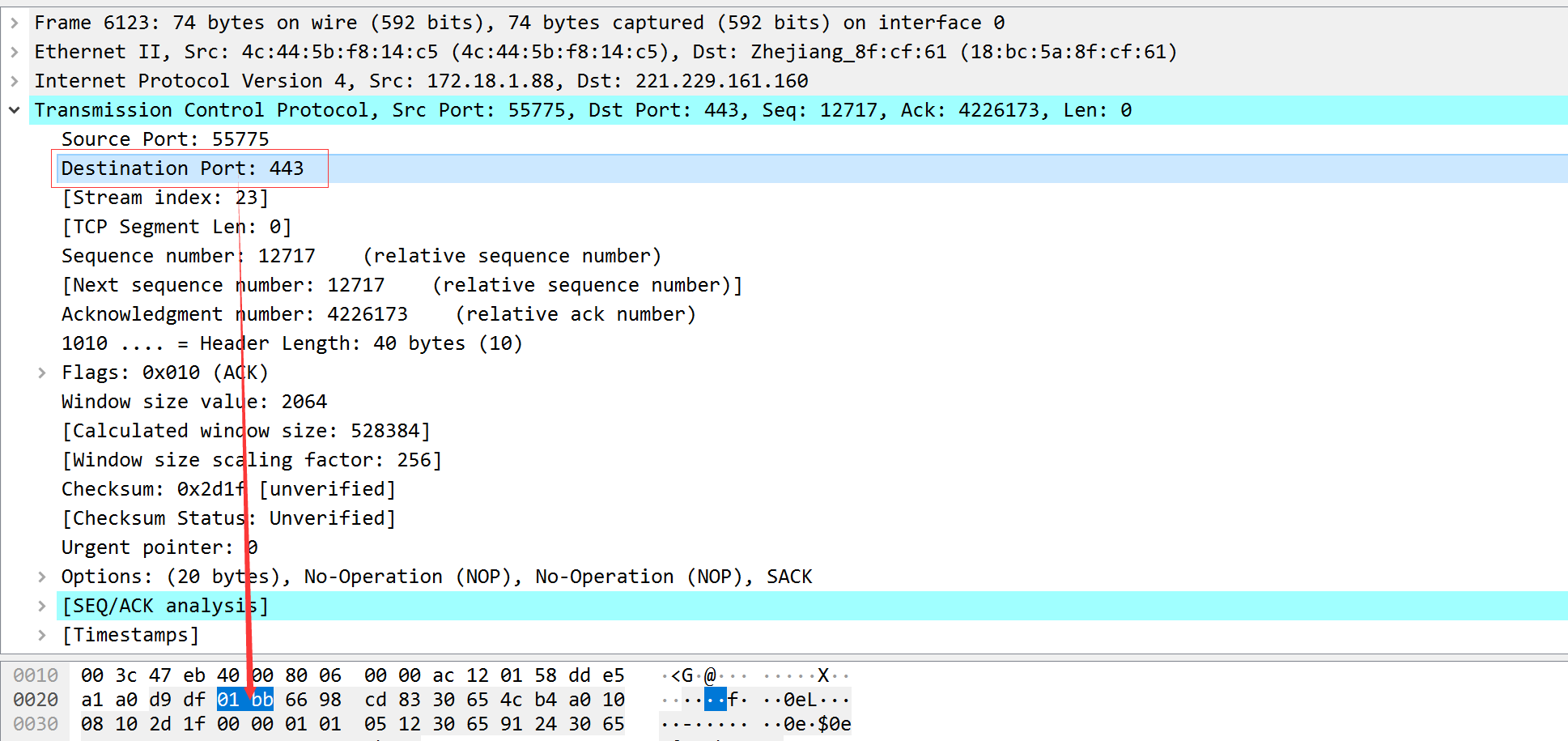
一个TCP报文中的目的端口号信息。
1.7 分用(解包)
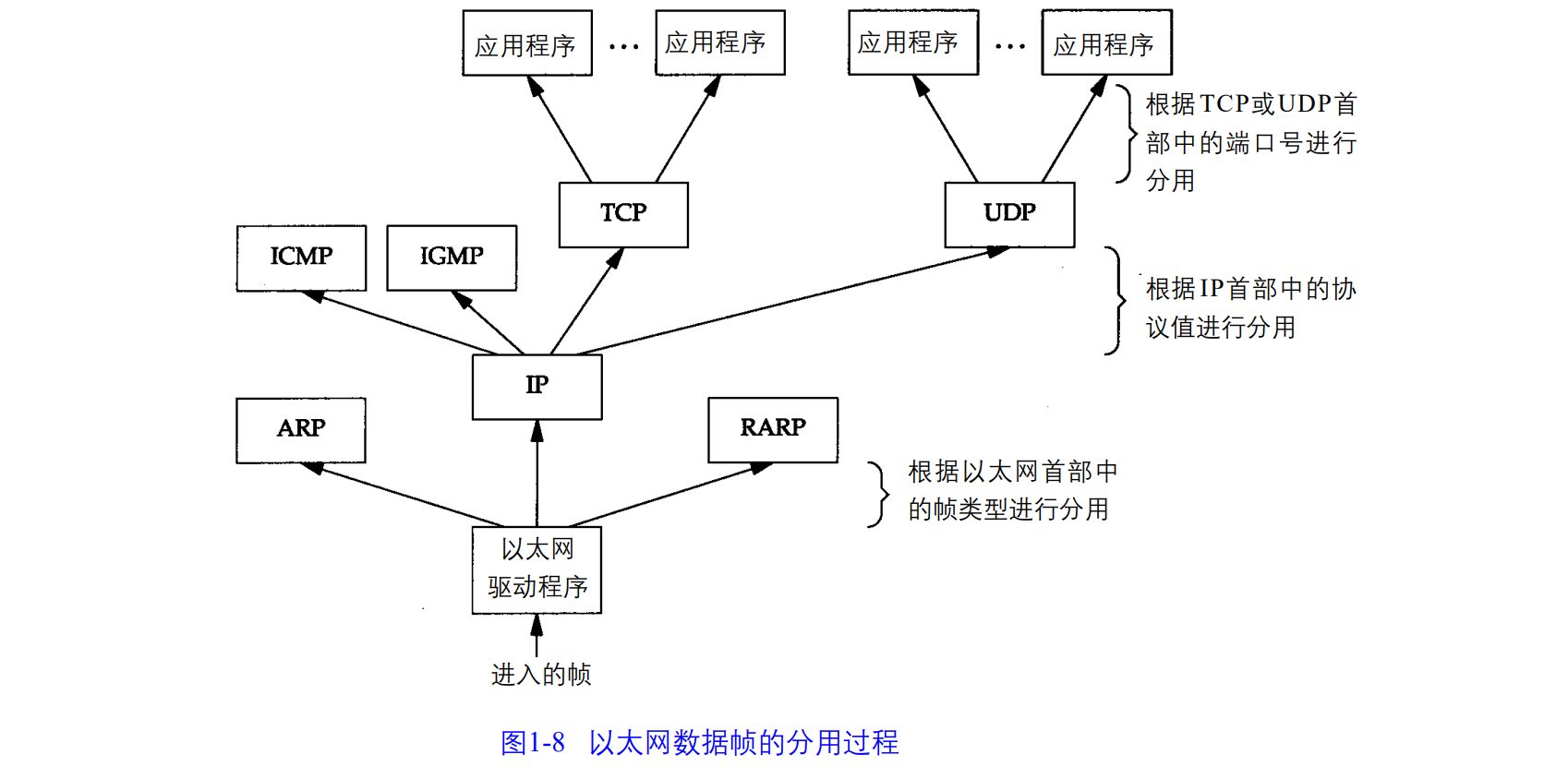
协议通过目的端口号、源IP地址和源端口号进行解包。
1.8 客户服务器模型
重复型:
1.等待客户请求
2.处理客户请求
3.发送响应给发送请求的客户
4.返回1步骤
并发型:
1.等待客户请求到来
2.生成启动一个新的服务器处理客户请求,可能生成一个新的进程、任务或线程,依赖底层操作系统支持。生成新的服务器对客户全部请求进行处理。处理结束,终止新服务器
3.返回1步
一般TCP服务是并发的,UDP服务是重复的,但有例外。
1.9端口号
服务器通过知名端口号识别服务,如FTP对应21,Telnet对应23。任何TCP/IP实现所提供的服务都用1-1023之间的端口号。
客户端的端口号并不关心,仅需要保证该端口在本机唯一即可,所以客户端口号又叫做临时端口号,存在时间很短,仅在用户运行该客户程序时才存在。服务器对应端口号只要打开,就代表其服务打开。
所以在系统排错的时候经常通过过滤端口号的形势判断对应服务是否打开
netstat -natp | grep :80

大部分TCP/IP实现给临时端口分配1024-5000之间的端口,大于5000端口为其他服务器预留的。
1.10-1.11标准化过程
1.12 标准简单服务
当使用TCP和UDP提供相同服务的时候,一般选择相同的端口号。
1.15 应用编程接口
使用TCP/IP协议的应用程序采用两种应用编程接口(API):socket和TLI(运输层接口:Transport Layer Interface)
第二章:链路层
2.1引言
链路层三个目的
1.为ip模块发送和接收ip数据包
2.为ARP模块发送ARP请求和接收ARP应答
3.为RARP发送RARP请求和接受RARP应答
两个接口链路层协议(SLIP和PPP)。
以太网与SLIP
MTU最大传输单元
2.2以太网和IEEE 802封装
