

4 ODB Querying the Database ODB数据库查询
If we don't know the identifiers of the objects that we are looking for, we can use queries to search the database for objects matching certain criteria. The ODB query facility is optional and we need to explicitly request the generation of the necessary database support code with the --generate-query ODB compiler option.
如果我们不知道要查找的对象的标识符,我们可以使用查询在数据库中搜索符合特定条件的对象。ODB查询工具是可选的,我们需要使用 --generate-query ODB编译器选项显式请求生成必要的数据库支持代码。
ODB provides a flexible query API that offers two distinct levels of abstraction from the database system query language such as SQL. At the high level we are presented with an easy to use yet powerful object-oriented query language, called ODB Query Language. This query language is modeled after and is integrated into C++ allowing us to write expressive and safe queries that look and feel like ordinary C++. We have already seen examples of these queries in the introductory chapters. Below is another, more interesting, example:
ODB提供了一个灵活的查询API,它从数据库系统查询语言(如SQL)中提供了两个不同的抽象级别。在高层,我们将看到一种易于使用但功能强大的面向对象查询语言,称为ODB查询语言。这个查询语言是仿照C++的,它可以让我们写出看起来像普通C++的表达和安全的查询。我们已经在导言章节中看到了这些查询的示例。下面是另一个更有趣的例子:

typedef odb::query<person> query; typedef odb::result<person> result; unsigned short age; query q (query::first == "John" && query::age < query::_ref (age)); for (age = 10; age < 100; age += 10) { result r (db.query<person> (q)); ... }
At the low level, queries can be written as predicates using the database system-native query language such as the WHERE predicate from the SQL SELECT statement. This language will be referred to as native query language. At this level ODB still takes care of converting query parameters from C++ to the database system format. Below is the re-implementation of the above example using SQL as the native query language:
在低级别,可以使用数据库系统本机查询语言(如SQL SELECT语句中的WHERE谓词)将查询编写为谓词。这种语言将被称为本机查询语言。在这个级别,ODB仍然需要将查询参数从C++转换为数据库系统格式。下面是使用SQL作为本机查询语言重新实现上述示例:
query q ("first = 'John' AND age = " + query::_ref (age));
Note that at this level we lose the static typing of query expressions. For example, if we wrote something like this:
请注意,在这个级别,我们将丢失查询表达式的静态类型。例如,如果我们写了这样的东西:
query q (query::first == 123 && query::agee < query::_ref (age));
We would get two errors during the C++ compilation. The first would indicate that we cannot compare query::first to an integer and the second would pick the misspelling in query::agee. On the other hand, if we wrote something like this:
我们在C++编译期间会有两个错误。第一个将表示我们无法将query::first与整数进行比较,第二个将选择query::agee中的拼写错误。另一方面,如果我们这样写:
query q ("first = 123 AND agee = " + query::_ref (age));
It would compile fine and would trigger an error only when executed by the database system.
它可以很好地编译,并且只有在数据库系统执行时才会触发错误。
We can also combine the two query languages in a single query, for example:
我们还可以在单个查询中组合两种查询语言,例如:
query q ("first = 'John' AND" + (query::age < query::_ref (age)));
4.1 ODB Query Language ODB查询语言
An ODB query is an expression that tells the database system whether any given object matches the desired criteria. As such, a query expression always evaluates as true or false. At the higher level, an expression consists of other expressions combined with logical operators such as && (AND), || (OR), and ! (NOT). For example:
ODB查询是一个表达式,它告诉数据库系统任何给定对象是否符合所需的条件。因此,查询表达式的计算结果总是true或false。在更高的级别上,表达式由与逻辑运算符组合的其他表达式组成,如&(AND),| |(OR)和!(NOT)。例如:
typedef odb::query<person> query; query q (query::first == "John" || query::age == 31);
At the core of every query expression lie simple expressions which involve one or more object members, values, or parameters. To refer to an object member we use an expression such as query::first above. The names of members in the query class are derived from the names of data members in the object class by removing the common member name decorations, such as leading and trailing underscores, the m_ prefix, etc.
