
k8s-简介
1.K8s简介
Kubenetes是一个针对容器应用,进行自动部署,弹性伸缩和管理的开源系统,K8s 作为缩写的结果来自计算“K”和“s”之间的八个字母。主要功能是生产环境中的容器编排。 K8S是Google公司推出的,它来源于由Google公司内部使用了15年的Borg系统,集结了Borg的精华。
参考文献官网:https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
主要介绍kubernetes的基本概念以及应用场景,K8s的设计理念,以及K8s能干什么不能干什么。
1.1 使用Kubernetes会收获哪些好处
- 可以“轻装上阵”地开发复杂系统
以前需要很多人(其中不乏技术达人)一起分工协作才能设计、实现和运维的分布式系统,在采用Kubernetes解决方案之后,只需一个精悍的小团队就能轻松应对。在 这个团队里,只需一名架构师负责系统中服务组件的架构设计,几名开 发工程师负责业务代码的开发,一名系统兼运维工程师负责Kubernetes 的部署和运维,因为Kubernetes已经帮我们做了很多。 - 可以全面拥抱微服务架构
微服务架构的核心是将一个巨大 的单体应用分解为很多小的互相连接的微服务,一个微服务可能由多个 实例副本支撑,副本的数量可以随着系统的负荷变化进行调整。微服务 架构使得每个服务都可以独立开发、升级和扩展,因此系统具备很高的 稳定性和快速迭代能力,开发者也可以自由选择开发技术。 - 可以随时随地将系统整体“搬迁”到公有云上
Kubernetes最 初的设计目标就是让用户的应用运行在谷歌自家的公有云GCE中,华为 云(CCE)、阿里云(ACK)和腾讯云(TKE)先后宣布支持 Kubernetes集群,未来会有更多的公有云及私有云支持Kubernetes。同 时,在Kubernetes的架构方案中完全屏蔽了底层网络的细节,基于 Service的虚拟IP地址(Cluster IP)的设计思路让架构与底层的硬件拓扑 无关,我们无须改变运行期的配置文件,就能将系统从现有的物理机环 境无缝迁移到公有云上。 - Kubernetes内在的服务弹性扩容机制可以让我们轻松应对突发流量
在服务高峰期,我们可以选择在公有云中快速扩容某些Service 的实例副本以提升系统的吞吐量,这样不仅节省了公司的硬件投入,还 大大改善了用户体验。 - Kubernetes系统架构超强的横向扩容能力可以让我们的竞争 力大大提升
我们利用Kubernetes 提供的工具,不用修改代码,就能将一个Kubernetes集群从只包含几个 Node的小集群平滑扩展到拥有上百个Node的大集群,甚至可以在线完成集群扩容。
2.K8S-组件介绍与工作流程
2.1K8s的部分核心概念
Kubernetes权威指南:从Docker到Kubernetes实践全接触/龚正等编 著.—4版.—北京:电子工业出版社
Master:
Kubernetes里的Master指的是集群控制节点,在每个Kubernetes集群 里都需要有一个Master来负责整个集群的管理和控制,基本上 Kubernetes的所有控制命令都发给它,它负责具体的执行过程,我们后 面执行的所有命令基本都是在Master上运行的。Master通常会占据一个 独立的服务器(高可用部署建议用3台服务器),主要原因是它太重要 了,是整个集群的“首脑”,如果它宕机或者不可用,那么对集群内容器 应用的管理都将失效。
master组件通常运行以下关键进程:
- Kubernetes API Server(kube-apiserver):提供了HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增、删、改、查等操作 的唯一入口,也是集群控制的入口进程。
- Kubernetes Controller Manager(kube-controller-manager): Kubernetes里所有资源对象的自动化控制中心,可以将其理解为资源对象的“大总管”。
- Kubernetes Scheduler(kube-scheduler):负责资源调度(Pod 调度)的进程,相当于公交公司的“调度室”。
另外,在Master上通常还需要部署etcd服务,因为Kubernetes里的所有资源对象的数据都被保存在etcd中。也可以搭建单独的etcd集群用以储存这些关键数据。
Node:
除了Master,Kubernetes集群中的其他机器被称为Node,在较早的 版本中也被称为Minion。与Master一样,Node可以是一台物理主机,也 可以是一台虚拟机。Node是Kubernetes集群中的工作负载节点,每个 Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机 时,其上的工作负载会被Master自动转移到其他节点上。
node组件通常运行以下关键进程:
- kubelet:负责Pod对应的容器的创建、启停等任务,同时与 Master密切协作,实现集群管理的基本功能。
- kube-proxy:实现Kubernetes Service的通信与负载均衡机制的 重要组件。
- Docker Engine(docker):容器引擎,负责本机的容器创建 和管理工作。
Node可以在运行期间动态增加到Kubernetes集群中,前提是在这个 节点上已经正确安装、配置和启动了上述关键进程,在默认情况下 kubelet会向Master注册自己,这也是Kubernetes推荐的Node管理方式。 一旦Node被纳入集群管理范围,kubelet进程就会定时向Master汇报自身 的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及当 前有哪些Pod在运行等,这样Master就可以获知每个Node的资源使用情 况,并实现高效均衡的资源调度策略。而某个Node在超过指定时间不上 报信息时,会被Master判定为“失联”,Node的状态被标记为不可用 (Not Ready),随后Master会触发“工作负载大转移”的自动流程。
kubectl get nodes可以查看集群中有多少node节点
kubectl describe node 可以查看集群中节点的详细信息
Pod:
Pod是Kubernetes最重要的基本概念,如图所示是Pod的组成示意 图,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause容器。 Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器, 每个Pod还包含一个或多个紧密相关的用户业务容器。
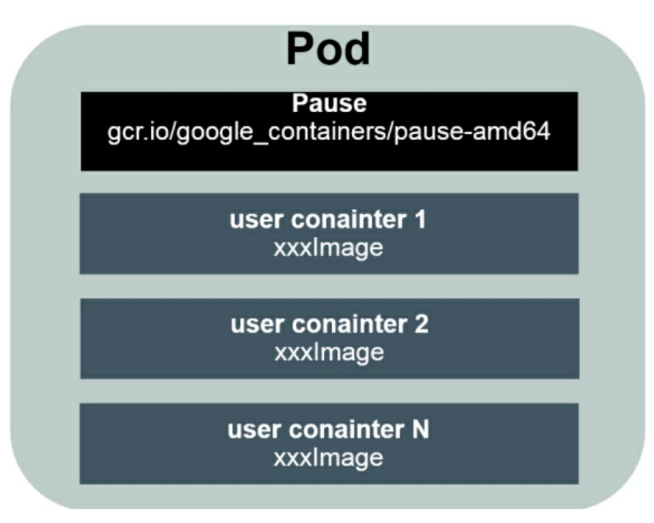
为什么Kubernetes会设计出一个全新的Pod的概念并且Pod有这样特 殊的组成结构?
