【原创】elasticsearch入门
示例
示例一:
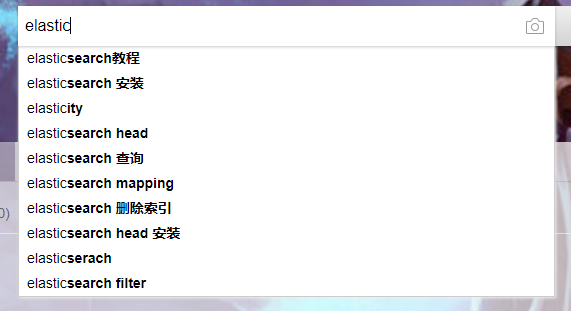
示例二:
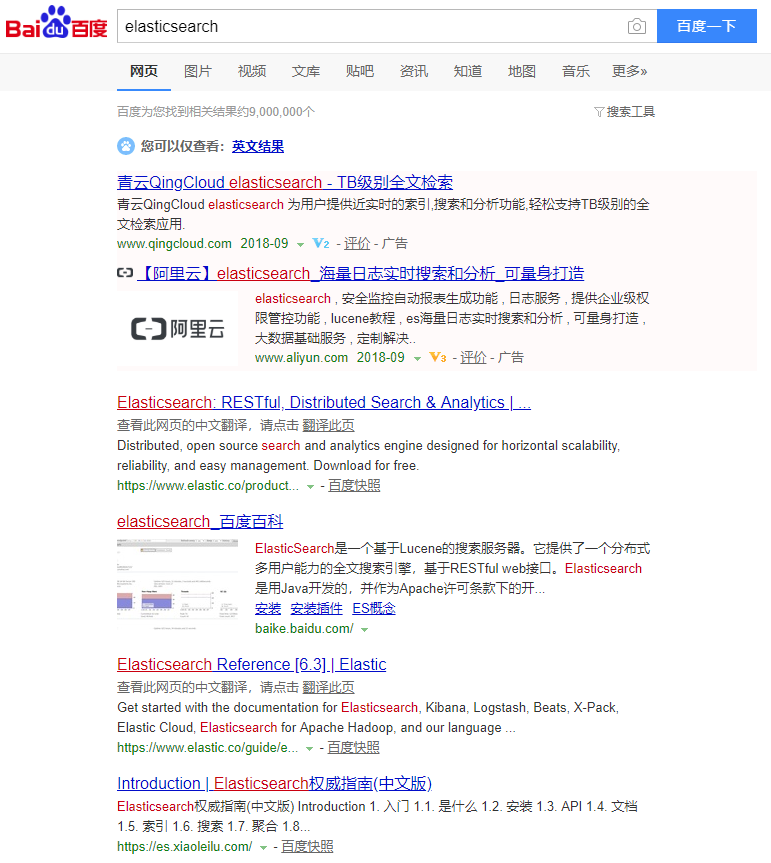
示例三:

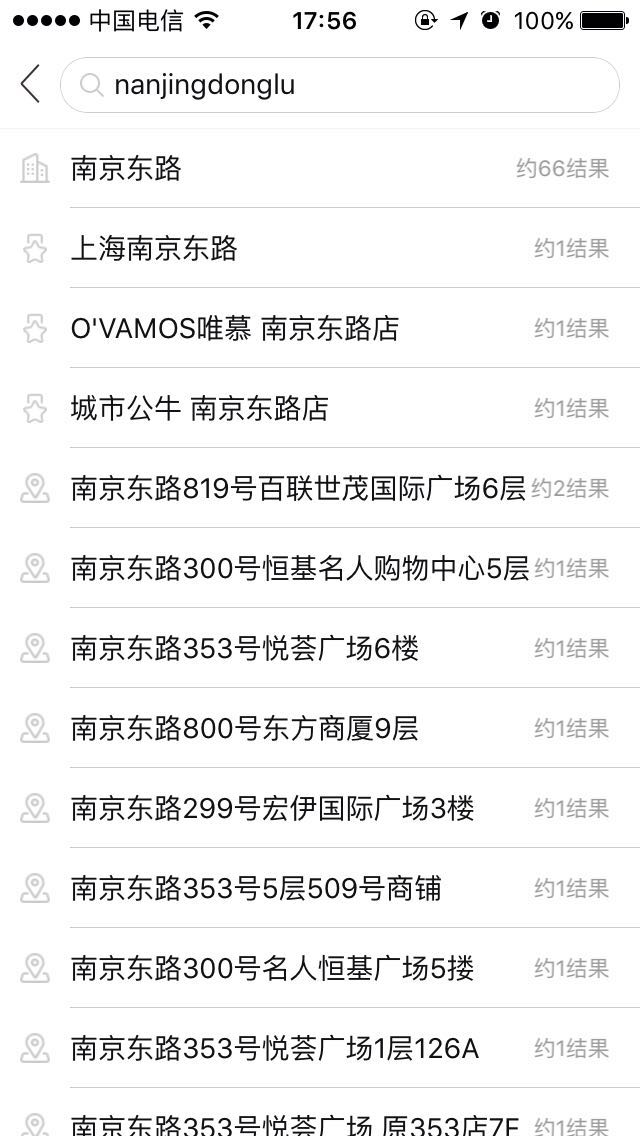



示例四:

ES介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
安装过程
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.0.tar.gz
tar -xvzf elasticsearch-6.4.0.tar.gz
cd elasticsearch-6.4.0/bin
./elasticsearch -d
修改配置文件
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-application
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 192.168.141.129
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
再次启动报错:
[2018-09-13T09:29:43,060][INFO ][o.e.b.BootstrapChecks ] [7hyiUY2] bound or publishing to a non-loopback address, enforcing bootstrap checks
ERROR: [2] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方案:
vi /etc/security/limits.conf # 添加两行行配置,并重连SSH
elasticsearch soft nofile 65536
elasticsearch hard nofile 65537
vi /etc/sysctl.conf # 添加一行配置
vm.max_map_count=262144
sysctl -p
页面访问
地址:
http://192.168.141.129:9200/?pretty
显示:

ES架构
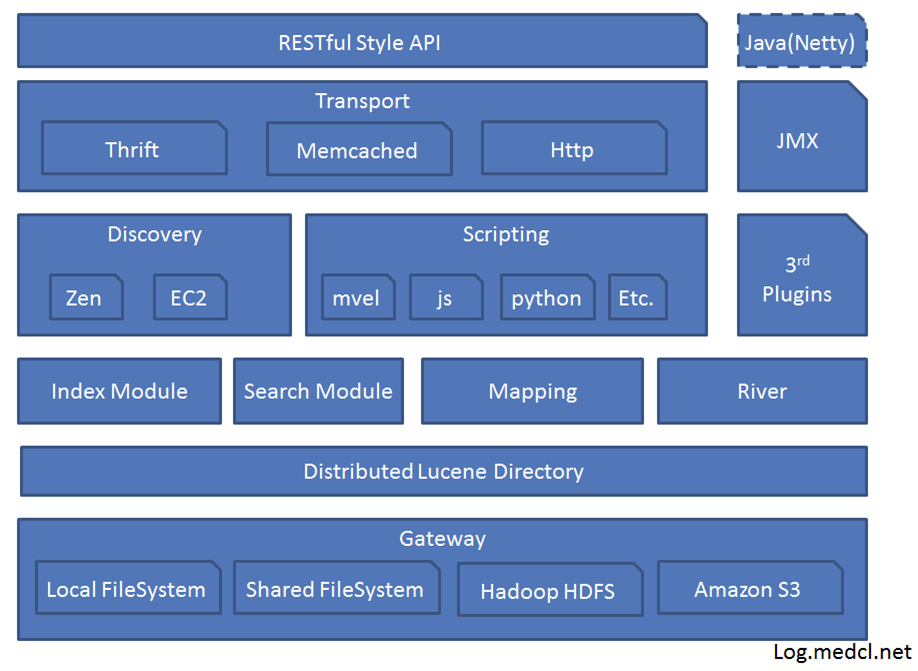
基础概念
https://www.cnblogs.com/xiaochina/p/6855591.html
- 接近实时(NRT)
Elasticsearch 是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个很小的延迟(通常是 1 秒) - 集群(Cluster)
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。 - 节点(Node)
节点是一个单独运行的elasticsearch实例,它属于一个集群。默认情况下,elasticsearch中的每个节点都加入名为“elasticsearch”的集群。每个节点都可以在elasticsearch中使用自己的elasticsearch.yml,它们可以对内存和资源分配有不同的设置。 - 数据节点(Data Node)
数据节点索引文档并对索引文档执行搜索。建议添加更多的数据节点,以提高性能或扩展集群。通过在elasticsearch中设置这些属性,可以使节点成为一个数据节点。elasticsearch.yml配置 - 管理节点(Master Node)
主节点负责集群的管理。对于大型集群,建议有三个专用的主节点(一个主节点和两个备份节点),它们只作为主节点,不存储索引或执行搜索。在elasticsearch.yml配置声明节点为主节点: - 路由节点亦称负载均衡节点(Routing Node or load balancer node)
这些节点不扮演主或数据节点的角色,但只需执行负载平衡,或为搜索请求路由,或将文档编入适当的节点。这对于高容量搜索或索引操作非常有用。 - 索引(Index)
