

第5章下 线性回归法
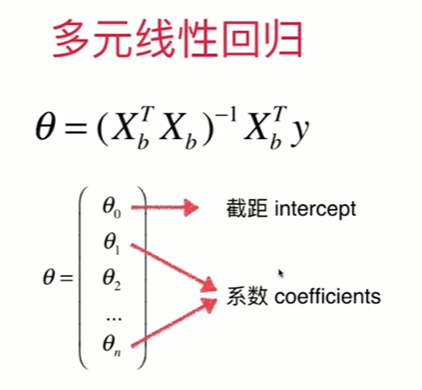
5-7 多元线性回归和正规方程解
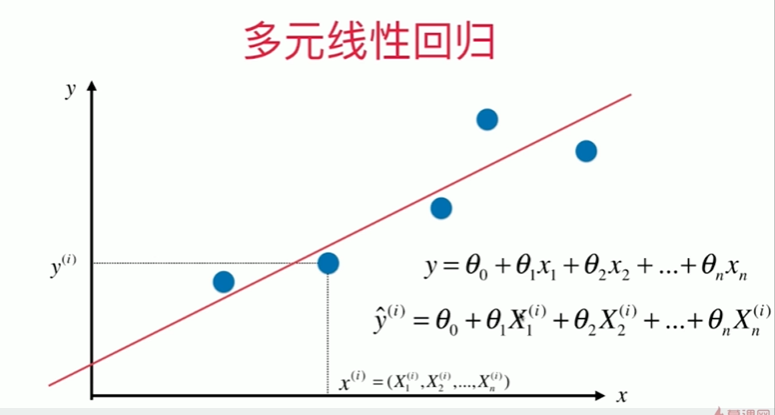

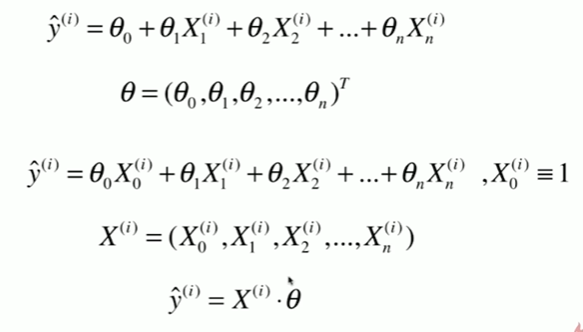
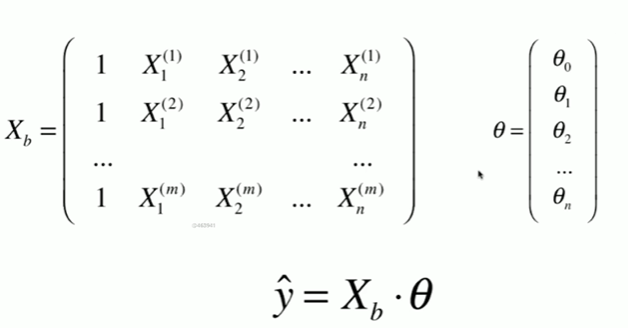

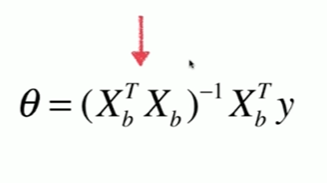

5-8 实现多元线性回归
Notbook 示例
Notbook 源码

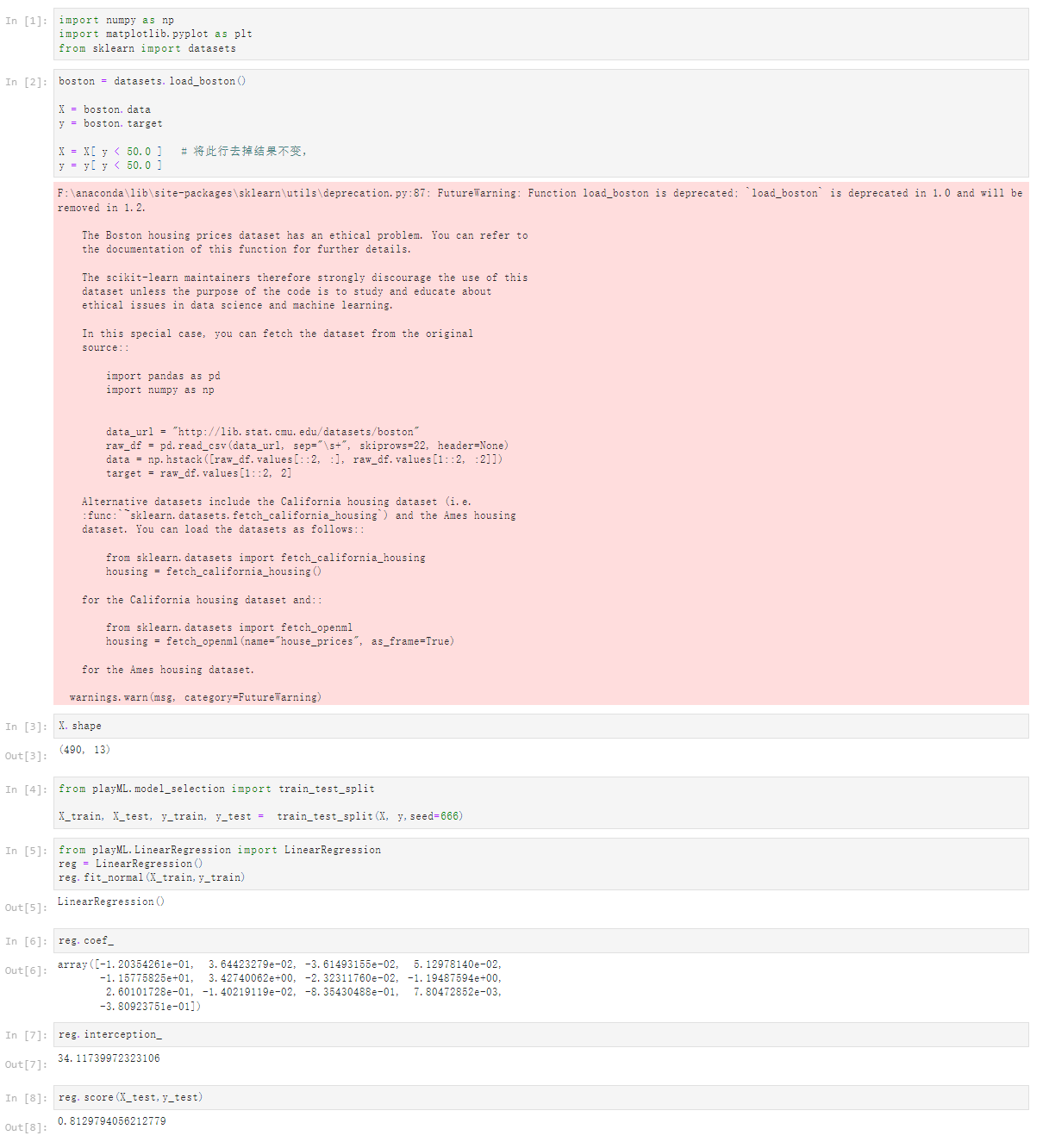
1 [1] 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from sklearn import datasets 5 [2] 6 boston = datasets.load_boston() 7 8 X = boston.data 9 y = boston.target 10 11 X = X[ y < 50.0 ] # 将此行去掉结果不变, 12 y = y[ y < 50.0 ] 13 F:\anaconda\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function load_boston is deprecated; `load_boston` is deprecated in 1.0 and will be removed in 1.2. 14 15 The Boston housing prices dataset has an ethical problem. You can refer to 16 the documentation of this function for further details. 17 18 The scikit-learn maintainers therefore strongly discourage the use of this 19 dataset unless the purpose of the code is to study and educate about 20 ethical issues in data science and machine learning. 21 22 In this special case, you can fetch the dataset from the original 23 source:: 24 25 import pandas as pd 26 import numpy as np 27 28 29 data_url = "http://lib.stat.cmu.edu/datasets/boston" 30 raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None) 31 data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) 32 target = raw_df.values[1::2, 2] 33 34 Alternative datasets include the California housing dataset (i.e. 35 :func:`~sklearn.datasets.fetch_california_housing`) and the Ames housing 36 dataset. You can load the datasets as follows:: 37 38 from sklearn.datasets import fetch_california_housing 39 housing = fetch_california_housing() 40 41 for the California housing dataset and:: 42 43 from sklearn.datasets import fetch_openml 44 housing = fetch_openml(name="house_prices", as_frame=True) 45 46 for the Ames housing dataset. 