8bit=两位十六进制数=1字节
1111 1000=E8 =1字节(大小)
1位=1比特
1字=2字节
1字节=8位
1字=16位
下图显示了两种不同形式的封装格式。图中的每个方框下面的数字是它们的字节长度。
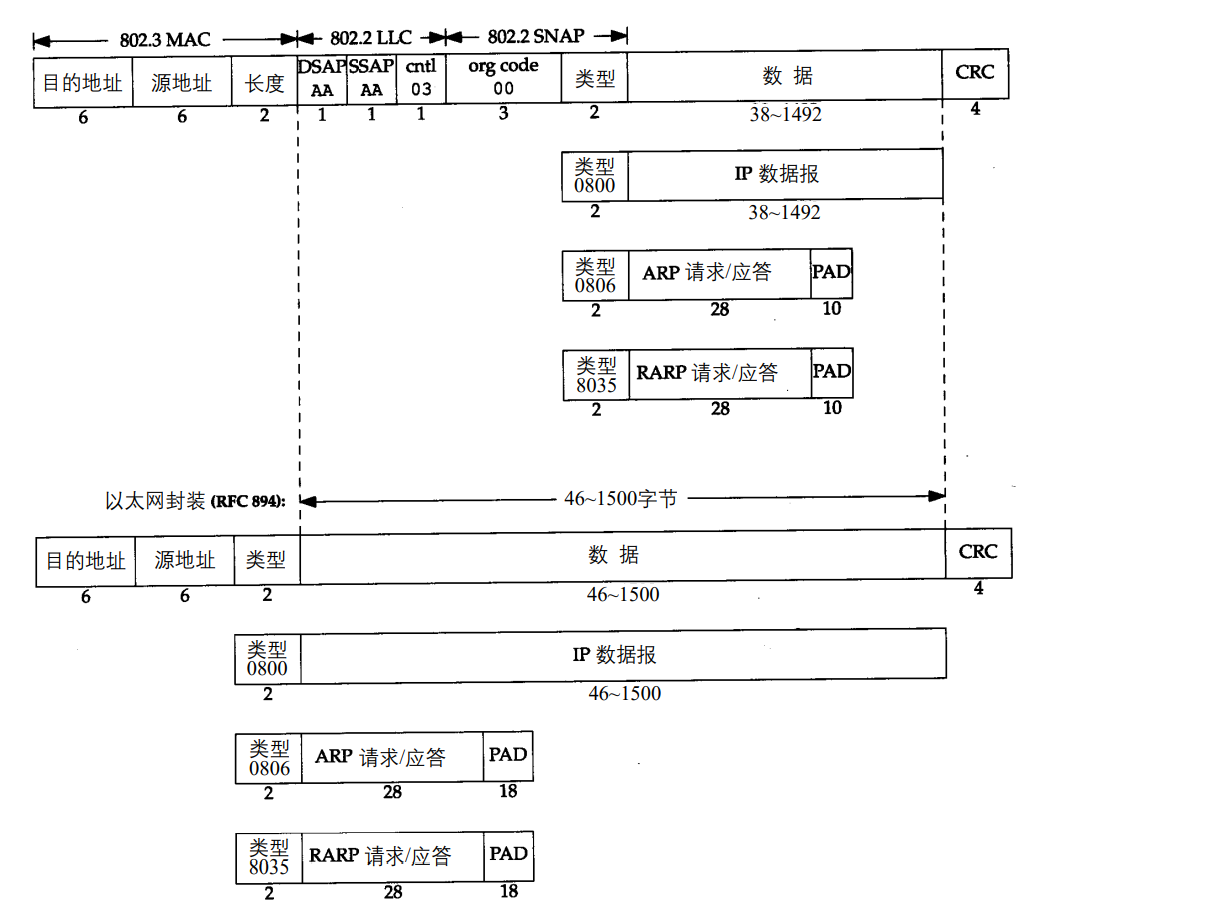
802标准:长度字段代表后续数据的字节长度,不包括CRC校验码,类型字段由后续的子网接入协议(Sub-networkd Access Protocol,SNAP)的首部给出。
以太网类型:定义后续数据的类型,类型字段后就是数据
802.3标准定义的帧和以太网的帧都有最小长度要求。802.3数据部分必须至少为38字节,以太网,最少要有46字节。为保证这一点,必须在不足的空间插入填充字节
802标准的有效长度值和以太网的有效类型值无一相同,通过该方式可以对帧格式进行区分
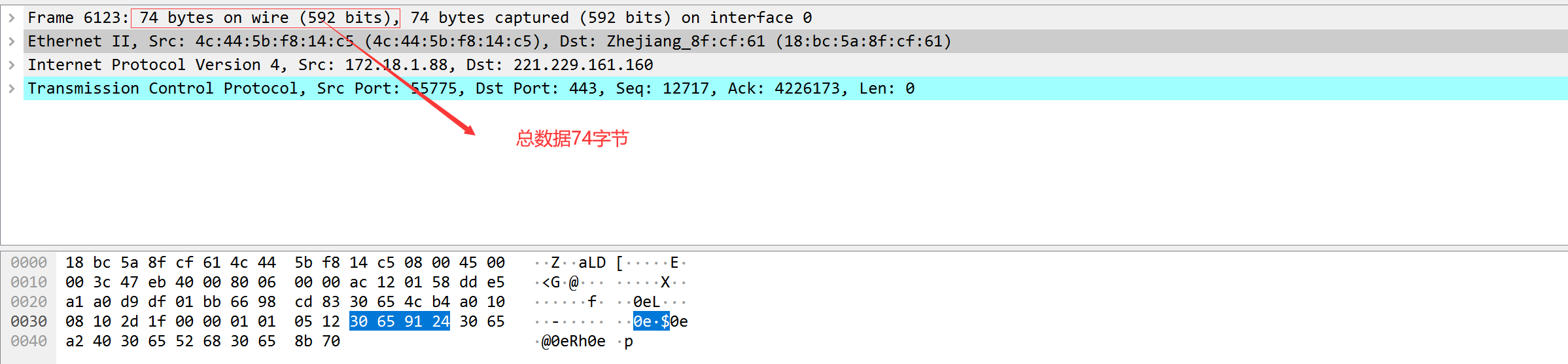
以太网封装格式抓包演示:
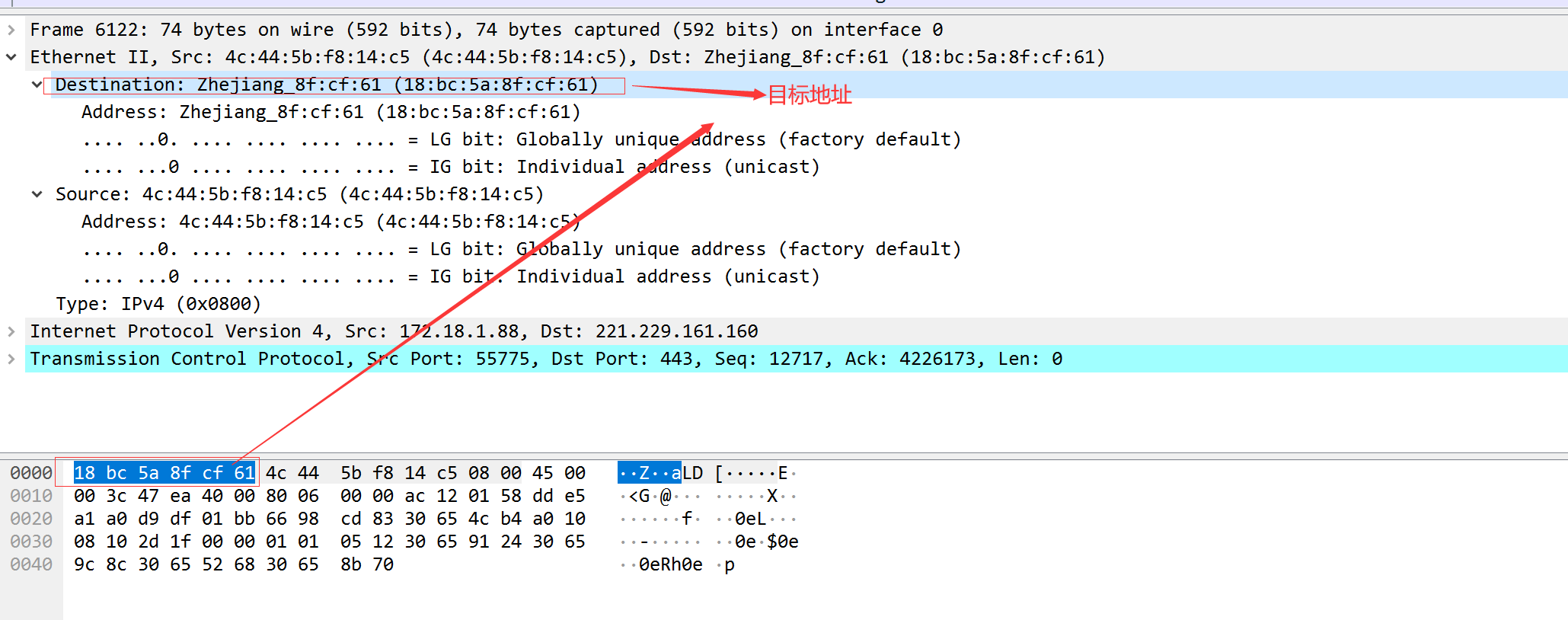
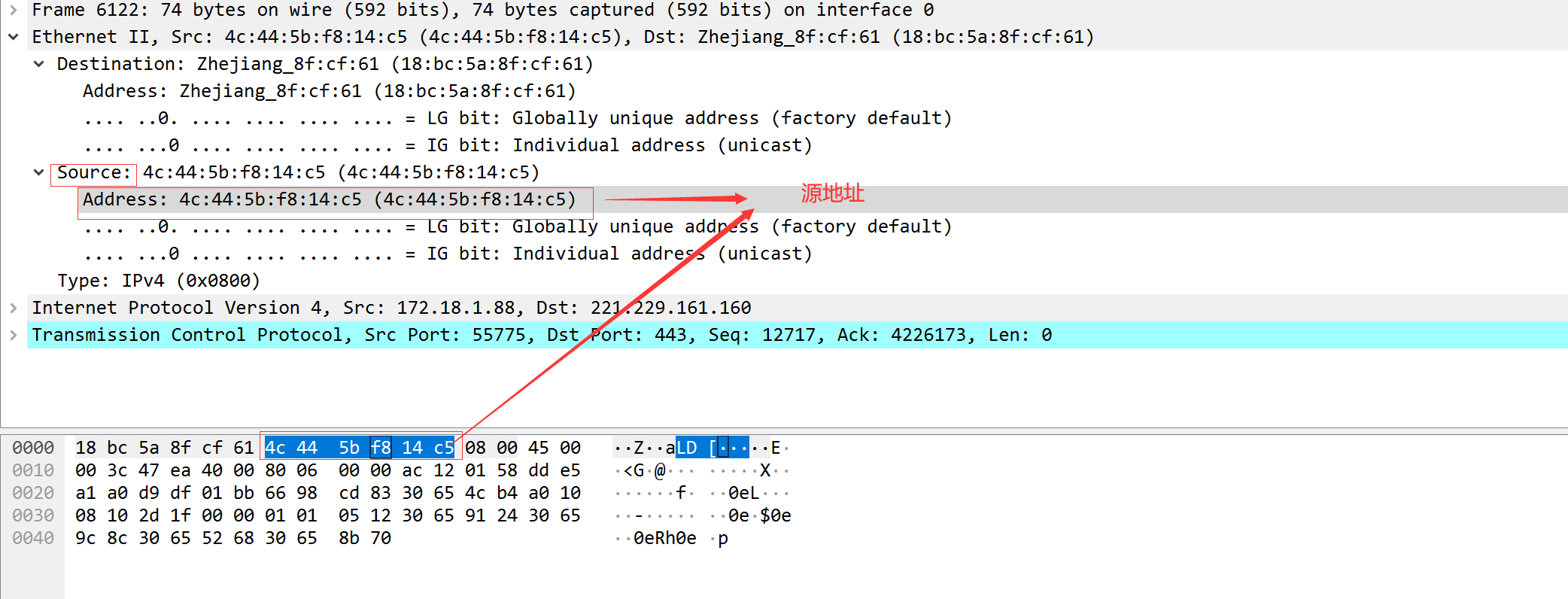
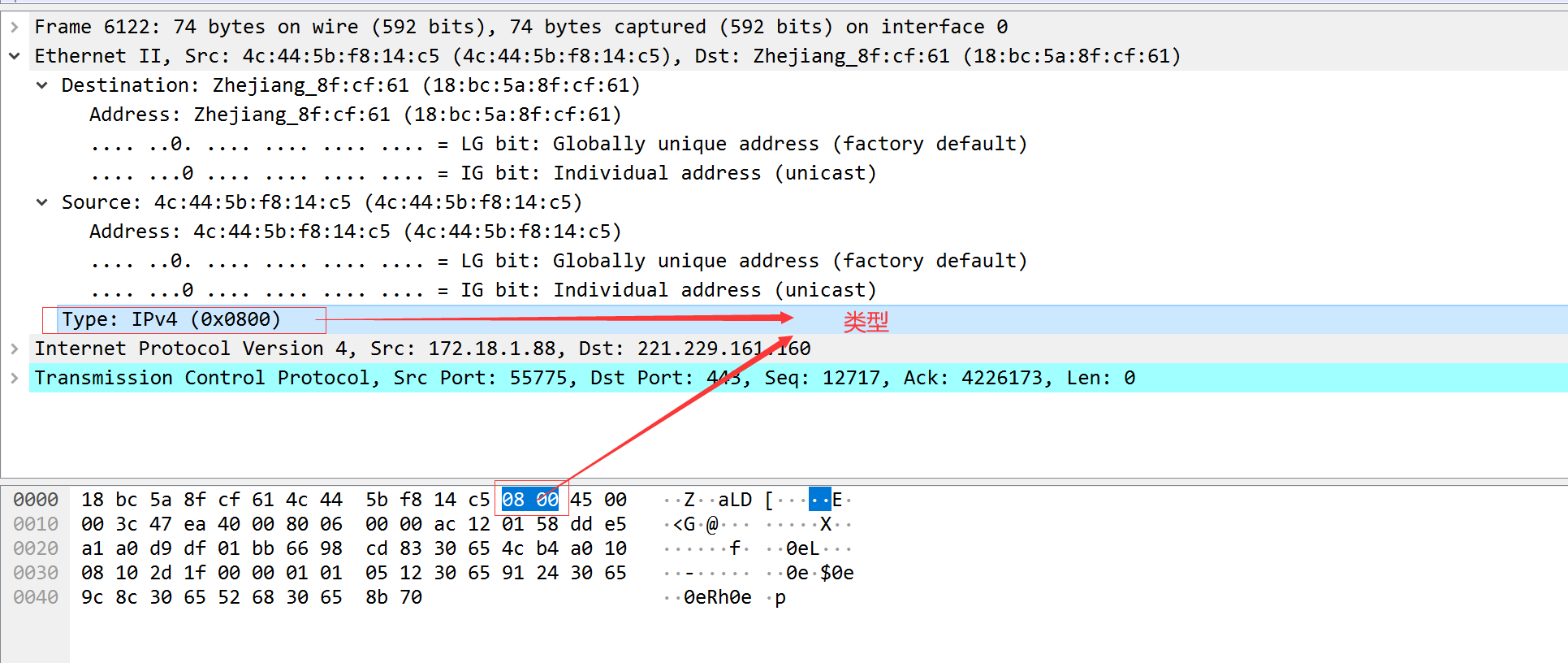
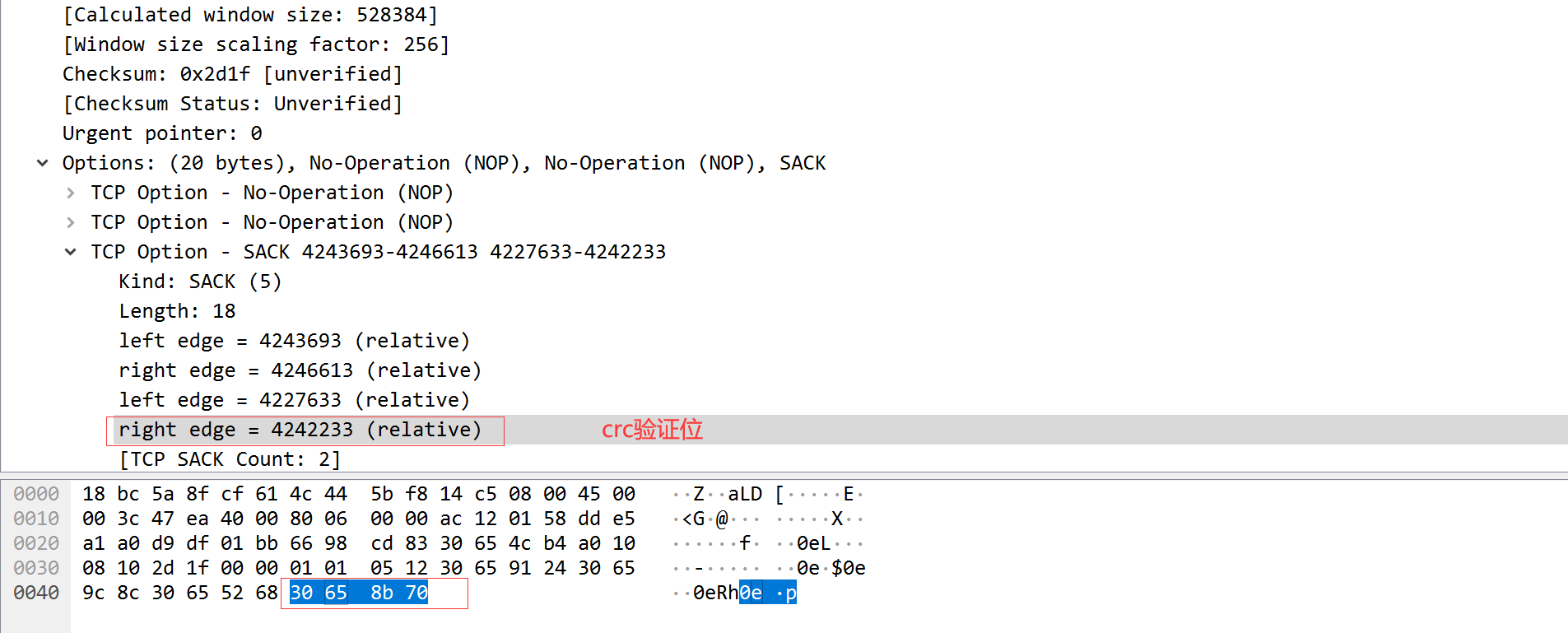
总数据:74 以太网帧数据大小:64-1518字节
2.3 尾部封装
已废弃,不在举例说明使用
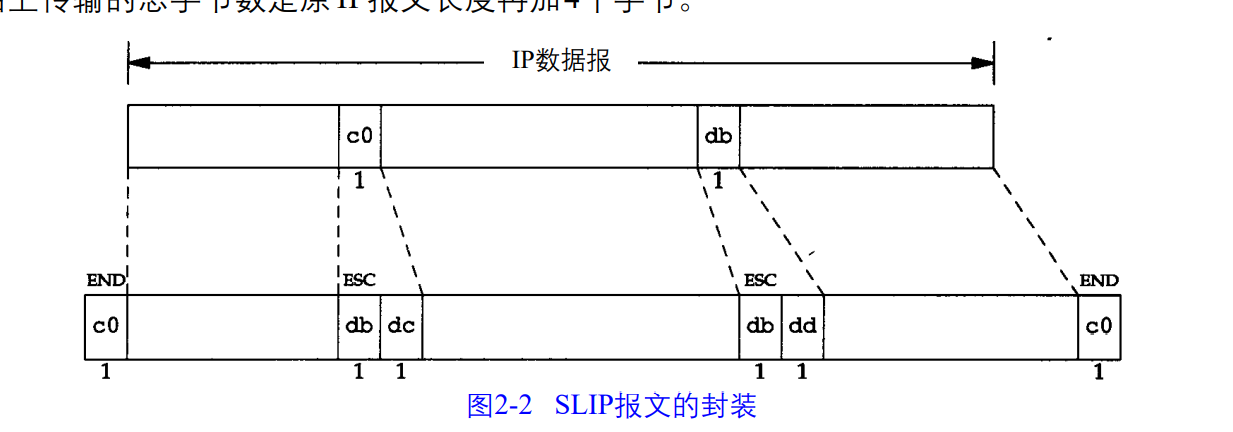
2.4SLIP:串行线路IP
SLIP是一个简单的帧封装方法,缺陷有:
1)每一端都必须知道对方的IP地址。没有办法把本端的IP地址通知给另一段。
2)数据帧中没有类型字段,如果一条串行线路使用SLIP,那么它不能同时使用其他协议
3)SLIP没有在数据帧上加入校验和,必须由上层协议提供某种形式CRC校验
2.5压缩的SLIP
2.6 PPP:点对点协议
PPP修改了SLIP协议中的所有缺陷(所以现在还有用SLIP协议的站嘛?)