原因之一:在一组容器作为一个单元的情况下,我们难以简单地 对“整体”进行判断及有效地行动。比如,一个容器死亡了,此时算是整体死亡么?是N/M的死亡率么?引入业务无关并且不易死亡的Pause容器作为Pod的根容器,以它的状态代表整个容器组的状态,就简单巧 妙地解决了这个难题。
原因之二:Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问 题,也很好地解决了它们之间的文件共享问题。 Kubernetes为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个 Pod里的多个容器共享Pod IP地址。Kubernetes要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来 实现,例如Flannel、Open vSwitch等,因此我们需要牢记一点:在 Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
Label:
Label(标签)是Kubernetes系统中另外一个核心概念。一个Label是 一个key=value的键值对,其中key与value由用户自己指定。Label可以被附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的 资源对象上。Label通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。
Replication Controller(RC):
RC是Kubernetes系统中的核心概念之一,简单来说,它其实定义了 一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预 期值,所以RC的定义包括如下几个部分。
- Pod期待的副本数量。
- 用于筛选目标Pod的Label Selector。
- 当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模板 (template)
Service:
Service服务也是Kubernetes里的核心资源对象之一,Kubernetes里的 每个Service其实就是我们经常提起的微服务架构中的一个微服务,之前 讲解Pod、RC等资源对象其实都是为讲解Kubernetes Service做铺垫的。
下图显示了Pod、RC与Service的逻辑关系。
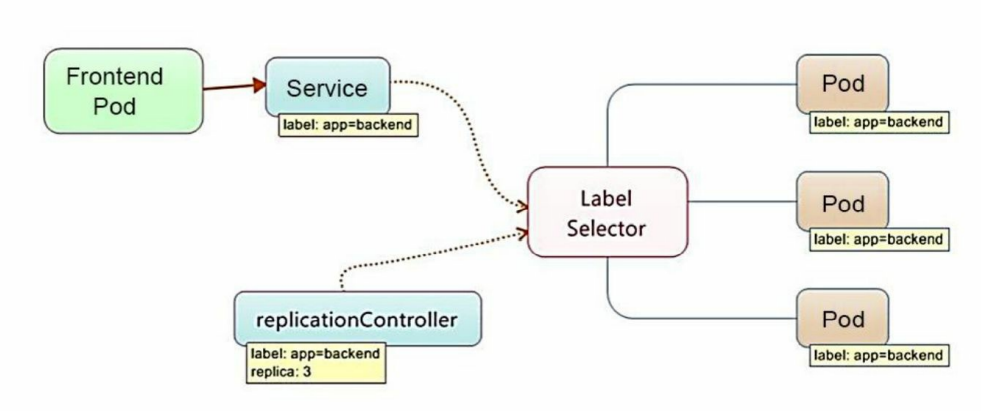
Kubernetes的Service定义了一个服务的访问 入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由 Pod副本组成的集群实例,Service与其后端Pod副本集群之间则是通过 Label Selector来实现无缝对接的。RC的作用实际上是保证Service的服务能力和服务质量始终符合预期标准。
3.创建POD流程
1.用户通过kubectl发起创建pod请求
2.apiserver收到请求,先创建一个包含pod信息的yaml文件,将该文件信息写入到etcd中(如果直接使用yaml文件创建则无该步骤)
3.controller manager 获取到创建pod的yaml信息,并根据配置信息将要创建的资源对象(pod)放在等待队列中。
4.当scheduler通过死循环查看api-server,如果获取到新的pod请求,根据etcd中的集群状态信息,计算node节点资源,并根据预选调度和优选调度,选择最佳的node节点。
5.api-server与选出的最佳node节点的kubelet进行通信,该node节点上的kublet通过与容器引擎交互,根据资源清单,由容器引擎创建对应pod。
6.在通过kube-proxy生成对应的网络策略,生成用户访问入口。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现