
iOS图片加载速度极限优化—FastImageCache解析
本文转载至 http://blog.cnbang.net/tech/2578/
FastImageCache是Path团队开发的一个开源库,用于提升图片的加载和渲染速度,让基于图片的列表滑动起来更顺畅,来看看它是怎么做的。
优化点
iOS从磁盘加载一张图片,使用UIImageVIew显示在屏幕上,需要经过以下步骤:
- 从磁盘拷贝数据到内核缓冲区
- 从内核缓冲区复制数据到用户空间
- 生成UIImageView,把图像数据赋值给UIImageView
- 如果图像数据为未解码的PNG/JPG,解码为位图数据
- CATransaction捕获到UIImageView layer树的变化
- 主线程Runloop提交CATransaction,开始进行图像渲染
- 6.1 如果数据没有字节对齐,Core Animation会再拷贝一份数据,进行字节对齐。
- 6.2 GPU处理位图数据,进行渲染。
FastImageCache分别优化了2,4,6.1三个步骤:
- 使用mmap内存映射,省去了上述第2步数据从内核空间拷贝到用户空间的操作。
- 缓存解码后的位图数据到磁盘,下次从磁盘读取时省去第4步解码的操作。
- 生成字节对齐的数据,防止上述第6.1步CoreAnimation在渲染时再拷贝一份数据。
接下来具体介绍这三个优化点以及它的实现。
内存映射
平常我们读取磁盘上的一个文件,上层API调用到最后会使用系统方法read()读取数据,内核把磁盘数据读入内核缓冲区,用户再从内核缓冲区读取数据复制到用户内存空间,这里有一次内存拷贝的时间消耗,并且读取后整个文件数据就已经存在于用户内存中,占用了进程的内存空间。
FastImageCache采用了另一种读写文件的方法,就是用mmap把文件映射到用户空间里的虚拟内存,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,相当于已经把整个文件放入内存,但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作,只有真正使用这些数据时,也就是图像准备渲染在屏幕上时,虚拟内存管理系统VMS才根据缺页加载的机制从磁盘加载对应的数据块到物理内存,再进行渲染。这样的文件读写文件方式少了数据从内核缓存到用户空间的拷贝,效率很高。
解码图像
一般我们使用的图像是JPG/PNG,这些图像数据不是位图,而是是经过编码压缩后的数据,使用它渲染到屏幕之前需要进行解码转成位图数据,这个解码操作是比较耗时的,并且没有GPU硬解码,只能通过CPU,iOS默认会在主线程对图像进行解码。很多库都解决了图像解码的问题,不过由于解码后的图像太大,一般不会缓存到磁盘,SDWebImage的做法是把解码操作从主线程移到子线程,让耗时的解码操作不占用主线程的时间。
FastImageCache也是在子线程解码图像,不同的是它会缓存解码后的图像到磁盘。因为解码后的图像体积很大,FastImageCache对这些图像数据做了系列缓存管理,详见下文实现部分。另外缓存的图像体积大也是使用内存映射读取文件的原因,小文件使用内存映射无优势,内存拷贝的量少,拷贝后占用用户内存也不高,文件越大内存映射优势越大。
字节对齐
Core Animation在图像数据非字节对齐的情况下渲染前会先拷贝一份图像数据,官方文档没有对这次拷贝行为作说明,模拟器和Instrument里有高亮显示“copied images”的功能,但似乎它有bug,即使某张图片没有被高亮显示出渲染时被copy,从调用堆栈上也还是能看到调用了CA::Render::copy_image方法:

那什么是字节对齐呢,按我的理解,为了性能,底层渲染图像时不是一个像素一个像素渲染,而是一块一块渲染,数据是一块块地取,就可能遇到这一块连续的内存数据里结尾的数据不是图像的内容,是内存里其他的数据,可能越界读取导致一些奇怪的东西混入,所以在渲染之前CoreAnimation要把数据拷贝一份进行处理,确保每一块都是图像数据,对于不足一块的数据置空。大致图示:(pixel是图像像素数据,data是内存里其他数据)
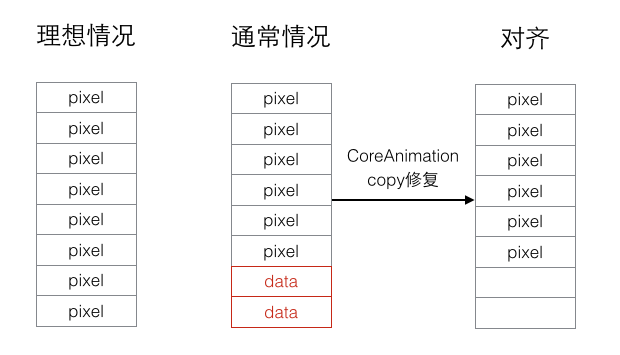
块的大小应该是跟CPU cache line有关,ARMv7是32byte,A9是64byte,在A9下CoreAnimation应该是按64byte作为一块数据去读取和渲染,让图像数据对齐64byte就可以避免CoreAnimation再拷贝一份数据进行修补。FastImageCache做的字节对齐就是这个事情。
