

redis高可用
Redis-高可用(主从复制、哨兵模式、集群)
1.主从复制
1.1 主从复制简介
在 Redis 复制的基础上,使用和配置主从复制非常简单,能使得从 Redis 从服务器(下文称 slave)能精确得复制主 Redis 服务器(下文称 master)的内容。每次当 slave 和 master 之间的连接断开时, slave 会自动重连到 master 上,并且无论这期间 master 发生了什么, slave 都将尝试让自身成为 master 的精确副本。
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台 Redis 服务器都是主节点;且一个主节点可以有多个从节点 (或没有从节点),但一个从节点只能有一个主节点。
1.2 关于Redis复制的几点事实
- Redis 使用异步复制,slave 和 master 之间异步地确认处理的数据量
- 一个 master 可以拥有多个 slave
- slave 可以接受其他 slave 的连接。除了多个 slave 可以连接到同一个 master 之外, slave 之间也可以像层叠状的结构(cascading-like structure)连接到其他 slave 。自 Redis 4.0 起,所有的 sub-slave 将会从 master 收到完全一样的复制流。
- Redis 复制在 master 侧是非阻塞的。这意味着 master 在一个或多个 slave 进行初次同步或者是部分重同步时,可以继续处理查询请求。
- 复制在 slave 侧大部分也是非阻塞的。当 slave 进行初次同步时,它可以使用旧数据集处理查询请求,假设你在 redis.conf 中配置了让 Redis 这样做的话。否则,你可以配置如果复制流断开, Redis slave 会返回一个 error 给客户端。但是,在初次同步之后,旧数据集必须被删除,同时加载新的数据集。 slave 在这个短暂的时间窗口内(如果数据集很大,会持续较长时间),会阻塞到来的连接请求。自 Redis 4.0 开始,可以配置 Redis 使删除旧数据集的操作在另一个不同的线程中进行,但是,加载新数据集的操作依然需要在主线程中进行并且会阻塞 slave 。
- 复制既可以被用在可伸缩性,以便只读查询可以有多个 slave 进行(例如 O(N) 复杂度的慢操作可以被下放到 slave ),或者仅用于数据安全。
