
第8章下 多项式回归与模型泛化
8-6 验证数据集与交叉验证
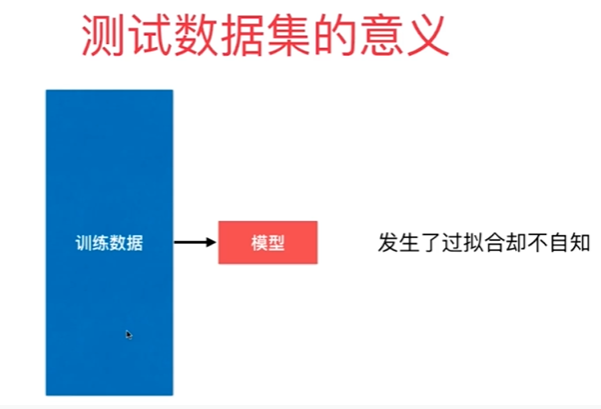
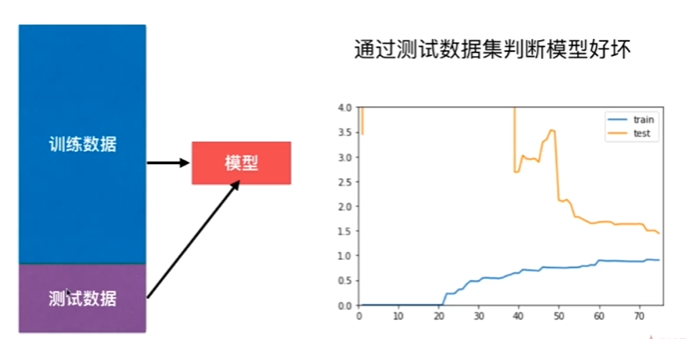
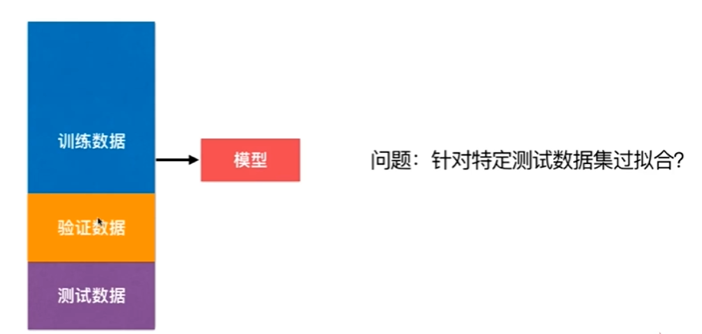
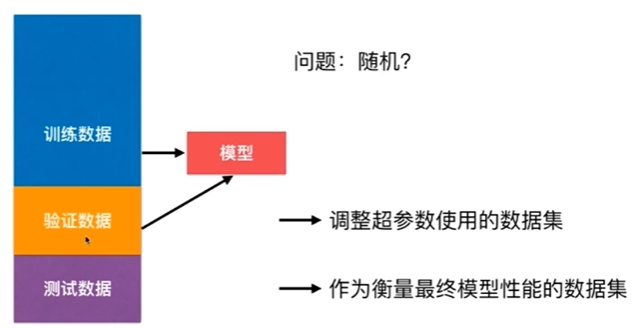