每个查询表达式的核心都是涉及一个或多个对象成员、值或参数的简单表达式。为了引用对象成员,我们使用上面的query::first这样的表达式。查询类中的成员名称是从对象类中的数据成员名称派生而来的,方法是删除常用的成员名称修饰,例如前导和尾随下划线、m_u前缀等。
In a simple expression an object member can be compared to a value, parameter, or another member using a number of predefined operators and functions. The following table gives an overview of the available expressions:
在简单表达式中,可以使用许多预定义的运算符和函数将对象成员与值、参数或其他成员进行比较。下表概述了可用的表达式:
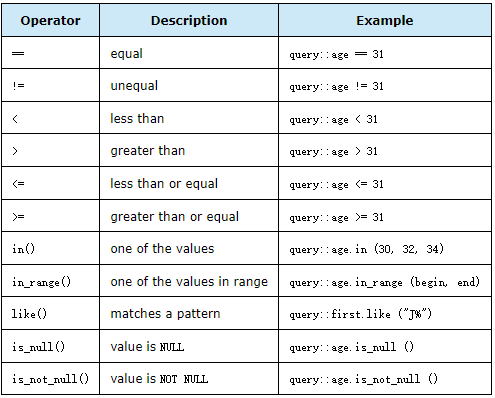
The in() function accepts a maximum of five arguments. Use the in_range() function if you need to compare to more than five values. This function accepts a pair of standard C++ iterators and compares to all the values from the begin position inclusive and until and excluding the end position. The following code fragment shows how we can use these functions:
in()函数最多接受五个参数。如果需要与五个以上的值进行比较,请使用in_range()函数。此函数接受一对标准的C++迭代器,并与包含开始位置的所有值进行比较,直到和排除结束位置。下面的代码片段显示了如何使用这些函数:
std::vector<string> names; names.push_back ("John"); names.push_back ("Jack"); names.push_back ("Jane"); query q1 (query::first.in ("John", "Jack", "Jane")); query q2 (query::first.in_range (names.begin (), names.end ()));
Note that the like() function does not perform any translation of the database system-specific extensions of the SQL LIKE operator. As a result, if you would like your application to be portable among various database systems, then limit the special characters used in the pattern to % (matches zero or more characters) and _ (matches exactly one character). It is also possible to specify the escape character as a second argument to the like() function. This character can then be used to escape the special characters (% and _) in the pattern. For example, the following query will match any two characters separated by an underscore:
请注意,like()函数不执行SQL like运算符的数据库系统特定扩展的任何转换。因此,如果希望应用程序能够在各种数据库系统之间移植,则将模式中使用的特殊字符限制为%(匹配零个或多个字符)和_ (仅匹配一个字符)。还可以将转义字符指定为like()函数的第二个参数。然后,可以使用此字符转义模式中的特殊字符(%and x)。例如,以下查询将匹配由下划线分隔的任意两个字符:
query q (query::name.like ("_!__", "!"));
The operator precedence in the query expressions are the same as for equivalent C++ operators. We can use parentheses to make sure the expression is evaluated in the desired order. For example:
查询表达式中的运算符优先级与等效C++运算符相同。我们可以使用括号来确保表达式按所需顺序计算。例如:
query q ((query::first == "John" || query::first == "Jane") && query::age < 31);
4.2 Parameter Binding 参数绑定
An instance of the odb::query class encapsulates two parts of information about the query: the query expression and the query parameters. Parameters can be bound to C++ variables either by value or by reference.
odb::query类的实例封装了有关查询的两部分信息:查询表达式和查询参数。参数可以通过值或引用绑定到C++变量。
If a parameter is bound by value, then the value for this parameter is copied from the C++ variable to the query instance at the query construction time. On the other hand, if a parameter is bound by reference, then the query instance stores a reference to the bound variable. The actual value of the parameter is only extracted at the query execution time. Consider, for example, the following two queries:
如果参数由值绑定,则此参数的值在查询构造时间从C++变量复制到查询实例。另一方面,如果参数是通过引用绑定的,那么查询实例将存储对绑定变量的引用。参数的实际值仅在查询执行时提取。例如,考虑以下两个查询:
string name ("John"); query q1 (query::first == query::_val (name)); query q2 (query::first == query::_ref (name)); name = "Jane"; db.query<person> (q1); // Find John. db.query<person> (q2); // Find Jane.
The odb::query class provides two special functions, _val() and _ref(), that allow us to bind the parameter either by value or by reference, respectively. In the ODB query language, if the binding is not specified explicitly, the value semantic is used by default. In the native query language, binding must always be specified explicitly. For example:
odb::query 类提供了两个特殊函数,_val()和_ref(),分别允许我们通过值或引用绑定参数。在ODB查询语言中,如果未明确指定绑定,则默认使用值语义。在本机查询语言中,必须始终显式指定绑定。例如:
query q1 (query::age < age); // By value. query q2 (query::age < query::_val (age)); // By value. query q3 (query::age < query::_ref (age)); // By reference. query q4 ("age < " + age); // Error. query q5 ("age < " + query::_val (age)); // By value. query q6 ("age < " + query::_ref (age)); // By reference.
A query that only has by-value parameters does not depend on any other variables and is self-sufficient once constructed. A query that has one or more by-reference parameters depends on the bound variables until the query is executed. If one such variable goes out of scope and we execute the query, the behavior is undefined.
只有by value参数的查询不依赖于任何其他变量,并且在构造后是自给自足的。在执行查询之前,具有一个或多个by引用参数的查询依赖于绑定变量。如果一个这样的变量超出范围,我们执行查询,那么行为是未定义的。
4.3 Executing a Query 执行查询
Once we have the query instance ready and by-reference parameters initialized, we can execute the query using the database::query() function template. It has two overloaded versions:
一旦查询实例就绪并通过引用参数初始化,就可以使用database::query()函数模板执行查询。它有两个重载版本:
template <typename T> result<T> query (bool cache = true); template <typename T> result<T> query (const odb::query<T>&, bool cache = true);
The first query() function is used to return all the persistent objects of a given type stored in the database. The second function uses the passed query instance to only return objects matching the query criteria. The cache argument determines whether the objects' states should be cached in the application's memory or if they should be returned by the database system one by one as the iteration over the result progresses. The result caching is discussed in detail in the next section.
函数的第一个作用是返回数据库中存储的给定类型的所有持久对象。第二个函数使用传递的查询实例仅返回与查询条件匹配的对象。cache参数确定对象的状态是应该缓存在应用程序的内存中,还是应该随着迭代结果的进行由数据库系统逐个返回。下一节将详细讨论结果缓存。
When calling the query() function, we have to explicitly specify the object type we are querying. For example:
调用query()函数时,必须显式指定要查询的对象类型。例如:
typedef odb::query<person> query; typedef odb::result<person> result; result all (db.query<person> ()); result johns (db.query<person> (query::first == "John"));
Note that it is not required to explicitly create a named query variable before executing it. For example, the following two queries are equivalent:
请注意,在执行命名查询变量之前,不需要显式创建该变量。例如,以下两个查询是等效的:
query q (query::first == "John"); result r1 (db.query<person> (q)); result r1 (db.query<person> (query::first == "John"));
Normally, we would create a named query instance if we are planning to run the same query multiple times and would use the in-line version for those that are executed only once (see also Section 4.5, "Prepared Queries" for a more optimal way to re-execute the same query multiple times). A named query instance that does not have any by-reference parameters is immutable and can be shared between multiple threads without synchronization. On the other hand, a query instance with by-reference parameters is modified every time it is executed. If such a query is shared among multiple threads, then access to this query instance must be synchronized from the execution point and until the completion of the iteration over the result.
