
字典实例化类
依对象的属性作为key值,value为属性值。以下使用user(**xiao)注入字典获取user对象,与使用 u = user('xiaoming', '123')一致
class user(object):
def __init__(self,userName,password):
self.userName = userName
self.password = password
xiao = {'userName':'xiaoming','password':'123'}
u=user(**xiao)
print u.userName
日志打印format
formate打印注意string中变量和format中变量名对应
time = 10
name = 'caesar'
print "time:{time},name:{name}".format(time = time, name = name)
元类
用于构造类的类,可以控制类的创建行为,需要在类上加上@six.add_metaclass('xxx'),如下:
type 有两个重载版本:
type(object),即我们最常用的版本。
type(name, bases, dict),一个更强大的版本。通过指定 类名称(name)、父类列表(bases)和 属性字典(dict)动态合成一个类
import six
#元类修改方法名
class Mymetaclass(type):
def __new__(cls, clsname, bases,dct):
my_attr={}
for name,val in dct.items():
if not name.startswith('__'):
my_attr["my_"+name] = val # 类中的方法名加my_,val为方法对象
else:
my_attr[name] = val
return type.__new__(cls, clsname, bases,my_attr)
# 创建类
@six.add_metaclass(Mymetaclass)
class ca_class(object):
def print_name(self,name):
print('%s come here' %name)
ca = ca_class()
ca.print_name('caesar') # 调用方法会报错
执行报错,没有print_name属性:

修改 print_name为my_print_name

字典排序
dic = {"A":2,"Q":4,"B":7,"E":9,"C":1}
sorted(dic)
输出['A', 'B', 'C', 'E', 'Q']
dic = {"A":2,"Q":4,"B":7,"E":9,"C":1}
sorted(dic.items())
输出[('A', 2), ('B', 7), ('C', 1), ('E', 9), ('Q', 4)] 以key自然升序排列,元素为元组的list
li = [] ciro = {'age':12,'name':'ciro'} caesar = {'age':11,'name':'caesar'} li.append(ciro) li.append(caesar) sorted(li, key=lambda x:x['age'])
对序列按照其中元素或对象的某值进行排序,以上按照其中元素的age进行升序排序[{'age': 11, 'name': 'caesar'}, {'age': 12, 'name': 'ciro'}], 当指定reverse=True,按照逆序排列
三目表达
逻辑 if 条件 else 逻辑 ,类似java中 (x==y)?'Y':'N' 如果X=Y 执行'Y',否则执行 ''N
self._sleep(wait_time if (started or wait_time is None) else 0)
多list合并一个list
两个list 合并为1个list 使用过 list = list1 + list2
将一个list中所有子列表合并成一个list
list_t = [["co","olor"],["bro","ther"]] list(itertools.chain(*list_t))
列表推导式
①[x for x in data if condition]
此处if主要起条件判断作用,data数据中只有满足if条件的才会被留下,最后统一生成为一个数据列表
②[exp1 if condition else exp2 for x in data]
此处if...else主要起赋值作用,当data中的数据满足if条件时将其做exp1处理,否则按照exp2处理,最后统一生成为一个 数据列表
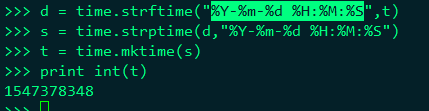
时间戳
time.time()获取当前时间数字
time.localtime() 获取当前时间数组

将当前时间转化为日期,将struct_time ,string-format-time

请日期转为时间戳 string-parse-time
datetime对象
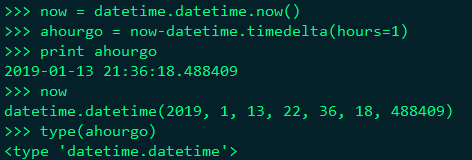
datetime.datetime.now()获取当前时间datetime对象
datetime.timedelta(hours=1) 获取当前时间1小时前的datetime对象
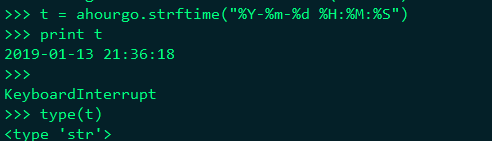
datetime对象通过strftime("%Y-%m-%d %H:%M:%S")转为日期
在转化时间戳时,还是需要转为struct_time, datetime的timetuple方法
类加载
在java中类加载,父类静态方法-->子类静态方法-->父类初始化方法--->子类初始化方法
但在python中,创建子类对象不加载父类静态方法和初始化方法(此处加载即执行),而是将父类的方法属性作为子类的方法属性
super(B, self).__init__() ,super用于调用父类方法。
类中__call__
__call__ 在那些类的实例经常改变状态的时候会非常有效。调用这个实例是一种改变这个对象状态的直接和优雅的做法
正则表达式
给每个匹配起一个漂亮的名字(类似pyparsing的setResultsName )
在正则中使用(?P<name>正则匹配)
import re
netinfo="enp0s3: 13857 151 0 0 0 0 0 0 " \
" 15432 185 0 0 0 0 0 0"
pa="(?P<name>[a-z\d]+:)\s+" \
"(?P<rx_bytes>\d+)\s+" \
"(?P<rx_packets>\d+)\s+" \
"(?P<rx_errs>\d+)\s+" \
"(?P<rx_drop>\d+)\s+" \
"(?P<rx_fifo>\d+)\s+" \
"(?P<rx_frame>\d+)\s+" \
"(?P<rx_compressed>\d+)\s+" \
"(?P<rx_multicast>\d+)\s+" \
"(?P<tx_bytes>\d+)\s+" \
"(?P<tx_packets>\d+)\s+" \
"(?P<tx_errs>\d+)\s+" \
"(?P<tx_drop>\d+)\s+" \
"(?P<tx_fifo>\d+)\s+" \
"(?P<tx_colls>\d+)\s+" \
"(?P<tx_carrier>\d+)\s+" \
"(?P<tx_compressed>\d+)"
p=re.compile(pa)
match = p.search(netinfo)
m=match.groupdict()
print m
执行后返回:

// 前瞻:
exp1(?=exp2) 查找exp2前面的exp1
// 后顾:
(?<=exp2)exp1 查找exp2后面的exp1
// 负前瞻:
exp1(?!exp2) 查找后面不是exp2的exp1
// 负后顾:
(?<!exp2)exp1 查找前面不是exp2的exp1
>>> re.sub(r'(?<=\[\')foo',"caesar", "['foo1', 'foo2'")
"['caesar1', 'foo2'"
与linux命令交互
读取linux命令控制台输出,sys.stdin.readlines()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号