Nnotbook 示例
Notbook 源码

1 交叉验证 2 [1] 3 import numpy as np 4 from sklearn import datasets 5 [2] 6 digits = datasets.load_digits() 7 X = digits.data 8 y = digits.target 9 测试 train_test_split 10 [3] 11 from sklearn.model_selection import train_test_split 12 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666) 13 [4] 14 from sklearn.neighbors import KNeighborsClassifier 15 16 best_score, best_p, best_k = 0, 0, 0 17 for k in range(2,11): 18 for p in range(1,6): 19 knn_clf = KNeighborsClassifier(weights="distance",n_neighbors=k,p=p) 20 knn_clf.fit(X_train, y_train) 21 score = knn_clf.score(X_test,y_test) 22 if score > best_score: 23 best_score, best_p, best_k = score, p, k 24 25 print("Best_k = ", best_k) 26 print("Best_p = ",best_p) 27 print("Best_score = ",best_score) 28 Best_k = 3 29 Best_p = 2 30 Best_score = 0.9860917941585535 31 32 使用交叉验证 33 [5] 34 from sklearn.model_selection import cross_val_score 35 36 knn_clf = KNeighborsClassifier() 37 cross_val_score(knn_clf, X_train,y_train) 38 array([0.99537037, 0.98148148, 0.97685185, 0.97674419, 0.97209302]) 39 [6] 40 best_score, best_p, best_k = 0, 0, 0 41 for k in range(2,11): 42 for p in range(1,6): 43 knn_clf = KNeighborsClassifier(weights="distance",n_neighbors=k,p=p) 44 knn_clf.fit(X_train, y_train) 45 scores = cross_val_score(knn_clf,X_train,y_train) 46 score = np.mean(scores) 47 if score > best_score: 48 best_score, best_p, best_k = score, p, k 49 50 print("Best_k = ", best_k) 51 print("Best_p = ",best_p) 52 print("Best_score = ",best_score) 53 Best_k = 2 54 Best_p = 2 55 Best_score = 0.9851507321274763 56 57 [7] 58 best_knn_clf = KNeighborsClassifier(weights="distance", n_neighbors =2,p=2) 59 [8] 60 best_knn_clf.fit(X_train, y_train) 61 best_knn_clf.score(X_test, y_test) 62 0.980528511821975 63 回顾网格搜索 64 [13] 65 from sklearn.model_selection import GridSearchCV 66 67 param_grid = [ 68 { 69 "weights":["distance"], 70 "n_neighbors":[i for i in range(2,11)], 71 "p":[i for i in range(1,6)] 72 } 73 ] 74 75 grid_search = GridSearchCV(knn_clf, param_grid, verbose=1) 76 grid_search.fit(X_train,y_train) 77 Fitting 5 folds for each of 45 candidates, totalling 225 fits 78 79 GridSearchCV(estimator=KNeighborsClassifier(n_neighbors=10, p=5, 80 weights='distance'), 81 param_grid=[{'n_neighbors': [2, 3, 4, 5, 6, 7, 8, 9, 10], 82 'p': [1, 2, 3, 4, 5], 'weights': ['distance']}], 83 verbose=1) 84 [14] 85 grid_search.best_score_ 86 0.9851507321274763 87 [15] 88 grid_search.best_params_ 89 {'n_neighbors': 2, 'p': 2, 'weights': 'distance'} 90 [17] 91 best_knn_clf = grid_search.best_estimator_ 92 best_knn_clf.score(X_test,y_test) 93 0.980528511821975 94 [18] 95 cross_val_score(knn_clf, X_train,y_train,cv=3) 96 array([0.98055556, 0.98050139, 0.96100279]) 97 [19] 98 GridSearchCV(knn_clf, param_grid, verbose=1, cv=3) 99 GridSearchCV(cv=3, 100 estimator=KNeighborsClassifier(n_neighbors=10, p=5, 101 weights='distance'), 102 param_grid=[{'n_neighbors': [2, 3, 4, 5, 6, 7, 8, 9, 10], 103 'p': [1, 2, 3, 4, 5], 'weights': ['distance']}], 104 verbose=1)
8-7 偏差方差平衡

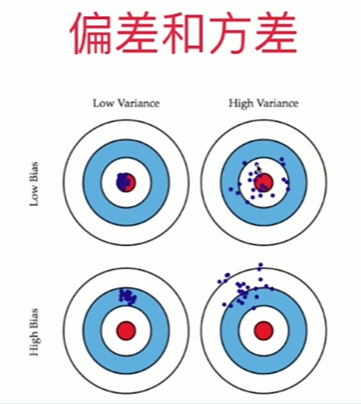

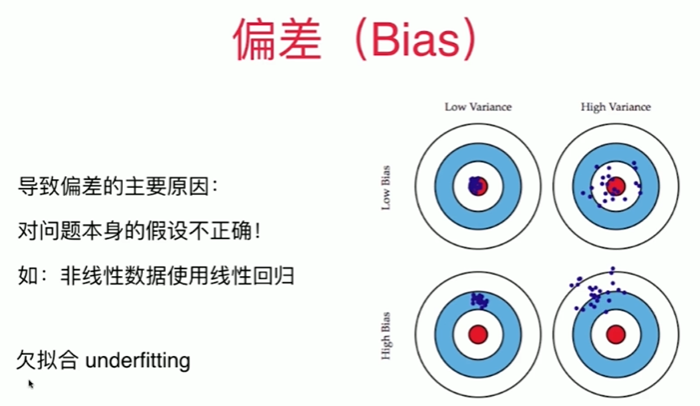
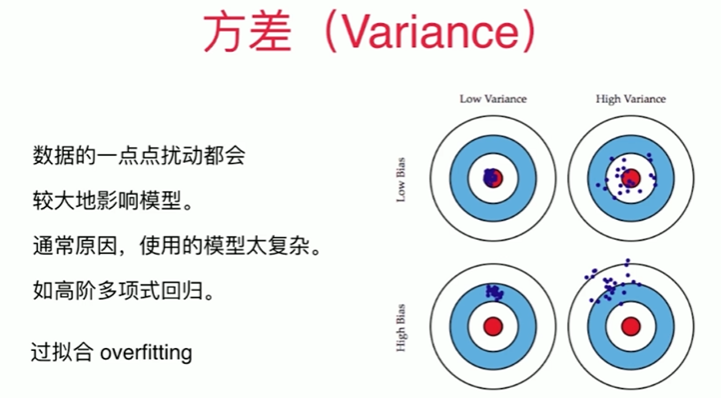





