【Python爬虫】爬取云班课资源,活动
写在前面
最近学校好多老师使用云班课,在一门课程结束后,想要看看同学们的作业(以活动形式提交的)怎么办呢?云班课并没有给学生端提供批量下载这个功能。
再加上某位老师新发布的教学任务,居然设置了视频不允许拖动不允许倍速😥,所以正好有时间,想写个爬虫再练练手,进行云班课资源,活动的爬取。
下面将会较为详细的介绍活动的爬取,这里是交的两种格式的作业(word和pdf),并在最后给出完整的活动爬取代码,以及类似的资源(也就是视频格式的)爬取代码。
登录
当我企图直接使用request库访问云班课的活动页面时,倒是返回200爬下来了一个html,但是诶怎么找不到想要的链接,于是我把这个爬下来的html本地复制了一下,发现如下图:
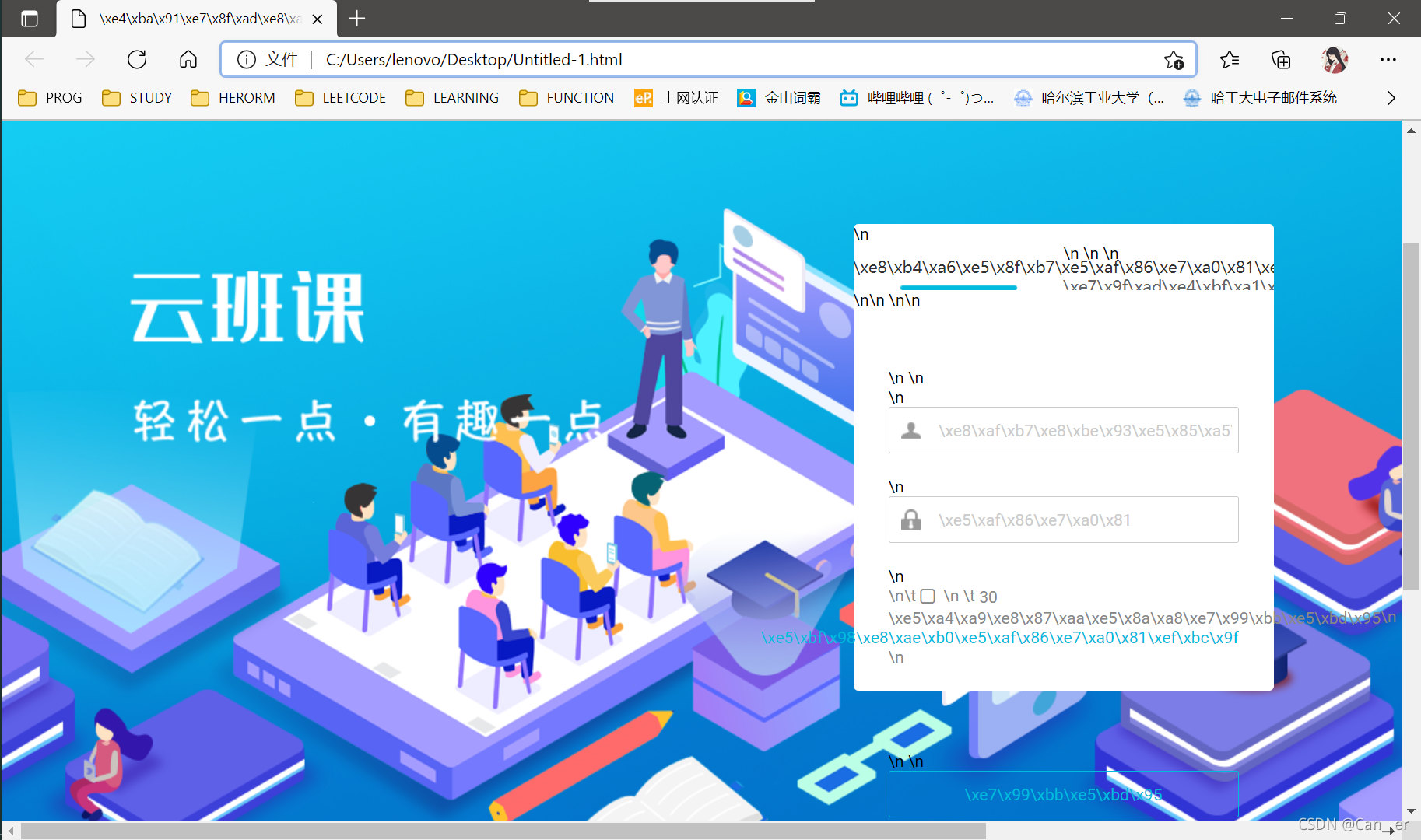
好吧,还没有登录。我们模仿这个登录的过程有两种方法,一种是获得session,另一种是带着cookies(关于这俩个东西是什么就不介绍啦,其实后文会发现本质都是相同的,相当于你的通行证)。
-
获取session:requests库中已经封装好了方法
requests.session(),我们要做的事情就是- 获取session
- 根据登录时发的包(这里需要自己去抓包分析格式),按同样同样封装一个data和header(非必须,有些网站可能会有反爬虫机制)
- 让该session向 登录网页(一定是登录网页,想想没登陆的时候会自己重定向到的也是登录的网页) 发送这个包,也就是模拟登录了
def getsession(account_name, user_pwd): logURL = r'https://www.mosoteach.cn/web/index.php?c=passport&m=account_login' session = requests.session() logHeader = { 'Referer': 'https://www.mosoteach.cn/web/index.php?c=passport', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko' } logData = { 'account_name': account_name, 'user_pwd': user_pwd, 'remember_me': 'Y' } logRES = session.post(logURL, headers=logHeader, data=logData) return session这个时候,如果你
print一下session中的属性,会发现session中有一个字段叫做cookies,是这个样子滴:
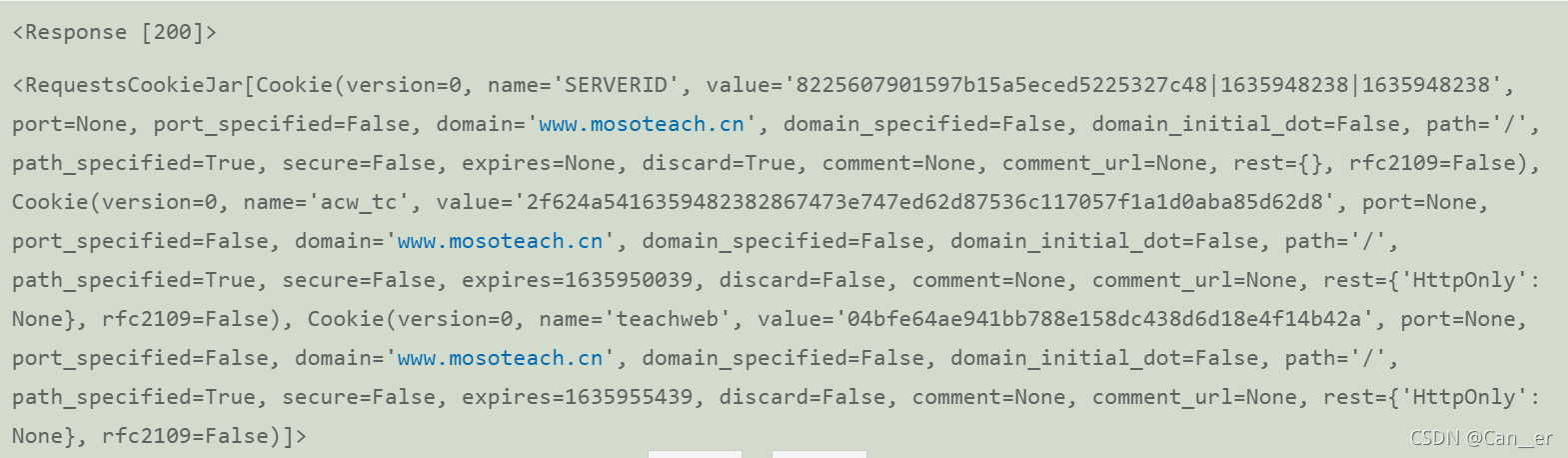
我们模拟登录获取session也是为了让它自身携带着这个cookie去完成后面的工作。 -
带着cookies:不用模拟登录,直接在网页版上登录之后,得到自己的cookie
- 获取cookies的方法可以点这个链接,讲的很详细了
- 然后带着cookie,封装进header,发包~也就相当于告诉了服务器你是谁
header = { "Cookie": cookie, 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko', 'Connection': 'Keep-Alive' }
获取作业列表
我期望获得的是这样一个形式,{“文件名”:“下载url”},并且pdf和word分开下载。首先还是去检查(网页上右击或者F12)一下,怎么才能得到这两个信息:
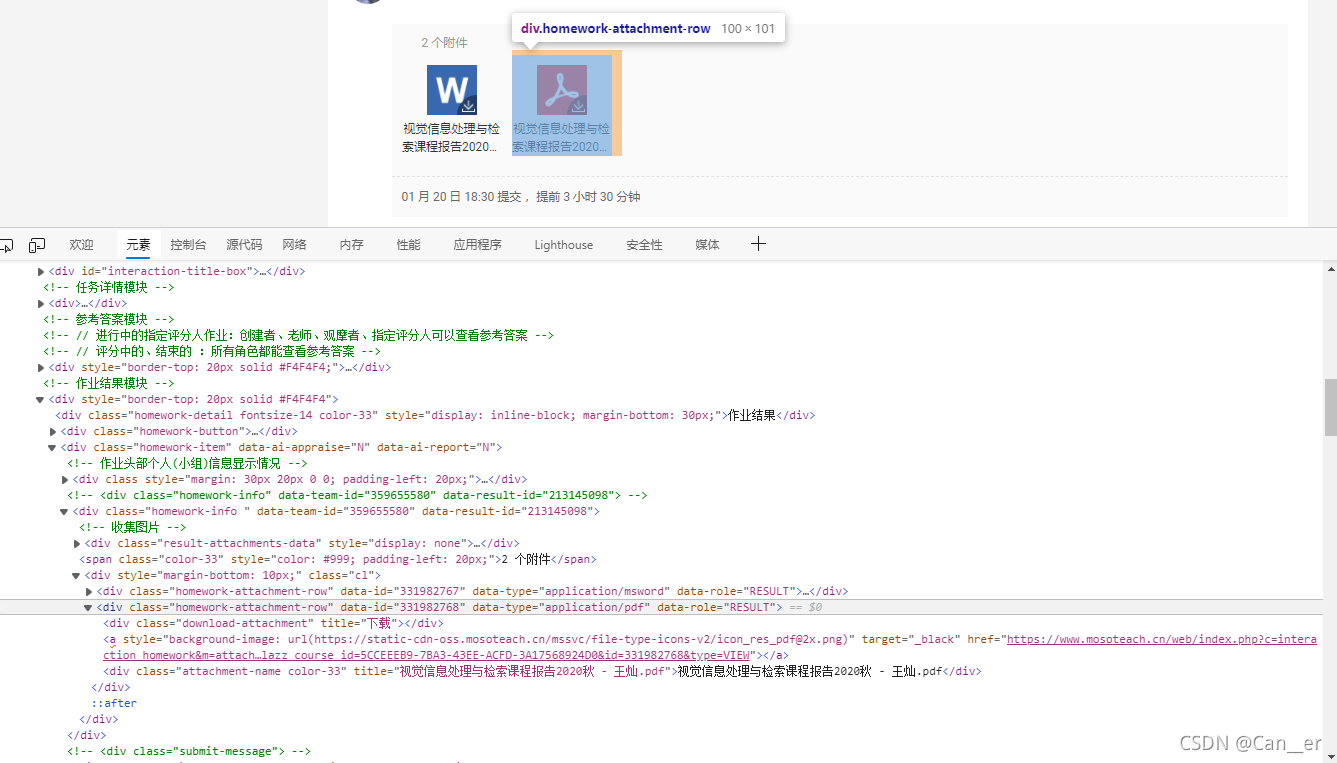
可能看不清,我给复制到这里来了:
<div class="homework-attachment-row" data-id="331982768" data-type="application/pdf" data-role="RESULT">
<div class="download-attachment" title="下载"></div>