- 可以使用复制来避免 master 将全部数据集写入磁盘造成的开销:一种典型的技术是配置你的 master Redis.conf 以避免对磁盘进行持久化,然后连接一个 slave ,其配置为不定期保存或是启用 AOF。但是,这个设置必须小心处理,因为重新启动的 master 程序将从一个空数据集开始:如果一个 slave 试图与它同步,那么这个 slave 也会被清空。
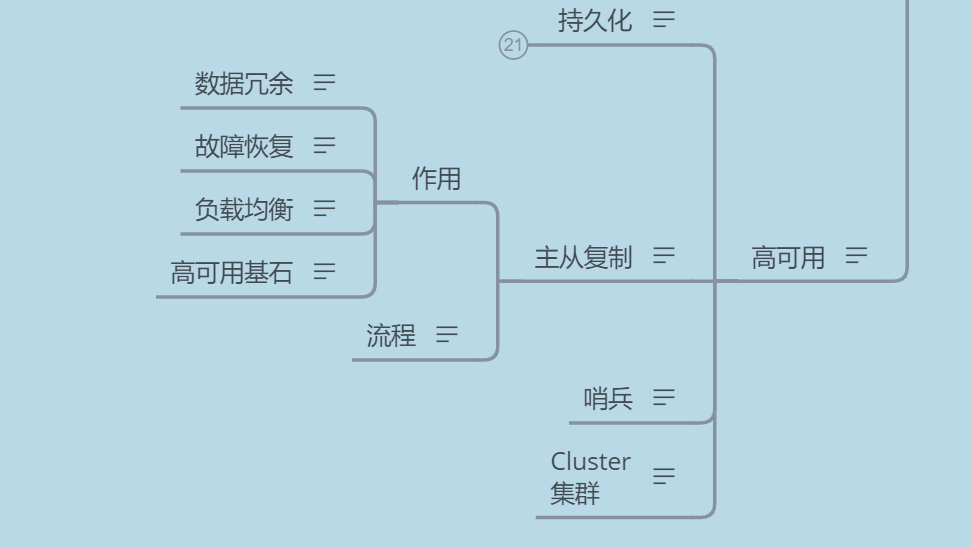
1.3 主从复制的作用
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
1.4 主从复制的流程
1.若启动一个Slave机器进程,则它会向Master机器发送一个“sync command" 命令,请求同步连接。
2.无论是第一次连接还是重新连接,Master机器 都会启动一个后台进程,将数据快照保存到数据文件中(执行rdb操作) ,同时 Master 还会记录修改数据的所有命令并缓存在数据文件中。
3.后台进程完成缓存操作之后,Master 机器就会向 Slave 机器发送数据文件,Slave 端机器将数据文件保存到硬盘上,然后将其加载到内存中,接着 Master 机器就会将修改数据的所有操作一并发送给 Slave 端机器。若 Slave 出现故障导致宕机,则恢复正常后会自动重新连接。
4.Master机器收到 Slave 端机器的连接后,将其完整的数据文件发送给 Slave 端机器,如果 Mater 同时收到多个 Slave 发来的同步请求,则 Master 会在后台启动一个进程以保存数据文件,然后将其发送给所有的 Slave 端机器,确保所有的 Slave 端机器都正常
1.5 部署redis主从复制
环境准备
| 服务器类型 | IP | Redis版本 |
|---|---|---|
| Master | 192.168.80.20 | redis-5.0.7 |
| slaver1 | 192.168.80.25 | redis-5.0.7 |
| slaver2 | 192.168.80.30 | redis-5.0.7 |
redis的安装步骤可参考

1.5.1 操作步骤
1.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