通常,如果我们计划多次运行同一个查询,我们将创建一个命名查询实例,并且对于那些只执行一次的查询,我们将使用内嵌版本(另请参见第4.5节“准备好的查询”,以获得多次重新执行同一查询的最佳方法)。没有任何by-reference参数的命名查询实例是不可变的,可以在多个线程之间共享,而无需同步。另一方面,每次执行带有by-reference参数的查询实例时都会对其进行修改。如果这样的查询在多个线程之间共享,那么必须从执行点开始同步对此查询实例的访问,直到对结果的迭代完成。
It is also possible to create queries from other queries by combining them using logical operators. For example:
还可以通过使用逻辑运算符组合其他查询来创建查询。例如:
result find_minors (database& db, const query& name_query) { return db.query<person> (name_query && query::age < 18); } result r (find_minors (db, query::first == "John"));
The result of executing a query is zero, one, or more objects matching the query criteria. The query() function returns this result as an instance of the odb::result class template, which provides a stream-like interface and is discussed in detail in the next section.
执行查询的结果是零个、一个或多个与查询条件匹配的对象。query()函数的作用是将此结果作为odb::result类模板的实例返回,该模板提供了一个类似流的接口,将在下一节中详细讨论。
In situations where we know that a query produces at most one element, we can instead use the database::query_one() and database::query_value() shortcut functions, for example:
在我们知道查询最多生成一个元素的情况下,我们可以使用database::query_one() 和database::query_value() 快捷方式函数,例如:
typedef odb::query<person> query; auto_ptr<person> p ( db.query_one<person> ( query::email == "jon@example.com")); //The shortcut query functions have the following signatures: template <typename T> typename object_traits<T>::pointer_type query_one (); template <typename T> bool query_one (T&); template <typename T> T query_value (); template <typename T> typename object_traits<T>::pointer_type query_one (const odb::query<T>&); template <typename T> bool query_one (const odb::query<T>&, T&); template <typename T> T query_value (const odb::query<T>&);
Similar to query(), the first three functions are used to return the only persistent object of a given type stored in the database. The second three versions use the passed query instance to only return the object matching the query criteria.
与query()类似,前三个函数用于返回存储在数据库中的给定类型的唯一持久对象。后三个版本使用传递的查询实例仅返回与查询条件匹配的对象。
Similar to the database::find() functions (Section 3.9, "Loading Persistent Objects"), query_one() can either allocate a new instance of the object class in the dynamic memory or it can load the object's state into an existing instance. The query_value() function allocates and returns the object by value.
与database::find()函数类似(第3.9节,“加载持久对象”),query_one()可以在动态内存中分配对象类的新实例,也可以将对象的状态加载到现有实例中。query_value()函数的作用是按值分配并返回对象。
The query_one() function allows us to determine if the query result contains zero or one element. If no objects matching the query criteria were found in the database, the first version of query_one() returns the NULL pointer while the second — false. If the second version returns false, then the passed object remains unchanged. For example:
query_one()函数允许我们确定查询结果是包含零个元素还是一个元素。如果在数据库中找不到与查询条件匹配的对象,则query_one()的第一个版本返回空指针,而第二个版本返回-false。如果第二个版本返回false,则传递的对象保持不变。例如:
if (unique_ptr<person> p = db.query_one<person> ( query::email == "jon@example.com")) { ... } person p; if (db.query_one<person> (query::email == "jon@example.com", p)) { ... }
If the query executed using query_one() or query_value() returns more than one element, then these functions fail with an assertion. Additionally, query_value() also fails with an assertion if the query returned no elements.
如果使用query_one()或query_value() 执行的查询返回多个元素,则这些函数会因断言而失败。此外,如果查询未返回任何元素,则query_value()也会因断言而失败。
Common situations where we can use the shortcut functions are a query condition that uses a data member with the unique constraint (at most one element returned; see Section 14.7, "Index Definition Pragmas") as well as aggregate queries (exactly one element returned; see Chapter 10, "Views").
我们可以使用快捷方式函数的常见情况是,查询条件使用具有唯一约束的数据成员(最多返回一个元素;请参阅第14.7节“索引定义Pragmas”)以及聚合查询(仅返回一个元素;请参阅第10章“视图”)。
4.4 Query Result 查询结果
The database::query() function returns the result of executing a query as an instance of the odb::result class template, for example:
database::query() 函数的作用是返回作为odb::result类模板实例执行查询的结果,例如:
typedef odb::query<person> query; typedef odb::result<person> result; result johns (db.query<person> (query::first == "John"));
It is best to view an instance of odb::result as a handle to a stream, such as a file stream. While we can make a copy of a result or assign one result to another, the two instances will refer to the same result stream. Advancing the current position in one instance will also advance it in another. The result instance is only usable within the transaction it was created in. Trying to manipulate the result after the transaction has terminated leads to undefined behavior.
