
第5章上 线性回归法
5-1 简单线性回归


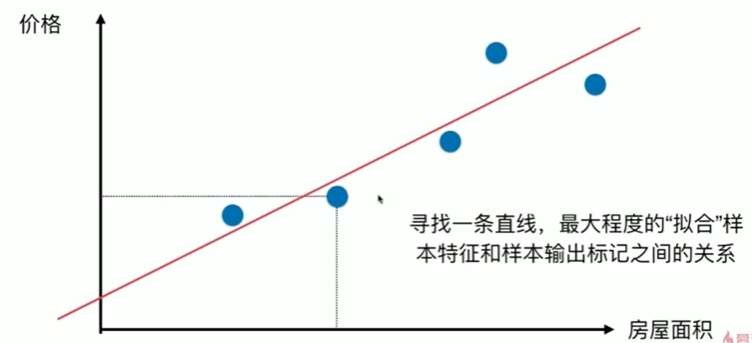
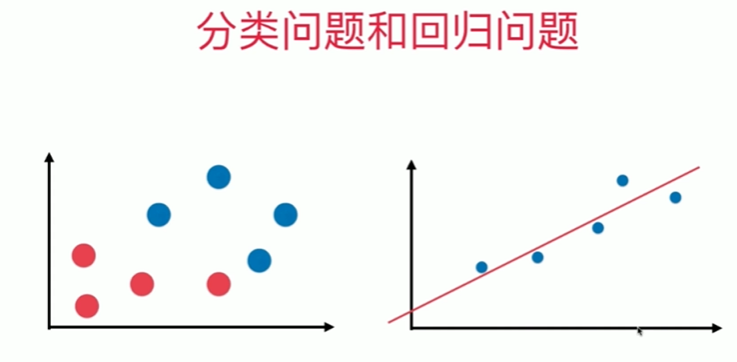
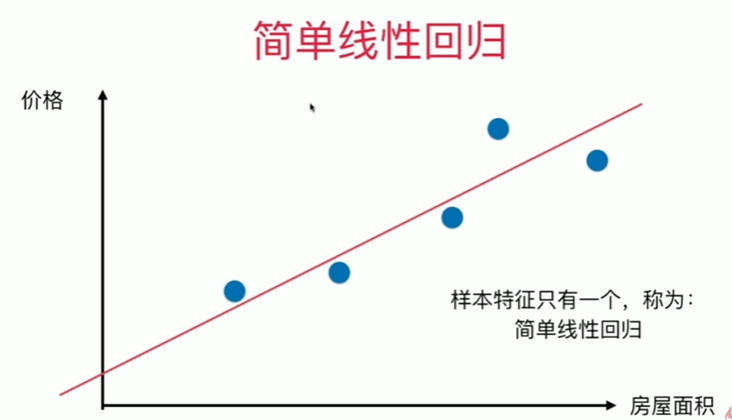
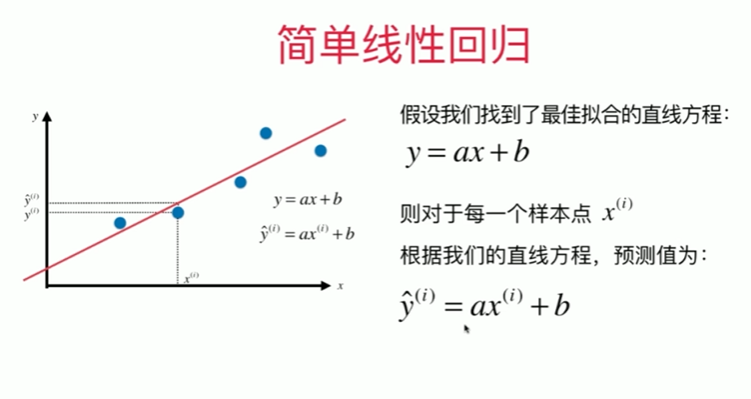





5-2 最小二乘法

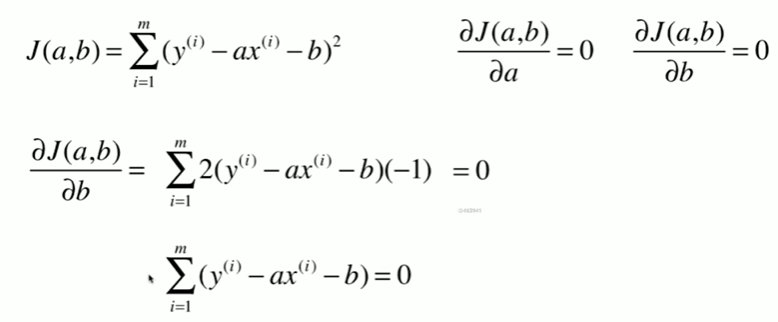
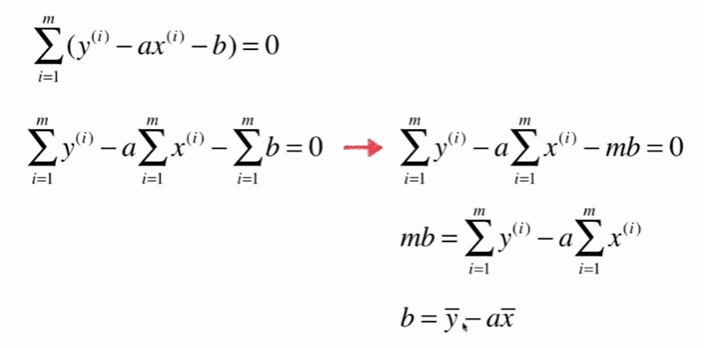
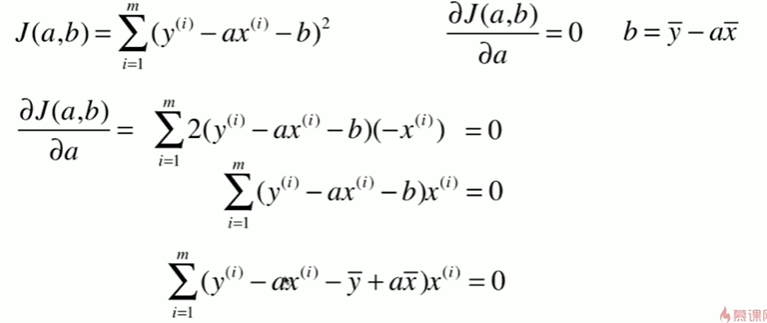

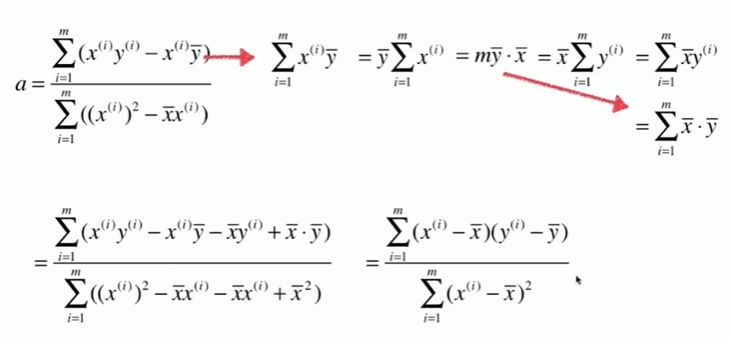
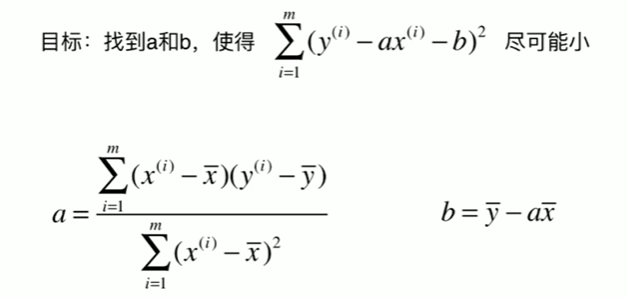
5-3 简单线性回归的实现
#见下面代码
5-4 向量化

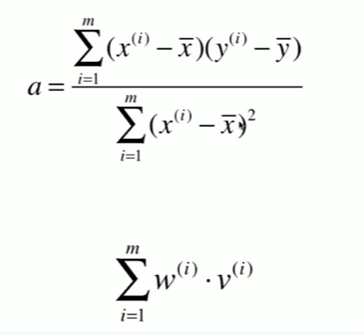
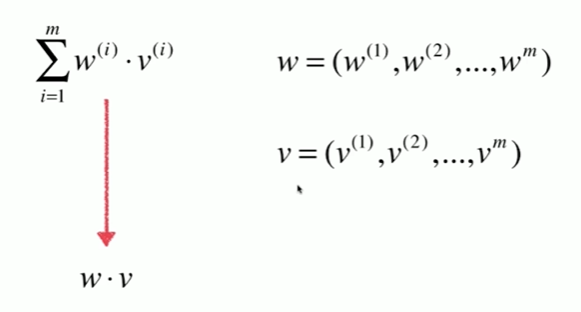
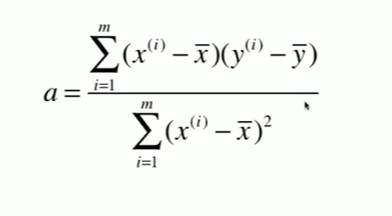
Notbook 示例
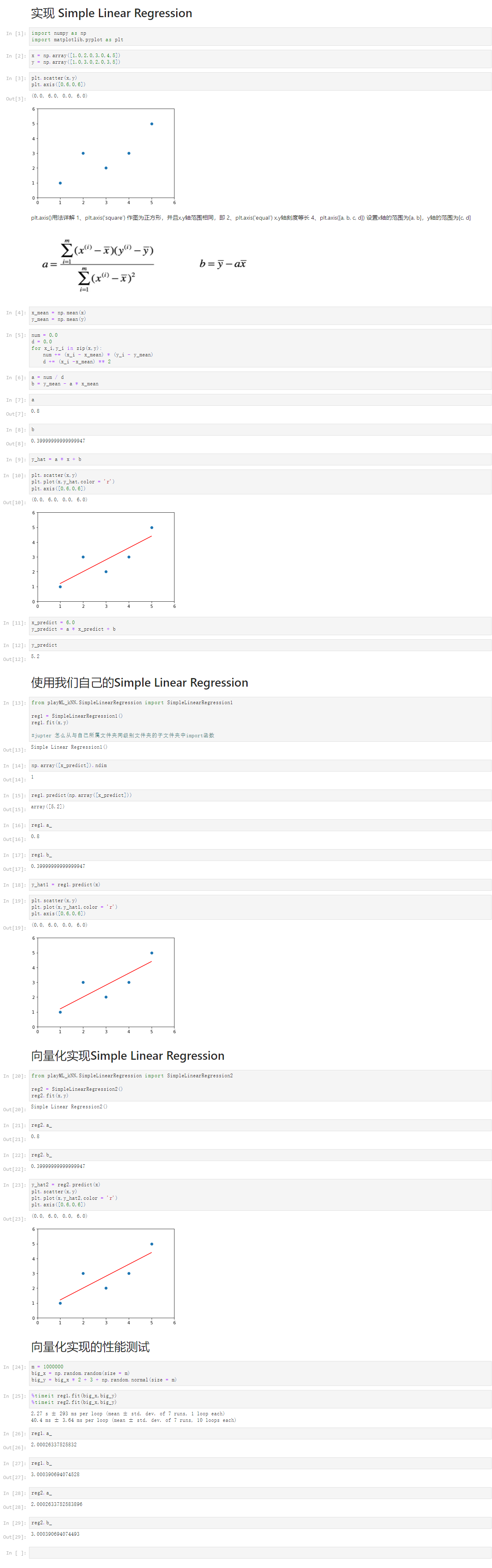
Notbook 源码

1 实现 Simple Linear Regression 2 [1] 3 import numpy as np 4 import matplotlib.pyplot as plt 5 [2] 6 x = np.array([1.0,2.0,3.0,4,5]) 7 y = np.array([1.0,3.0,2.0,3,5]) 8 [3] 9 plt.scatter(x,y) 10 plt.axis([0,6,0,6]) 11 (0.0, 6.0, 0.0, 6.0) 12 13 plt.axis()用法详解 1、plt.axis(‘square’) 作图为正方形,并且x,y轴范围相同,即 2、plt.axis(‘equal’) x,y轴刻度等长 4、plt.axis([a, b, c, d]) 设置x轴的范围为[a, b],y轴的范围为[c, d] 14 15 %E7%BA%BF%E6%80%A7%E5%9B%9E%E5%BD%92.png 16 17 [4] 18 x_mean = np.mean(x) 19 y_mean = np.mean(y) 20 [5] 21 num = 0.0 22 d = 0.0 23 for x_i,y_i in zip(x,y): 24 num += (x_i - x_mean) * (y_i - y_mean) 25 d += (x_i -x_mean) ** 2 26 [6] 27 a = num / d 28 b = y_mean - a * x_mean 29 [7] 30 a 31 0.8 32 [8] 33 b 34 0.39999999999999947 35 [9] 36 y_hat = a * x + b 