Elasticsearch索引是一组具有共同特征的文档集合。每个索引(index)包含多个类型(type),这些类型依次包含多个文档(document),每个文档包含多个字段(Fields)。在Elasticsearch中索引由多个JSON文档组成。在Elasticsearch集群中可以有多个索引。 - 类型(Type)[Deprecated]
类型用于在索引中提供一个逻辑分区。它基本上表示一类类似类型的文档。一个索引可以有多个类型,我们可以根据上下文来解除它们。 - 文档(Document)。
Elasticsearch文档是一个存储在索引中的JSON文档。每个文档都有一个类型和对应的ID,这是惟一的。 - 映射(Mapping)
映射用于映射文档的每个field及其对应的数据类型,例如字符串、整数、浮点数、双精度数、日期等等。在索引创建过程中,elasticsearch会自动创建一个针对fields的映射,并且根据特定的需求类型,可以很容易地查询或修改这些映射。 - 分片(Shard)
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。 - 副本(Replica)
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。 - river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。 - gateway
代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
| GET /_cat | 命令解释 |
|---|---|
| /_cluster/stats | 查看集群统计信息 |
| /_cat/allocation | |
| /_cat/shards | |
| /_cat/shards/ | |
| /_cat/master | |
| /_cat/nodes | 查看集群的节点列表 |
| /_cat/tasks | |
| /_cat/indices | 查看所有索引 |
| /_cat/indices/ | 查看指定索引 |
| /_cat/segments | |
| /_cat/segments/ | |
| /_cat/count | |
| /_cat/count/ | |
| /_cat/recovery | |
| /_cat/recovery/ | |
| /_cat/health | 查看集群的健康状况 |
| /_cat/pending_tasks | |
| /_cat/aliases | |
| /_cat/aliases/ | |
| /_cat/thread_pool | |
| /_cat/thread_pool/ | |
| /_cat/plugins | |
| /_cat/fielddata | |
| /_cat/fielddata/ | |
| /_cat/nodeattrs | |
| /_cat/repositories | |
| /_cat/snapshots/ | |
| /_cat/templates | |
| /_stats | 查看所有的索引状态 |
- v是用来要求在结果中返回表头
- pretty 格式化json
- help 帮助
状态值说明
- Green - everything is good (cluster is fully functional),即最佳状态
- Yellow - all data is available but some replicas are not yet allocated (cluster is fully functional),即数据和集群可用,但是集群的备份有的是坏的
- Red - some data is not available for whatever reason (cluster is partially functional),即数据和集群都不可用
索引管理
创建索引
直接创建
PUT twitter
settings
PUT twitter
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}
mappings
PUT twitter