2.修改Master配置文件
-----------修改Redis 配置文件(Master节点操作) ----------
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,注释掉bind项,或修改为0.0.0.0,默认监听所有网卡
daemonize yes #137行,开启守护进程
logfile /var/log/redis_6379.log #172行,指定日志文件目录
dir /var/lib/redis/6379 #264行,指定工作目录
appendonly yes #700行,开启AOF持久化功能
/etc/init.d/redis_6379 restart
3.修改slaver1、slaver2配置
-----------修改Redis 配置文件(Slave节点操作)------------
vim /etc/redis/6379.conf
bind 0.0.0.0 #70行,修改监听地址为0.0.0.0
1.5.2 操作截图
1.主配置文件修改






2.slaver1、slaver2从节点配置






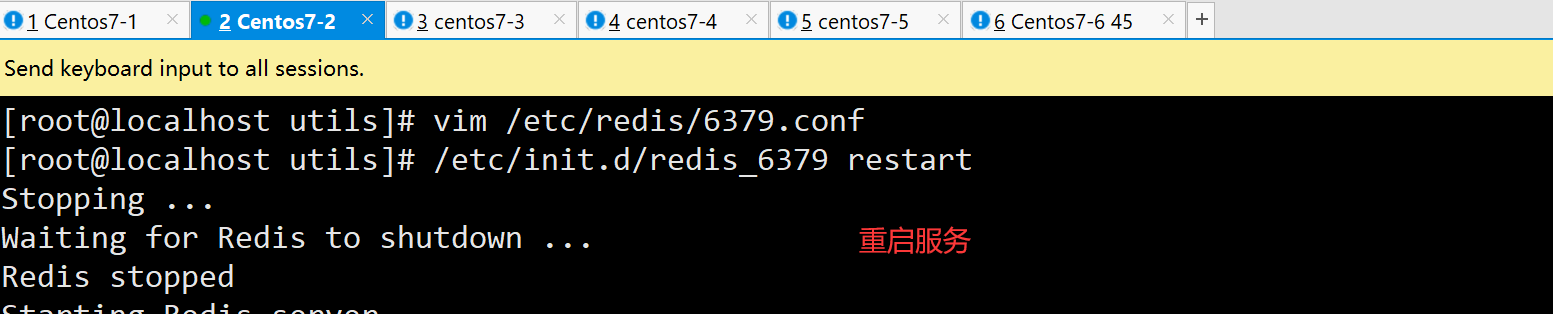
3.验证主从效果
主查看日志
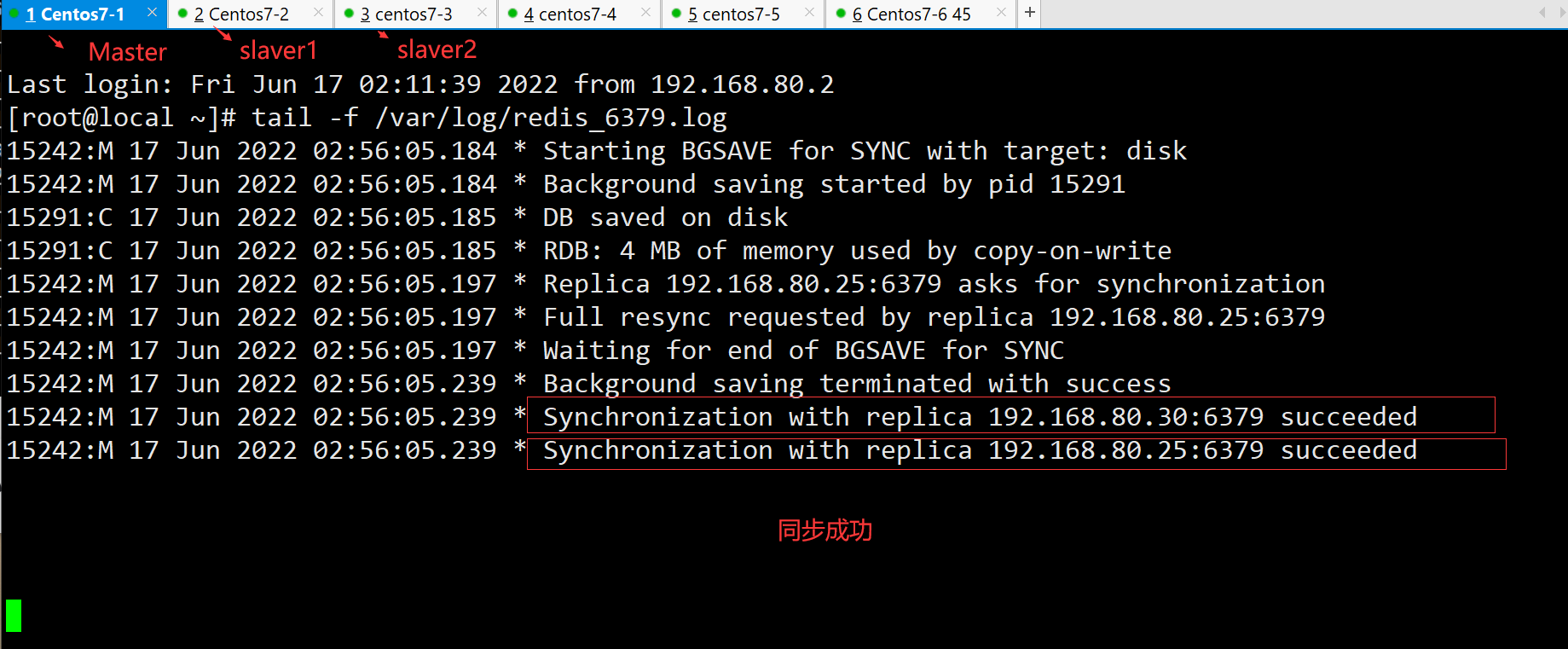
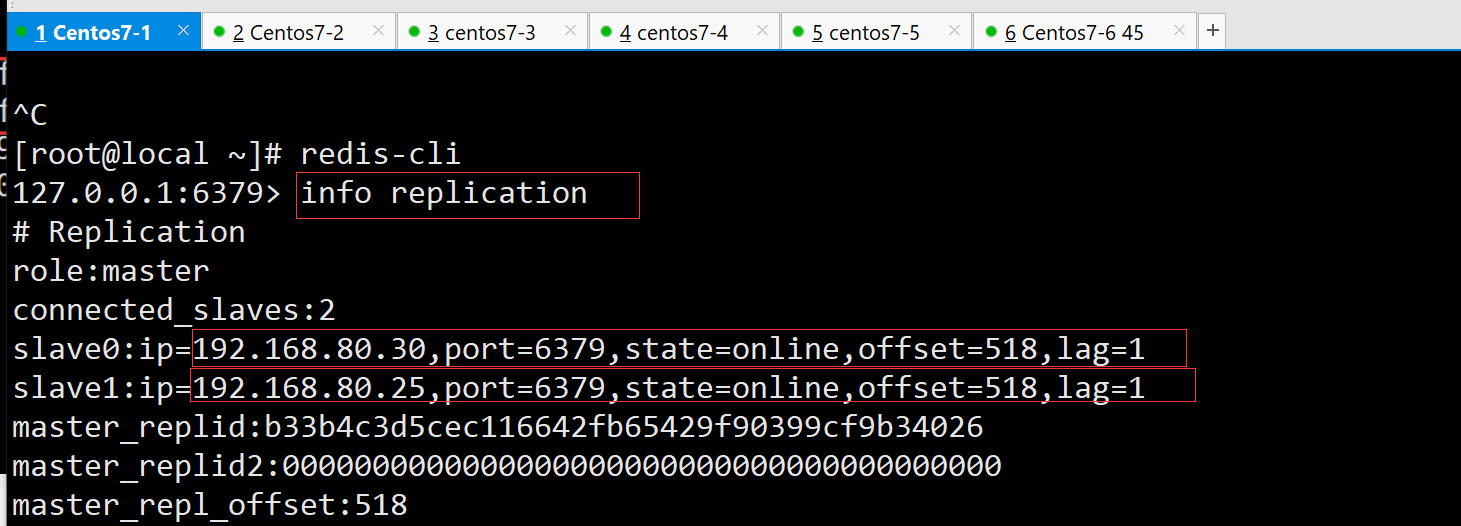
redis内查看
主插入一条数据




2.哨兵(Sentinel)模式
2.1 哨兵模式简介
哨兵的核心功能:在主从复制的基础上,哨兵引入了主节点的自动故障转移。
Redis 的哨兵系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
- 监控(Monitoring):哨兵会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
2.2 哨兵模式结构
哨兵结构由两部分组成:哨兵节点和数据节点。
- 哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 redis 节点,不存储数据。
- 数据节点:主节点和从节点都是数据节点。