实现
FastImageCache把同个类型和尺寸的图像都放在一个文件里,根据文件偏移取单张图片,类似web的css雪碧图,这里称为ImageTable。这样做主要是为了方便统一管理图片缓存,控制缓存的大小,整个FastImageCache就是在管理一个个ImageTable的数据。整体实现的数据结构如图:
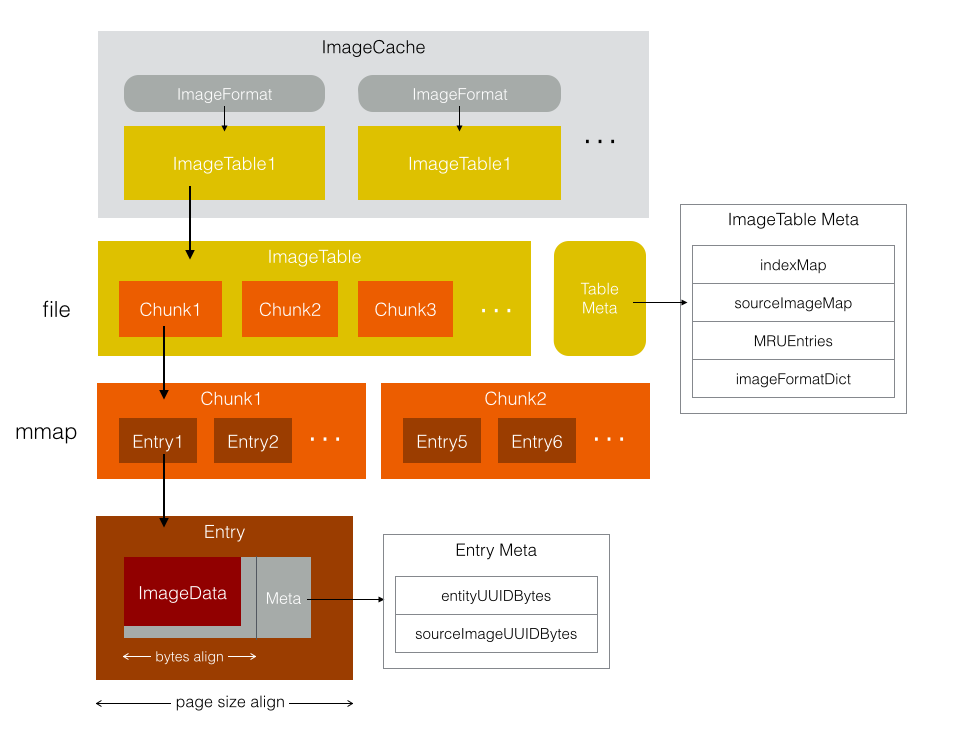
一些补充和说明:
ImageTable
- 一个ImageFormat对应一个ImageTable,ImageFormat指定了ImageTable里图像渲染格式/大小等信息,ImageTable里的图像数据都由ImageFormat规定了统一的尺寸,每张图像大小都是一样的。
- 一个ImageTable一个实体文件,并有另一个文件保存这个ImageTable的meta信息。
- 图像使用entityUUID作为唯一标示符,由用户定义,通常是图像url的hash值。ImageTable Meta的indexMap记录了entityUUID->entryIndex的映射,通过indexMap就可以用图像的entityUUID找到缓存数据在ImageTable对应的位置。
ImageTableEntry
- ImageTable的实体数据是ImageTableEntry,每个entry有两部分数据,一部分是对齐后的图像数据,另一部分是meta信息,meta保存这张图像的UUID和原图UUID,用于校验图像数据的正确性。
- Entry数据是按内存分页大小对齐的,数据大小是内存分页大小的整数倍,这样可以保证虚拟内存缺页加载时使用最少的内存页加载一张图像。
- 图像数据做了字节对齐处理,CoreAnimation使用时无需再处理拷贝。具体做法是CGBitmapContextCreate创建位图画布时bytesPerRow参数传64倍数。
Chunk
- ImageTable和实体数据Entry间多了层Chunk,Chunk是逻辑上的数据划分,N个Entry作为一个Chunk,内存映射mmap操作是以chunk为单位的,每一个chunk执行一次mmap把这个chunk的内容映射到虚拟内存。为什么要多一层chunk呢,按我的理解,这样做是为了灵活控制mmap的大小和调用次数,若对整个ImageTable执行mmap,载入虚拟内存的文件过大,若对每个Entry做mmap,调用次数会太多。
缓存管理
- 用户可以定义整个ImageTable里最大缓存的图像数量,在有新图像需要缓存时,如果缓存没有超过限制,会以chunk为单位扩展文件大小,顺序写下去。如果已超过最大缓存限制,会把最少使用的缓存替换掉,实现方法是每次使用图像都会把UUID插入到MRUEntries数组的开头,MRUEntries按最近使用顺序排列了图像UUID,数组里最后一个图像就是最少使用的。被替换掉的图片下次需要再使用时,再走一次取原图—解压—存储的流程。
使用
FastImageCache适合用于tableView里缓存每个cell上同样规格的图像,优点是能极大加快第一次从磁盘加载这些图像的速度。但它有两个明显的缺点:一是占空间大。因为缓存了解码后的位图到磁盘,位图是很大的,宽高100*100的图像在2x的高清屏设备下就需要200*200*4byte/pixel=156KB,这也是为什么FastImageCache要大费周章限制缓存大小。二是接口不友好,需预定义好缓存的图像尺寸。FastImageCache无法像SDWebImage那样无缝接入UIImageView,使用它需要配置ImageTable,定义好尺寸,手动提供的原图,每种实体图像要定义一个FICEntity模型,使逻辑变复杂。
FastImageCache已经属于极限优化,做图像加载/渲染优化时应该优先考虑一些低代价高回报的优化点,例如CALayer代替UIImageVIew,减少GPU计算(去透明/像素对齐),图像子线程解码,避免Offscreen-Render等。在其他优化都做到位,图像的渲染还是有性能问题的前提下才考虑使用FastImageCache进一步提升首次加载的性能,不过字节对齐的优化倒是可以脱离FastImageCache直接运用在项目上,只需要在解码图像时bitmap画布的bytesPerRow设为64的倍数即可。