<a style="background-image: url(https://static-cdn-oss.mosoteach.cn/mssvc/file-type-icons-v2/icon_res_pdf@2x.png)" target="_black" href="https://www.mosoteach.cn/web/index.php?c=interaction_homework&m=attachment_url&clazz_course_id=5CCEEEB9-7BA3-43EE-ACFD-3A17568924D0&id=331982768&type=VIEW"></a>
<div class="attachment-name color-33" title="视觉信息处理与检索课程报告2020秋 - 人名.pdf">视觉信息处理与检索课程报告2020秋 - 人名.pdf</div>
</div>
可以发现,每个资源都存在一个类为homework-attachment-row的<div>下,而我们用到的是homework-attachment-row下的两个东西:
<a>对应的是url,但是如果点击这个图标,实际上是默认浏览的。查看“网络”页面,点击下载一下pdf,会发现其真正的url是那一大串href,把最后的VIEW改成DOWNLOAD(哈哈其实我没看http包的时候就直接猜中了)attachment-name color-33对应的是名字,没什么好说的
然后就是使用BeautifulSoup库的一个元素处理和选择啦,上代码:
def getdic(url):
pdfdic, worddic = {}, {}
# 改成人眼可读的编码
raw_data = session.get(url).content.decode('utf-8')
data = BeautifulSoup(raw_data, 'html5lib')
# 获取每个资源框
homeworks = data.select('.homework-attachment-row')
# 对每个资源进行分解处理,获取name和url
for homework in homeworks:
name = homework.select('.attachment-name')[0]['title']
url = homework.select('a')[0]['href']
if '.pdf' in name:
pdfdic[name] = url
elif ('.doc' in name):
worddic[name] = url
worddic.pop('视觉信息处理与检索课程报告2020秋 - XXX.doc')
return pdfdic, worddic
这是我们获取出来的样子,结果发现,两个列表长度不匹配(worddic中多了两个),可以发现第一个资源中有老师上传的doc模板,需要pop掉:

另外一个。。。是因为当时我使用的是print(1 if ('.docx' or '.docx' in name) else 0),而python执行逻辑是先in再or,永远为True,所以混进来了一个同学作业里交的视频'test1_face_result.mp4',我点开一看,是个ai换脸的功能演示,乐半天,感受一下哈哈哈,就离谱。
下载
最后,就是下载,对列表中的每一个元素的url发包,获取bytes,然后按块写入!别忘了对url的一个处理,毕竟我们直接分析得到的是VIEW模式。
def download(dic, dir):
os.makedirs(dir, exist_ok=True)
for name, url in tqdm(dic.items()):
url = url.replace("VIEW", "DOWNLOAD")
# 像目标url地址发送get请求,返回一个response对象
data = session.get(url=url, stream=True)
with open(dir+"/"+name, "wb") as f:
for chunk in data.iter_content(chunk_size=512):
f.write(chunk)
加个优雅的进度条,看看效果:
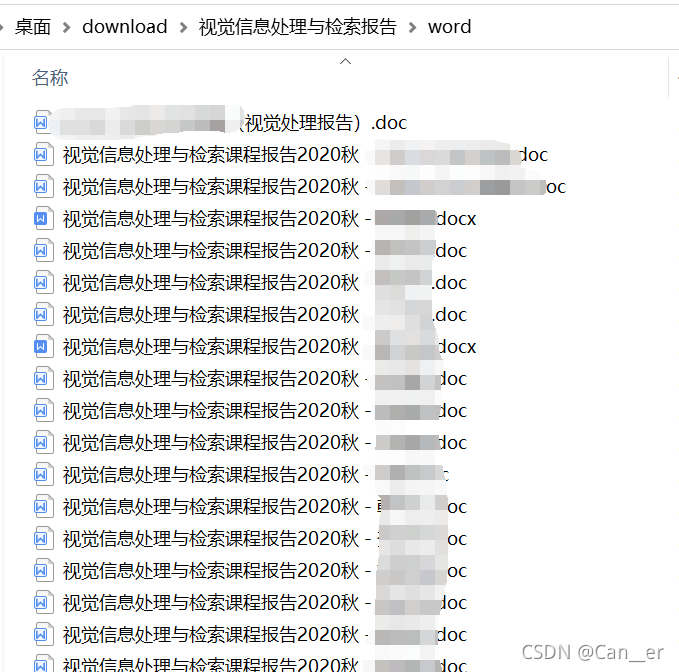