最好将 odb::result 的实例视为流的句柄,例如文件流。虽然我们可以复制一个结果或将一个结果分配给另一个结果,但这两个实例将引用相同的结果流。在一种情况下推进当前位置也会在另一种情况下推进当前位置。结果实例仅在创建它的事务中可用。在事务终止后尝试操纵结果会导致未定义的行为。
The odb::result class template conforms to the standard C++ sequence requirements and has the following interface:
odb::result 类模板符合标准C++序列要求,并具有以下接口:
namespace odb { template <typename T> class result { public: typedef odb::result_iterator<T> iterator; public: result (); result (const result&); result& operator= (const result&); void swap (result&) public: iterator begin (); iterator end (); public: void cache (); bool empty () const; std::size_t size () const; }; }
The default constructor creates an empty result set. The cache() function caches the returned objects' state in the application's memory. We have already mentioned result caching when we talked about query execution. As you may remember the database::query() function caches the result unless instructed not to by the caller. The cache() function allows us to cache the result at a later stage if it wasn't already cached during query execution.
默认构造函数创建一个空结果集。cache() 函数的作用是将返回对象的状态缓存在应用程序的内存中。在谈到查询执行时,我们已经提到了结果缓存。您可能还记得,除非调用者指示不缓存结果,否则database::query()函数将缓存结果。cache()函数允许我们在以后的阶段缓存结果,如果在查询执行期间还没有缓存。
If the result is cached, the database state of all the returned objects is stored in the application's memory. Note that the actual objects are still only instantiated on demand during result iteration. It is the raw database state that is cached in memory. In contrast, for uncached results the object's state is sent by the database system one object at a time as the iteration progresses.
如果缓存了结果,则所有返回对象的数据库状态都存储在应用程序的内存中。请注意,在结果迭代期间,实际对象仍然只是根据需要实例化的。它是缓存在内存中的原始数据库状态。相反,对于未缓存的结果,随着迭代的进行,对象的状态由数据库系统一次发送一个对象。
Uncached results can improve the performance of both the application and the database system in situations where we have a large number of objects in the result or if we will only examine a small portion of the returned objects. However, uncached results have a number of limitations. There can only be one uncached result in a transaction. Creating another result (cached or uncached) by calling database::query() will invalidate the existing uncached result. Furthermore, calling any other database functions, such as update() or erase() will also invalidate the uncached result. It also follows that uncached results cannot be used on objects with containers (Chapter 5, "Containers") since loading a container would invalidate the uncached result.
在结果中包含大量对象或者只检查一小部分返回对象的情况下,未缓存的结果可以提高应用程序和数据库系统的性能。但是,未缓存的结果有一些限制。一个事务中只能有一个未缓存的结果。通过调用database::query()创建另一个结果(缓存或未缓存)将使现有的未缓存结果无效。此外,调用任何其他数据库函数,如update()或erase(),也会使未缓存的结果无效。同样,未缓存的结果不能用于带有容器的对象(第5章,“容器”),因为加载容器会使未缓存的结果无效。
The empty() function returns true if there are no objects in the result and false otherwise. The size() function can only be called for cached results. It returns the number of objects in the result. If we call this function on an uncached result, the odb::result_not_cached exception is thrown.
如果结果中没有对象,empty()函数将返回true,否则返回false。只能为缓存的结果调用size()函数。它返回结果中的对象数。如果我们对未缓存的结果调用此函数,将引发odb::result_not_cached异常。
To iterate over the objects in a result we use the begin() and end() functions together with the odb::result<T>::iterator type, for example:
为了迭代结果中的对象,我们使用begin()和end()函数以及 odb::result<T>::iterator 类型,例如:
result r (db.query<person> (query::first == "John")); for (result::iterator i (r.begin ()); i != r.end (); ++i) { ... }
In C++11 we can use the auto-typed variabe instead of spelling the iterator type explicitly, for example:
在C++11中,我们可以使用auto-typed,而不是显式拼写迭代器类型,例如:
for (auto i (r.begin ()); i != r.end (); ++i) { ... }
The C++11 range-based for-loop can be used to further simplify the iteration:
基于C++11范围的for循环可用于进一步简化迭代:
for (person& p: r) { ... }
The result iterator is an input iterator which means that the only two position operations that it supports are to move to the next object and to determine whether the end of the result stream has been reached. In fact, the result iterator can only be in two states: the current position and the end position. If we have two iterators pointing to the current position and then we advance one of them, the other will advance as well. This, for example, means that it doesn't make sense to store an iterator that points to some object of interest in the result stream with the intent of dereferencing it after the iteration is over. Instead, we would need to store the object itself.