最大特点每一帧都以标志字符0x7e开始和结束,紧接着是一个地址字节,值始终为0xff,然后是一个值为0x03的控制字节
1.PPP支持数据为8位和无奇偶校验的异步模式,还支持面向比特的同步链接。
2.建立、配置及测试数据链路的链路控制协议,通过双方协商,确定不同选项。
3.针对不同的网络层协议的网络控制协议体系,IP NCP允许双方商定是否对报文头部进行压缩。
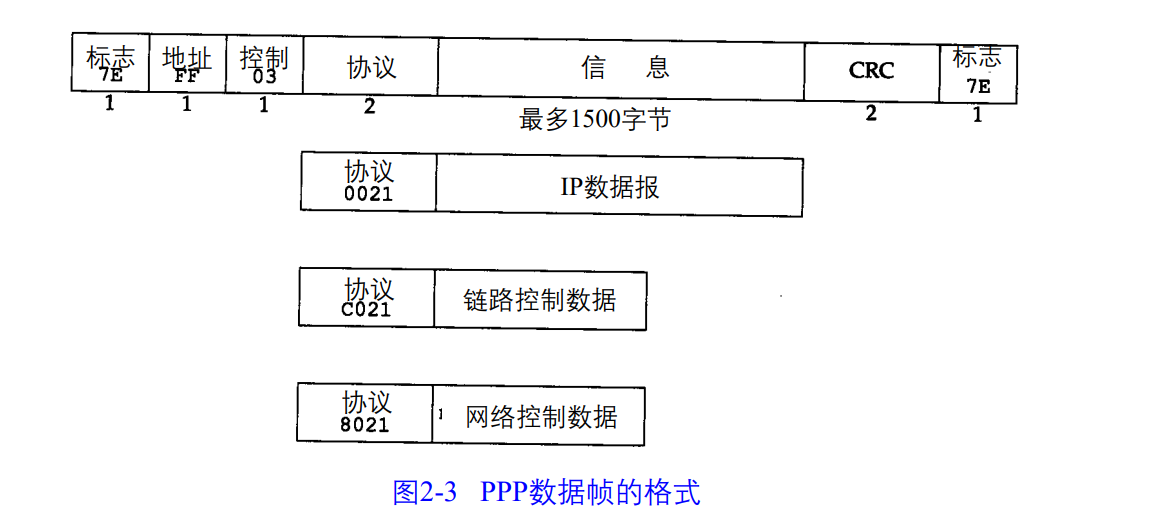
协议字段:
0x0021:信息字段是一个IP数据报
0xc021:信息字段是链路控制数据
0x8021:信息字段是网络控制数据
2.7 环回接口
2.8 最大传输单元MTU
当IP层的一个数据报长度比链路层的MTU还大,那么IP层就需要进行分片,将数据包分成若干片。
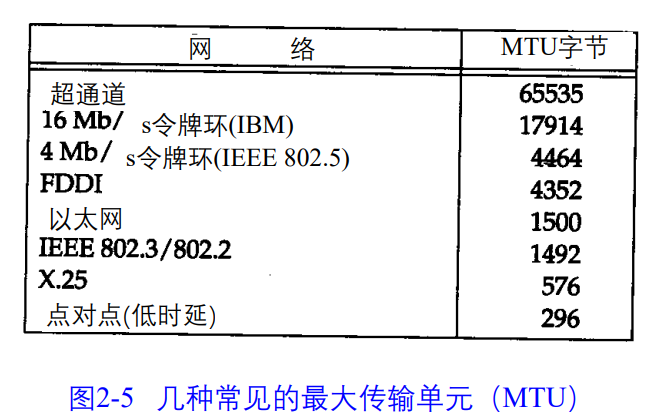
点对点的链路层(如SLIP与PPP)的MTU非网络媒体的物理特性,而是逻辑限制。
2.9 路径MTU
两台通信主机路径中的最小MTU,被称为路径MTU。两台主机之间的MTU不一定是常数,取决于当时选择的路由,且选路不一定是对称的。
2.10串行路线吞吐量计算
1s=1000ms毫秒
1ms毫秒=1000us微妙
1us微秒=1000ns纳秒
线路速度 9600 b/s,一字节8bit,+起始bit和停止bit。线路速度960 B/s(字节/秒),传输一个1024字节 1066ms
9600/(8+2)=960 B/s
1024/960=1.066s=1066ms。
当有另外一个应用程序如FTP发送或接收1024字节的数据。
最坏的情况:FTP刚刚启动,正在传送第一个字节,那么交互式应用程序需要等待1066ms,在FTP传送完毕之后才能发送自己的分组数据
最好的情况:FTP正在传送最后的一个字节,那么交互式应用程序就不需要等待,就可以传送自己的分组数据
平均起来,就是533ms
第三章:网际协议
3.1引言
IP协议特点:
1.不可靠
ip不能保证ip数据报能成功的到达目的地,仅提供传输服务。
通过丢弃该数据包,发送ICMP消息给信源端,由上层协议提供可靠性。
2.无连接
IP不维护任何后续数据报的状态信息。每个数据报的处理都是相互独立的,IP数据报可以不按发送顺序接受。
3.2 IP首部
普通IP首部长20字节,基本结构如下:
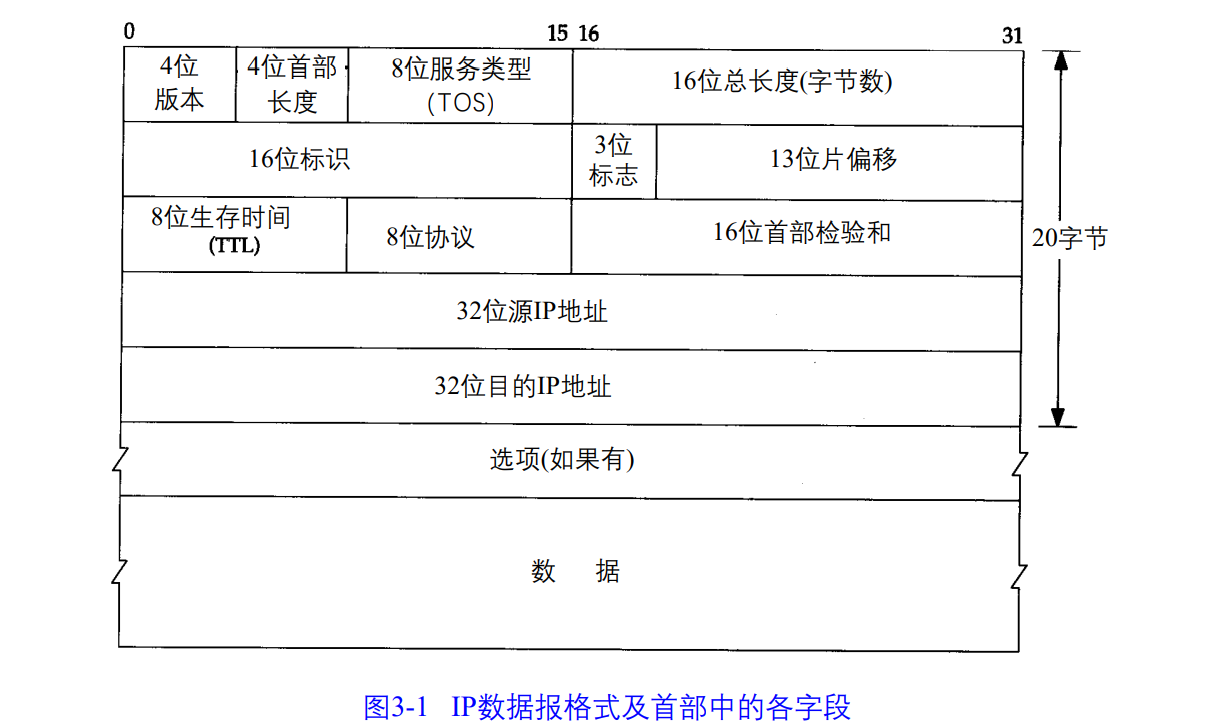
最高位在左边,记为0bit;最低位在右边,记为31bit。
4字节的32bit以下面的次序传输,0-7bit,8-15bit,16-23bit,24-31bit。该传输次序被称为big endian字节序,TCP/IP首部所有二进制数在网络传输的时候都要求这种次序,所以又被称为网络字节序。
网络字节序与主机字节序
不同的CPU有不同的字节序类型 这些字节序是指整数在内存中保存的顺序 这个叫做主机序
最常见的有两种
1. Little endian:将低序字节存储在起始地址
2. Big endian:将高序字节存储在起始地址
以其他形式存储二进制整数的机器,必须在传输数据之前把首部转换成网络字节序。
首部信息分片讲解:
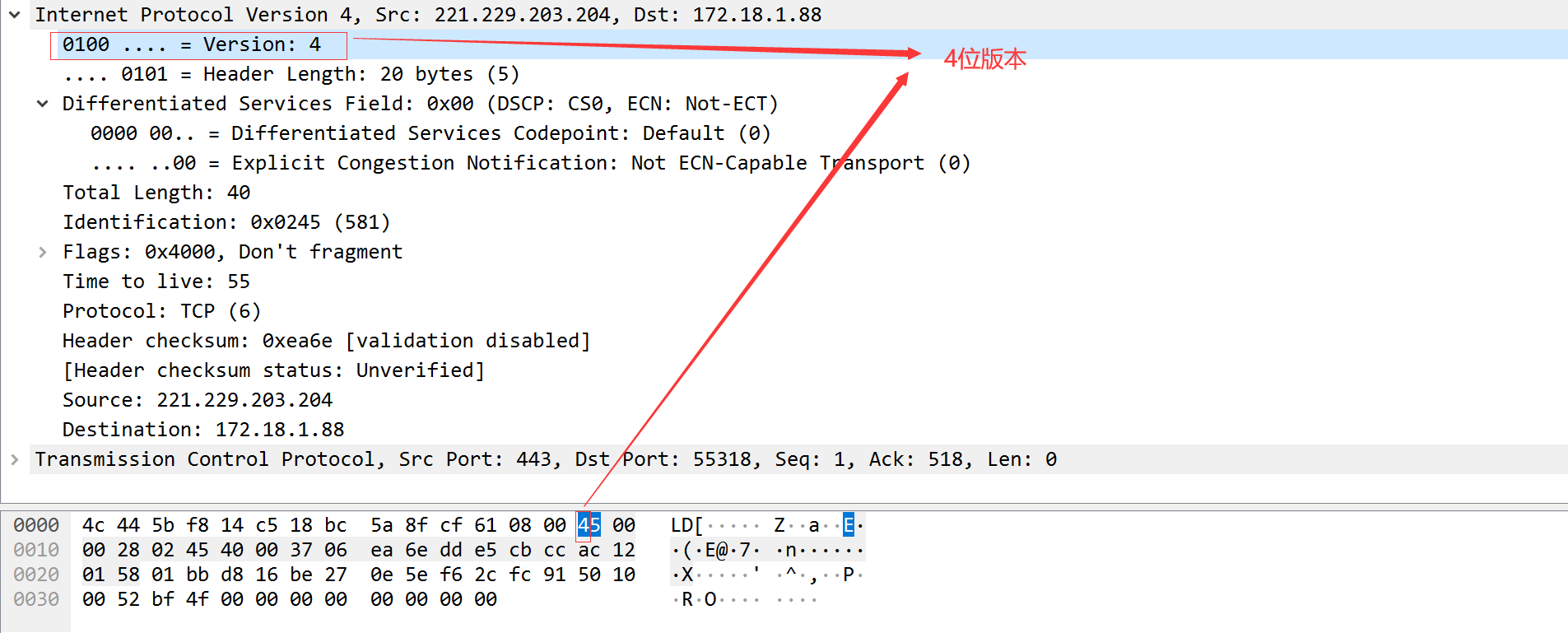
