
u版pytorch的YOLOv3训练过程理解\(^o^)/
注:本文中的代码基于https://github.com/ultralytics/yolov3
——————————————————————————————————
(1)首先将图片以416*416的形式输入系统,然后经过Darknet53网络特征提取和计算后就会得到3个不同尺度大小的YOLO层结果(分别是13/26/52)。比如我所训练的种类只有行人这一种,那么13*13的YOLO层输出就一共会有3*13*13个预测结果,每个结果里面有6个数值分别是:
[x, y, w, h, obj, cls]。
(2)接下来就是要重点研究这些预测结果和标签理论结果的损失函数怎么计算。
比如我设置的batch_size是8,那么在这8张图片中一共有86个行人存在,也就是对应的有8个txt文件,里面一共有86行。每一行的格式为:
[0,0.6492187500000001,0.5364583333333334,0.2328125,0.48125]
即[类别序号, 中心点x, 中心点y, 目标w, 目标h]
疑问:为什么都是小于0的小数?
答:这些都是指把一张图片的高和宽假设成1,每个参数对应的比例。
(3)一般训练过程的常见解释都是说:YOLO在训练的时候把图片分割成S*S个网格,然后判断哪个网格里面有标签中所包含的目标,对这个网格进行预测,然后根据预测结果和标签理论结果求损失进行梯度下降。那么问题来了,网络不是每个尺度下每个网格都有3个预测结果了吗?怎么说是根据标签来预测?
(4)首先 ,我们需要对标签中所包含的目标进行处理,看看到底标签对应的3个YOLO层输出理论应该是怎样的。也就是探讨,这8张图片里的86个行人,我们可以用哪些尺度(13/26/52)里面的哪些anchor(每个尺度对应3个anchor)进行预测。(注意,这个时候我们面向的对象就已经不是8张图片了,而是8张图片中的86个行人个体目标)。比如,86个行人,在13*13这个尺度下,并不是就可以对应86*3=258个理论预测结果。需要先进行一轮的IOU筛选:利用86个标签的wh和13*13相应的3个anchor的wh进行IOU求解,当这个wh_IOU小于某个阈值iou_thre的时候,就说明这些anchor根本不适合对该目标进行预测。经过这个步骤处理,可以去掉很多不适合的预测。我觉得也可以这么理解:13*13这个尺度比较适合预测大尺度目标,anchor也比较大,只有少数行人适合用这个YOLO层进行预测。
经过实验:86个行人在13*13中可以有12个预测,在26*26中可以有30个预测,在52*52中可以有125个预测。这12+30+125的预测就是86个行人标签中可以利用YOLO层预测的理论结果。
(5)得到的理论结果用于和YOLO层输出的真实结果进行损失计算。这个标签目标处理过程的代码:
tcls, tbox, indices, anchor_vec = build_targets(p, targets, model)
返回的就是86个行人可以在三个YOLO层进行预测的12+30+125个理论结果。其中,tcls表示这个行人对应的类别0;tbox的格式为[x, y, w, h],表示这个行人对应的宽高中心坐标;indices的格式为[图片索引,对应可用来预测的anchor的索引,行人在这张图片中网格的左上角坐标xy],图片索引就是指这个行人是属于8张图片中的那张图片。
因为是3个尺度13/26/52,在返回的数值中,tcls[0],tbox[0],indices[0], anchor_vec[0]就是对应13*13这个尺度的12个行人的理论结果。
(6)接下来取13*13尺度的理论结果,一共有12个行人。在u版代码中:
b, a, gj, gi = indices[i]
其中b表示这12个行人所在图片的索引(范围为0-7),a表示这12个行人可以利用的anchor的索引(范围为0-2),gj表示这12个行人所在网格的左上角横坐标(范围为0-12),gi表示这12个行人所在网格的左上角横坐标(范围为0-12)。
(7)在上面就是把13*13尺度下12个行人的标签理论结果构造好一部分了,接下来就要构造置信度。
tobj = torch.zeros_like(pi[..., 0])
构造出一个和实际的YOLO层输出一样多的置信度矩阵全零,形状为(bs, anchors, grid, grid),比如实际的YOLO层在13尺度下一共有8*13*13*3个置信度,所以一共是4056个。
(8)接下来要开始计算这12个行人对应的实际YOLO层预测出的结果,用于后面求损失值。
for i, pi in enumerate(p):
ps = pi[b, a, gj, gi]
这里的p是指三个YOLO层输出的所有结果,i就是0,1,2三个YOLO层索引,pi就是对应YOLO层的所有实际预测结果。利用之前根据12个行人标签所计算好的b, a, gj, gi就可以找到pi层对应的结果。实际返回的ps格式为[x, y, w, h, obj, cls]
(9)
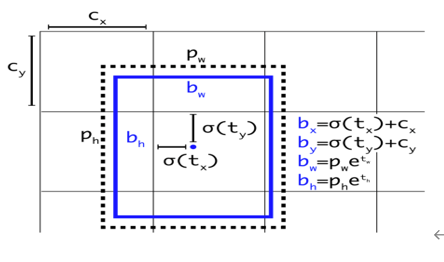
pxy = torch.sigmoid(ps[:, 0:2]) # pxy = pxy * s - (s - 1) / 2, s = 1.5 (scale_xy)
pwh = torch.exp(ps[:, 2:4]).clamp(max=1E3) * anchor_vec[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
上面的代码对应计算出预测的bbox的bx, by, bw, bh。
(10)接下来计算实际预测结果bbox和理论结果tbox的GIOU。
giou = bbox_iou(pbox.t(), tbox[i], x1y1x2y2=False, GIoU=True) # giou computation
lbox += (1.0 - giou).sum() if red == 'sum' else (1.0 - giou).mean() # giou loss
(11)接下来就要对这12个行人的置信度进行设置成1,因为前面我们是初始化成全0。
要注意,obj应该是obj和giou相乘后的数值,所以不再单纯是1。
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * giou.detach().clamp(0).type(tobj.dtype) # giou ratio
(12)接下来就是对所有的实际预测结果和理论预测结果求置信度损失。
lobj += BCEobj(pi[..., 4], tobj) # obj loss
因为只有12个行人对应的预测框的理论置信度被设置成1,其他的预测框的理论置信度都是0。在实际计算过程中,所有YOLO层的实际预测框都会去求置信度损失,但在这些预测框里面其实只有少数是真的含有目标的,这就会导致没有目标的负样本在这个损失部分里占了主导地位,容易使系统的训练方向跑偏,系统变得不怎么敢去预测行人这个结果,所以才会有focal loss损失的出现解决这个问题,但是加入focal loss之后系统又变得过于大胆预测行人,会出现更多误检。
(13)因为我只有行人一个类别,所以类别损失函数就省略不讲了。目标置信度损失函数为BCEWithLogisticLoss,该函数是sigmoid函数和二分类交叉熵损失函数的组合。目标定位损失函数采用的是MSELoss,均方误差应用在目标框上并不是直接计算四个参数和标签数据的均方误差之和,而是计算两框之间的GIOU数值。——————————————————————————————————————————————
以上就是对u版YOLOv3训练过程代码的理解。:D
文章属于个人总结,如有错误之处,请评论指正,不胜感激。(ฅ>ω<*ฅ)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号