37 [10] 38 plt.scatter(x,y) 39 plt.plot(x,y_hat,color = 'r') 40 plt.axis([0,6,0,6]) 41 (0.0, 6.0, 0.0, 6.0) 42 43 [11] 44 x_predict = 6.0 45 y_predict = a * x_predict + b 46 [12] 47 y_predict 48 5.2 49 使用我们自己的Simple Linear Regression 50 [13] 51 from playML_kNN.SimpleLinearRegression import SimpleLinearRegression1 52 53 reg1 = SimpleLinearRegression1() 54 reg1.fit(x,y) 55 56 #jupter 怎么从与自己所属文件夹同级别文件夹的子文件夹中import函数 57 Simple Linear Regression1() 58 [14] 59 np.array([x_predict]).ndim 60 1 61 [15] 62 reg1.predict(np.array([x_predict])) 63 array([5.2]) 64 [16] 65 reg1.a_ 66 0.8 67 [17] 68 reg1.b_ 69 0.39999999999999947 70 [18] 71 y_hat1 = reg1.predict(x) 72 [19] 73 plt.scatter(x,y) 74 plt.plot(x,y_hat1,color = 'r') 75 plt.axis([0,6,0,6]) 76 (0.0, 6.0, 0.0, 6.0) 77 78 向量化实现Simple Linear Regression 79 [20] 80 from playML_kNN.SimpleLinearRegression import SimpleLinearRegression2 81 82 reg2 = SimpleLinearRegression2() 83 reg2.fit(x,y) 84 Simple Linear Regression2() 85 [21] 86 reg2.a_ 87 0.8 88 [22] 89 reg2.b_ 90 0.39999999999999947 91 [23] 92 y_hat2 = reg2.predict(x) 93 plt.scatter(x,y) 94 plt.plot(x,y_hat2,color = 'r') 95 plt.axis([0,6,0,6]) 96 (0.0, 6.0, 0.0, 6.0) 97 98 向量化实现的性能测试 99 [24] 100 m = 1000000 101 big_x = np.random.random(size = m) 102 big_y = big_x * 2 + 3 + np.random.normal(size = m) 103 [25] 104 %timeit reg1.fit(big_x,big_y) 105 %timeit