4位版本:目前协议版本号为4,即常说的IPv4
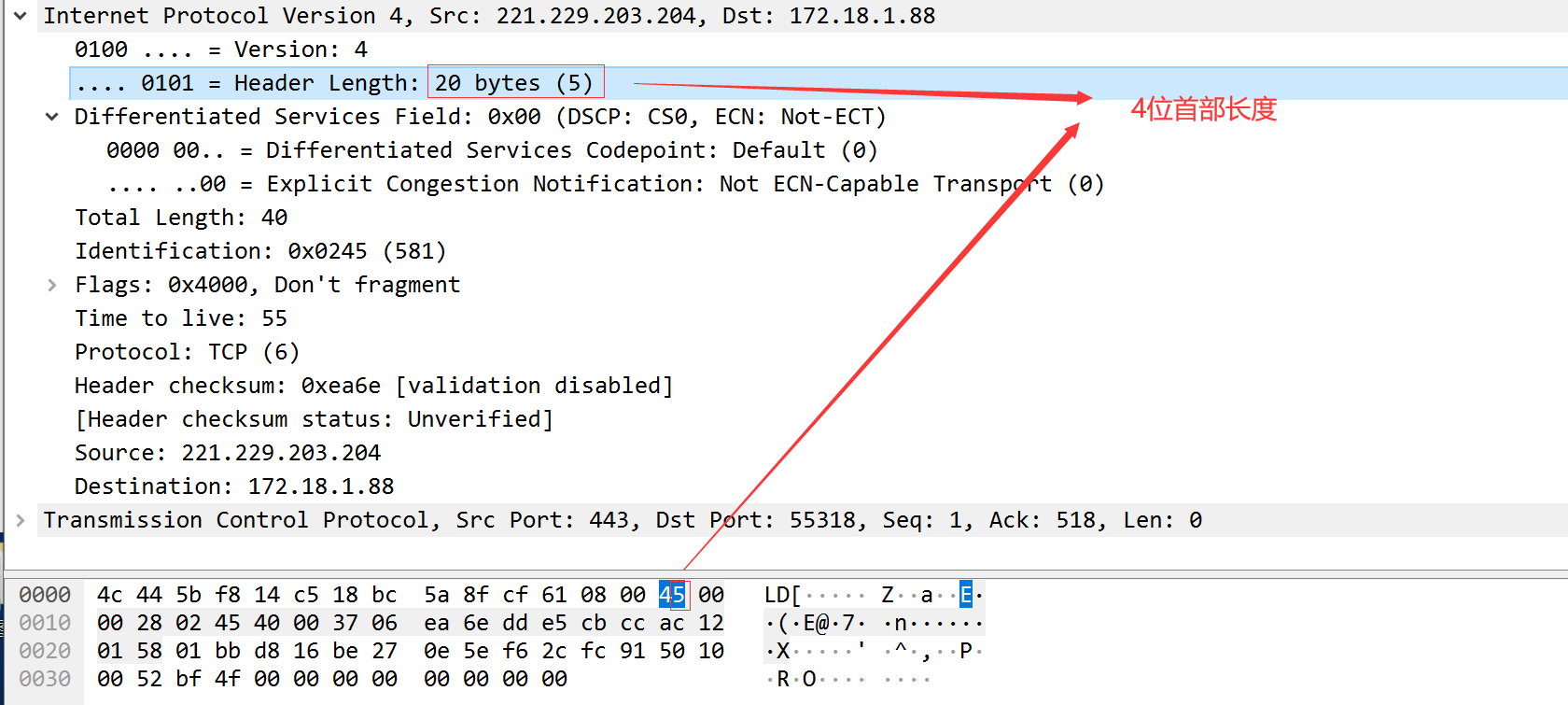
4位首部长度:首部长度指的是首都占32bit字的数目,包括任何选项,由于其是一个4比特字段,所以首部长度最长位60个字节。 32bit=4字节,占4bit最大表示数为1111 (二进制)=15。15*4=60字节,普通ip数据报字段的值是5。
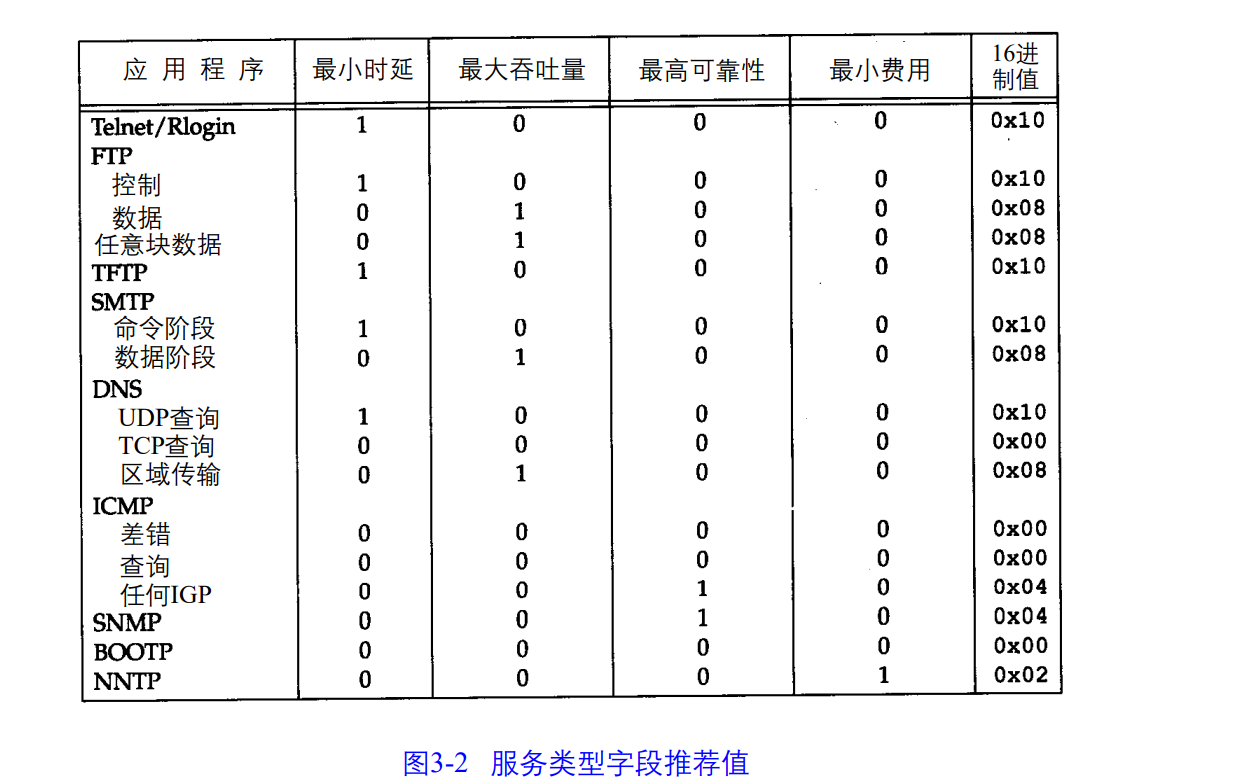
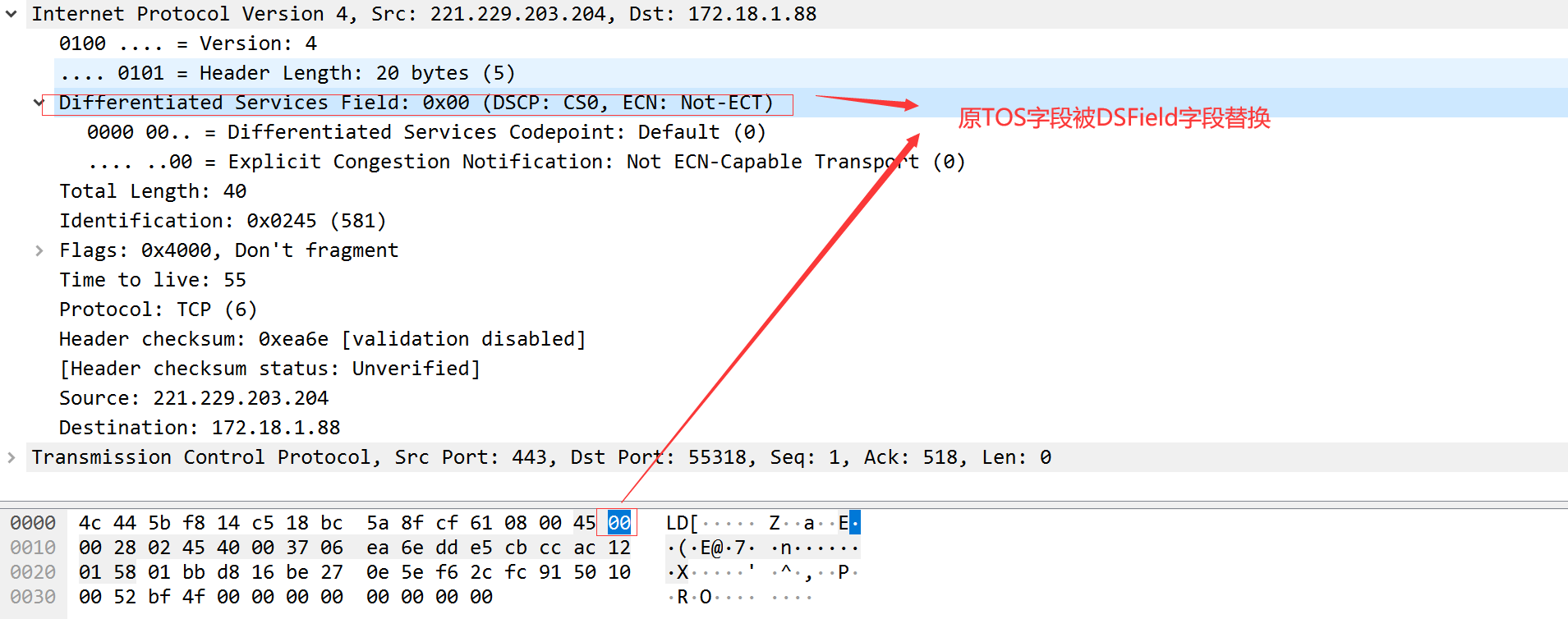
服务类型(TOS)包括一个3bit的有限权子字段,4bit的TOS子字段和1 bit未用位但必须置。4bit的TOS分别代表:最小时延、最大吞吐量、最高可靠性和最小费用。4bit中只能置其中1bit。如果所有4bit均为0,代表一般服务。
下图是根据不同应用提供的建议TOS值。(由于该书成书年代比较久远,所以值不一定一一对应,我个人抓的SNMP报,TOS也是0x00,网上搜该规则可能已经失效),目前IPV4服务类型(TOS)被Differentiated Services Field(DSField)替换。
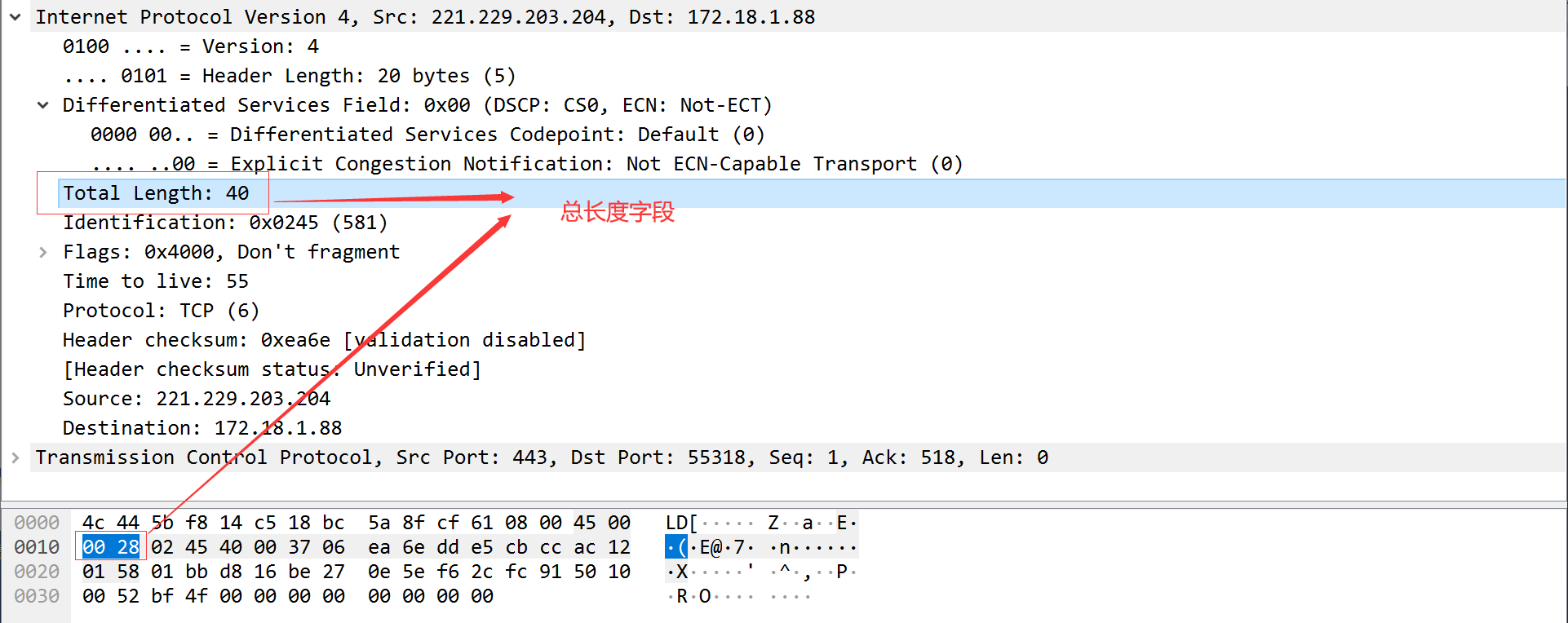
总长度字段指的是整个IP数据报的长度,以字节为单位。利用首部字段和总长度字段就可以知道IP数据报中数据内容的起始位置和长度。该字段长16bit,IP数据报最长可为65535字节,与超级通道的MTU长度一致。当数据被分片的时候,该字段值也随之变化。
尽管可以传输65535字节的IP数据报,但是大多数链路层都会对其分片。
主机也要求不能接受超过576字节的数据报,大量使用UDP的应用都会限制用户数据报长度为512字节,小于576字节。但是事实上现在大多数的实现都允许超过8192字节的IP数据报。
总长度字段是IP首部中必要的内容,一些数据链路需要填充一些数据以达到最小长度。如果没有总长度字段,IP层不知道46字节中有多少是IP数据报的内容。
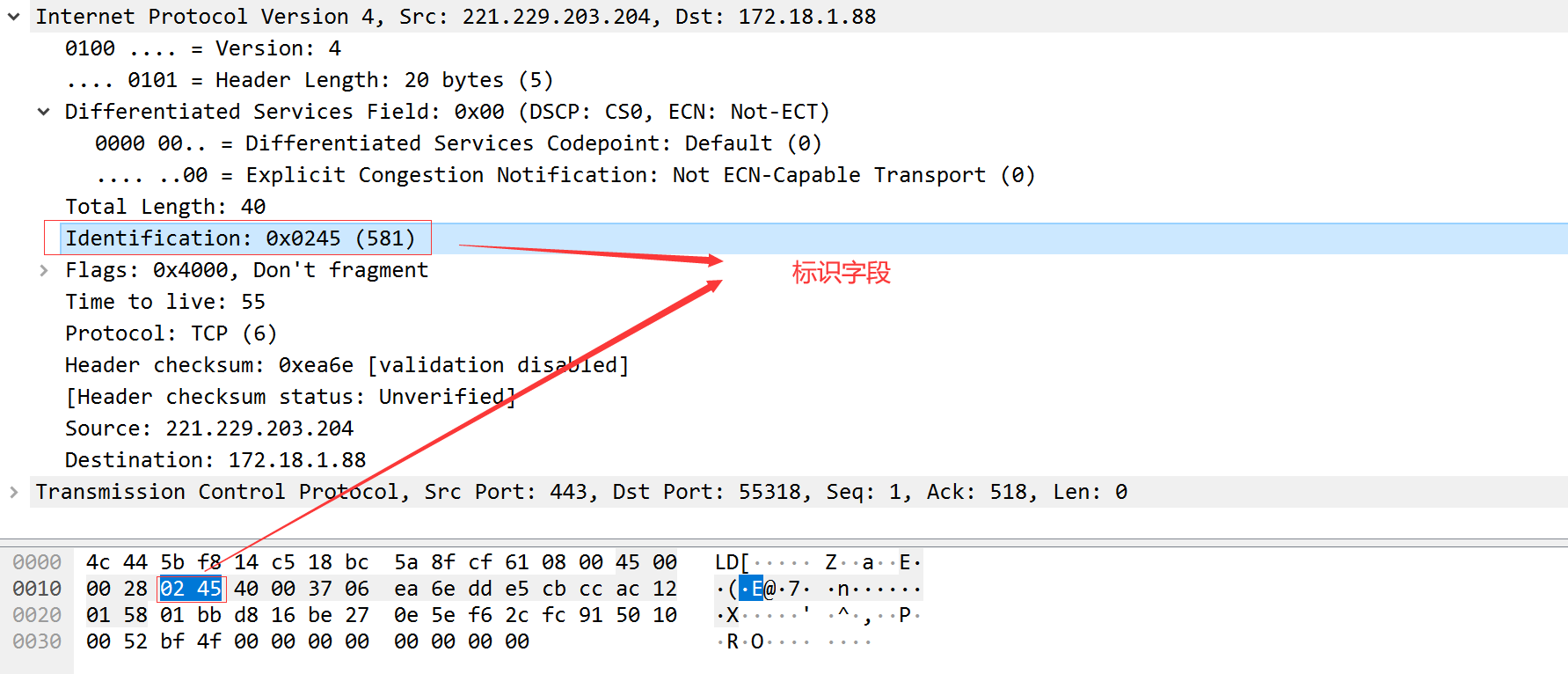
标识字段的唯一地标识主机发送的每一份数据报,每发一个报文值都会加1,用于数据的分片和重组。
在讨论分片时在讨论标志字段和片偏移字段。
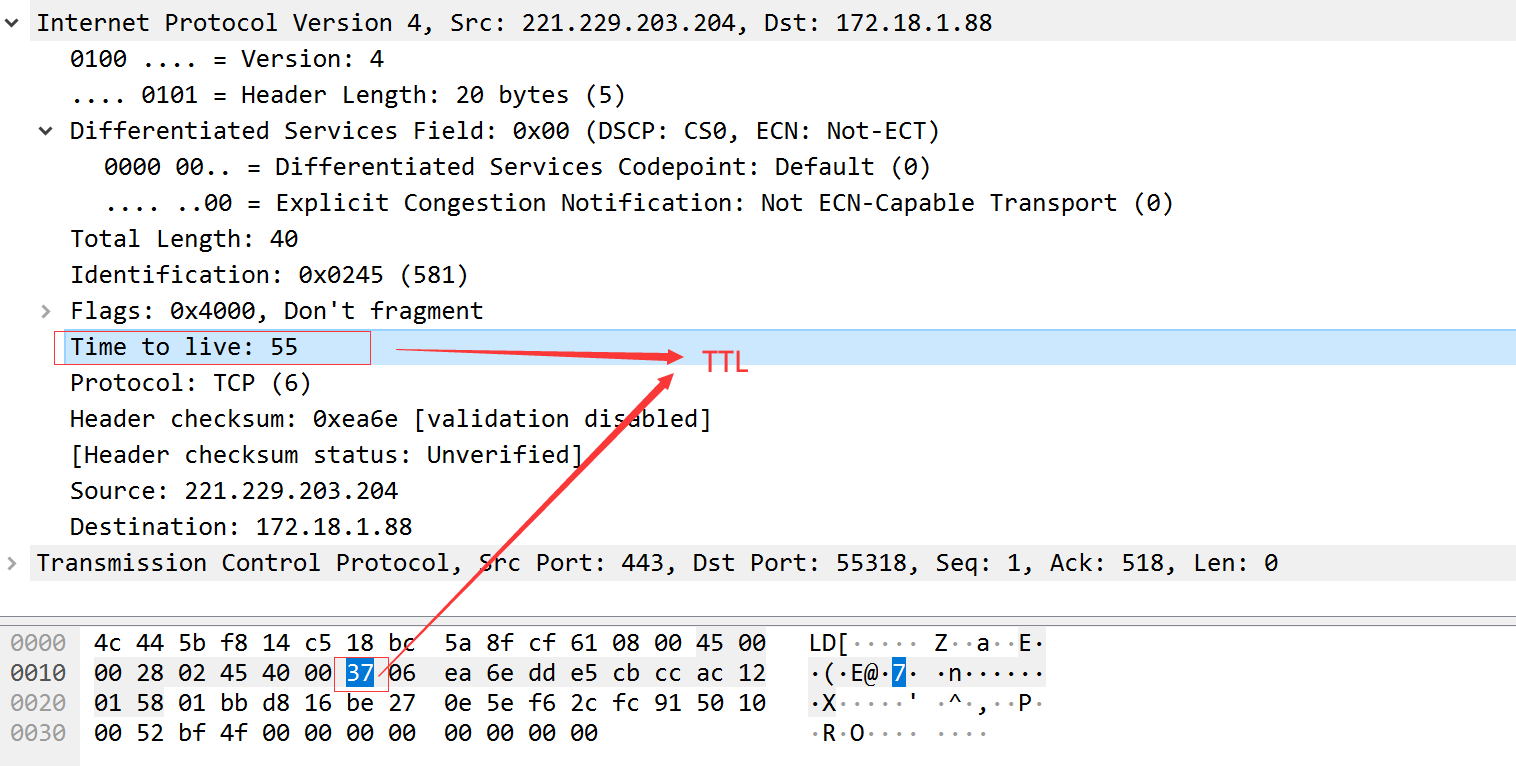
TTL生存时间字段设置了数据报可以经过的最多路由器数。指定了数据报的生存时间。TTL初始值由源主机设置(一般为32,64,128,256),该字段为0,数据报丢弃,并发送ICMP报文通知源主机。
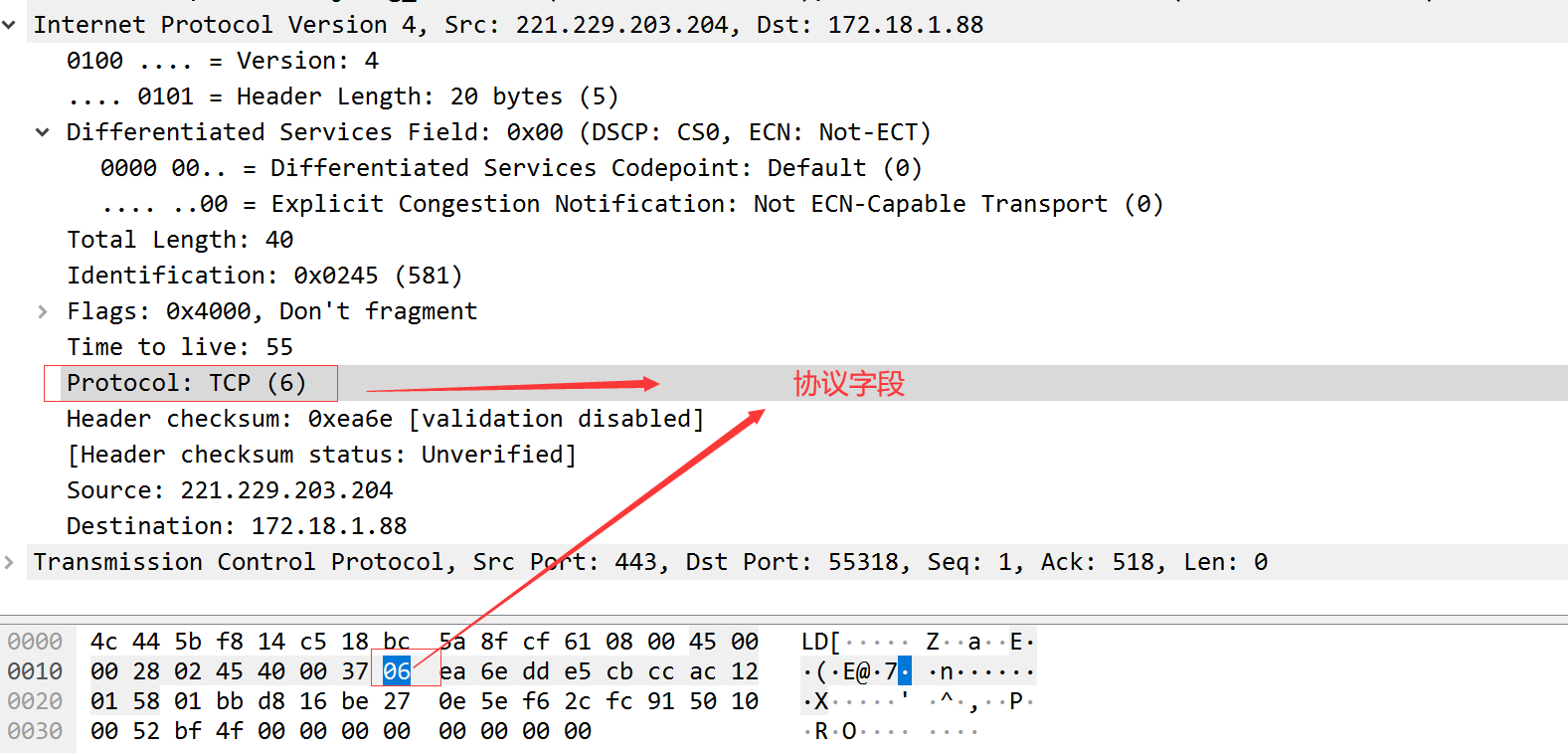
协议字段可以识别时那个协议向IP发送数据。
首部校验和字段时更具IP根据计算的校验和码,不对首部后面的数据进行计算。ICMP\IGMP\UDP和TCP在各自的首部均罕有同时覆盖首部和数据校验和码。
校验方法:
IP/ICMP/IGMP/TCP/UDP等协议的校验和算法都是相同的,算法如下:
在发送数据时,为了计算IP数据包的校验和。应该按如下步骤:
(1)把IP数据包的校验和字段置为0;