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
},
"mappings" : {
"_doc" : {
"properties" : {
"field1" : { "type" : "text" }
}
}
}
}
查看索引
GET /twitter/
GET /twitter/_search
删除索引
DELETE /twitter
映射管理
Core Datatypes 核心类型
string
text and keyword
Numeric datatypes
long, integer, short, byte, double, float, half_float, scaled_float
Date datatype
date
Boolean datatype
boolean
Binary datatype
binary
Range datatypes 范围
integer_range, float_range, long_range, double_range, date_range
Complex datatypes 复合类型
Array datatype
数组就是多值,不需要专门的类型
Object datatype
object :表示值为一个JSON 对象
Nested datatype
nested:for arrays of JSON objects(表示值为JSON对象数组 )
Geo datatypes 地理数据类型
Geo-point datatype
geo_point: for lat/lon points (经纬坐标点)
Geo-Shape datatype
geo_shape: for complex shapes like polygons (形状表示)
Specialised datatypes 特别的类型
IP datatype
ip: for IPv4 and IPv6 addresses
Completion datatype
completion: to provide auto-complete suggestions
Token count datatype
token_count: to count the number of tokens in a string
mapper-murmur3
murmur3: to compute hashes of values at index-time and store them in the index
Percolator type
Accepts queries from the query-dsl
join datatype
Defines parent/child relation for documents within the same index
文档管理
新建
指定id
PUT twitter/_doc/1
{
"id": 1,
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
自动生成id
POST twitter/_doc/
{
"id": 1,
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
查看
HEAD twitter/_doc/11
GET twitter/_doc/1
更新
PUT twitter/_doc/1
{
"id": 1,
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
删除
DELETE twitter/_doc/1
批处理
POST _bulk
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
index 无论是否存在,都会成功
create 存在会提示
update 不存在会提示
delete 不存在会提示
结构化搜索
精确值查找term
POST /my_store/_doc/_bulk
{ "index": { "_id": 1 }}
{ "price" : 10, "productID" : "XHDK-A-1293-#fJ3" }
{ "index": { "_id": 2 }}