reg2.fit(big_x,big_y) 106 2.27 s ± 293 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) 107 40.4 ms ± 3.64 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) 108 109 [26] 110 reg1.a_ 111 2.00026337525832 112 [27] 113 reg1.b_ 114 3.000390694074528 115 [28] 116 reg2.a_ 117 2.0002633752583896 118 [29] 119 reg2.b_ 120 3.000390694074493
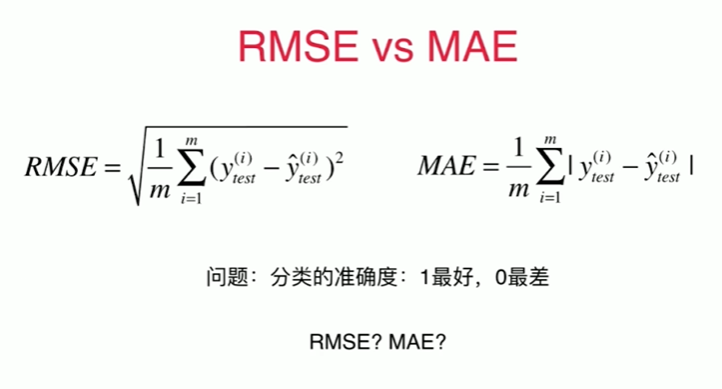
5-5 衡量线性回归法的指标 MSE,RMS,MAE






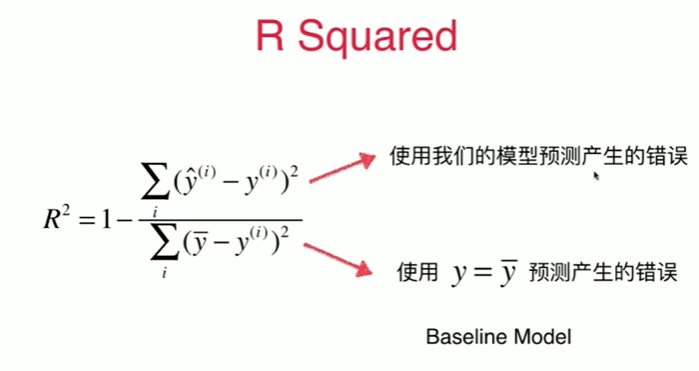
5-6 最好的衡量线性回归法的指标 R Squared


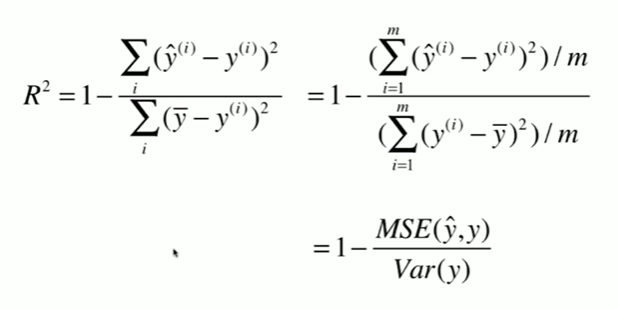
Notbook 示例
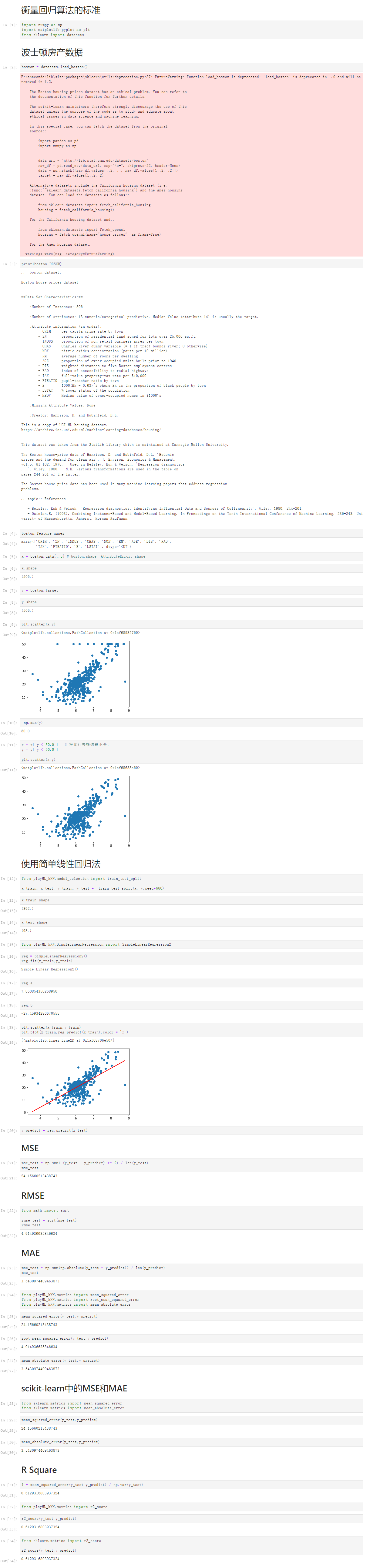
Notbook 源码
1 衡量回归算法的标准 2 [1] 3 import numpy as np 4 import matplotlib.pyplot as plt 5 from sklearn import datasets 6 波士顿房产数据 7 [2] 8 boston = datasets.load_boston() 9 F:\anaconda\lib\site-packages\sklearn\utils\deprecation.py:87: FutureWarning: Function load_boston is deprecated; `load_boston` is deprecated in 1.0 and will be removed in 1.2. 10 11 The Boston housing prices dataset has an ethical problem. You can refer to 12 the documentation of this function for further details. 13 14 The scikit-learn maintainers therefore strongly discourage the use of this 15 dataset unless the purpose of the code is to study and educate about 16 ethical issues in data science and machine learning. 