结果迭代器是一个输入迭代器,这意味着它支持的仅有两个位置操作是移动到下一个对象并确定是否已到达结果流的末尾。事实上,结果迭代器只能处于两种状态:当前位置和结束位置。如果我们有两个迭代器指向当前位置,然后我们推进其中一个,另一个也会推进。例如,这意味着存储一个迭代器是没有意义的,它指向结果流中某个感兴趣的对象,目的是在迭代结束后取消对它的引用。相反,我们需要存储对象本身。
The result iterator has the following dereference functions that can be used to access the pointed-to object:
结果迭代器具有以下解引用函数,可用于访问指向的对象:
namespace odb { template <typename T> class result_iterator { public: T* operator-> () const; T& operator* () const; typename object_traits<T>::pointer_type load (); void load (T& x); typename object_traits<T>::id_type id (); }; }
When we call the * or -> operator, the iterator will allocate a new instance of the object class in the dynamic memory, load its state from the database state, and return a reference or pointer to the new instance. The iterator maintains the ownership of the returned object and will return the same pointer for subsequent calls to either of these operators until it is advanced to the next object or we call the first load() function (see below). For example:
当我们调用*或->操作符时,迭代器将在动态内存中分配对象类的新实例,从数据库状态加载其状态,并返回指向新实例的引用或指针。迭代器保持返回对象的所有权,并将为后续调用这些操作符中的任何一个返回相同的指针,直到它被提升到下一个对象,或者我们调用第一个load()函数(见下文)。例如:
result r (db.query<person> (query::first == "John")); for (result::iterator i (r.begin ()); i != r.end ();) { cout << i->last () << endl; // Create an object. person& p (*i); // Reference to the same object. cout << p.age () << endl; ++i; // Free the object. }
The overloaded result_iterator::load() functions are similar to database::load(). The first function returns a dynamically allocated instance of the current object. As an optimization, if the iterator already owns an object as a result of an earlier call to the * or -> operator, then it relinquishes the ownership of this object and returns it instead. This allows us to write code like this without worrying about a double allocation:
重载的 result_iterator::load() 函数类似于 database::load() 。第一个函数返回当前对象的动态分配实例。作为一种优化,如果迭代器由于先前对*或->操作符的调用而已经拥有一个对象,那么它将放弃该对象的所有权并返回它。这样我们就可以编写这样的代码,而不用担心双重分配:
result r (db.query<person> (query::first == "John")); for (result::iterator i (r.begin ()); i != r.end (); ++i) { if (i->last == "Doe") { auto_ptr p (i.load ()); ... } }
Note, however, that because of this optimization, a subsequent to load() call to the * or -> operator results in the allocation of a new object.
但是,请注意,由于这种优化,对*或->运算符的后续load()调用会导致分配新对象。
The second load() function allows us to load the current object's state into an existing instance. For example:
第二个load()函数允许我们将当前对象的状态加载到现有实例中。例如:
result r (db.query<person> (query::first == "John")); person p; for (result::iterator i (r.begin ()); i != r.end (); ++i) { i.load (p); cout << p.last () << endl; cout << i.age () << endl; }
The id() function return the object id of the current object. While we can achieve the same by loading the object and getting its id, this function is more efficient since it doesn't actually create the object. This can be useful when all we need is the object's identifier. For example:
id()函数的作用是:返回当前对象的对象id。虽然我们可以通过加载对象并获取其id来实现这一点,但此函数效率更高,因为它实际上并不创建对象。当我们只需要对象的标识符时,这会很有用。例如:
std::set<unsigned long> set = ...; // Persons of interest. result r (db.query<person> (query::first == "John")); for (result::iterator i (r.begin ()); i != r.end (); ++i) { if (set.find (i.id ()) != set.end ()) // No object loaded. { cout << i->first () << endl; // Object loaded. } }
4.5 Prepared Queries 预处理查询
Most modern relational database systems have the notion of a prepared statement. Prepared statements allow us to perform the potentially expensive tasks of parsing SQL, preparing the query execution plan, etc., once and then executing the same query multiple times, potentially using different values for parameters in each execution.
大多数现代关系数据库系统都有预处理语句的概念。Prepared语句允许我们执行一次解析SQL、准备查询执行计划等可能代价高昂的任务,然后多次执行同一查询,每次执行中可能使用不同的参数值。
In ODB all the non-query database operations such as persist(), load(), update(), etc., are implemented in terms of prepared statements that are cached and reused. While the query(), query_one(), and query_one() database operations also use prepared statements, these statements are not cached or reused by default since ODB has no knowledge of whether a query will be executed multiple times or only once. Instead, ODB provides a mechanism, called prepared queries, that allows us to prepare a query once and execute it multiple times. In other words, ODB prepared queries are a thin wrapper around the underlying database's prepared statement functionality.
在ODB中,所有非查询数据库操作(如persist()、load()、update()等)都是根据缓存和重用的准备语句来实现的。虽然query()、query_one()和query_one()数据库操作也使用预先预处理语句,但默认情况下不会缓存或重用这些语句,因为ODB不知道查询是要执行多次还是只执行一次。相反,ODB提供了一种称为“准备好的查询”的机制,允许我们准备一次查询并多次执行。换句话说,ODB准备好的查询是底层数据库预处理语句功能的薄包装。
In most cases ODB shields the application developer from database connection management and multi-threading issues. However, when it comes to prepared queries, a basic understanding of how ODB manages these aspects is required. Conceptually, the odb::database class represents a specific database, that is, a data store. However, underneath, it maintains one or more connections to this database. A connection can be used only by a single thread at a time. When we start a transaction (by calling database::begin()), the transaction instance obtains a connection and holds on to it until the transaction is committed or rolled back. During this time no other thread can use this connection. When the transaction releases the connection, it may be closed or reused by another transaction in this or another thread. What exactly happens to a connection after it has been released depends on the connection factory that is used by the odb::database instance. For more information on connection factories, refer to Part II, "Database Systems".
在大多数情况下,ODB保护应用程序开发人员免受数据库连接管理和多线程问题的影响。然而,对于预处理查询,需要基本了解ODB如何管理这些方面。从概念上讲,odb::database 类表示一个特定的数据库,即数据存储。但是,在下面,它维护到该数据库的一个或多个连接。一次只能由一个线程使用连接。当我们启动一个事务(通过调用database::begin())时,事务实例将获得一个连接,并保持连接,直到提交或回滚该事务。在此期间,没有其他线程可以使用此连接。当事务释放连接时,它可能会被此线程或其他线程中的另一个事务关闭或重用。释放连接后,连接的具体情况取决于odb:database 实例使用的连接工厂。有关连接工厂的更多信息,请参阅第二部分“数据库系统”。
A query prepared on one connection cannot be executed on another. In other words, a prepared query is associated with the connection. One important implication of this restriction is that we cannot prepare a query in one transaction and then try to execute it in another without making sure that both transactions use the same connection.