47 48 warnings.warn(msg, category=FutureWarning) 49 50 [3] 51 X.shape 52 (490, 13) 53 [4] 54 from playML.model_selection import train_test_split 55 56 X_train, X_test, y_train, y_test = train_test_split(X, y,seed=666) 57 [5] 58 from playML.LinearRegression import LinearRegression 59 reg = LinearRegression() 60 reg.fit_normal(X_train,y_train) 61 LinearRegression() 62 [6] 63 reg.coef_ 64 array([-1.20354261e-01, 3.64423279e-02, -3.61493155e-02, 5.12978140e-02, 65 -1.15775825e+01, 3.42740062e+00, -2.32311760e-02, -1.19487594e+00, 66 2.60101728e-01, -1.40219119e-02, -8.35430488e-01, 7.80472852e-03, 67 -3.80923751e-01]) 68 [7] 69 reg.interception_ 70 34.11739972323106 71 [8] 72 reg.score(X_test,y_test) 73 0.8129794056212779
5-9 使用scikit-learn解决回归问题
Notbook 示例
Notbook 源码
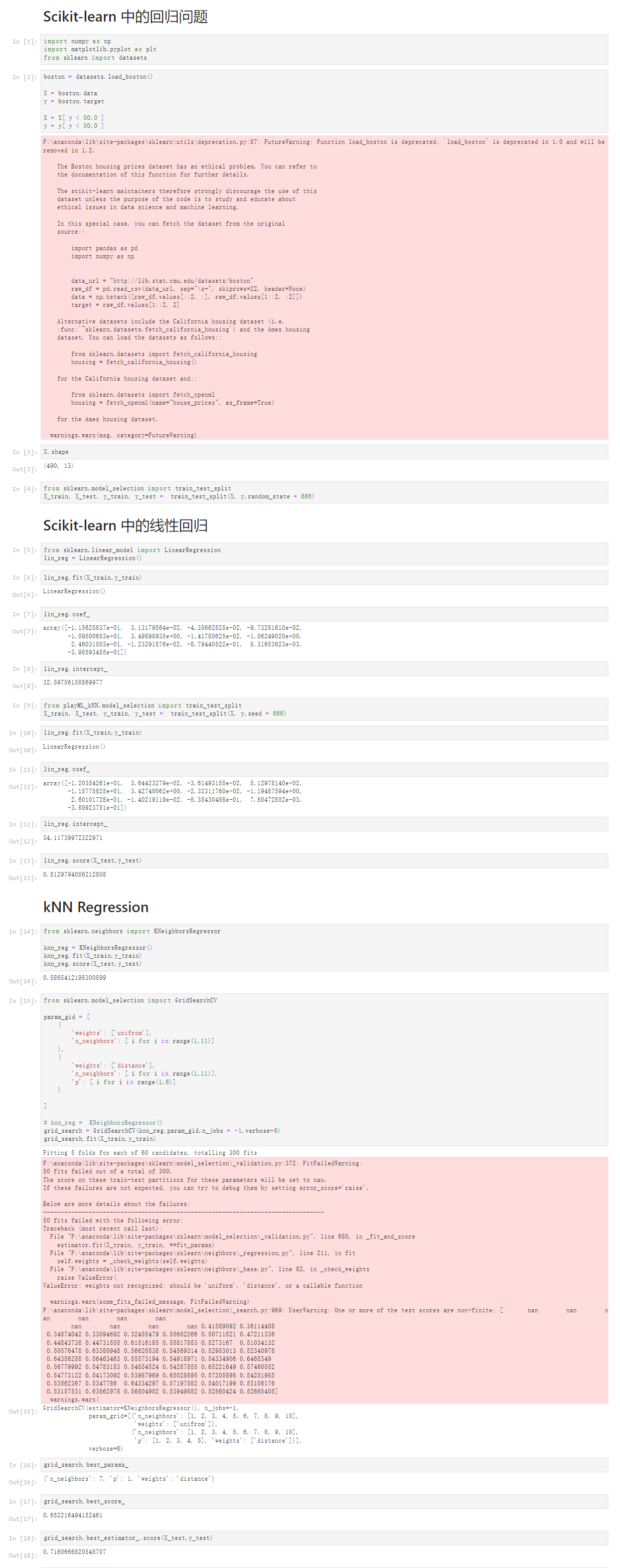
1 Scikit-learn 中的回归问题 2 [1] 3 import numpy as np 4 import matplotlib.pyplot as plt 5 from sklearn import datasets 6 [2] 7 boston = datasets.load_boston() 8 9 X = boston.data 10 y = boston.target 11 12 X = X[ y < 50.0 ] 13 y = y[ y < 50.0 ] 14 F:\anaconda\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function load_boston is deprecated; `load_boston` is deprecated in 1.0 and will be removed in 1.2. 15 16 The Boston housing prices dataset has an ethical problem. You can refer to 17 the documentation of this function for further details. 18 19 The scikit-learn maintainers therefore strongly discourage the use of this 20 dataset unless the purpose of the code is to study and educate about 21 ethical issues in data science and machine learning. 22 23 In this special case, you can fetch the dataset from the original 24 source:: 25 26 import pandas as pd 27 import numpy as np 28 29 30 data_url = "http://lib.stat.cmu.edu/datasets/boston" 31 raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None) 32 data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) 33 target = raw_df.values[1::2, 2] 34 35 Alternative datasets include the California housing dataset (i.e. 36 :func:`~sklearn.datasets.fetch_california_housing`) and the Ames housing 37 dataset. You can load the datasets as follows:: 38 39 from sklearn.datasets import fetch_california_housing 40 housing = fetch_california_housing() 41 42 for the California housing dataset and:: 43 44 from sklearn.datasets import fetch_openml 45 housing = fetch_openml(name="house_prices", as_frame=True) 46 47 for the Ames housing dataset. 