17 18 In this special case, you can fetch the dataset from the original 19 source:: 20 21 import pandas as pd 22 import numpy as np 23 24 25 data_url = "http://lib.stat.cmu.edu/datasets/boston" 26 raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None) 27 data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) 28 target = raw_df.values[1::2, 2] 29 30 Alternative datasets include the California housing dataset (i.e. 31 :func:`~sklearn.datasets.fetch_california_housing`) and the Ames housing 32 dataset. You can load the datasets as follows:: 33 34 from sklearn.datasets import fetch_california_housing 35 housing = fetch_california_housing() 36 37 for the California housing dataset and:: 38 39 from sklearn.datasets import fetch_openml 40 housing = fetch_openml(name="house_prices", as_frame=True) 41 42 for the Ames housing dataset. 43 44 warnings.warn(msg, category=FutureWarning) 45 46 [3] 47 print(boston.DESCR) 48 .. _boston_dataset: 49 50 Boston house prices dataset 51 --------------------------- 52 53 **Data Set Characteristics:** 54 55 :Number of Instances: 506 56 57 :Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target. 58 59 :Attribute Information (in order): 60 - CRIM per capita crime rate by town 61 - ZN proportion of residential land zoned for lots over 25,000 sq.ft. 62 - INDUS proportion of non-retail business acres per town 63 - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) 64 - NOX nitric oxides concentration (parts