在一个连接上准备的查询无法在另一个连接上执行。换句话说,准备好的查询与连接相关联。这个限制的一个重要含义是,我们不能在一个事务中准备一个查询,然后在另一个事务中尝试执行它,而不确保两个事务使用相同的连接。
To enable the prepared query functionality we need to specify the --generate-prepared ODB compiler option. If we are planning to always prepare our queries, then we can disable the once-off query execution support by also specifying the --omit-unprepared option.
要启用预处理查询功能,我们需要指定--generate-prepared ODB 编译选项。如果我们计划始终准备查询,那么还可以通过指定--omit-unprepared选项来禁用一次性查询执行支持。
To prepare a query we use the prepare_query() function template. This function can be called on both the odb::database and odb::connection instances. The odb::database version simply obtains the connection used by the currently active transaction and calls the corresponding odb::connection version. If no transaction is currently active, then this function throws the odb::not_in_transaction exception (Section 3.5, "Transactions"). The prepare_query() function has the following signature:
要准备查询,我们使用prepare_query()函数模板。此函数可以在 odb::database 和 odb::connection 实例上调用。odb::database 版本只获取当前活动事务使用的连接,并调用相应的 odb::connection 版本。如果当前没有活动的事务,则此函数将抛出odb::not_in_transaction 异常(第3.5节“事务”)。prepare_query()函数具有以下签名:
template <typename T> prepared_query<T> prepare_query (const char* name, const odb::query<T>&);
The first argument to the prepare_query() function is the prepared query name. This name is used as a key for prepared query caching (discussed later) and must be unique. For some databases, notably PostgreSQL, it is also used as a name of the underlying prepared statement. The name "object_query" (for example, "person_query") is reserved for the once-off queries executed by the database::query() function. Note that the prepare_query() function makes only a shallow copy of this argument, which means that the name must be valid for the lifetime of the returned prepared_query instance.
prepare_query()函数的第一个参数是已准备好的查询名称。此名称用作准备好的查询缓存(稍后讨论)的键,并且必须是唯一的。对于某些数据库,尤其是PostgreSQL,它还用作基础prepared语句的名称。名称“object_query”(例如,“person_query”)是为database::query()函数执行的一次性查询保留的。请注意,prepare_query()函数只生成此参数的浅拷贝,这意味着该名称必须在返回的prepared_query实例的生存期内有效。
The second argument to the prepare_query() function is the query criteria. It has the same semantics as in the query() function discussed in Section 4.3, "Executing a Query". Similar to query(), we also have to explicitly specify the object type that we will be querying. For example:
prepare_query()函数的第二个参数是查询条件。它与第4.3节“执行查询”中讨论的query()函数具有相同的语义。与query()类似,我们还必须显式指定要查询的对象类型。例如:
typedef odb::query<person> query; typedef odb::prepared_query<person> prep_query; prep_query pq ( db.prepare_query<person> ("person-age-query", query::age > 50));
The result of executing the prepare_query() function is the prepared_query instance that represent the prepared query. It is best to view prepared_query as a handle to the underlying prepared statement. While we can make a copy of it or assign one prepared_query to another, the two instances will refer to the same prepared statement. Once the last instance of prepared_query referencing a specific prepared statement is destroyed, this statement is released. The prepared_query class template has the following interface:
执行prepare_query()函数的结果是表示预处理查询的prepared_query实例。最好将 prepared_query 视为底层prepared语句的句柄。虽然我们可以复制它或将一个预处理查询分配给另一个,但这两个实例将引用同一个预处理的语句。一旦引用特定prepared语句的prepared_query 的最后一个实例被销毁,该语句将被释放。预处理查询类模板具有以下接口:
namespace odb { template <typename T> struct prepared_query { prepared_query (); prepared_query (const prepared_query&) prepared_query& operator= (const prepared_query&) result<T> execute (bool cache = true); typename object_traits<T>::pointer_type execute_one (); bool execute_one (T& object); T execute_value (); const char* name () const; statement& statement () const; operator unspecified_bool_type () const; }; }
The default constructor creates an empty prepared_query instance, that is, an instance that does not reference a prepared statement and therefore cannot be executed. The only way to create a non-empty prepared query is by calling the prepare_query() function discussed above. To test whether the prepared query is empty, we can use the implicit conversion operator to a boolean type. For example:
默认构造函数创建一个空的prepared_query实例,即不引用prepared语句的实例,因此无法执行。创建非空准备查询的唯一方法是调用上面讨论的prepare_query()函数。为了测试准备的查询是否为空,我们可以使用布尔类型的隐式转换运算符。例如:
prepared_query<person> pq; if (pq) { // Not empty. ... }
The execute() function executes the query and returns the result instance. The cache argument indicates whether the result should be cached and has the same semantics as in the query() function. In fact, conceptually, prepare_query() and execute() are just the query() function split into two: prepare_query() takes the first query() argument (the query condition) while execute() takes the second (the cache flag). Note also that re-executing a prepared query invalidates the previous execution result, whether cached or uncached.