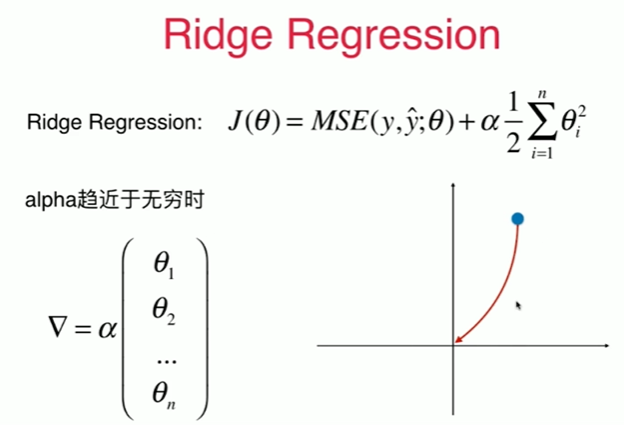
8-8 模型泛化与岭回归
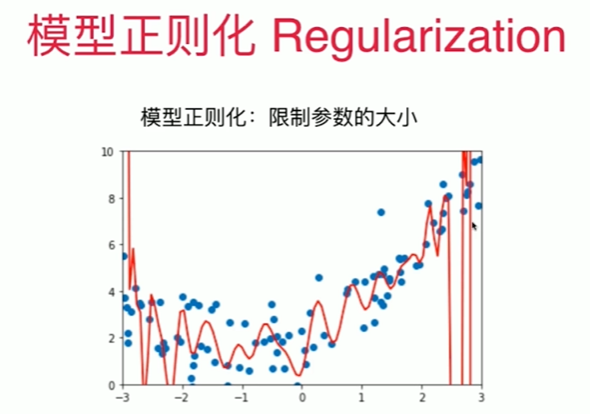

