软工第三次作业
软工1816 · 第三次作业 - 结对项目1
非常无敌超级优秀的结对队友(感谢他带我飞,这是真心的话):乐忠豪
原型模型
原型模型设计工具:Axure RP 8.0
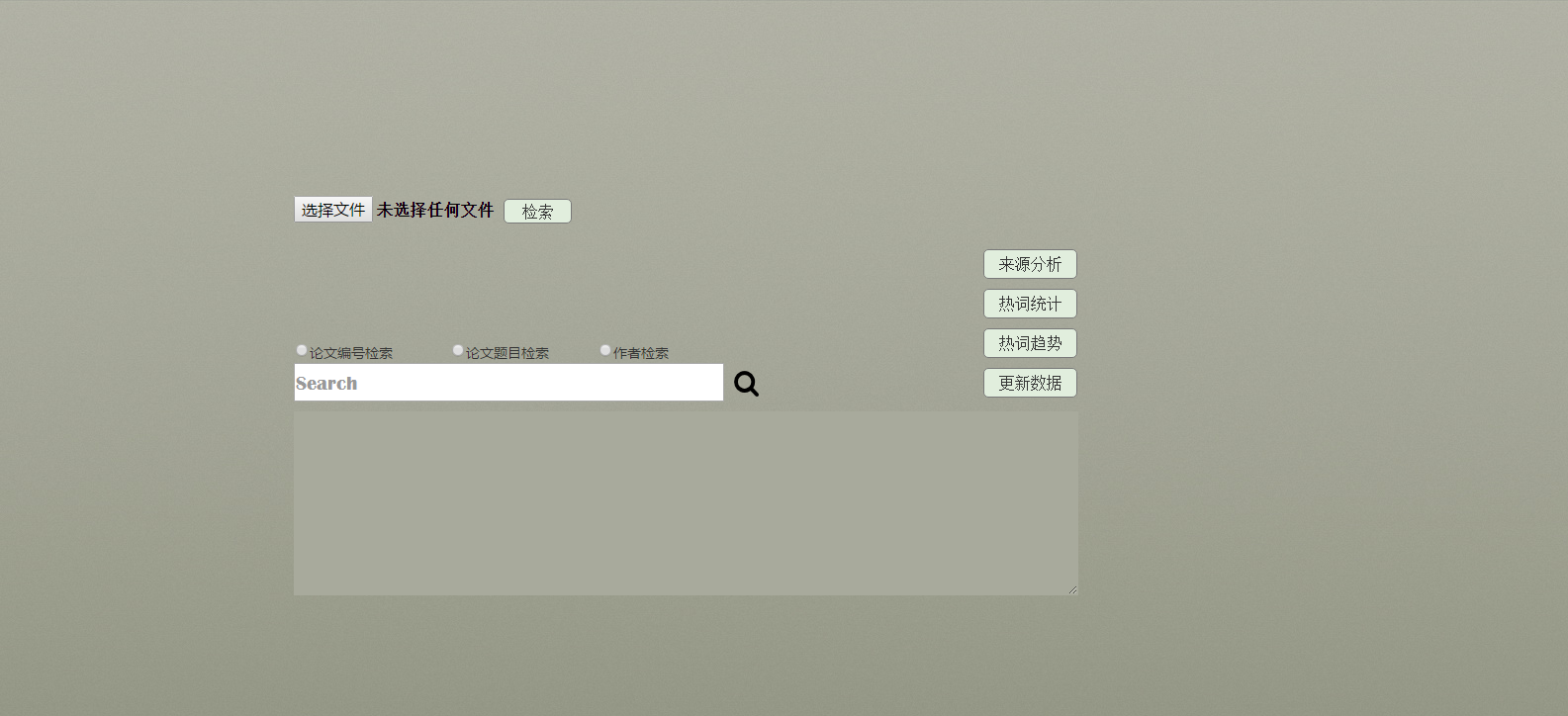
- 模型首页:
![]()
功能说明:- 选择文件:可从本地磁盘中选取论文列表文件用作查询
![]()
- 检索按钮/更新数据按钮:在选择文件之后点击检索按钮可将爬取到的数据展示在下面的文本框中
- 热词统计按钮/热词趋势按钮:在按钮按下后使用,功能分别为呈现热词和近三年的热词趋势
![]()
- 选择文件:可从本地磁盘中选取论文列表文件用作查询
设计文档
1.背景
小樱是一名大三的学生,一直痴迷于吃鸡类游戏,某日听闻同宿舍的小狼刚和导师去参加了CVPR会议,内心羡慕不已,便下定决心痛改前非、努力钻研,希望能在毕业前完成一篇站在时代前沿的优秀论文。但令人苦恼的是,他不知道近几年顶会的热门领域和研究方向,根据论文list去一篇一篇查找总结效率又着实太低,于是求助于“软工实践互助爱心组织”,希望我们能帮助他设计一个平台解决现阶段的需求。
2.设计目标
- 2.1需求分析
- 用户给定一个论文列表
- 1.要求实现通过论文列表爬取论文的题目、摘要以及原文链接。
- 2.可实现对论文列表的增删改操作(今年、近两年、近三年)。
- 对爬取的信息进行结构化处理,分析top10个热门领域或热门研究方向
- 1.可对论文属性(oral、spotlight、poster)进行筛选及分析。
- 2.形成如热词图谱之类直观的查看方式。
- 可进行论文检索,当用户输入论文编号、题目、作者等基本信息,分析返回相关的paper、source code、homepage等信息。
- 可对多年间、不同顶会的热词呈现热度走势对比(这里将范畴限定在计算机视觉的三大顶会CVPR、ICCV、ECCV内)。
- 可进行数据统计,例如每个国家录用文章的分析、每个学校录用文章的分析、哪个学校哪方面的研究方向比较强等。
- 附加需求:
在不改变设计理念、符合用户使用习惯的前提下,在上述需求的基础上进行扩充升级,或发挥想象能力为原型添加自己的idea。
- 用户给定一个论文列表
- 2.2性能指标
- 从需求来看,最主要的时间耗费在爬去论文信息以及存储论文结构体上,用户的目标体量在9000篇论文左右(3年的论文3大顶会每大顶会1000篇)。论文题目不超过200个字符,总体量为200W字符。
- 1.完成全部论文标题遍历及存储需5s的响应时间。
- 2.(爬取时间待检测)
- 3.检索论文题目及相应信息、形成热词图谱的时间各在1s内。
- 4.添加功能可以通过论文编号、论文关键词查找相关论文。
3.模块设计
- 3.1模块流程图及说明
- 设计实现流程如下:
通过用户给定的论文列表从网页上爬去论文信息(论文编号、作者、原文链接等) - 使用C++数据结构以及map<string,class>容器存储爬去到的论文信息
- 通过map容器实现数据检索,热词统计(添加通过文章关键词检索相关文章的功能)以及数据分析
- 将统计结果以图像的形式展现出来
![]()
- 设计实现流程如下:
- 3.2数据结构说明

//伪代码
论文类:
{
属性:
论文ID;论文题目;论文摘要;论文年份;论文作者;论文属性(oral、spotlight、poster);关键词(用作词频统计);type(表明属于哪一个会议)
成员函数:
获取类属性的各个值;
};
- 3.3算法描述