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式,所有节点上都需要部署哨兵模式,哨兵模式会监控所有的Redis 工作节点是否正常,当Master 出现问题的时候,因为其他节点与主节点失去联系,因此会投票,投票过半就认为这个 Master 的确出现问题,然后会通知哨兵间,然后从Slaves中选取一个作为新的 Master。
需要特别注意的是:客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
2.3 部署哨兵模式
2.3.1 操作步骤
1.所有节点修改哨兵模式配置文件
--------修改Redis哨兵模式的配置文件(所有节点操作) --------
vim /opt/redis-5.0.7/sentinel.conf
protected-mode no #17行,关闭保护模式
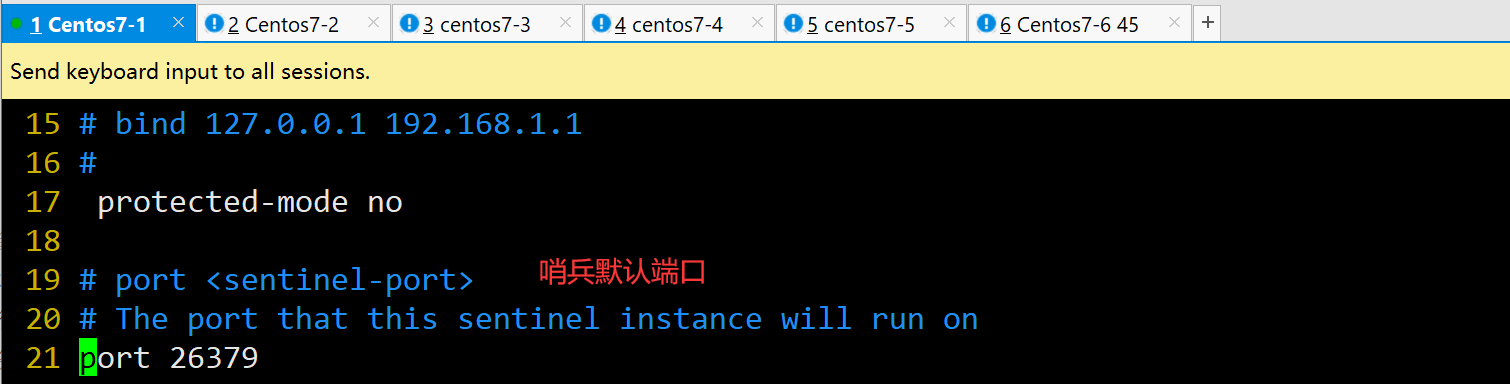
port 26379 #21行,Redis哨兵默认的监听端口
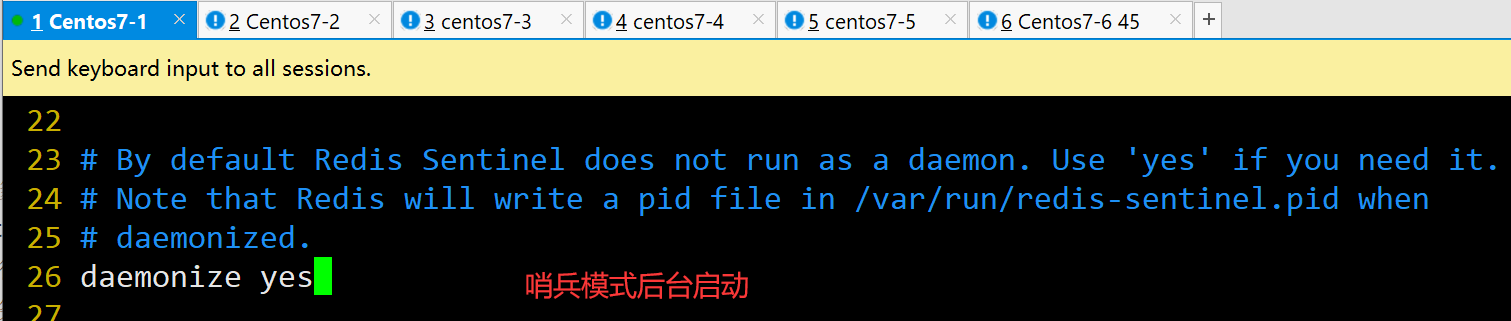
daemonize yes #26行,指定sentinel为后台启动
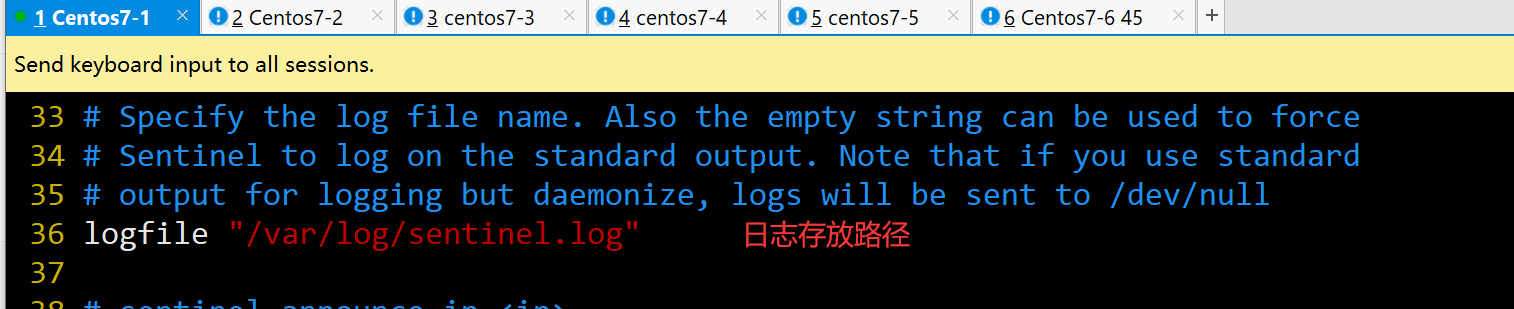
logfile "/var/log/sentinel.log" #36行,指定日志存放路径
dir "/var/lib/redis/6379" #65行,指定数据库存放路径
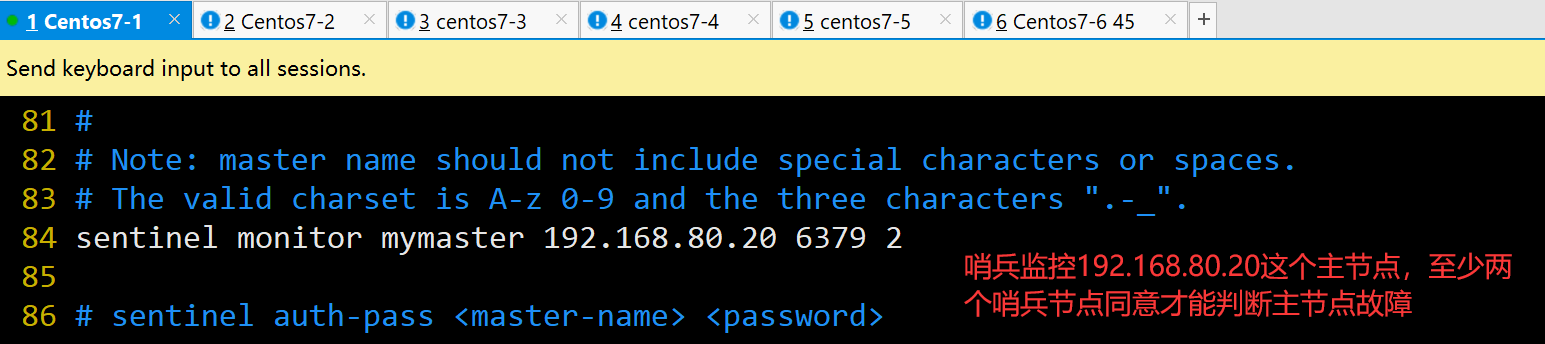
sentinel monitor mymaster 192.168.80.20 6379 2 #84行, 修改
指定该哨兵节点监控192.168.80.20:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移
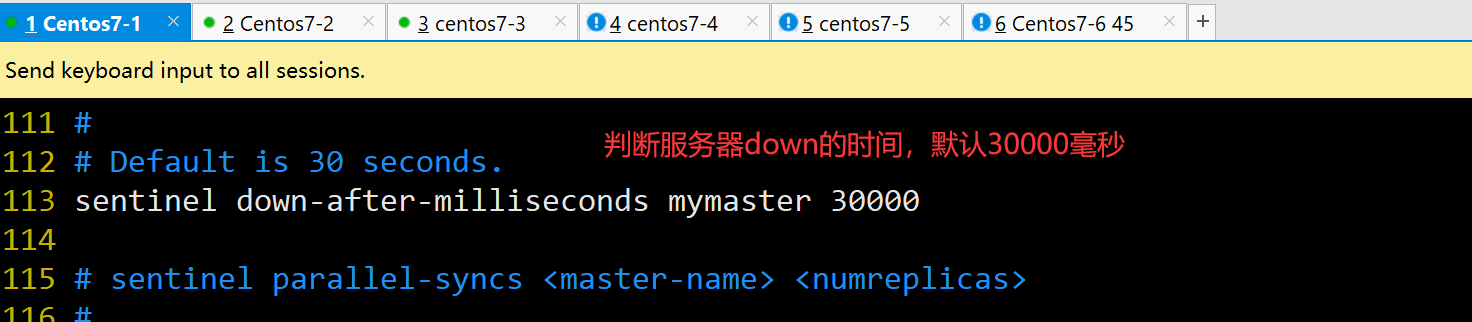
sentinel down-after-milliseconds mymaster 30000 #113行,判定服务器down掉的时间周期,默认30000毫秒(30秒)
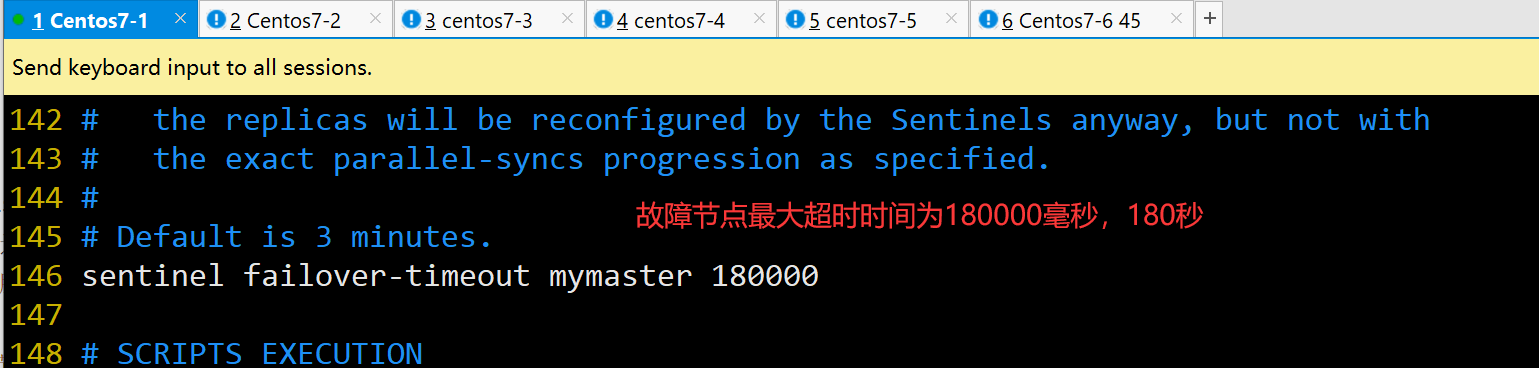
sentinel failover-timeout mymaster 180000 #146行,故障节点的最大超时时间为180000 (180秒 )