Notbook 示例

Notbook 源码
1 [1] 2 import numpy as np 3 import matplotlib.pyplot as plt 4 [2] 5 x = np.random.uniform(-3, 3, size=100) 6 X = x.reshape(-1,1) 7 y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100) 8 [3] 9 from sklearn.linear_model import LinearRegression 10 from sklearn.pipeline import Pipeline 11 from sklearn.preprocessing import PolynomialFeatures 12 from sklearn.preprocessing import StandardScaler 13 14 lin_reg = LinearRegression() 15 def PolynomialRegression(degree): 16 return Pipeline([ 17 ("poly",PolynomialFeatures(degree=degree)),#!!!!!!!!! 18 ("std_scaler",StandardScaler()), 19 ("lin_reg",lin_reg) 20 ]) 21 [4] 22 from sklearn.metrics import mean_squared_error 23 24 poly100_reg = PolynomialRegression(degree=100) 25 poly100_reg.fit(X,y) 26 y100_predict = poly100_reg.predict(X) 27 mean_squared_error(y,y100_predict) 28 0.3630662022937054 29 [5] 30 X_plot = np.linspace(-3, 3, 100).reshape(100,1) 31 y_plot = poly100_reg.predict(X_plot) 32 33 plt.scatter(x,y) 34 plt.plot(X_plot[:,0],y_plot,color='r') 35 plt.axis([-3, 3, 0, 10]) 36 (-3.0, 3.0, 0.0, 10.0) 37 38 [7] 39 lin_reg.coef_ 40 array([ 2.85566833e+13, -4.86652731e+00, -7.63042344e+01, 6.36319430e+02, 41 6.80489039e+03, -2.54310157e+04, -2.61198355e+05, 4.27336689e+05, 42 5.34542751e+06, -6.94337912e+05, -6.10790341e+07, -8.57691190e+07, 43 3.45202670e+08, 1.52465049e+09, 1.63928865e+08, -1.37144024e+10, 44 -1.83536476e+10, 7.66032914e+10, 1.51424297e+11, -2.77869759e+11, 45 -6.87557673e+11, 6.35340216e+11, 1.95698070e+12, -7.64753325e+11, 46 -3.41717491e+12, -5.12331050e+10, 2.97457272e+12, 1.50129966e+12, 47 3.40803862e+11, -1.39777394e+12, -2.30445737e+12, -1.21676316e+12, 48 -1.35548542e+12, 3.17823462e+12, 4.37853931e+12, -2.07598680e+12, 49 7.58006069e+11, 2.79811420e+11, -5.12394013e+12, 7.17900735e+11, 50 3.11502081e+11, -1.29435321e+12, 3.24230619e+12, 1.90755460e+11, 51 -1.82400131e+12, 6.13112904e+11, 2.74467307e+12, 7.50934834e+11, 52 -1.11741536e+12, -1.12780418e+12, -1.79875318e+12, 1.00555887e+12, 53 -1.81669614e+12, -2.06157950e+11, 1.95131392e+12, -1.64604514e+12, 54 2.95054100e+12, -3.60793010e+11, -2.25796459e+12, 3.78295754e+11, 55 -1.55480037e+12, 2.64352577e+12, 2.96302159e+12, 6.25824566e+11, 56 6.90176136e+11, -2.17209673e+12, -2.54504094e+12, 1.19441715e+11, 57 -1.56445519e+12, 5.18954696e+11, 7.81463582e+10, -2.19228398e+12, 58 1.65924203e+12, -4.84099102e+11, 1.29028838e+12, 5.91610483e+10, 59 3.85131883e+11, 2.18088026e+12, 7.85255857e+10, 4.20546626e+12, 60 -2.34625370e+12, -1.77089952e+12, 1.25388875e+11, -4.66199247e+12, 61 -5.50443098e+11, 9.78014262e+11, 1.54262864e+12, 4.78137117e+11, 62 6.60472983e+11, -1.09921649e+12, -1.21323016e+12, 2.42539428e+12, 63 3.52655517e+11, 5.42616419e+11, -1.52587784e+11, -1.43140935e+12, 64 -3.82481390e+11, -8.61566638e+10, 7.93538571e+11, 2.24669016e+11, 65 -3.49271059e+11]) 66 岭回归 67 [10] 68 np.random.seed(42) 69 x = np.random.uniform(-3.0, 3.0, size=100) 70 X = x.reshape(-1,1) 71 y = 0.5 * x + 3 + np.random.normal(0, 1, size=100) 72 [11] 73 plt.scatter(x,y) 74 <matplotlib.collections.PathCollection at 0x1a7f0b35d00>