execute() 函数的作用是执行查询并返回结果实例。cache参数指示是否应该缓存结果,并且具有与query()函数中相同的语义。实际上,从概念上讲,prepare_query()和execute()只是将query()函数分为两部分:prepare_query()接受第一个query()参数(查询条件),execute()接受第二个(缓存标志)。还要注意,重新执行准备好的查询会使以前的执行结果(无论是缓存的还是未缓存的)无效。
The execute_one() and execute_value() functions can be used as shortcuts to execute a query that is known to return at most one or exactly one object, respectively. The arguments and return values in these functions have the same semantics as in query_one() and query_value(). And similar to execute() above, prepare_query() and execute_one/value() can be seen as the query_one/value() function split into two: prepare_query() takes the first query_one/value() argument (the query condition) while execute_one/value() takes the second argument (if any) and returns the result. Note also that execute_one/value() never caches its result but invalidates the result of any previous execute() call on the same prepared query.
execute_one()和execute_value()函数可以用作快捷方式,以执行已知分别最多返回一个或恰好返回一个对象的查询。这些函数中的参数和返回值的语义与query_one()和query_value()中的相同。与上面的execute()类似,prepare_query()和execute_one/value()可以看作是将query_one/value()函数分成两部分:prepare_query()接受第一个query_one/value()参数(查询条件),execute_one/value()接受第二个参数(如果有)并返回结果。还请注意,execute_one/value()从不缓存其结果,而是使之前对同一准备好的查询执行的任何execute()调用的结果无效。
The name() function returns the prepared query name. This is the same name as was passed as the first argument in the prepare_query() call. The statement() function returns a reference to the underlying prepared statement. Note also that calling any of these functions on an empty prepared_query instance results in undefined behavior.
name() 函数的作用是:返回准备好的查询名称。这与prepare_query()调用中传递的第一个参数的名称相同。statement()函数的作用是:返回对底层预处理语句的引用。还要注意,在空的prepare_query()实例上调用这些函数中的任何一个都会导致未定义的行为。
The simplest use-case for a prepared query is the need to execute the same query multiple times within a single transaction. Consider the following example that queries for people that are older than a number of different ages. This and subsequent code fragments are taken from the prepared example in the odb-examples package.
预处理查询最简单的用例是需要在单个事务中多次执行同一查询。考虑下面的例子,询问比不同年龄更老的人。此代码片段和后续代码片段取自odb示例包中准备好的示例。
typedef odb::query<person> query; typedef odb::prepared_query<person> prep_query; typedef odb::result<person> result; transaction t (db.begin ()); unsigned short age; query q (query::age > query::_ref (age)); prep_query pq (db.prepare_query<person> ("person-age-query", q)); for (age = 90; age > 40; age -= 10) { result r (pq.execute ()); ... } t.commit ();
Another scenario is the need to reuse the same query in multiple transactions that are executed at once. As was mentioned above, in this case we need to make sure that the prepared query and all the transactions use the same connection. Consider an alternative version of the above example that executes each query in a separate transaction:
另一种情况是需要在同时执行的多个事务中重用同一查询。如上所述,在这种情况下,我们需要确保准备好的查询和所有事务使用相同的连接。考虑上述示例的另一个版本,它在一个单独的事务中执行每个查询:
connection_ptr conn (db.connection ()); unsigned short age; query q (query::age > query::_ref (age)); prep_query pq (conn->prepare_query<person> ("person-age-query", q)); for (age = 90; age > 40; age -= 10) { transaction t (conn->begin ()); result r (pq.execute ()); ... t.commit (); }
Note that with this approach we hold on to the database connection until all the transactions involving the prepared query are executed. In particular, this means that while we are busy, the connection cannot be reused by another thread. Therefore, this approach is only recommended if all the transactions are executed close to each other. Also note that an uncached (see below) prepared query is invalidated once we release the connection on which it was prepared.
请注意,使用这种方法,我们将保持数据库连接,直到执行所有涉及准备好的查询的事务。特别是,这意味着当我们忙时,连接不能被另一个线程重用。因此,只有当所有事务都彼此接近执行时,才建议使用这种方法。还请注意,一旦我们释放了一个未缓存(见下文)的准备好的查询的连接,它就会失效。
If we need to reuse a prepared query in transactions that are executed at various times, potentially in different threads, then the recommended approach is to cache the prepared query on the connection. To support this functionality the odb::database and odb::connection classes provide the following function templates. Similar to prepare_query(), the odb::database versions of the below functions call the corresponding odb::connection versions using the currently active transaction to resolve the connection.
如果我们需要在不同时间(可能在不同线程中)执行的事务中重用准备好的查询,那么推荐的方法是在连接上缓存准备好的查询。为了支持此功能,odb::database 和odb::connection 类提供了以下函数模板。与prepare_query()类似,以下函数的odb::database 版本使用当前活动的事务调用相应的 odb::connection 版本来解析连接。
template <typename T> void cache_query (const prepared_query<T>&); template <typename T, typename P> void cache_query (const prepared_query<T>&, std::[auto|unique]_ptr<P> params); template <typename T> prepared_query<T> lookup_query (const char* name) const; template <typename T, typename P> prepared_query<T> lookup_query (const char* name, P*& params) const;
The cache_query() function caches the passed prepared query on the connection. The second overloaded version of cache_query() also takes a pointer to the by-reference query parameters. In C++98/03 it should be std::auto_ptr while in C++11 std::auto_ptr or std::unique_ptr can be used. The cache_query() function assumes ownership of the passed params argument. If a prepared query with the same name is already cached on this connection, then the odb::prepared_already_cached exception is thrown.