(2)把首部看成以16位为单位的数字组成,依次进行二进制反码求和;
(3)把得到的结果存入校验和字段中。
在接收数据时,计算数据包的校验和相对简单,按如下步骤:
(1)把首部看成以16位为单位的数字组成,依次进行二进制反码求和,包括校验和字段;
(2)检查计算出的校验和的结果是否等于零(反码应为16个0);
(3)如果等于零,说明被整除,校验是和正确。否则,校验和就是错误的,协议栈要抛弃这个数据包。
1. 原码
将一个整数转换成二进制形式,就是其原码。例如short a = 6; a 的原码就是0000 0000 0000 0110;更改 a 的值a = -18; 此时 a 的原码就是1000 0000 0001 0010。
通俗的理解,原码就是一个整数本来的二进制形式。
2. 反码
对于正数,它的反码就是其原码(原码和反码相同);负数的反码是将原码中除符号位以外的所有位(数值位)取反,也就是 0 变成 1,1 变成 0。例如short a = 6; a 的原码和反码都是0000 0000 0000 0110;更改 a 的值a = -18; 此时 a 的反码是1111 1111 1110 1101。
3. 补码
对于正数,它的补码就是其原码(原码、反码、补码都相同);负数的补码是其反码加 1。例如short a = 6; a 的原码、反码、补码都是0000 0000 0000 0110;更改 a 的值a = -18; 此时 a 的补码是1111 1111 1110 1110。

每一个IP数据报都包含源IP地址和目的IP地址,都是32bit的值。
最后一个字段时任选项,是数据报中的一个可变长的可选信息。
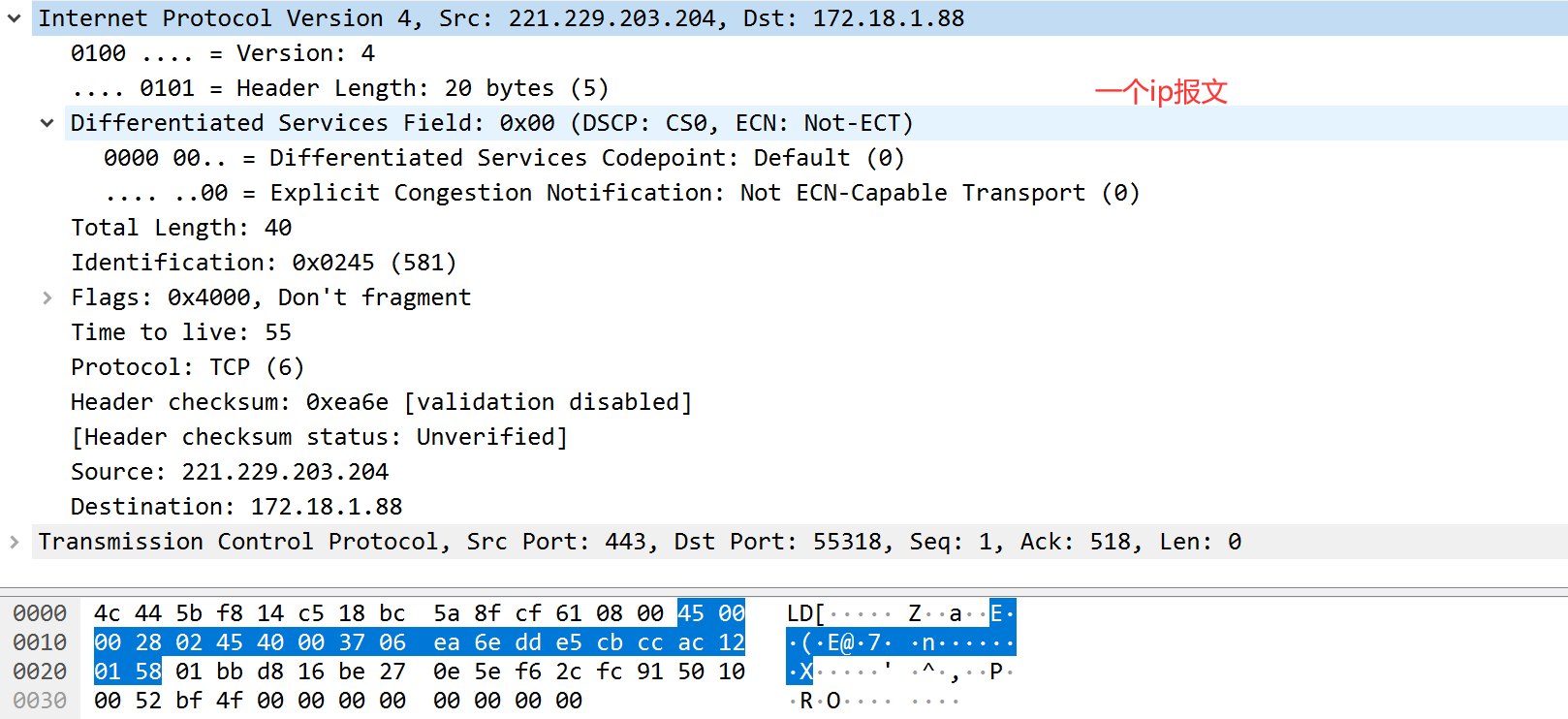

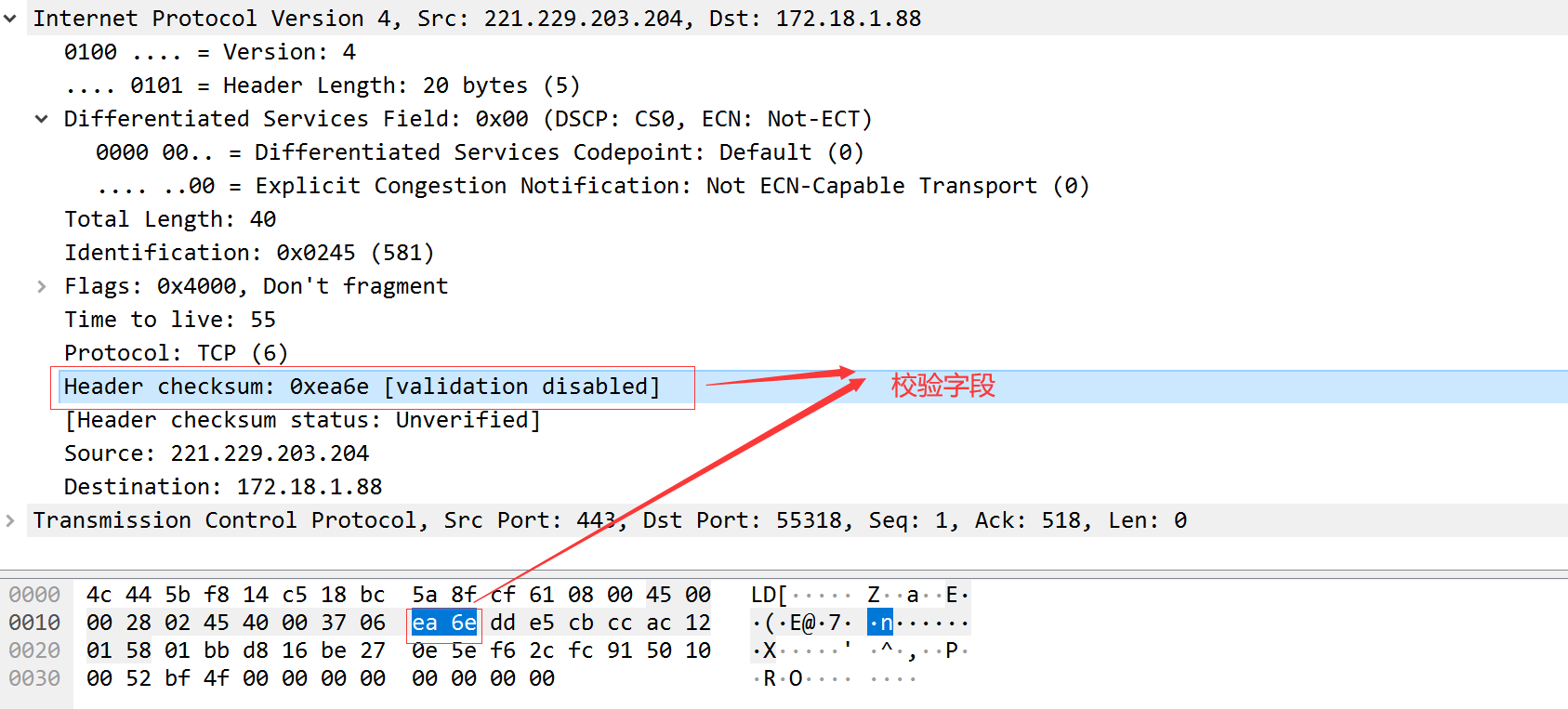
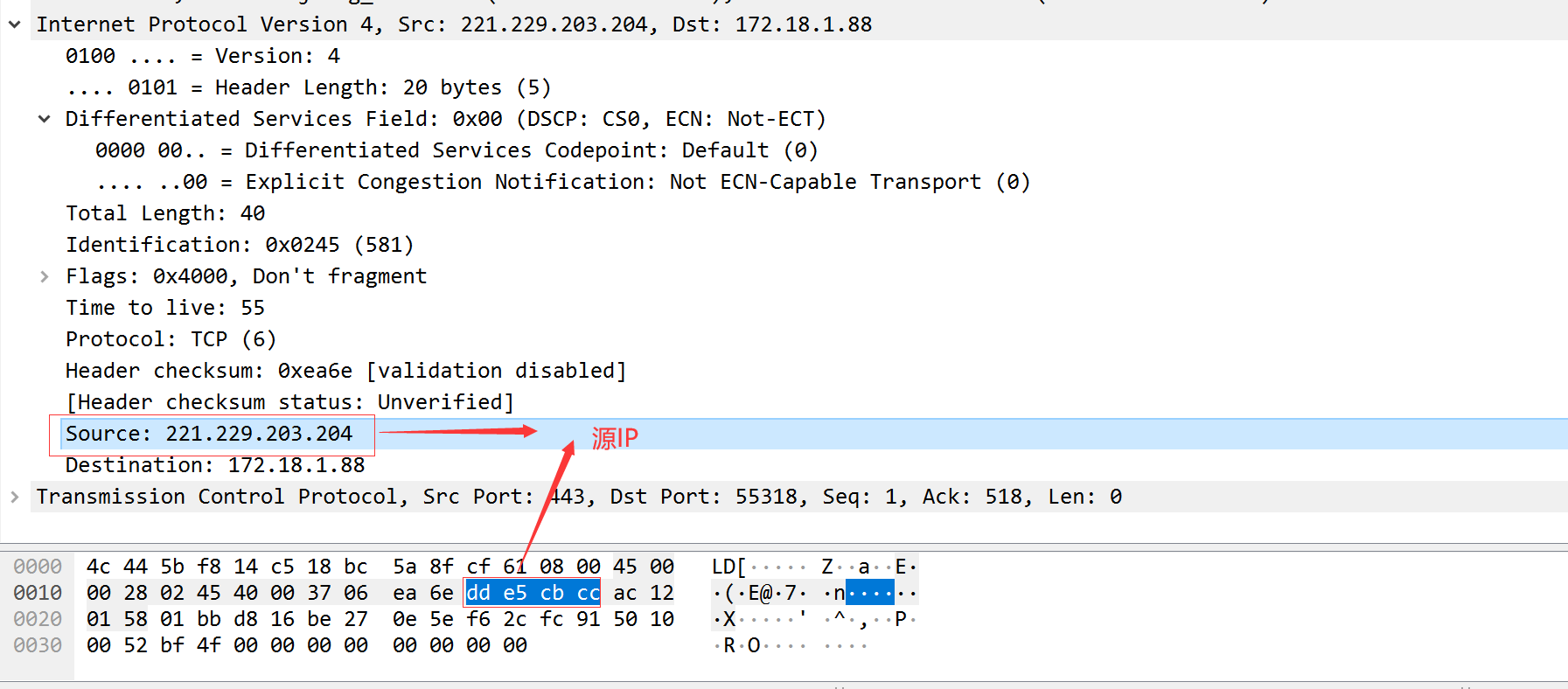
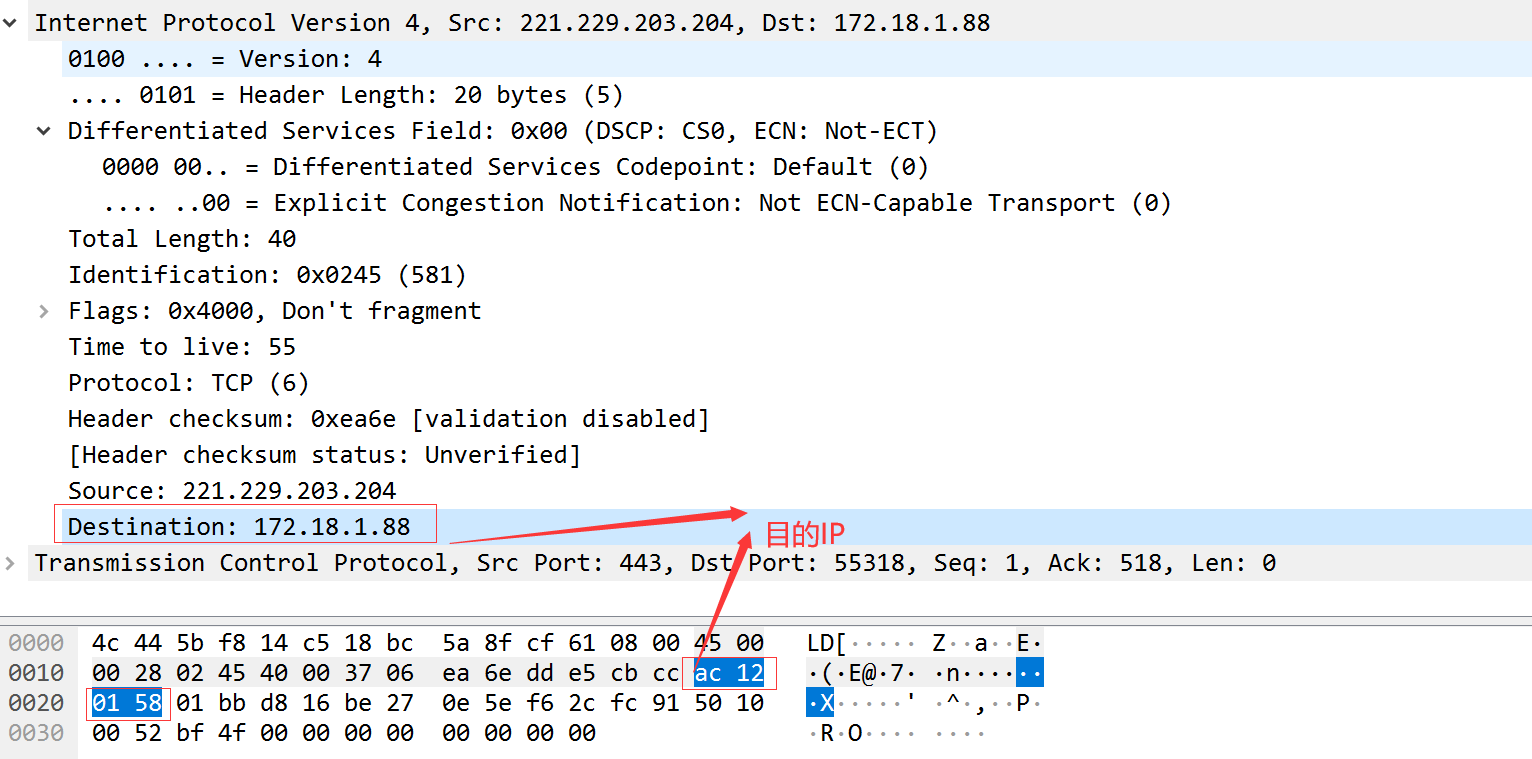
校验计算示例
45 00 00 28 02 45 40 00 37 06 ea 6e dd e5 cb cc ac 12 01 58
ea 6e为校验位 先置0
45 00 00 28 02 45 40 00 37 06 00 00 dd e5 cb cc ac 12 01 58
16位转换
45 00 = 0100010100000000 反码:0100010100000000
00 28 = 0000000000101000 反码:0000000000101000
02 45 = 0000001001000101 反码:0000001001000101
40 00 = 0100000000000000 反码:0100000000000000
37 06 = 0011011100000110 反码:0011011100000110
00 00 = 0000000000000000 反码:0000000000000000
dd e5 = 1101110111100101 反码:1010001000011010
cb cc = 1100101111001100 反码:1011010000110011