1 岭回归 2 [1] 3 import numpy as np 4 import matplotlib.pyplot as plt 5 [2] 6 np.random.seed(42) 7 x = np.random.uniform(-3.0, 3.0, size=100) 8 X = x.reshape(-1,1) 9 y = 0.5 * x + 3 + np.random.normal(0, 1, size=100) 10 [3] 11 plt.scatter(x,y) 12 <matplotlib.collections.PathCollection at 0x247e4798910> 13 14 [4] 15 from sklearn.linear_model import LinearRegression 16 from sklearn.pipeline import Pipeline 17 from sklearn.preprocessing import PolynomialFeatures 18 from sklearn.preprocessing import StandardScaler 19 20 def PolynomialRegression(degree): 21 return Pipeline([ 22 ("poly",PolynomialFeatures(degree=degree)),#!!!!!!!!! 23 ("std_scaler",StandardScaler()), 24 ("lin_reg",LinearRegression()) 25 ]) 26 [5] 27 from sklearn.model_selection import train_test_split 28 29 np.random.seed(666) 30 X_train, X_test, y_train, y_test = train_test_split(X, y) 31 [6] 32 from sklearn.metrics import mean_squared_error 33 34 poly_reg = PolynomialRegression(degree=20) 35 poly_reg.fit(X_train,y_train) 36 37 y_poly_predict = poly_reg.predict(X_test) 38 mean_squared_error(y_test,y_poly_predict) 39 167.9401086187559 40 [7] 41 X_plot = np.linspace(-3, 3, 100).reshape(100,1) 42 y_plot = poly_reg.predict(X_plot) 43 44 plt.scatter(x,y) 45 plt.plot(X_plot[:,0],y_plot,color='r') 46 plt.axis([-3, 3, 0, 10]) 47 (-3.0, 3.0, 0.0, 10.0) 48 49 [8] 50 def plot_model(model): 51 X_plot = np.linspace(-3, 3, 100).reshape(100,1) 52 y_plot = model.predict(X_plot) 53 54 plt.scatter(x,y) 55 plt.plot(X_plot[:,0],y_plot,color='r') 56 plt.axis([-3, 3, 0, 10]) 57 58 plot_model(poly_reg) 59 60 使用岭回归 61 [9] 62 from sklearn.linear_model import Ridge 63 64 def RidgeRegression(degree, alpha): 65 return Pipeline([ 66 ("poly",PolynomialFeatures(degree=degree)), 67 ("std_scaler",StandardScaler()), 68 ("lin_reg",Ridge(alpha=alpha)) 69 ]) 70 [10] 71 ridg1_reg = RidgeRegression(20,0.0001) 72 ridg1_reg.fit(X_train,y_train) 73 74 y1_predict = ridg1_reg.predict(X_test) 75 mean_squared_error(y_test,y1_predict) 76 1.323349275399316 77 [11] 78 plot_model(ridg1_reg) 79 80 [13] 81 ridg2_reg = RidgeRegression(20,1) 82 ridg2_reg.fit(X_train,y_train) 83 84 y2_predict = ridg2_reg.predict(X_test) 85 mean_squared_error(y_test,y2_predict) 86 1.1888759304218464 87 [14] 88 plot_model(ridg2_reg) 89 90 [16] 91 ridg3_reg = RidgeRegression(20,100) 92 ridg3_reg.fit(X_train,y_train) 93 94 y3_predict = ridg3_reg.predict(X_test) 95 mean_squared_error(y_test,y3_predict) 96 1.31964561130862 97 [17] 98 plot_model(ridg3_reg) 99 100 [18] 101 ridg4_reg = RidgeRegression(20,1000000000) 102 ridg4_reg.fit(X_train,y_train) 103 104 y4_predict = ridg4_reg.predict(X_test) 105 mean_squared_error(y_test,y4_predict) 106 1.8408934818370333 107 [19] 108 plot_model(ridg4_reg)
8-9 LASSO