嗯,很让人满意。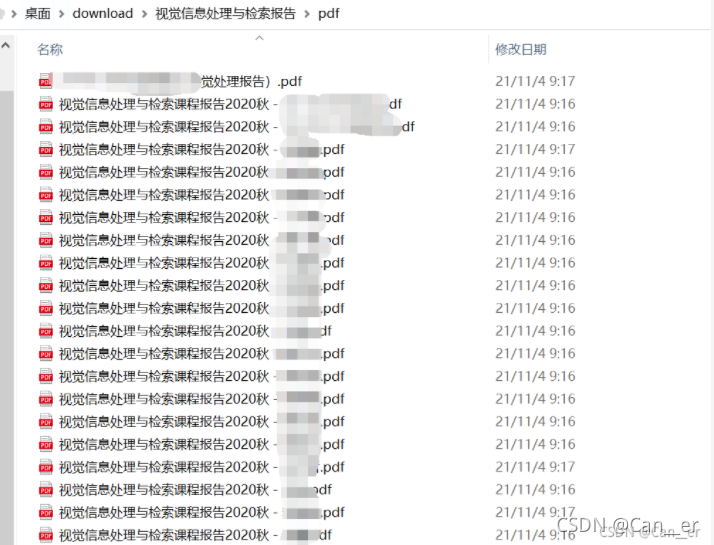
代码
下载资源的(函数体上面已经给出)
import requests
import os
from bs4 import BeautifulSoup
from tqdm import tqdm
# 活动链接
inter_url = '填上你浏览器上的链接,一定是https://www.mosoteach.cn/web/index.php?c=interaction_homework&开头的'
# 用户名
account_name = '填上你的用户名'
# 密码
user_pwd = '填上你的密码'
# 你想要保存在的文件夹地址
pdf_dir = "视觉信息处理与检索报告/pdf"
word_dir = "视觉信息处理与检索报告/word"
# 模拟登录
session = getsession(account_name, user_pwd)
# 获取资源列表
pdfdic, worddic = getdic(inter_url)
# 下载
download(pdfdic, pdf_dir)
download(worddic, word_dir)
下载视频的
这个还是有点费劲的,因为它收发包的逻辑是这样的:

点击视频,发过去的是一个请求,返回的是m3u8文件的下载url,下载这个m3u8,然后用记事本打开,发现:
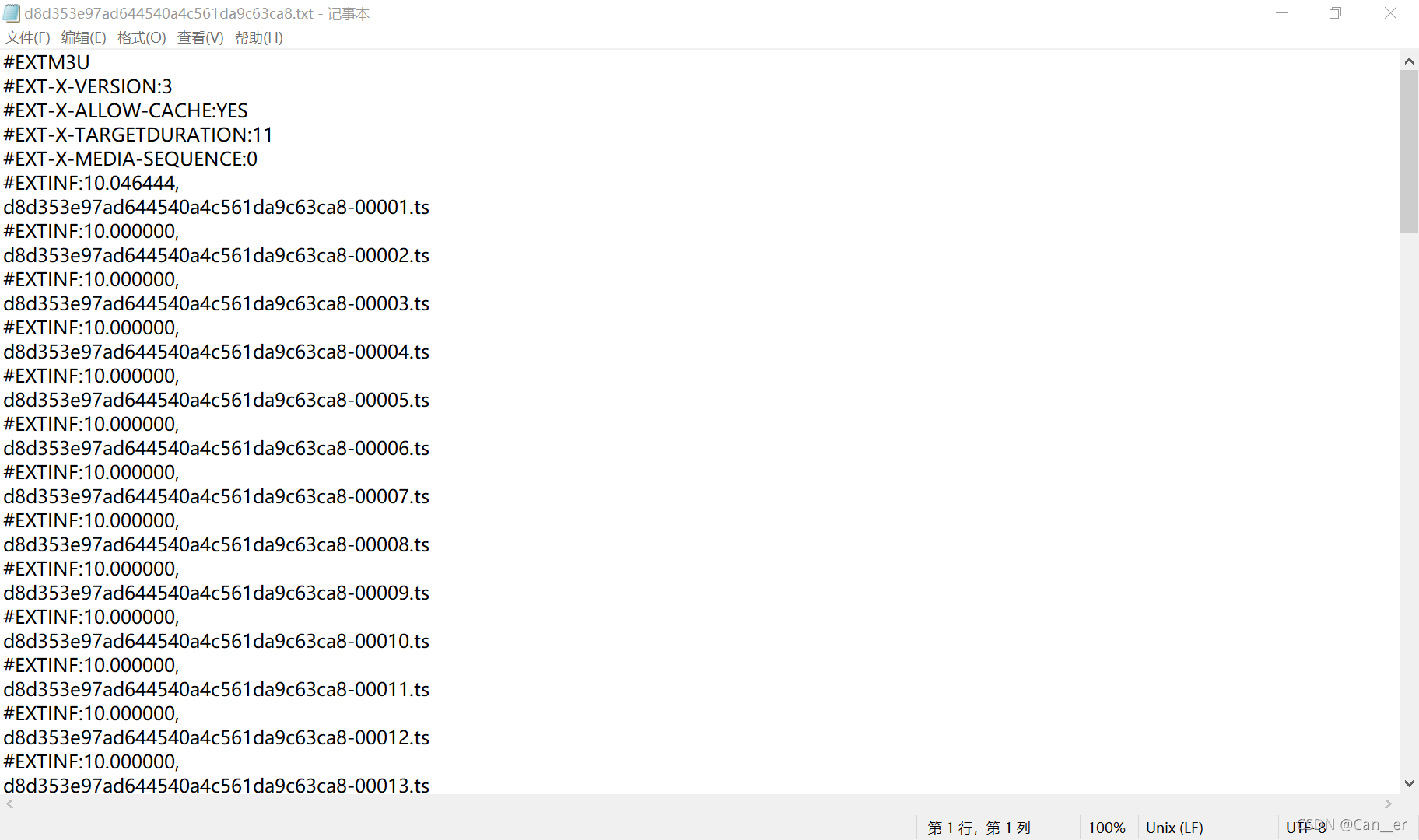
这才是对应的视频列表,每段10秒钟左右,真的无语,可能检测学生有没有看也是通过这个有没有请求到最后一个包来判断的吧。
然后下面就是不断的发包收包的过程,也是这个博主写的使用m3u8爬取云班课视频的方法。
但我老觉得一定有更简单的途径,譬如。。。这段html。之所以能找到,是因为有了前面扒活动的经验,搜了一下DOWNLOAD,而不是按照它网络中的收发包来检查的,嘿嘿。
然后,开始行动吧。
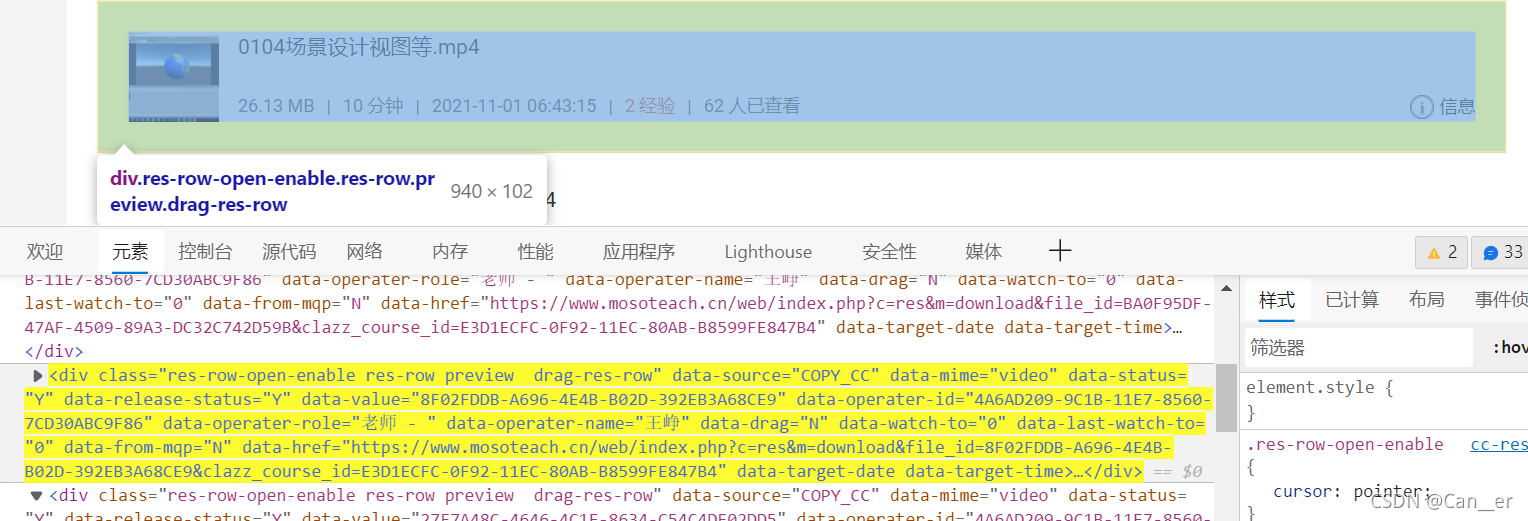