2.启动哨兵模式
----------启动哨兵模式-----------------
注意:先启master,再启slave
cd /opt/redis-5.0.7/
redis-sentinel sentinel.conf &
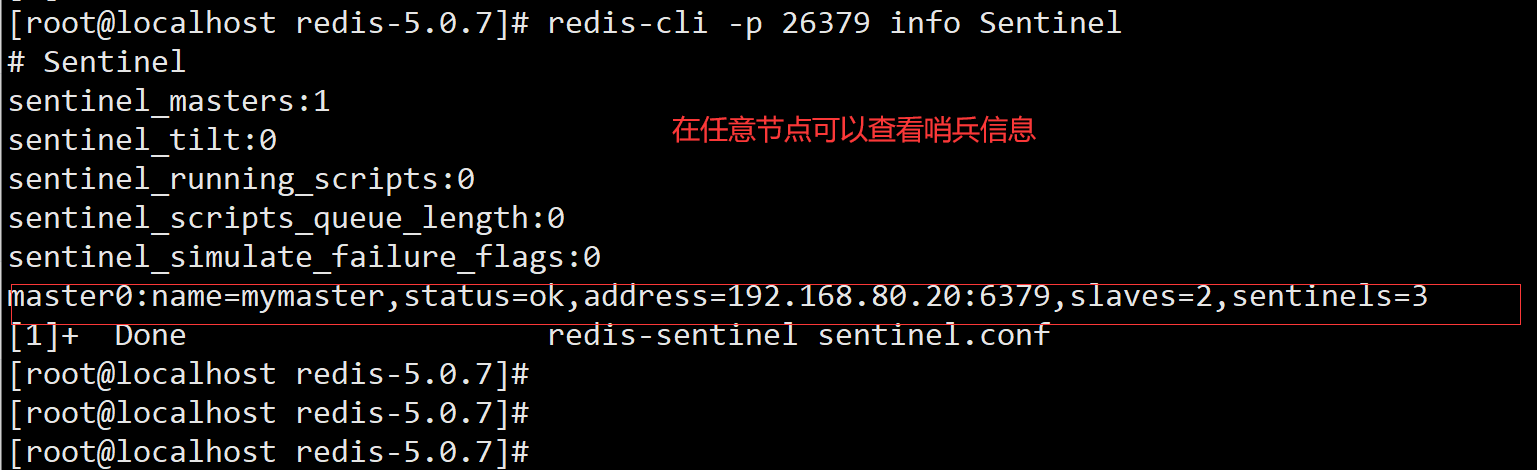
3.查看哨兵信息
-----------查看哨兵信息------------------
redis-cli -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.80.20:6379,slaves=2,sentinels=3
2.3.2 操作截图



故障模拟:
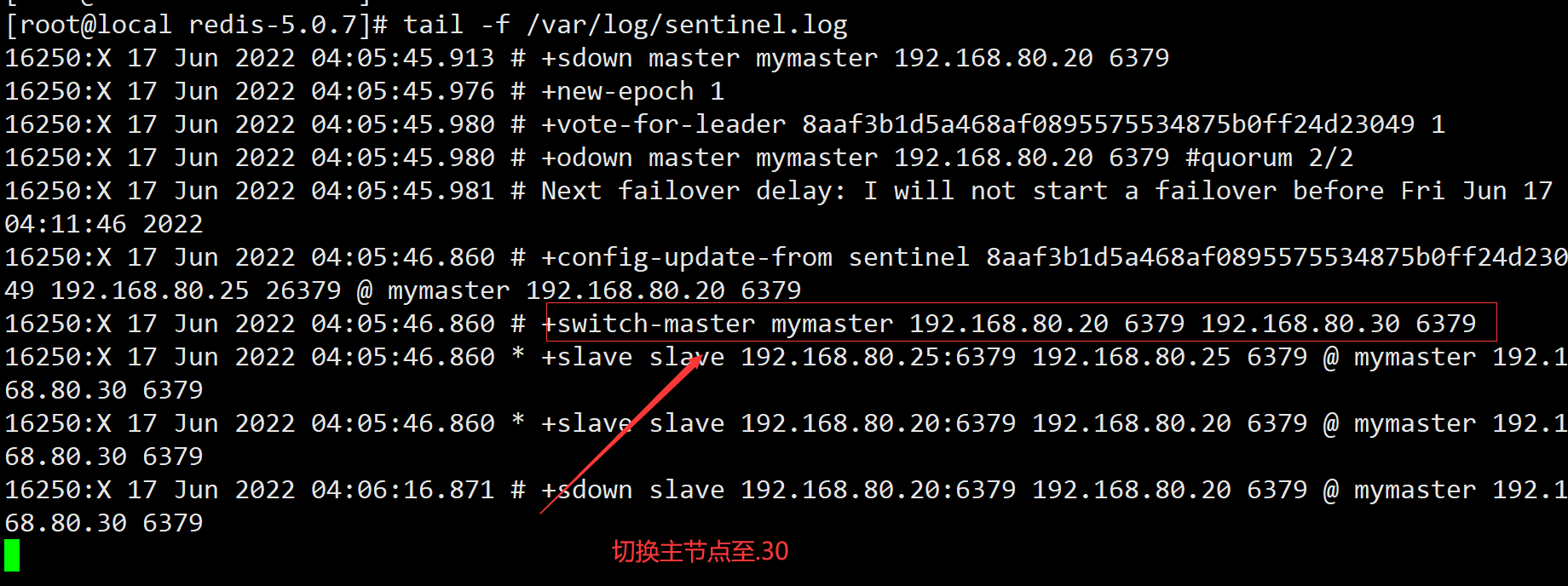
关闭主的redis服务,模拟服务宕机

查看节点是否切换
原主上查看日志
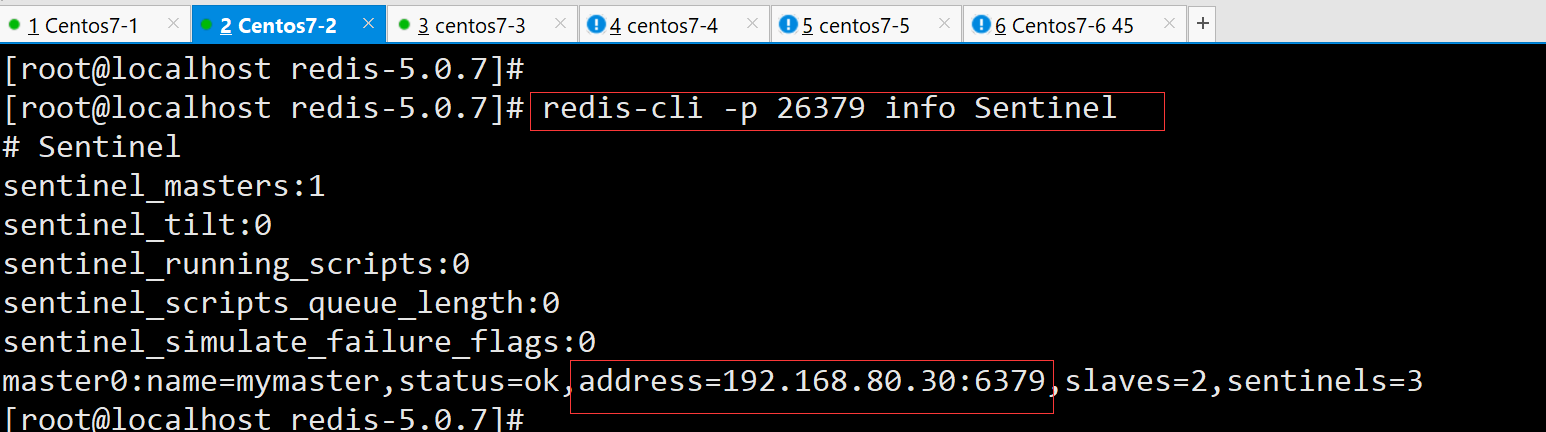
在现存的两个节点查看哨兵状态
3.集群模式
3.1 集群模式简介
Redis 集群是 Redis 的一个分布式实现,主要是为了实现以下这些目标(按在设计中的重要性排序):
- 在1000个节点的时候仍能表现得很好并且可扩展性(scalability)是线性的。
- 没有合并操作,这样在 Redis 的数据模型中最典型的大数据值中也能有很好的表现。
- 写入安全(Write safety):那些与大多数节点相连的客户端所做的写入操作,系统尝试全部都保存下来。不过公认的,还是会有小部分(small windows?)写入会丢失。
- 可用性(Availability):在绝大多数的主节点(master node)是可达的,并且对于每一个不可达的主节点都至少有一个它的从节点(slave)可达的情况下,Redis 集群仍能进行分区(partitions)操作。
3.2 集群模式的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
3.3 Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
3.4 Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
- 客户端向主节点B写入一条命令.
- 主节点B向客户端回复命令状态.