48 49 warnings.warn(msg, category=FutureWarning) 50 51 [3] 52 X.shape 53 (490, 13) 54 [4] 55 from sklearn.model_selection import train_test_split 56 X_train, X_test, y_train, y_test = train_test_split(X, y,random_state = 666) 57 Scikit-learn 中的线性回归 58 [5] 59 from sklearn.linear_model import LinearRegression 60 lin_reg = LinearRegression() 61 [6] 62 lin_reg.fit(X_train,y_train) 63 LinearRegression() 64 [7] 65 lin_reg.coef_ 66 array([-1.15625837e-01, 3.13179564e-02, -4.35662825e-02, -9.73281610e-02, 67 -1.09500653e+01, 3.49898935e+00, -1.41780625e-02, -1.06249020e+00, 68 2.46031503e-01, -1.23291876e-02, -8.79440522e-01, 8.31653623e-03, 69 -3.98593455e-01]) 70 [8] 71 lin_reg.intercept_ 72 32.59756158869977 73 [9] 74 from playML_kNN.model_selection import train_test_split 75 X_train, X_test, y_train, y_test = train_test_split(X, y,seed = 666) 76 [10] 77 lin_reg.fit(X_train,y_train) 78 LinearRegression() 79 [11] 80 lin_reg.coef_ 81 array([-1.20354261e-01, 3.64423279e-02, -3.61493155e-02, 5.12978140e-02, 82 -1.15775825e+01, 3.42740062e+00, -2.32311760e-02, -1.19487594e+00, 83 2.60101728e-01, -1.40219119e-02, -8.35430488e-01, 7.80472852e-03, 84 -3.80923751e-01]) 85 [12] 86 lin_reg.intercept_ 87 34.11739972322971 88 [13] 89 lin_reg.score(X_test,y_test) 90 0.8129794056212808 91 kNN Regression 92 [14] 93 from sklearn.neighbors import KNeighborsRegressor 94 95 knn_reg = KNeighborsRegressor() 96 knn_reg.fit(X_train,y_train) 97 knn_reg.score(X_test,y_test) 98 0.5865412198300899 99 [15] 100 from sklearn.model_selection import GridSearchCV 101 102 param_gid = [ 103 { 104 'weights': ['unifrom'], 105 'n_neighbors': [ i for i in range(1,11)] 106 }, 107 { 108 'weights': ['distance'], 109 'n_neighbors': [ i for i in range(1,11)], 110 'p': [ i for i in range(1,6)] 111 } 112 113 ] 114 115 # knn_reg = KNeighborsRegressor() 116 grid_search = GridSearchCV(knn_reg,param_gid,n_jobs = -1,verbose=6) 117 grid_search.fit(X_train,y_train) 118 119 Fitting 5 folds for each of 60 candidates, totalling 300 fits 120 121 F:\anaconda\lib\site-packages\sklearn\model_selection\_validation.py:372: FitFailedWarning: 122 50 fits failed out of a total of 300. 123 The score on these train-test partitions for these parameters will be set to nan. 124 If these failures are not expected, you can try to debug them by setting error_score='raise'. 