import requests
import os
from bs4 import BeautifulSoup
from tqdm import tqdm
# 资源链接
res_url = '填上你浏览器上的链接,一定是https://www.mosoteach.cn/web/index.php?c=res&开头的'
# 用户名
account_name = '填上你的用户名'
# 密码
user_pwd = '填上你的密码'
# 你想要保存在的文件夹地址
mov_dir = "虚拟现实开发技术"
def getsession(account_name, user_pwd):
logURL = r'https://www.mosoteach.cn/web/index.php?c=passport&m=account_login'
session = requests.session()
logHeader = {
'Referer': 'https://www.mosoteach.cn/web/index.php?c=passport',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
logData = {
'account_name': account_name,
'user_pwd': user_pwd,
'remember_me': 'Y'
}
logRES = session.post(logURL, headers=logHeader, data=logData)
return session
def getdic(url):
movdic = {}
# 改成人眼可读的编码
raw_data = session.get(url).content.decode('utf-8')
data = BeautifulSoup(raw_data, 'html5lib')
# 获取每个资源框
movs = data.select('.res-row-open-enable')
# 对每个资源进行分解处理,获取name和url
for mov in movs:
name = mov.select('.res-info .overflow-ellipsis .res-name')[0].text
url = mov['data-href']
movdic[name] = url
return movdic
def download(dic, dir):
os.makedirs(dir, exist_ok=True)
for name, url in tqdm(dic.items()):
# 像目标url地址发送get请求,返回一个response对象
data = session.get(url=url, stream=True)
with open(dir+"/"+name, "wb") as f:
for chunk in data.iter_content(chunk_size=512):
f.write(chunk)
session = getsession(account_name, user_pwd)
movdic = getdic(res_url)
download(movdic, mov_dir)
更新:如何下载指定几个资源
每次放出资源都要再爬一遍,比较慢,新加一个切片函数,对字典进行处理。
# 从第几个视频开始下载,下载到第几个视频,隔几个下一次
# 如果全部下载直接注释,下面参数不用填
start, end, step = 13, 28, 1
def dicslice(dic, start=None, end=None, step=None):
return dict(list(dic.items())[start:end:])
session = getsession(account_name, user_pwd)
movdic = getdic(res_url)
resdic = dicslice(movdic, start-1, end)
download(resdic, mov_dir)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号