- 主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项:
3.5 集群模式的部署
3.5.1 操作步骤
环境准备
| 服务类型 | IP地址 | Redis版本 |
|---|---|---|
| Master1 | 192.168.80.20 | redis-5.0.7 |
| Master2 | 192.168.80.25 | redis-5.0.7 |
| Master3 | 192.168.80.30 | redis-5.0.7 |
| slaver1 | 192.168.80.35 | redis-5.0.7 |
| slaver2 | 192.168.80.40 | redis-5.0.7 |
| slaver3 | 192.168.80.45 | redis-5.0.7 |
1.配置文件修改
cd /etc/redis
vim 6379.conf
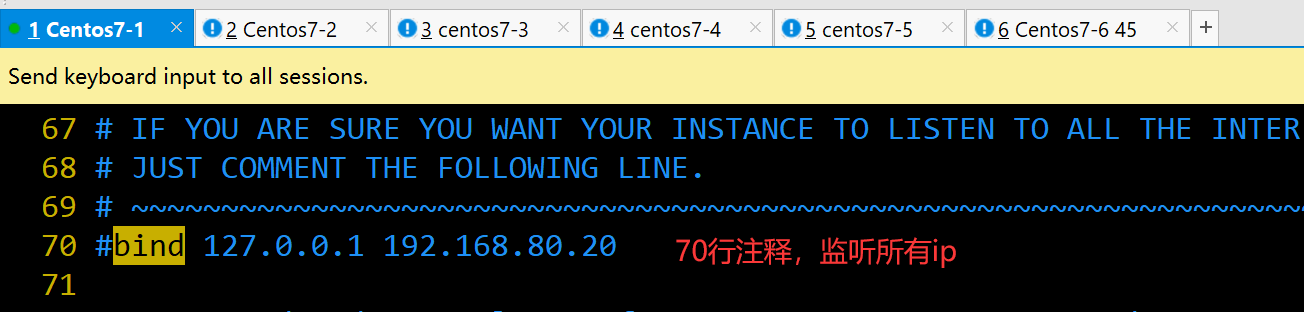
#bind 127.0.0.1 #70行,注释掉bind项,默认监听所有网卡
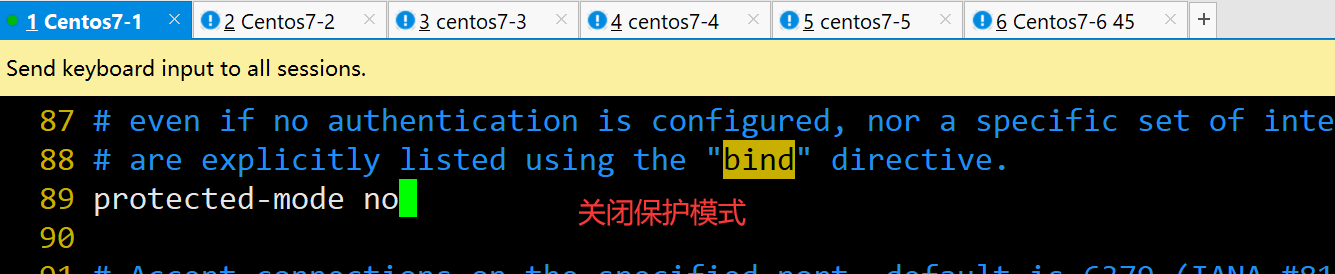
protected-mode no #89行,修改,关闭保护模式
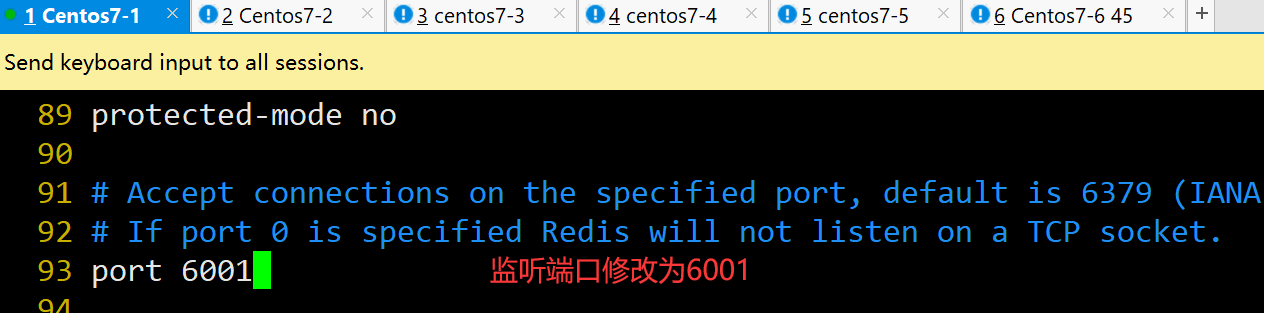
port 6001 #93行,修改,redis监听端口
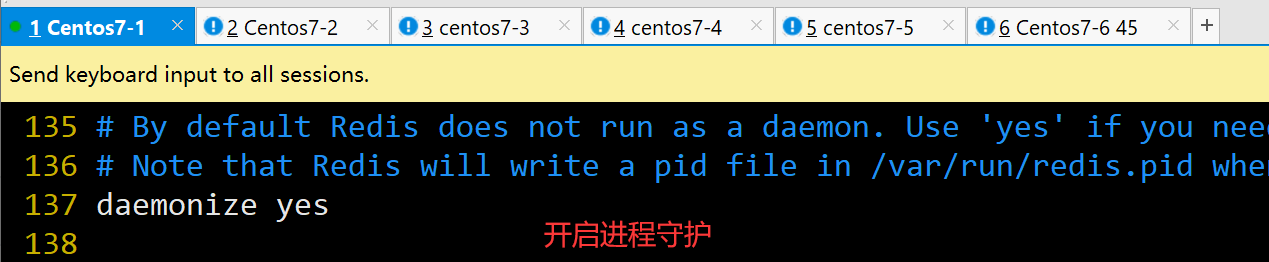
daemonize yes #137行,开启守护进程,以独立进程启动
appendonly yes #700行,修改,开启AOF持久化
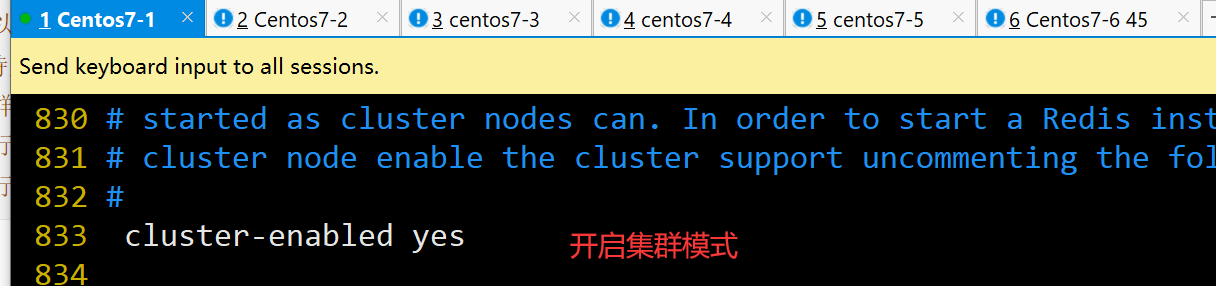
