【Redis】数据结构与对象(六种底层数据结构)——压缩链表
压缩列表
压缩列表(ziplist)是为了节约内存而设计的,是由一系列特殊编码的连续内存块组成的顺序性(sequential)数据结构,一个压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者一个整数值
压缩列表是列表(List)和散列(Hash)的底层实现之一,一个列表只包含少量列表项,并且每个列表项是小整数值或比较短的字符串,会使用压缩列表作为底层实现(在3.2版本之后是使用quicklist实现)
压缩列表的构成
一个压缩列表可以包含多个节点(entry),每个节点可以保存一个字节数组或者一个整数值

各部分组成说明如下
zlbytes:记录整个压缩列表占用的内存字节数,在压缩列表内存重分配,或者计算zlend的位置时使用zltail:记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过该偏移量,可以不用遍历整个压缩列表就可以确定表尾节点的地址zllen:记录压缩列表包含的节点数量,但该属性值小于UINT16_MAX(65535)时,该值就是压缩列表的节点数量,否则需要遍历整个压缩列表才能计算出真实的节点数量entryX:压缩列表的节点zlend:特殊值0xFF(十进制255),用于标记压缩列表的末端
压缩列表节点的构成
每个压缩列表节点可以保存一个字节数字或者一个整数值,结构如下

previous_entry_ength:记录压缩列表前一个字节的长度encoding:节点的encoding保存的是节点的content的内容类型content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定
新增节点
在列表键的内容比较少时才会使用压缩列表,那么压缩列表为什么不能用于大的列表键呢?
ziplist 是连续存储的数据结构,内存是没有冗余的(前面的文章讲过的 SDS 中就有冗余空间), 也就是说,每一次新增节点,都需要进行内存申请,然后将如果当前内存连续块够用,那么将新节点添加,如果申请到的是另外一块连续内存空间,那么需要将所有的内容拷贝到新的地址。
也就是说,每一次新增节点,都需要内存分配,可能还需要进行内存拷贝。当 ziplist 中存储的值太多,内存拷贝将是一个很大的消耗。
也是因此,Redis 只在一些数据量小的场景下使用 ziplist.
级联更新
再次看看entry元素的结构,有一个previous_entry_length字段,他的长度要么都是1个字节,要么都是5个字节:
- 前一节点的长度小于254字节,则
previous_entry_length长度为1字节 - 前一节点的长度大于254字节,则
previous_entry_length长度为5字节
假设现在存在一组压缩列表,长度都在250字节至253字节之间,突然新增一新节点new, 长度大于等于254字节,会出现:
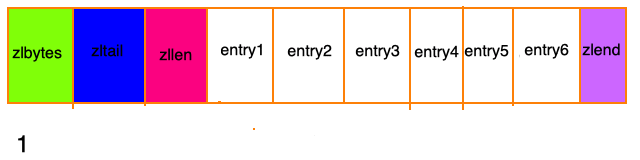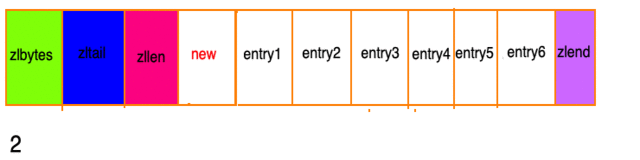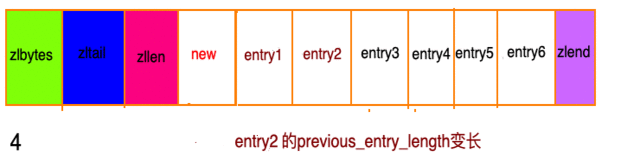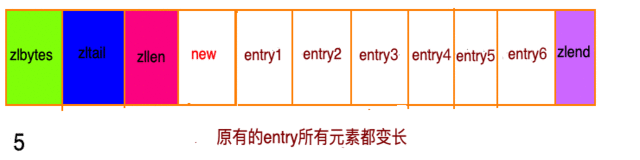
程序需要不断的对压缩列表进行空间重分配工作,直到结束。
除了增加操作,删除操作也有可能带来“连锁更新”。 请看下图,ziplist中所有entry节点的长度都在250字节至253字节之间,big节点长度大于254字节,small节点小于254字节。
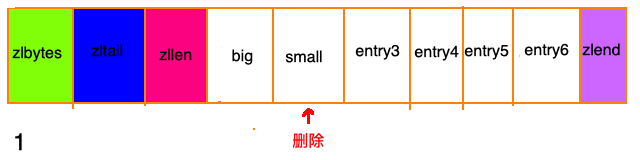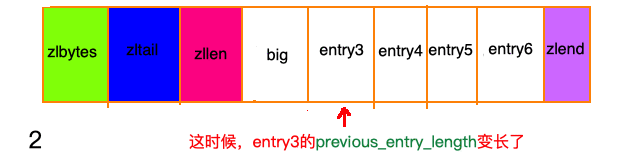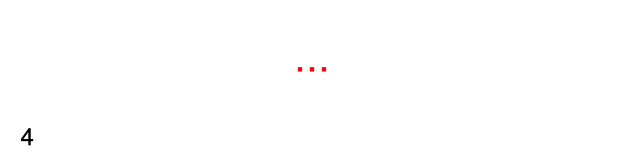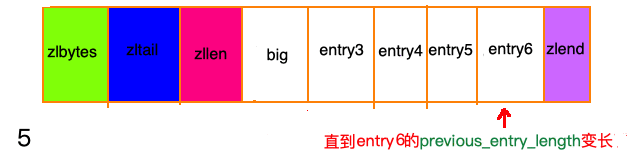
级联更新的时间复杂度很差,最多需要进行 N 次空间的重分配,每次空间的重分配最差需要 O(N), 所以级联更新的时间复杂度最差是 O(N²).
与新增节点相似,删除节点也有可能会造成级联更新的情况。
但是其实不用怕,因为级联更新造成 Redis 性能压力的概率极其低。
首先,级联更新需要连续的节点大小为250-253之间,这本就少见,而大范围的连续就更加少见了。如果运气不好出现了三五个的级联更新,也绝不会对 Redis 的性能有压力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号