ac 12 = 1010110000010010 反码:1101001111101101
01 58 = 0000000101011000 反码:0000000101011000
3.3 IP路由选择
直连情况下,IP数据报直接送到目的主机上。否则,主机将数据报发往一默认的路由器上。
根据路由表逐跳传输数据。
路由表信息:目的IP地址,下一跳路由器的IP地址,标志。数据报的传输网络接口。
3.4子网寻址
3.5子网掩码
用于划分子网
3.6 特殊IP
3.7 一个子网例子
3.8 ifconfig命令
3.9 netstat命令
第四章:ARP:地址解析协议
4.1引言
为IP地址与对应的硬件地址之间提供动态映射。
第五章:RARP:逆地址解析协议
第六章 ICMP:Internet控制报文协议
6.1引言
ICMP是IP层的一个组成部分,在IP数据报内部被传输。

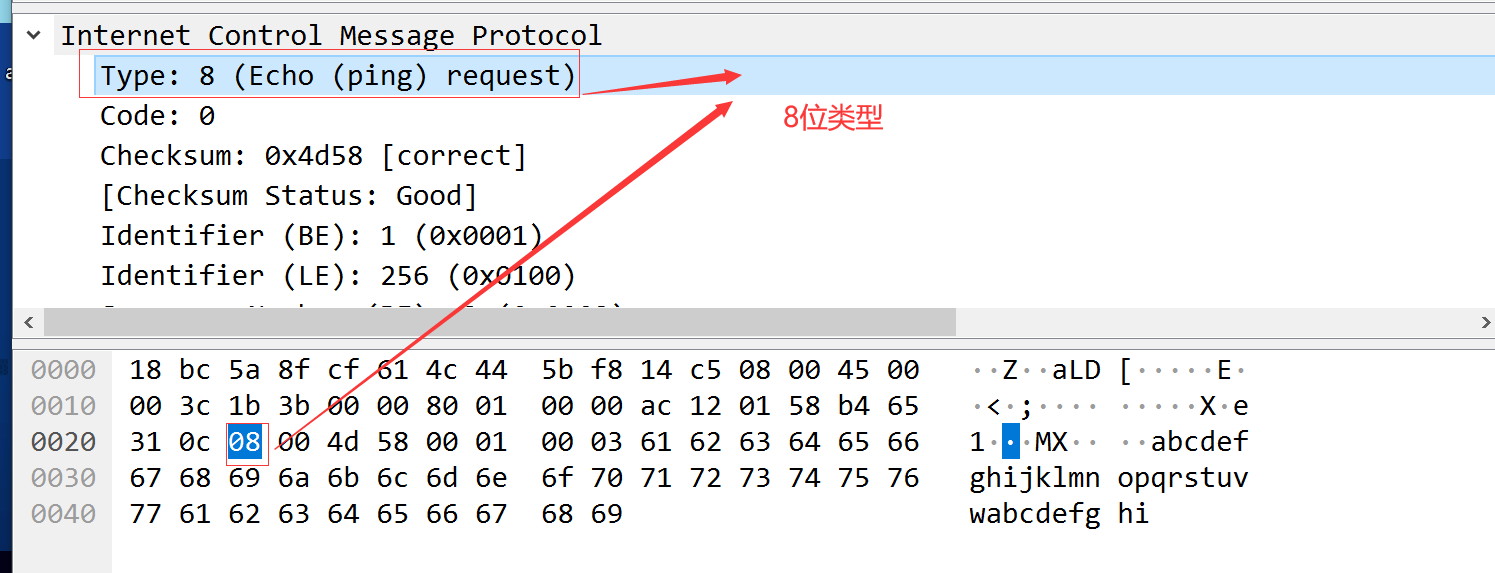
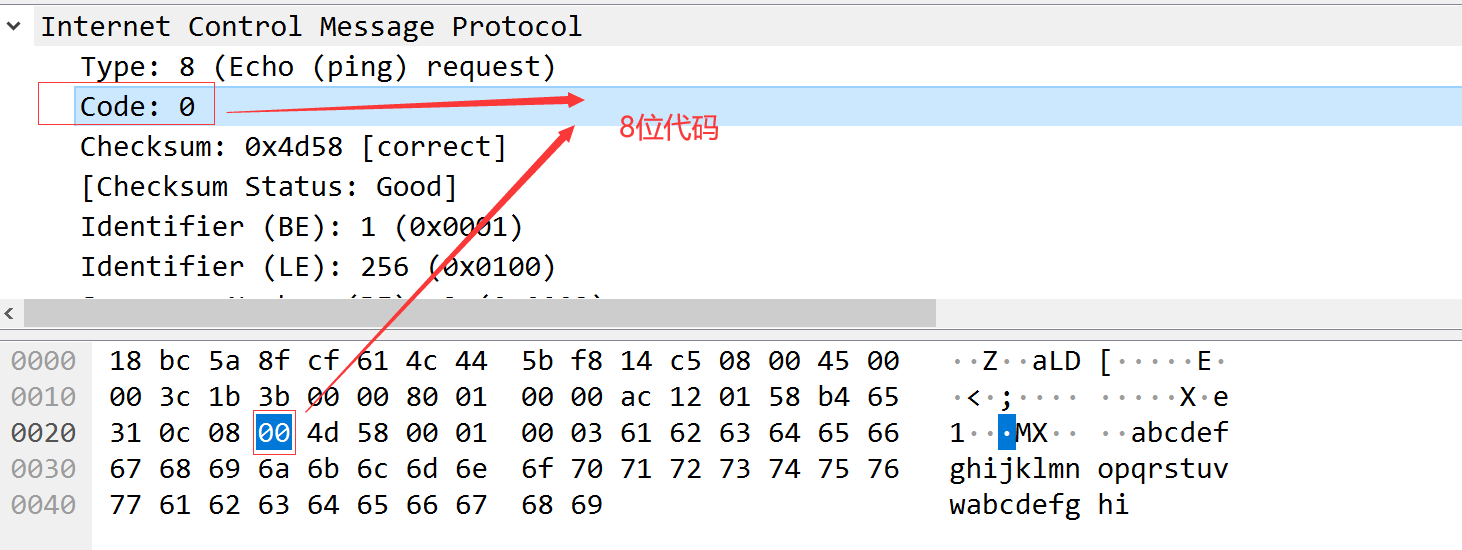
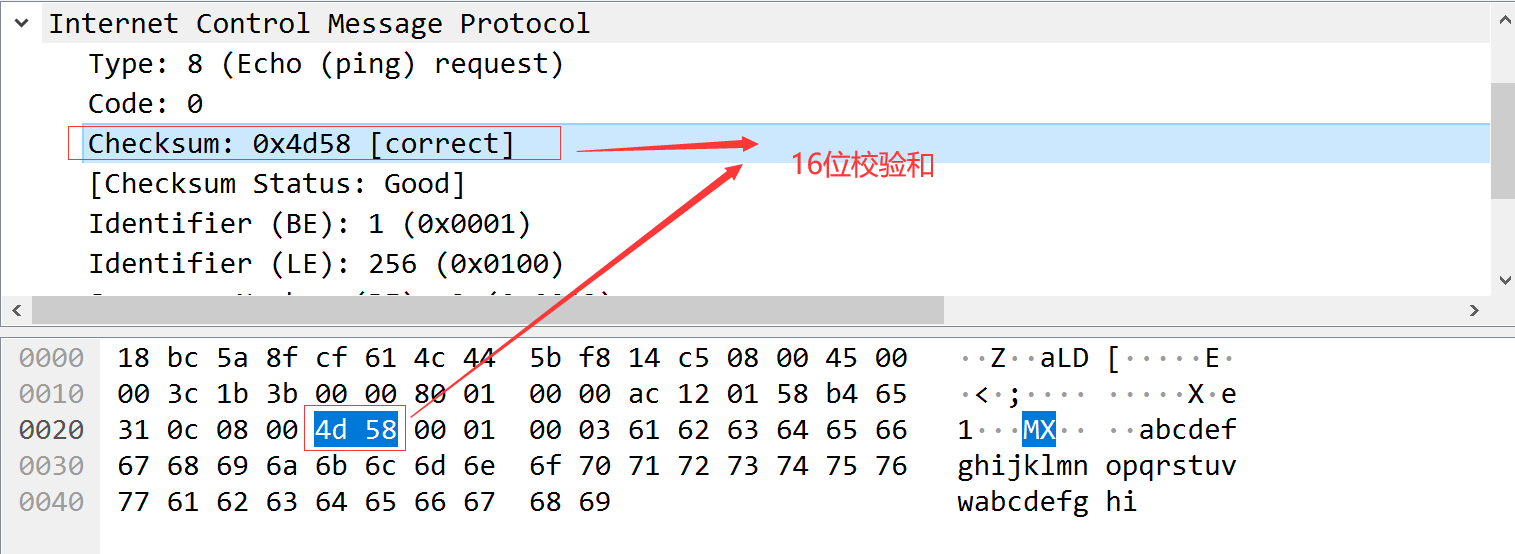
ICMP报文格式如下

所有报文的前4个字节都是一样的,但是剩下其他字节则互不相同。
类型字段可以有15个不同的值,描述特定类型的ICMP报文,某些ICMP报文还使用代码字段的值来进行进一步描述不同的条件。检验和字段覆盖整个ICMP报文。算法与IP首部校验算法相同。
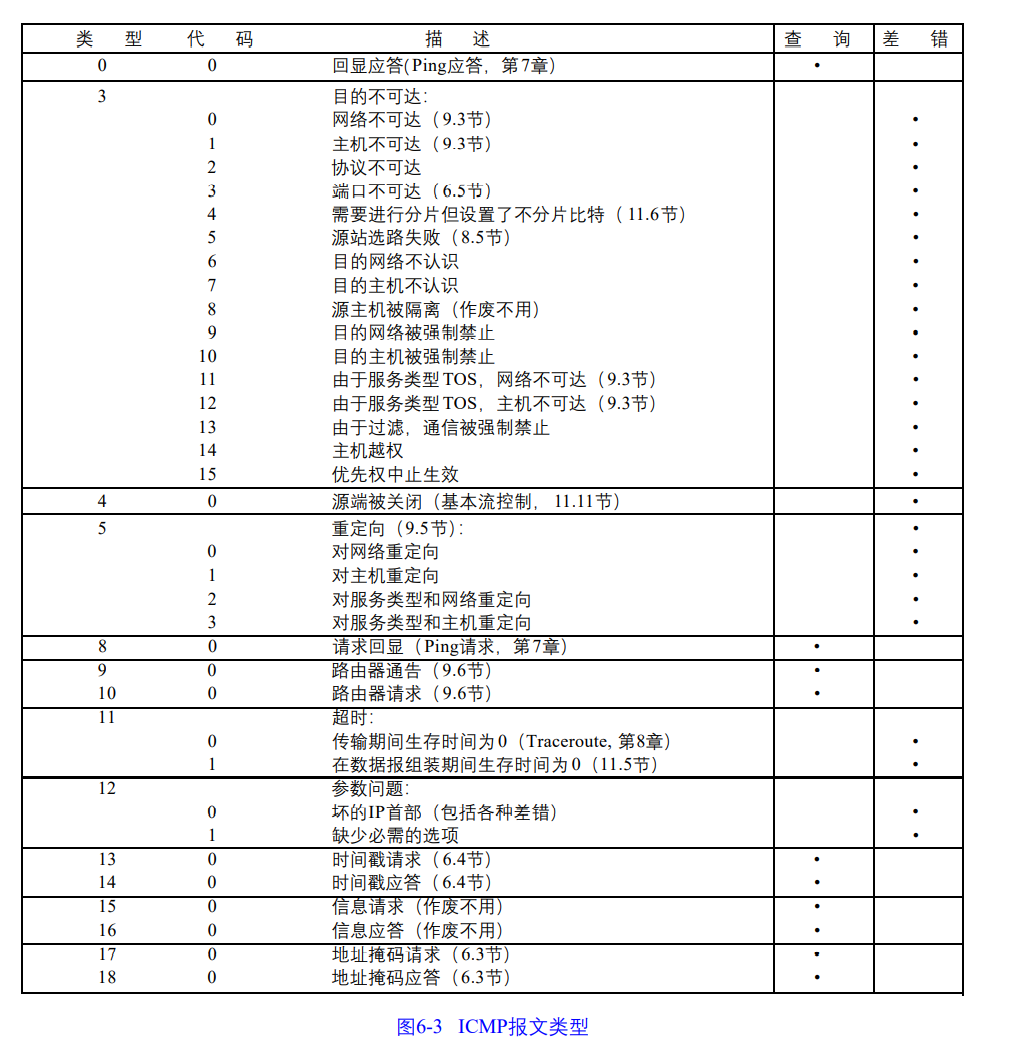
6.2 ICMP报文类型
ICMP的报文类型由报文中的类型字段和代码字段共同决定,最后两列表明ICMP是查询报文还是差错报文,对ICMP的差错报文有时需要特殊处理,因此要注意区分。
ICMP的差错报文,报文总是包含IP的首部和产生ICMP差错报文
下列5种情况不会产生ICMP差错报文。
1)ICMP差错报文(但是,ICMP查询报文可能会产生ICMP差错报文)。
2)目的地址是广播地址(见图3-9) 或多播地址(D类地址,见图1-5)的IP 数据报。
3)作为链路层广播的数据报。
4)不是IP分片的第一片(将在11.5节介绍分片)。
5)源地址不是单个主机的数据报。这就是说,源地址不能为零地址、环回地址、广播地址或多播地址
为了防止ICMP差错报文对广播分组响应所带来的广播风暴。
广播风暴(broadcast storm)简单的讲是指当广播数据充斥网络无法处理,并占用大量网络带宽,导致正常业务不能运行,甚至彻底瘫痪,这就发生了“广播风暴”。一个数据帧或包被传输到本地网段 (由广播域定义)上的每个节点就是广播;由于网络拓扑的设计和连接问题,或其他原因导致广播在网段内大量复制,传播数据帧,导致网络性能下降,甚至网络瘫痪,这就是广播风暴。
6.3 ICMP地址掩码请求与应答
ICMP地址掩码请求用于无盘系统在引导过程中获取自己的子网掩码Icmp地址掩码请求用于无盘系统在引导过程中获取自己的子网掩码
6.4 ICMP时间戳请求与应答
6.5 ICMP端口不可达差错(没看懂)
UDP的规则之一是,如果收到一份UDP数据报而目的端口与某个正在使用的进程不相符,那么UDP返回一个ICMP不可达报文。可以用TFTP来强制生成一个端口不可达报文。