cache_query()函数的作用是:缓存连接上传递的已准备好的查询。cache_query()的第二个重载版本还采用指向by-reference查询参数的指针。在C++98/03中,它应该是std::auto_ptr,而在C++11中,可以使用std::auto_ptr或std::unique_ptr。cache_query()函数假定传递的参数的所有权。如果此连接上已缓存具有相同名称的已准备查询,则会引发odb::prepared_ready_cached异常。
The lookup_query() function looks up a previously cached prepared query given its name. The second overloaded version of lookup_query() also returns a pointer to the by-reference query parameters. If a prepared query with this name has not been cached, then an empty prepared_query instance is returned. If a prepared query with this name has been cached but either the object type or the parameters type does not match that which was cached, then the odb::prepared_type_mismatch exception is thrown.
lookup_query()函数的作用是:在给定查询名称的情况下,查找以前缓存的已准备好的查询。lookup_query()的第二个重载版本还返回指向by reference查询参数的指针。如果尚未缓存具有此名称的准备好的查询,则返回空的准备好的查询实例。如果已缓存具有此名称的准备好的查询,但对象类型或参数类型与缓存的不匹配,则会引发odb::prepared_type_mismatch异常。
As a first example of the prepared query cache functionality, consider the case that does not use any by-reference parameters:
作为准备的查询缓存功能的第一个例子,考虑不使用任何参考参数的情况:
for (unsigned short i (0); i < 5; ++i) { transaction t (db.begin ()); prep_query pq (db.lookup_query<person> ("person-age-query")); if (!pq) { pq = db.prepare_query<person> ( "person-val-age-query", query::age > 50); db.cache_query (pq); } result r (pq.execute ()); ... t.commit (); // Do some other work. // ... }
The following example shows how to do the same but for a query that includes by-reference parameters. In this case the parameters are cached together with the prepared query.
下面的示例演示了如何执行相同的操作,但对于包含按引用参数的查询除外。在这种情况下,参数将与准备好的查询一起缓存。
for (unsigned short age (90); age > 40; age -= 10) { transaction t (db.begin ()); unsigned short* age_param; prep_query pq ( db.lookup_query<person> ("person-age-query", age_param)); if (!pq) { auto_ptr<unsigned short> p (new unsigned short); age_param = p.get (); query q (query::age > query::_ref (*age_param)); pq = db.prepare_query<person> ("person-age-query", q); db.cache_query (pq, p); // Assumes ownership of p. } *age_param = age; // Initialize the parameter. result r (pq.execute ()); ... t.commit (); // Do some other work. // ... }
As is evident from the above examples, when we use a prepared query cache, each transaction that executes a query must also include code that prepares and caches this query if it hasn't already been done. If a prepared query is used in a single place in the application, then this is normally not an issue since all the relevant code is kept in one place. However, if the same query is used in several different places in the application, then we may end up duplicating the same preparation and caching code, which makes it hard to maintain.
从上面的示例可以明显看出,当我们使用准备好的查询缓存时,执行查询的每个事务还必须包含准备和缓存该查询(如果尚未完成)的代码。如果在应用程序中的单个位置使用准备好的查询,那么这通常不是问题,因为所有相关代码都保存在一个位置。但是,如果在应用程序中的几个不同位置使用相同的查询,那么我们可能会复制相同的准备和缓存代码,这使得维护变得困难。
To resolve this issue ODB allows us to register a prepared query factory that will be called to prepare and cache a query during the call to lookup_query(). To register a factory we use the database::query_factory() function. In C++98/03 it has the following signature:
为了解决这个问题,ODB允许我们注册一个准备好的查询工厂,在调用lookup_query()期间,该工厂将被调用以准备和缓存查询。要注册工厂,我们使用database::query_factory()函数。在C++98/03中,它具有以下签名:
void query_factory (const char* name, void (*factory) (const char* name, connection&));
While in C++11 it uses the std::function class template:
在C++11中,它使用std::function类模板:
void query_factory (const char* name, std::function<void (const char* name, connection&)>);
The first argument to the query_factory() function is the prepared query name that this factory will be called to prepare and cache. An empty name is treated as a fallback wildcard factory that is capable of preparing any query. The second argument is the factory function or, in C++11, function object or lambda.
query_factory() 函数的第一个参数是准备好的查询名称,该工厂将被调用以准备和缓存。空名称被视为能够准备任何查询的回退通配符工厂。第二个参数是工厂函数,在C++11中是函数对象或lambda。
The example fragment shows how we can use the prepared query factory:
示例片段显示了如何使用准备好的查询工厂:
struct params { unsigned short age; string first; }; static void query_factory (const char* name, connection& c) { auto_ptr<params> p (new params); query q (query::age > query::_ref (p->age) && query::first == query::_ref (p->first)); prep_query pq (c.prepare_query<person> (name, q)); c.cache_query (pq, p); } db.query_factory ("person-age-name-query", &query_factory); for (unsigned short age (90); age > 40; age -= 10) { transaction t (db.begin ()); params* p; prep_query pq (db.lookup_query<person> ("person-age-name-query", p)); assert (pq); p->age = age; p->first = "John"; result r (pq.execute ()); ... t.commit (); }
In C++11 we could have instead used a lambda function as well as unique_ptr rather than auto_ptr:
在C++11中,我们可以使用lambda函数以及unique_ptr而不是auto_ptr:
db.query_factory ( "person-age-name-query", [] (const char* name, connection& c) { unique_ptr<params> p (new params); query q (query::age > query::_ref (p->age) && query::first == query::_ref (p->first)); prep_query pq (c.prepare_query<person> (name, q)); c.cache_query (pq, std::move (p)); });


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现