per 10 million) 65 - RM average number of rooms per dwelling 66 - AGE proportion of owner-occupied units built prior to 1940 67 - DIS weighted distances to five Boston employment centres 68 - RAD index of accessibility to radial highways 69 - TAX full-value property-tax rate per $10,000 70 - PTRATIO pupil-teacher ratio by town 71 - B 1000(Bk - 0.63)^2 where Bk is the proportion of black people by town 72 - LSTAT % lower status of the population 73 - MEDV Median value of owner-occupied homes in $1000's 74 75 :Missing Attribute Values: None 76 77 :Creator: Harrison, D. and Rubinfeld, D.L. 78 79 This is a copy of UCI ML housing dataset. 80 https://archive.ics.uci.edu/ml/machine-learning-databases/housing/ 81 82 83 This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University. 84 85 The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic 86 prices and the demand for clean air', J. Environ. Economics & Management, 87 vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics 88 ...', Wiley, 1980. N.B. Various transformations are used in the table on 89 pages 244-261 of the latter. 90 91 The Boston house-price data has been used in many machine learning papers that address regression 92 problems. 93 94 .. topic:: References 95 96 - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261. 97 - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann. 98 99 100 [4] 101 boston.feature_names 102 array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 103 'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7') 104 [5] 105 x = boston.data[:,5] # boston.shape AttributeError: shape 106 [6] 107 x.shape 108 (506,) 109 [7] 110 y = boston.target 111 [8] 112 y.shape 113 (506,) 114 [9] 115 plt.scatter(x,y) 116 <matplotlib.collections.PathCollection at 0x1af68582760> 117 118 [10] 119 np.max(y) 120 50.0 121 [11] 122 x = x[ y < 50.0 ] # 将此行去掉结果不变, 123 y = y[ y < 50.0 ] 124 125 plt.scatter(x,y) 126 <matplotlib.collections.PathCollection at 0x1af68688a60> 127 128 使用简单线性回归法 129 [12] 130 from playML_kNN.model_selection import train_test_split 131 132 x_train, x_test, y_train, y_test = train_test_split(x, y,seed=666) 133 [13] 134 x_train.shape 135 (392,) 136 [14] 137 x_test.shape 138 (98,) 139 [15] 140 from playML_kNN.SimpleLinearRegression import SimpleLinearRegression2 141 [16] 142 reg = SimpleLinearRegression2() 143 reg.fit(x_train,y_train) 144 Simple Linear Regression2() 145 [17] 146 reg.a_ 147 7.860854356268956 148 [18] 149 reg.b_ 150 -27.45934280670555 151 [19] 152 plt.scatter(x_train,y_train) 153 plt.plot(x_train,reg.predict(x_train),color = 'r') 154 [<matplotlib.lines.Line2D at 0x1af68706e50>] 155 156 [20] 157 y_predict = reg.predict(x_test) 158 MSE 159 [21] 160 mse_test = np.sum( (y_test - y_predict) ** 