{ "price" : 20, "productID" : "KDKE-B-9947-#kL5" }
{ "index": { "_id": 3 }}
{ "price" : 30, "productID" : "JODL-X-1937-#pV7" }
{ "index": { "_id": 4 }}
{ "price" : 30, "productID" : "QQPX-R-3956-#aD8" }
一个字段查询
GET my_store/_doc/_search
{
"query": {
"term": {
"price": "30"
}
}
}
组合过滤
GET my_store/_doc/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"price": 20
}
},
{
"term": {
"productID": "XHDK-A-1293-#fJ3"
}
}
],
"must_not": {
"term": {
"price": 30
}
}
}
}
}
PUT my_store
{
"mappings" : {
"_doc" : {
"properties" : {
"productID" : {
"type" : "keyword"
}
}
}
}
}
GET /my_store/_analyze
{
"field": "productID",
"text": "XHDK-A-1293-#fJ3"
}
高亮
GET my_store/_doc/_search
{
"query": {
"match": {
"productID": "b"
}
},
"highlight": {
"pre_tags" : ["<span class='hlt'>"],
"post_tags" : ["</span>"],
"title": {},
"content": {}
}
}
}
全文搜索
POST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" }
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps over the quick dog" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox brown dog" }
匹配查询
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "QUICK!"
}
}
}
GET /my_index/_analyze
{
"field": "title",
"text": "QUICK!"
}
组合查询
GET /my_index/my_type/_search
{
"query": {
"bool": {
"must": { "match": { "title": "quick" }},
"must_not": { "match": { "title": "lazy" }},
"should": [
{ "match": { "title": "brown" }},
{ "match": { "title": "dog" }}
]
}
}
}
分词
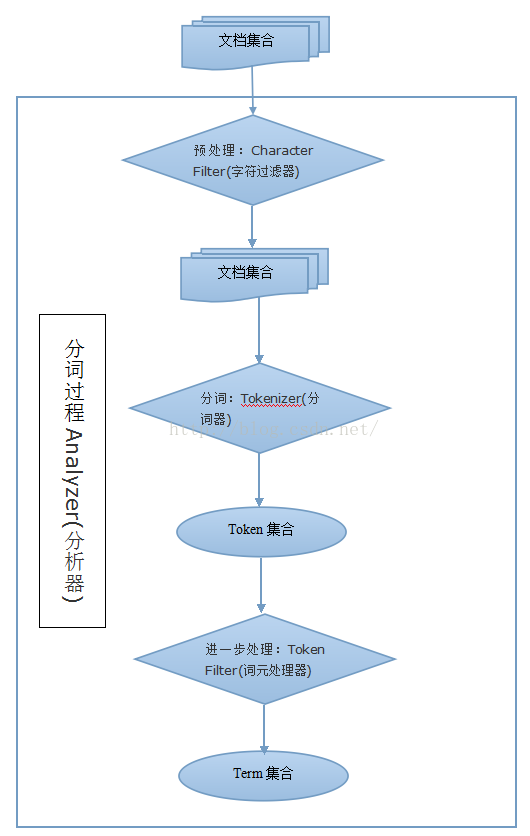
- character filter :字符过滤器,对文本进行字符过滤处理,如处理文本中的html标签字符。处理完后再交给tokenizer进行分词。一个analyzer中可包含0个或多个字符过滤器,多个按配置顺序依次进行处理。
- tokenizer:分词器,对文本进行分词。一个analyzer必需且只可包含一个tokenizer。
- token filter:词项过滤器,对tokenizer分出的词进行过滤处理。如转小写、停用词处理、同义词处理。一个analyzer可包含0个或多个词项过滤器,按配置顺序进行过滤。
测试分词器
POST _analyze
{
"tokenizer": "standard",
"char_filter": [ "html_strip" ],
"filter": [ "lowercase", "asciifolding" ],
"text": "Is this déja vu?"