125 126 Below are more details about the failures: 127 -------------------------------------------------------------------------------- 128 50 fits failed with the following error: 129 Traceback (most recent call last): 130 File "F:\anaconda\lib\site-packages\sklearn\model_selection\_validation.py", line 680, in _fit_and_score 131 estimator.fit(X_train, y_train, **fit_params) 132 File "F:\anaconda\lib\site-packages\sklearn\neighbors\_regression.py", line 211, in fit 133 self.weights = _check_weights(self.weights) 134 File "F:\anaconda\lib\site-packages\sklearn\neighbors\_base.py", line 82, in _check_weights 135 raise ValueError( 136 ValueError: weights not recognized: should be 'uniform', 'distance', or a callable function 137 138 warnings.warn(some_fits_failed_message, FitFailedWarning) 139 F:\anaconda\lib\site-packages\sklearn\model_selection\_search.py:969: UserWarning: One or more of the test scores are non-finite: [ nan nan nan nan nan nan 140 nan nan nan nan 0.41589092 0.36114408 141 0.34874042 0.33094692 0.32455479 0.55602266 0.50711521 0.47211336 142 0.44843738 0.44731555 0.61516185 0.55817853 0.5273167 0.51034132 143 0.50576478 0.63380948 0.56620538 0.54569314 0.52953013 0.52340978 144 0.64356258 0.56463463 0.55573194 0.54918971 0.54334906 0.6468349 145 0.56779992 0.54783183 0.54854524 0.54287855 0.65221649 0.57460552 146 0.54773122 0.54173092 0.53987969 0.65028895 0.57205898 0.54251985 147 0.53562367 0.5347786 0.64334297 0.57197582 0.54017199 0.53108176 148 0.53157531 0.63862978 0.56804902 0.53949882 0.52860424 0.52665405] 149 warnings.warn( 150 151 GridSearchCV(estimator=KNeighborsRegressor(), n_jobs=-1, 152 param_grid=[{'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 153 'weights': ['unifrom']}, 154 {'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 155 'p': [1, 2, 3, 4, 5], 'weights': ['distance']}], 156 verbose=6) 157 [16] 158 grid_search.best_params_ 159 {'n_neighbors': 7, 'p': 1, 'weights': 'distance'} 160 [17] 161 grid_search.best_score_ 162 0.652216494152461 163 [18] 164 grid_search.best_estimator_.score(X_test,y_test) 165 0.7160666820548707
5-10 线性回归的可解性和更多思考



Notbook 示例
Notbook 源码