cluster-enabled yes #833行,取消注释,开启群集功能
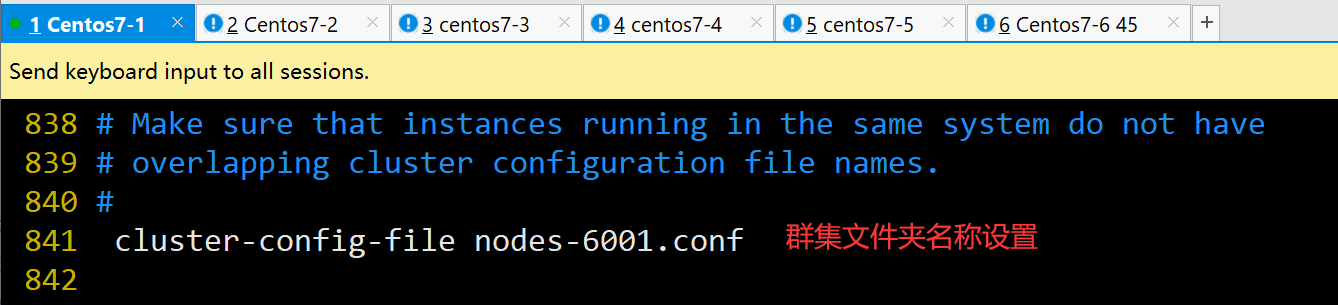
cluster-config-file nodes-6001.conf #841行,取消注释,群集名称文件设置
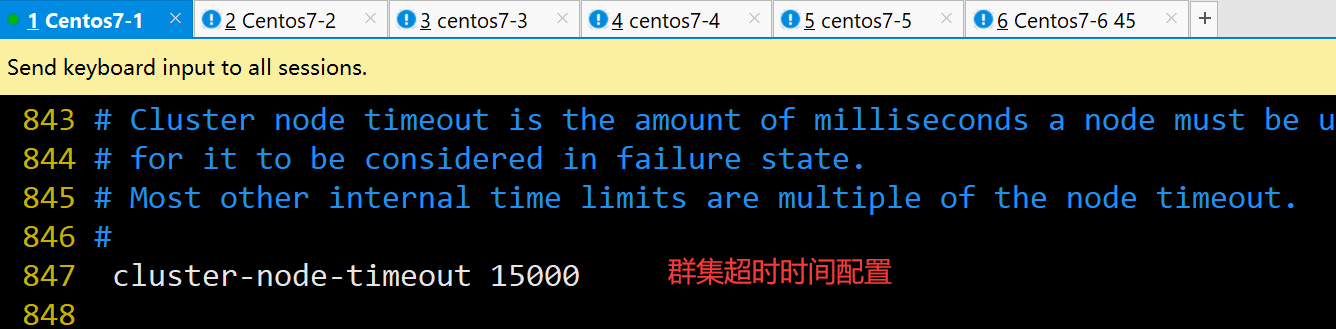
cluster-node-timeout 15000 #847行,取消注释群集超时时间设置
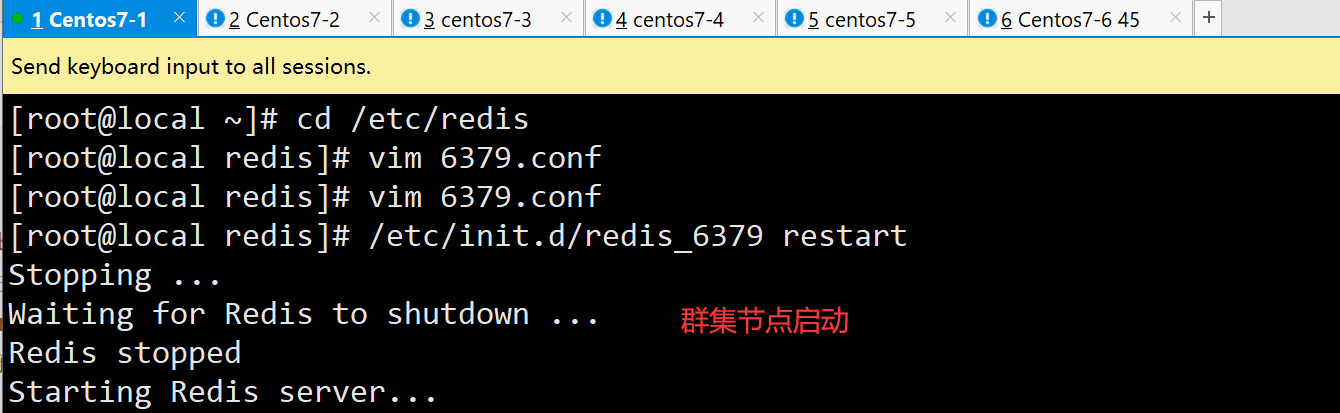
2.集群节点启动
/etc/init.d/redis_6379 restart
3.启动集群
#启动集群
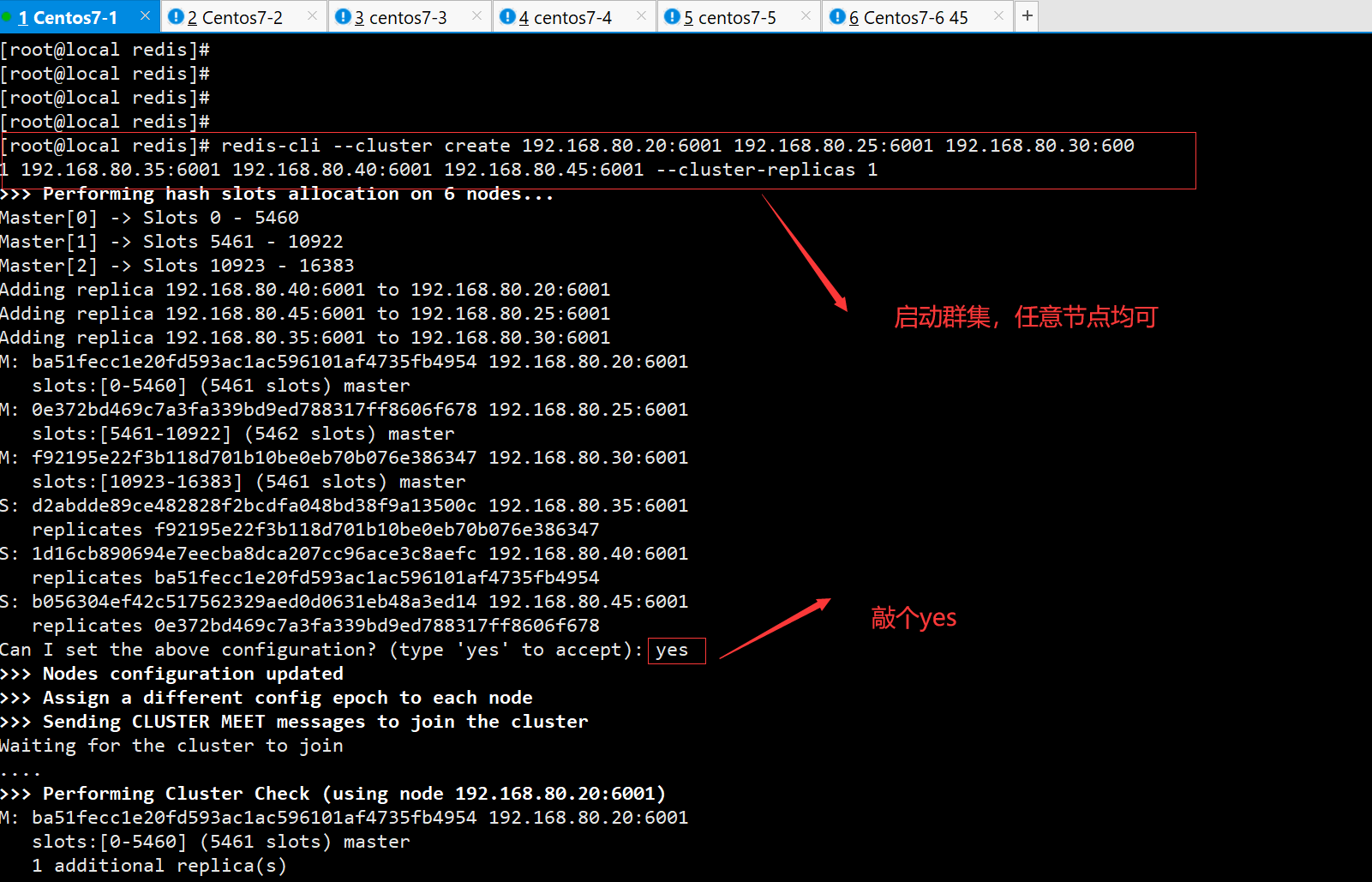
redis-cli --cluster create 192.168.80.20:6001 192.168.80.25:6001 192.168.80.30:6001 192.168.80.35:6001 192.168.80.40:6001 192.168.80.45:6001 --cluster-replicas 1
#六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候需要输入yes 才可以创建。
-replicas 1 #表示每个主节点有1个从节点。
4.测试集群
#测试群集
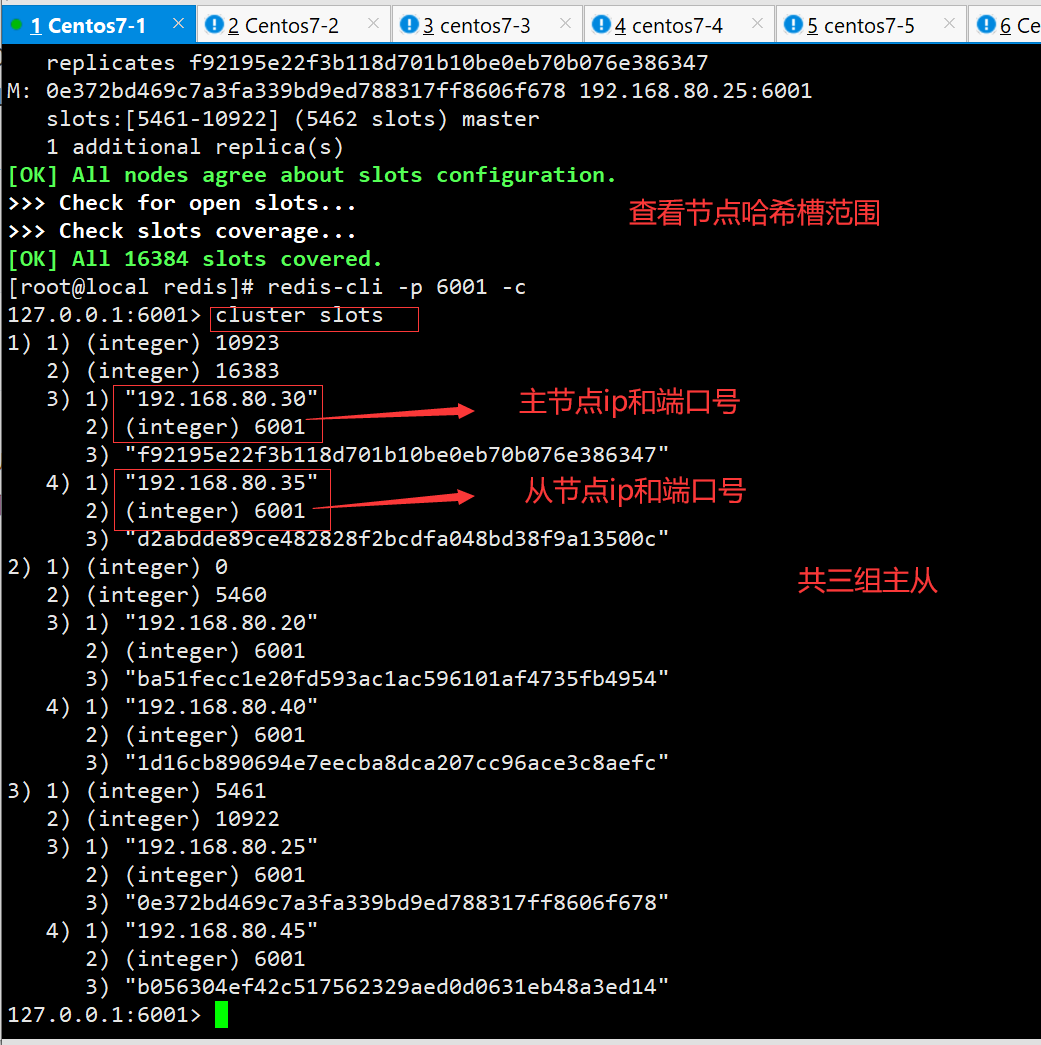
redis-cli -p 6001 -c #加-c参数,节点之间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
1) 1) (integer) 5461
2) (integer) 10922 #哈希槽编号范围
3) 1) "127.0.0.1" .
2) (integer) 6003 #主节点IP和端口号
3) " fdca661922216dd69a 63a7c9d3c4540cd6baef44"
4) 1) "127.0.0.1"
2) (integer) 6004 #从节点IP和端口号
3) "a2c0c32aff0f38980accd2b63d6d952812e44740"
2) 1) (integer) 0
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 6001
3) "0e5873747a2e2 6bdc935bc76c2ba fb19d0a54b11"
4) 1) "127.0.0.1"
2) (integer) 6006
3) "8842ef5584a85005e135fd0ee59e5a0d67b0cf8e"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6002
3) "81 6ddaa3d14 69540b2f fbcaaf9aa867646846b30"
4) 1) "127.0.0.1"
2) (integer) 6005
3) "f847077bfe6722466e96178ae8cbb09dc8b4d5eb"
127.0.0.1:6001> set name zhangsan
-> Redirected to slot [5798] located at 127.0.0.1: 6003
OK
127.0.0.1:6001> cluster keyslot name #查看name键的槽编号
(integer) 5798
3.5.2 操作截图

4.测试群集

4.小结


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!