- 首先使用python编写爬虫内嵌至C++中,将得到的数据存储于文件中,对文件遍历存储于map容器中(基于key,value值存储功能)
- 通过map容器的红黑二叉树进行数据查询访问,作出词频统计分析,以及检索筛选算法。
- 3.4与其它模块的接口
- 1.爬虫接口
- 2.类接口
- 3.5异常处理
- 1.读取论文列表失败。
- 2.爬取论文信息失败。
- 3.读入爬取数据失败。
- 4.论文列表中无用户输入的论文标题。
- 3.6测试考虑
- 单元测试:爬虫测试,类读取信息测试,词频统计排序测试
- 集成测试:测试能否得到预期需求的效果
- 测试工具:Visual Studio 2017
4.系统集成包装
- 将系统包装成一个拥有界面的windows窗体软件
5.文档总结
- 我们的产品“爬爬乐”是为了方便用户获取批量论文信息,他们需要通过给定的论文列表获取想要得到的信息以及相应的检索统计功能,但现有的产品并没有很好地解决这些需求,我们有独特的批量获取网页信息的方法,它们能极大地方便用户查找论文以及更清晰地呈现出总体论文的研究走势方向。
遇到的问题及解决方法
- 问题:论文信息的获取
- 应对方式:百度python爬虫嵌入C++的做法
- 问题:热词的统计
- 应对方式:个人作业1的词频统计
- 问题:信息的存储处理及分析
- 应对方式:使用文件处理数据,构造相应数据结构进行统计分析
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 90 | 120 |
| Development | 开发 | 310 | 440 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 240 |
| · Design Spec | · 生成设计文档 | 60 | 90 |
| · Design Review | · 设计复审 | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 0 | 0 |
| · Code Review | · 代码复审 | 0 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 0 | 0 |
| Reporting | 报告 | 25 | 40 |
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| | 合计 |425 |600
结对过程及照片
- 和乐忠豪同学进行需求的讨论,起先对需求如何实现还是一知半解,于是各自进行学习,再查找完资料的基础上继续对目标进行讨论,在多次的分析讨论可行性后,才确定了现在的实现方法。结对还是非常有用的,能发现彼此的不足之处,相互促进,相互进步。
- 丑照如下:
![image]()

学习进度条 (每周更新)
| 第N周 | 新增代码(行) | 累计代码(行) | 学习小时数(小时) | 累计学习小时数(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 100 | 100 | 15 | 15 | 学习了C++嵌入python的方法;Axure原型设计的方法 |
| 2 | 500 | 600 | 20 | 35 | 学习了python爬虫的编写以及Gephi的使用方法 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号