1 更多关于线性回归模型的讨论 2 [1] 3 import numpy as np 4 import matplotlib.pyplot as plt 5 from sklearn import datasets 6 [2] 7 boston = datasets.load_boston() 8 9 X = boston.data 10 y = boston.target 11 12 X = X[ y < 50.0 ] 13 y = y[ y < 50.0 ] 14 F:\anaconda\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function load_boston is deprecated; `load_boston` is deprecated in 1.0 and will be removed in 1.2. 15 16 The Boston housing prices dataset has an ethical problem. You can refer to 17 the documentation of this function for further details. 18 19 The scikit-learn maintainers therefore strongly discourage the use of this 20 dataset unless the purpose of the code is to study and educate about 21 ethical issues in data science and machine learning. 22 23 In this special case, you can fetch the dataset from the original 24 source:: 25 26 import pandas as pd 27 import numpy as np 28 29 30 data_url = "http://lib.stat.cmu.edu/datasets/boston" 31 raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None) 32 data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) 33 target = raw_df.values[1::2, 2] 34 35 Alternative datasets include the California housing dataset (i.e. 36 :func:`~sklearn.datasets.fetch_california_housing`) and the Ames housing 37 dataset. You can load the datasets as follows:: 38 39 from sklearn.datasets import fetch_california_housing 40 housing = fetch_california_housing() 41 42 for the California housing dataset and:: 43 44 from sklearn.datasets import fetch_openml 45 housing = fetch_openml(name="house_prices", as_frame=True) 46 47 for the Ames housing dataset. 48 49 warnings.warn(msg, category=FutureWarning) 50 51 [4] 52 from sklearn.linear_model import LinearRegression 53 lin_reg = LinearRegression() 54 lin_reg.fit(X,y) 55 LinearRegression() 56 [5] 57 lin_reg.coef_ 58 array([-1.06715912e-01, 3.53133180e-02, -4.38830943e-02, 4.52209315e-01, 59 -1.23981083e+01, 3.75945346e+00, -2.36790549e-02, -1.21096549e+00, 60 2.51301879e-01, -1.37774382e-02, -8.38180086e-01, 7.85316354e-03, 61 -3.50107918e-01]) 62 [6] 63 np.argsort(lin_reg.coef_) 64 array([ 4, 7, 10, 12, 0, 2, 6, 9, 11, 1, 8, 3, 5], dtype=int64) 65 [7] 66 boston.feature_names 67 array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 