ICMP是在主机之间交换的,而不用目的端口
6.6 ICMP报文的4.4BSD处理
第七章 PING程序
7.1引言
测试另外一台主机是否可达,该程序发送ICMP回显请求报文给主机,并等待返回ICMP回显应答。
ping不同不代表服务不可用,有可能是通过防火墙等设备阻止了ICMP协议通信。
7.2 Ping程序

7.2.1 Lan输出 Ping局域网
7.2.2 Wan输出 Ping广域网
7.2.3 线路SLIP链接
7.2.4 拨号SLIP链路
7.3 IP记录路由选项
PING -R 地址 但是现在很多主机已经忽略该选项, 可以使用traceroute查看对应路由。
7.4 IP时间戳选项
习题
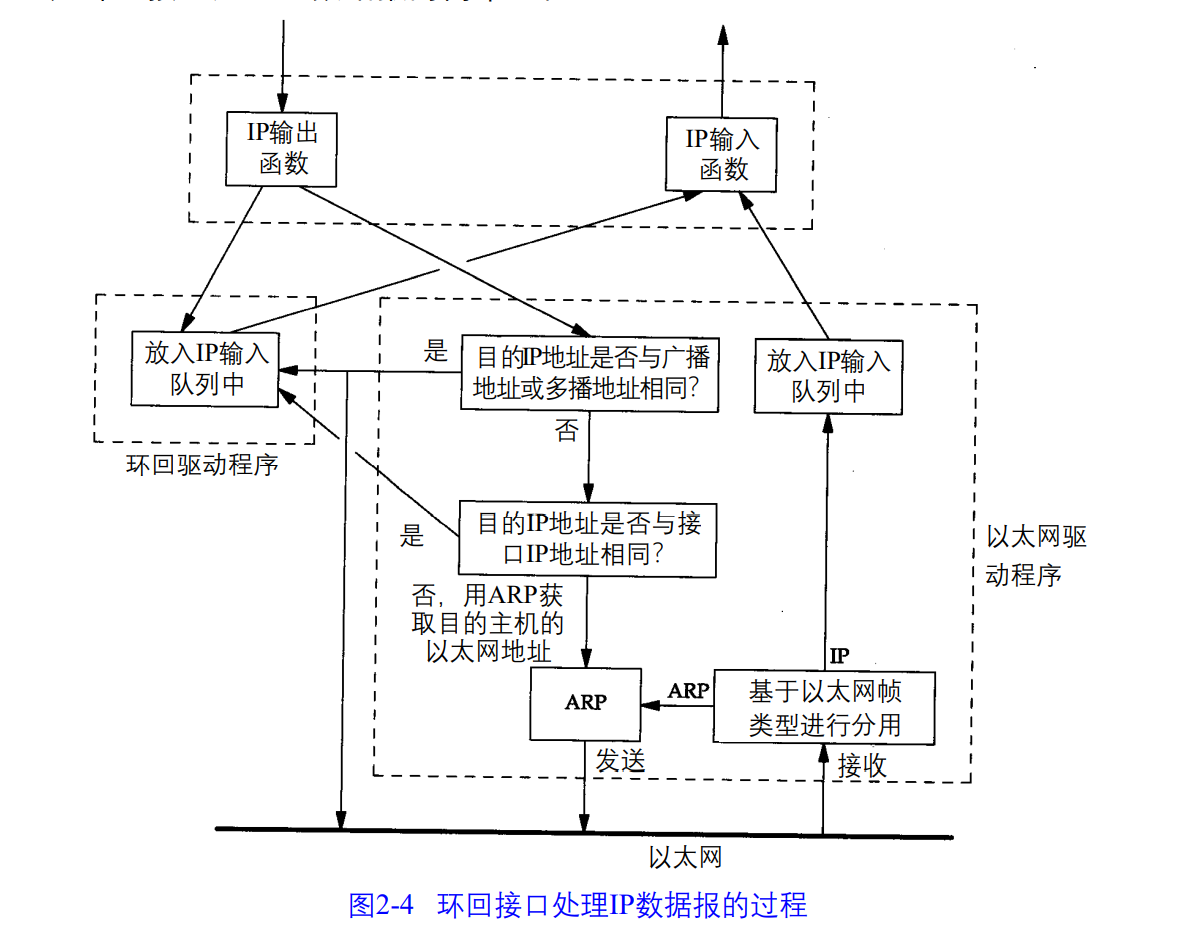
ping环回地址与ping本机地址的区别:
1.如果是环回地址 直接交给环回驱动程序处理 返回ip输入函数
2.如果不是环回地址 检查是不是广播或者多播地址
3.如果不是广播或者多播地址 才检查是不是本机地址 如果是本机地址 则交给环回驱动程序处理,环回驱动程序返回给ip输入函数
从上面可以看出 ping127.0.0.1 数据包是不经过网卡的 ping本机则是需要经过网卡的
第八章 traceroute程序
8.1 引言
Traceroute程序可以让我们看到IP数据报从一台主机传到另一台主机所经过的路由。
8.2 Traceroute程序的操作
window是tracert。
traceroute程序使用ICMP报文和IP首部中的TTL字段。
TTL字段的目的是防止数据报在选路时无休止地在网络中流动。
Traceroute原理:
发送一个TTL字段为1的IP数据报给目的主机,处理这份数据报的第一个路由器将TTL值减1,丢弃该数据报,并发挥一份ICMP报文,这样获取了该路径中第一个路由器的地址。然后Traceroute程序发送TTL值为2的数据报,这样获取路径中的第二个路由器的地址。继续这个过程直至该数据到达目的主机。
判断到达目的主机:
发送一份UDP报文给目的主机,选择一个不可能的值作为UDP端口号(大于30000),使目的主机任何一个应用程序都不可能使用该端口,当数据报到达时,将使目的主机的UDP模块产生一份“端口不可达‘错误的ICMP报文。Traceroute程序所要区分接受到的ICMP报文时超时还是端口不可达,判断结束时间。
8.3 局域网输出
8.4 广域网输出
8.5 IP源站选路选项
8.5.1 宽松的源站选路的traceroute程序示例
使用traceroute程序的-g选项,可以为宽松的源站选路指明一些中间路由器,采用该选项可以最多指定8个中间路由器。
8.5.2 严格的源站选路的traceroute程序实例
-G 可以观察在指明无效的严格的源站选路时其结果回事什么样子的
8.5.3 宽松的源站选路treaceroute程序的往返路由
第九章 IP选路
第十章 动态选路协议
第十一章 UDP:用户数据报协议
11.1 引言
UDP是一个简单的面向数据报的运输层协议,进程每个输出操作都正好产生一个UDP数据报,并组成一个待发送的IP数据报。
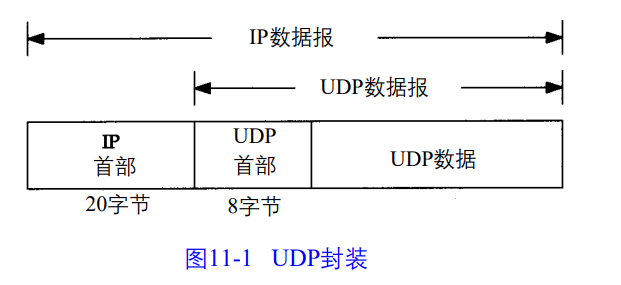
wireshark抓包示例