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "微知"
}
内置的分析器
- Standard Analyzer
- Simple Analyzer
- Whitespace Analyzer
- Stop Analyzer
- Keyword Analyzer
- Pattern Analyzer
- Language Analyzers
- Fingerprint Analyzer
- Custom analyzers
内建的character filter
- HTML Strip Character Filter
html_strip :过滤html标签,解码HTML entities like &. - Mapping Character Filter
mapping :用指定的字符串替换文本中的某字符串。 - Pattern Replace Character Filter
pattern_replace :进行正则表达式替换。
内建的Tokenizer
- Standard Tokenizer
- Letter Tokenizer
- Lowercase Tokenizer
- Whitespace Tokenizer
- UAX URL Email Tokenizer
- Classic Tokenizer
- Thai Tokenizer
- NGram Tokenizer
- Edge NGram Tokenizer
- Keyword Tokenizer
- Pattern Tokenizer
- Simple Pattern Tokenizer
- Simple Pattern Split Tokenizer
- Path Hierarchy Tokenizer
示例
PUT customer
{
"mappings": {
"_doc": {
"properties": {
"customerName": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"companyId": {
"type": "text"
}
}
}
}
}
POST /customer/_doc/_bulk
{ "index": { "_id": 1 }}
{ "companyId": "55", "customerName": "微知(上海)服务外包有限公司" }
{ "index": { "_id": 2 }}
{ "companyId": "55", "customerName": "上海微盟" }
{ "index": { "_id": 3 }}
{ "companyId": "55", "customerName": "上海知道广告有限公司" }
{ "index": { "_id": 4 }}
{ "companyId": "55", "customerName": "微鲸科技有限公司" }
{ "index": { "_id": 5}}
{ "companyId": "55", "customerName": "北京微尘大业电子商务" }
{ "index": { "_id": 6}}
{ "companyId": "55", "customerName": "福建微冲企业咨询有限公司" }
{ "index": { "_id": 7}}
{ "companyId": "55", "customerName": "上海知盛企业管理咨询有限公司" }
GET /customer/_doc/_search
{
"query": {
"match": {
"customerName": "知道"
}
}
}
GET /customer/_doc/_search
{
"query": {
"match": {
"customerName": "微知"
}
}
}
更多学习资料
- https://www.cnblogs.com/leeSmall/category/1210814.html
- https://blog.csdn.net/ricky110/article/category/7336900
- 官方的reference:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
| 标题 | 链接 |
|---|---|
| elasticsearch系列一:elasticsearch(ES简介、安装&配置、集成Ikanalyzer) | https://www.cnblogs.com/leeSmall/p/9189078.html |
| elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名) | https://www.cnblogs.com/leeSmall/p/9193476.html |
| elasticsearch系列三:索引详解(分词器、文档管理、路由详解(集群)) | https://www.cnblogs.com/leeSmall/p/9195782.html |
| elasticsearch系列四:搜索详解(搜索API、Query DSL) | https://www.cnblogs.com/leeSmall/p/9206641.html |
| elasticsearch系列五:搜索详解(查询建议介绍、Suggester 介绍) | https://www.cnblogs.com/leeSmall/p/9206646.html |
| elasticsearch系列六:聚合分析(聚合分析简介、指标聚合、桶聚合) | https://www.cnblogs.com/leeSmall/p/9215909.html |
| elasticsearch系列七:ES Java客户端-Elasticsearch Java client | https://www.cnblogs.com/leeSmall/p/9218779.html |
| elasticsearch系列八:ES 集群管理(集群规划、集群搭建、集群管理) | https://www.cnblogs.com/leeSmall/p/9220535.html |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号