2) / len(y_test) 161 mse_test 162 24.15660213438743 163 RMSE 164 [22] 165 from math import sqrt 166 167 rmse_test = sqrt(mse_test) 168 rmse_test 169 4.914936635846634 170 MAE 171 [23] 172 mae_test = np.sum(np.absolute(y_test - y_predict)) / len(y_predict) 173 mae_test 174 3.5430974409463873 175 [24] 176 from playML_kNN.metrics import mean_squared_error 177 from playML_kNN.metrics import root_mean_squared_error 178 from playML_kNN.metrics import mean_absolute_error 179 [25] 180 mean_squared_error(y_test,y_predict) 181 24.15660213438743 182 [26] 183 root_mean_squared_error(y_test,y_predict) 184 4.914936635846634 185 [27] 186 mean_absolute_error(y_test,y_predict) 187 3.5430974409463873 188 scikit-learn中的MSE和MAE 189 [28] 190 from sklearn.metrics import mean_squared_error 191 from sklearn.metrics import mean_absolute_error 192 [29] 193 mean_squared_error(y_test,y_predict) 194 24.15660213438743 195 [30] 196 mean_absolute_error(y_test,y_predict) 197 3.5430974409463873 198 R Square 199 [31] 200 1 - mean_squared_error(y_test,y_predict) / np.var(y_test) 201 0.6129316803937324 202 [32] 203 from playML_kNN.metrics import r2_score 204 [33] 205 r2_score(y_test,y_predict) 206 0.6129316803937324 207 [34] 208 from sklearn.metrics import r2_score 209 210 r2_score(y_test,y_predict) 211 0.6129316803937324


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?