68 'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7') 69 [8] 70 boston.feature_names[np.argsort(lin_reg.coef_)] 71 array(['NOX', 'DIS', 'PTRATIO', 'LSTAT', 'CRIM', 'INDUS', 'AGE', 'TAX', 72 'B', 'ZN', 'RAD', 'CHAS', 'RM'], dtype='<U7') 73 [9] 74 print(boston.DESCR) 75 .. _boston_dataset: 76 77 Boston house prices dataset 78 --------------------------- 79 80 **Data Set Characteristics:** 81 82 :Number of Instances: 506 83 84 :Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target. 85 86 :Attribute Information (in order): 87 - CRIM per capita crime rate by town 88 - ZN proportion of residential land zoned for lots over 25,000 sq.ft. 89 - INDUS proportion of non-retail business acres per town 90 - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) 91 - NOX nitric oxides concentration (parts per 10 million) 92 - RM average number of rooms per dwelling 93 - AGE proportion of owner-occupied units built prior to 1940 94 - DIS weighted distances to five Boston employment centres 95 - RAD index of accessibility to radial highways 96 - TAX full-value property-tax rate per $10,000 97 - PTRATIO pupil-teacher ratio by town 98 - B 1000(Bk - 0.63)^2 where Bk is the proportion of black people by town 99 - LSTAT % lower status of the population 100 - MEDV Median value of owner-occupied homes in $1000's 101 102 :Missing Attribute Values: None 103 104 :Creator: Harrison, D. and Rubinfeld, D.L. 105 106 This is a copy of UCI ML housing dataset. 107 https://archive.ics.uci.edu/ml/machine-learning-databases/housing/ 108 109 110 This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University. 111 112 The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic 113 prices and the demand for clean air', J. Environ. Economics & Management, 114 vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics 115 ...', Wiley, 1980. N.B. Various transformations are used in the table on 116 pages 244-261 of the latter. 117 118 The Boston house-price data has been used in many machine learning papers that address regression 119 problems. 120 121 .. topic:: References 122 123 - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261. 124 - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了