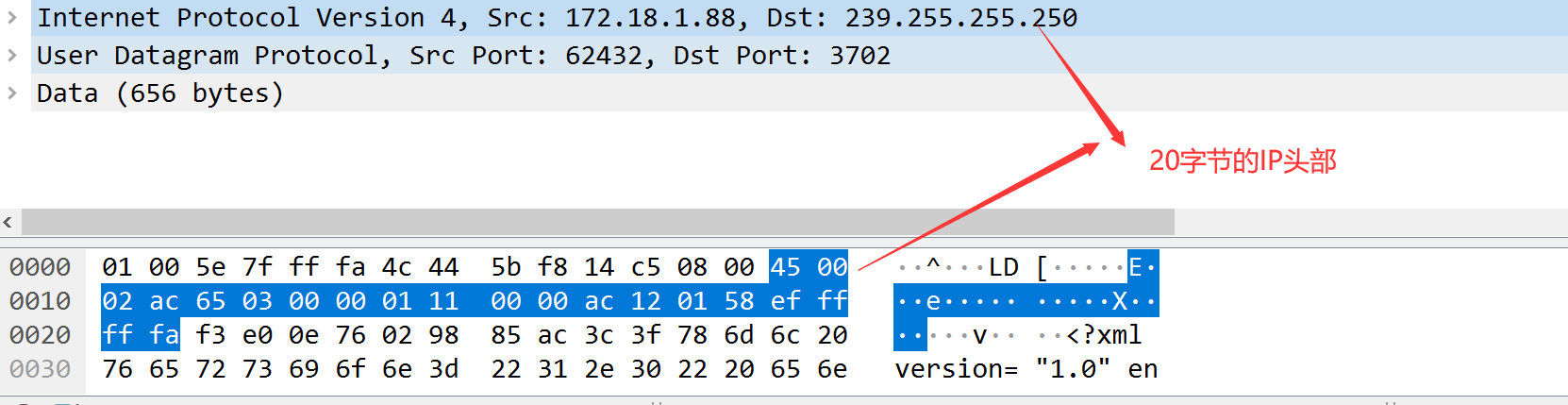
UDP不提供可靠性,他把应用程序传给IP层的数据发出去,并不保证能到达目的地。
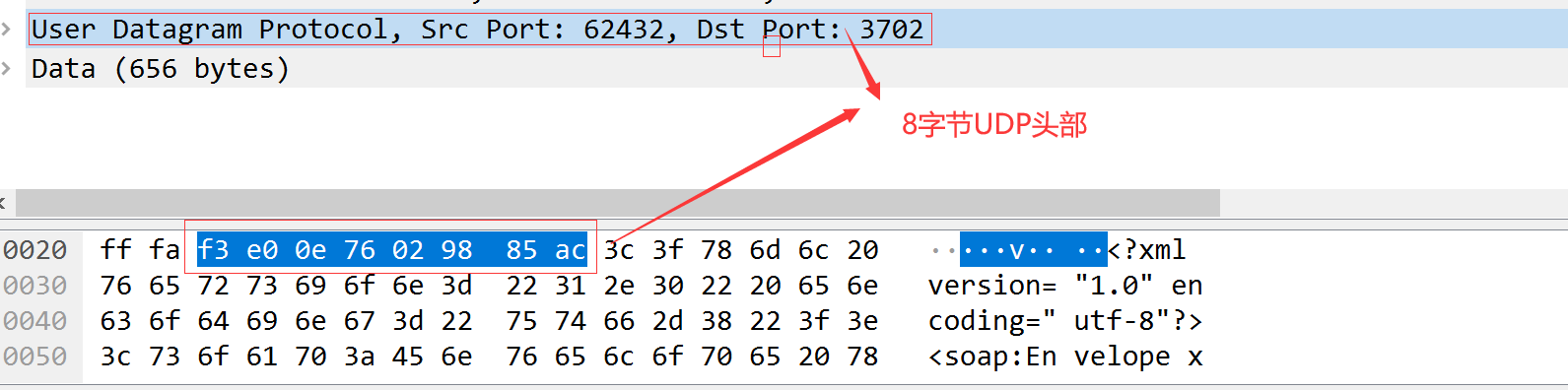
11.2 UDP首部
UDP首部各字段如图11-2所示。

wireshark抓包示例:

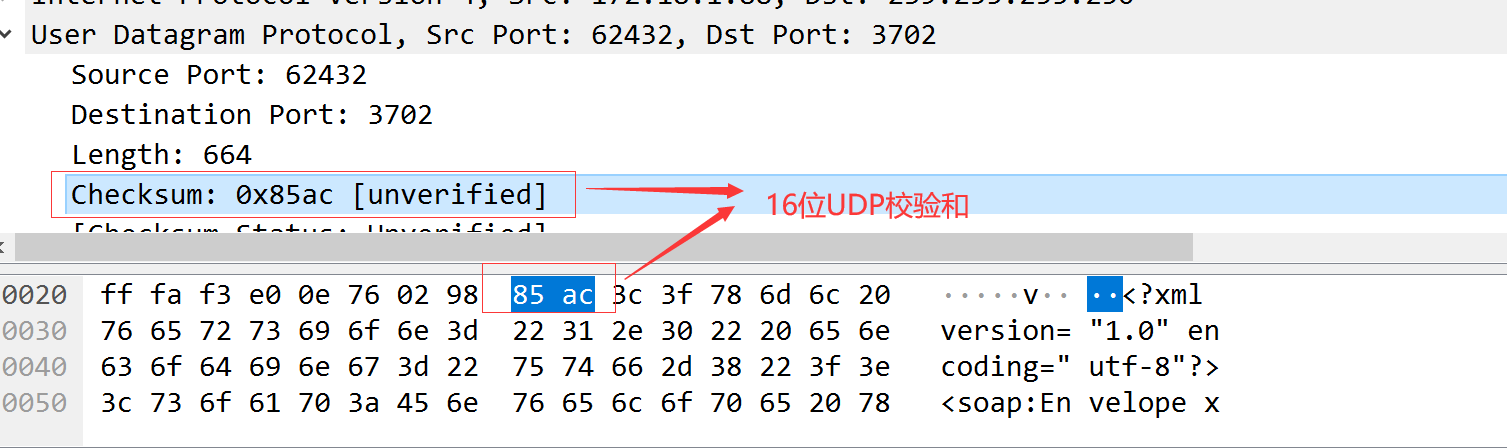
11.3 UDP校验和
UDP校验和覆盖UDP首部和UDP数据。到那时UDP的校验和是可选的,而TCP的校验和是必需的。
UDP校验和的基本计算方法和3.2介绍的IP首部校验和计算方法类似,但存在不同地方。
UDP数据报的长度可以为奇数字节,但校验和的算法是把若干个16bit字相加。解决方法是必要时在最后增加填充字节0,但只是为了校验和的计算。
UDP数据报和TCP段都有一个12字节长度的伪首部,为了计算校验和而设置的。会包含IP首部的一些字段,目的在于让UDP两次检查数据是否已经正确的到达目的地(例如,ip没有接受地址不是本主机的数据报,以及IP没有把应传给另一高层的数据报传给UDP)。
伪首部,不是真实存在于UDP报文中的,更像时从IP层继承过来的数据,也就是说在UDP报文计算校验和的时候会同时再次确认IP层数据,这样做的理由
为什么伪首部要有目的IP地址
学习过通信系统原理后,我们知道数据传输过程中会产生误码,0可能变为1,1可能变为0,并且每种校验码都有一定的查错能力,超过这个范围,就无法察觉错误了,而早期的通信环境大概比较糟糕,因此,在传输过程中出现误码,可能使IP报文的目的地址出现错误,接收主机的UDP计算校验和时,目的IP地址来自IP层,由于目的IP地址出现错误,导致发送主机计算检验和时使用的目的IP地址与接收主机计算检验和时使用的目的IP地址不同,UDP发现错误,丢弃报文
为什么伪首部要有源IP地址
为了让接收主机确认源IP地址没有出现错误。
假设我们想要开发一款基于UDP的程序,A发送UDP报文给B,B要发送回应报文给A,假设传输过程出现误码,源IP地址出现错误,则A计算检验和时使用的源IP地址与B计算校验和时使用的源IP地址不同,B就可以发现错误,从而丢弃报文,定时重传等可靠性由应用程序自己保证
为什么伪首部要有协议字段
为了确认操作系统交付给UDP的报文是UDP报文
为什么伪首部要有UDP的长度
现在想想,可能是为了防止UDP头部的长度字段出现错误,导致解析UDP报文时出现差错
再来看TCP
TCP的伪首部字段的作用和UDP完全类似,虽然操作系统会存储已经建立的TCP连接,假设伪首部没有源IP地址和目的IP地址,此时出现误码,导致接收的TCP报文刚好有对应的已建立的TCP连接,此时便会出现错误。
原文链接:https://blog.csdn.net/dhaiuda/article/details/80623150
也有说是为了加密数据的。
networking - What is the Significance of Pseudo Header used in UDP/TCP - Stack Overflow


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?