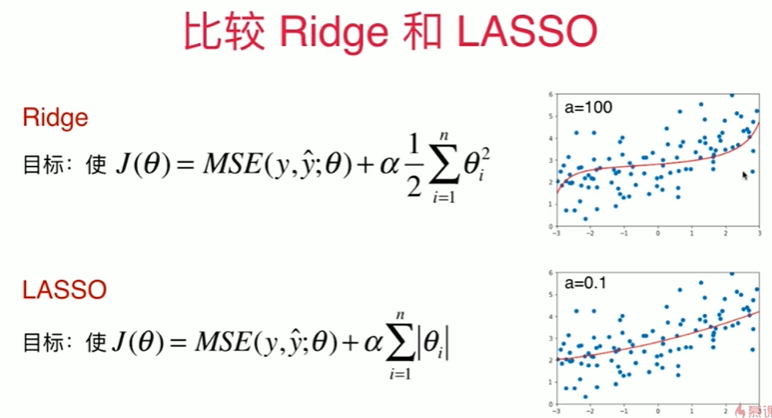


Notbook 示例

Notbook 源码
1 LASSO 2 [1] 3 import numpy as np 4 import matplotlib.pyplot as plt 5 [2] 6 np.random.seed(42) 7 x = np.random.uniform(-3.0, 3.0, size=100) 8 X = x.reshape(-1,1) 9 y = 0.5 * x + 3 + np.random.normal(0, 1, size=100) 10 [3] 11 plt.scatter(x,y) 12 <matplotlib.collections.PathCollection at 0x1769fffc280> 13 14 [4] 15 from sklearn.model_selection import train_test_split 16 17 np.random.seed(666) 18 X_train, X_test, y_train, y_test = train_test_split(X, y) 19 [5] 20 from sklearn.linear_model import LinearRegression 21 from sklearn.pipeline import Pipeline 22 from sklearn.preprocessing import PolynomialFeatures 23 from sklearn.preprocessing import StandardScaler 24 25 def PolynomialRegression(degree): 26 return Pipeline([ 27 ("poly",PolynomialFeatures(degree=degree)),#!!!!!!!!! 28 ("std_scaler",StandardScaler()), 29 ("lin_reg",LinearRegression()) 30 ]) 31 [6] 32 from sklearn.metrics import mean_squared_error 33 34 poly_reg = PolynomialRegression(degree=20) 35 poly_reg.fit(X_train,y_train) 36 37 y_poly_predict = poly_reg.predict(X_test) 38 mean_squared_error(y_test,y_poly_predict) 39 167.9401086187559 40 [7] 41 def plot_model(model): 42 X_plot = np.linspace(-3, 3, 100).reshape(100,1) 43 y_plot = model.predict(X_plot) 44 45 plt.scatter(x,y) 46 plt.plot(X_plot[:,0],y_plot,color='r') 47 plt.axis([-3, 3, 0, 10]) 48 49 plot_model(poly_reg) 50 51 LASSO 52 [8] 53 from sklearn.linear_model import Lasso 54 55 def LassoRegression(degree, alpha): 56 return Pipeline([ 57 ("poly",PolynomialFeatures(degree=degree)), 58 ("std_scaler",StandardScaler()), 59 ("lin_reg", Lasso(alpha=alpha)) 60 ]) 61 [10] 62 lasso1_reg = LassoRegression(20, 0.01) 63 lasso1_reg.fit(X_train,y_train) 64 65 y1_predict = lasso1_reg.predict(X_test) 66 mean_squared_error(y_test,y1_predict) 67 1.1496080843259961 68 [11] 69 plot_model(lasso1_reg) 70 71 [13] 72 lasso2_reg = LassoRegression(20, 0.1) 73 lasso2_reg.fit(X_train,y_train) 74 75 y2_predict = lasso2_reg.predict(X_test) 76 mean_squared_error(y_test,y2_predict) 77 1.1213911351818648 78 [14] 79 plot_model(lasso2_reg) 80 81 [15] 82 lasso3_reg = LassoRegression(20, 1) 83 lasso3_reg.fit(X_train,y_train) 84 85 y3_predict = lasso3_reg.predict(X_test) 86 mean_squared_error(y_test,y3_predict) 87 1.8408939659515595 88 [16] 89 plot_model(lasso3_reg)
8-10 L1,L2和弹性网络
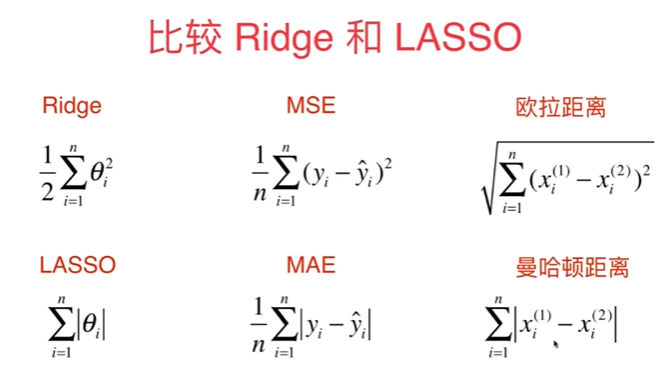

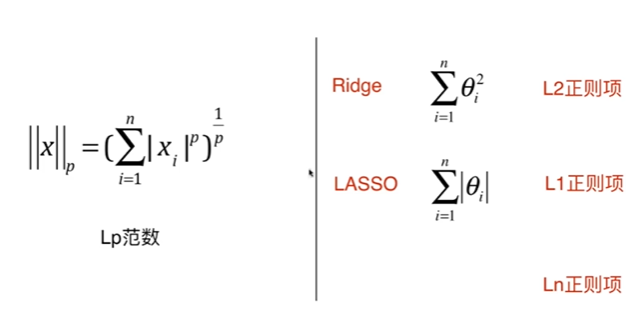
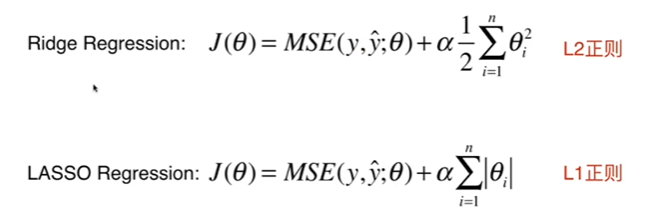




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?