【Redis】哈希分布的三种方式
哈希分布的三种方式
常见的数据分布方式有哈希(取余hash、一致性hash)、按数据范围、 按数据量。
在Cluster 中数据分布式方式选择的是哈希分区规则。而哈希分区 也有很多种实现方式,这里话主要图解节点取余hash、一致性hash、虚拟槽hash。
hash算法——节点取余分区
取余hash:取余hash 会使用特定的数据,比如说用户Id、手机号等,再根据节点的数量N通过公式:hash(key) % N计算出哈希值。如下图:
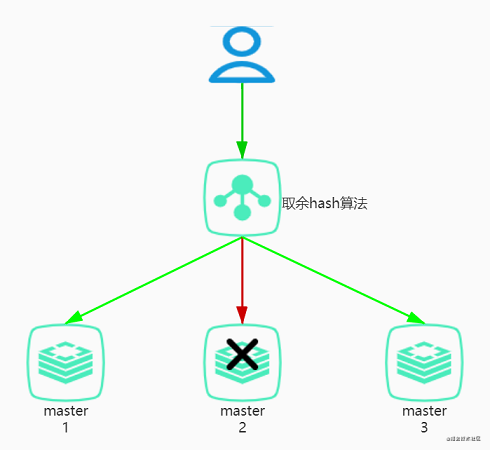

比如我们有三台 Redis 的主服务器,我们要存储用户id为10的数据。这时我们的公式为:hash(10) % 3 = 1(hash(10) = 10),我们就可以定位到将用户用户id为10的数据存入到master1 的服务器节点中。当我们获取数据时一样通过公式能定位到master1 主节点,这们就省去了遍历所有服务器的时间,从而大大提升了性能。
缺点f分析:
- 节点取余分区方式有一个问题:即当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分布
节点取余分区方式建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据

这种方式的劣势也是很明显的,首先如上图,当某一个主节点出现网络异常或者宕机产生不可达现象时,会出现整个集群环境下可用服务器基数的变化(从三台变成两台)。从而导致整个集群不可用,因为涉及到的计算公式已经变化,造成数据失效、混乱等现象。
另一方面的话在整个集群环境的横向扩展(添加主节点)上也是很不友好的,需要对旧数据重新做数据与节点的关系映射。
节点取余方式优点:
- 客户端分片
- 配置简单:对数据进行哈希,然后取余
节点取余方式缺点:
- 数据节点伸缩时,导致数据迁移
- 迁移数量和添加节点数据有关,建议翻倍扩容
一致性hash算法
一致性哈希原理:
将所有的数据当做一个token环,token环中的数据范围是0到2的32次方。然后为每一个数据节点分配一个token范围值,这个节点就负责保存这个范围内的数据。
对每一个key进行hash运算,被哈希后的结果在哪个token的范围内,则按顺时针去找最近的节点,这个key将会被保存在这个节点上。


一致性hash算法就是为了解决上面取余hash的问题,首先失效的最主要原因是取余的基数是根据集群中的节点数动态变化的!一致性hash算法把取余的基数固定为一个常数 232,这样可以做到以不变应万变。从而把取余范围控制在[0,232-1]的区间内,并把这个区间按照顺时针的方向均匀分布在一个圆环上,称之为hash环(如上图)。
其次,由于一致性hash算法把取余的基数固定为一个常数 232,从而也不存在横向扩容相关的问题。
如上图,当我们需要查询数据时,计算到的hash 值为10(上图N1节点顺时针第一个键)。这时我们的寻址规则就是根据圆环顺时针找到第一个大于等于该哈希值的数据节点(上图找到的是N2节点)
抑制性哈希扩容分析:
在上面的图中,有4个key被hash之后的值在在n1节点和n2节点之间,按照顺时针规则,这4个key都会被保存在n2节点上,
如果在n1节点和n2节点之间添加n5节点,当下次有key被hash之后的值在n1节点和n5节点之间,这些key就会被保存在n5节点上面了
在上面的例子里,添加n5节点之后,数据迁移会在n1节点和n2节点之间进行,n3节点和n4节点不受影响,数据迁移范围被缩小很多
同理,如果有1000个节点,此时添加一个节点,受影响的节点范围最多只有千分之2
一致性哈希一般用在节点比较多的时候
-
优势
- 解决数据失效的问题
- 不需要考虑横向扩容问题
- 有很好的容错性和可扩展性。
- 采用客户端分片方式:哈希 + 顺时针(优化取余)
节点伸缩时,只影响邻近节点,但是还是有数据迁移
-
劣势
N2节点宕机了,就会出现通过hash函数后落在N1顺时针到N3区间的数据都会使用N3这个节点来提供服务。从而造成数据分布不均匀(数据倾斜)。
也就是说当使用少量节点时,节点变化将大范围影响哈希环中数据映射,因此这种方式不适合少量数据节点的分布式方案。在增减节点时需要增加一倍或减去一半节点才能保证数据和负载的均衡。
一致性 hash + 虚拟节点

一致性hash出现数据和负载的不均衡,主要的问题是节点少,则该方式就是加上了虚拟节点,从而解决了上面的一致性hash的问题
主要的话就是解决一致性hash 数据倾斜和少量节点的问题
hash slot算法(虚拟槽hash)
虚拟槽分区是Redis Cluster采用的分区方式
取余hash、一致性hash还是一致性hash加上虚拟节点都是从服务器的角度来寻址(通过hash算法确定使用哪台服务器)。
那么什么是虚拟槽?
虚拟槽巧妙地使用了哈希空间,使用分散度良好的hash函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。这个范围一般远远大于节点数,比如Cluster 槽范围是0~16383。槽是集群内数据管理和迁移的基本单位。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责一定数量的槽。
 步骤:
步骤:
- 把16384槽按照节点数量进行平均分配,由节点进行管理
- 对每个key按照CRC16规则进行hash运算
- 把hash结果对16383进行取余
- 把余数发送给Redis节点
- 节点接收到数据,验证是否在自己管理的槽编号的范围
如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
虚拟槽分区特点:
使用服务端管理节点,槽,数据:例如Redis Cluster
可以对数据打散,又可以保证数据分布均匀

 浙公网安备 33010602011771号
浙公网安备 33010602011771号