布隆过滤器和LRU Cache的一些概念
一些关于布隆过滤器的参考链接
https://blog.csdn.net/tianyaleixiaowu/article/details/74721877
https://www.cnblogs.com/cpselvis/p/6265825.html
https://github.com/lovasoa/bloomfilter/blob/master/src/main/java/BloomFilter.java
https://github.com/Baqend/Orestes-Bloomfilter
布隆过滤器
将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。
HashTable + 拉链存储重复元素
布隆过滤器 VS hashTable
一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用来检索一个二元素是否在一个集合中。
优点是空间效率和查询时间都远远超过一般的算法
缺点是有一定的误识别率和删除困难
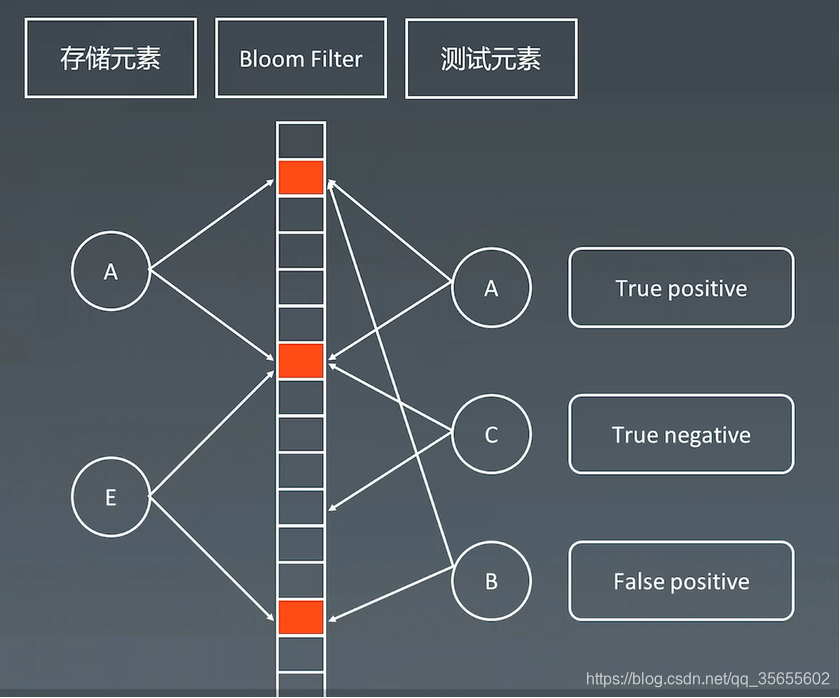
如果使用布隆过滤器算法,检测到B存在于布隆过滤器里面,则B元素可能存在;如果C有一个不存在布隆过滤器中,则C一定不存在于布隆过滤器中
布隆过滤器添加元素
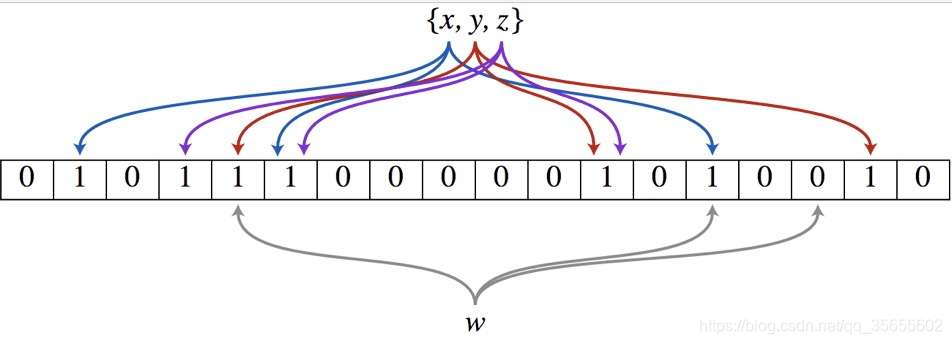
• 将要添加的元素给k个哈希函数
• 得到对应于位数组上的k个位置
• 将这k个位置设为1
布隆过滤器查询元素
• 将要查询的元素给k个哈希函数
• 得到对应于位数组上的k个位置
• 如果k个位置有一个为0,则肯定不在集合中
• 如果k个位置全部为1,则可能在集合中
如何判断一个元素是否存在一个集合中?
常规思路
• 数组
• 链表
• 树、平衡二叉树、Trie
• Map (红黑树)
• 哈希表
案例:
1. 比特币网络
2. 分布式系统(Map-Reduce) --hadoop、search engine
3. Redis缓存
4. 垃圾邮件、评论等的过滤
LRU cache
两个要素:大小、替换策略
Hash Table + Double LinkedList
O(1) 查询
O(1) 修改、更新
LRU cache的工作实例(最近被使用的元素)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号