Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields(翻译)
0 - Abstract
我们提出了一种方法去在一张图片中有效地识别多个人体的2D姿势。这个方法使用了一个无参数表示法,我们将其叫为Part Affinity Fields(PAFs),其是去在图片中根据个体识别身体各部分的联合。这个架构编码了全体信息,并且允许一个贪婪的从底向上的解析步骤,这在实现实时性能的时候有着高度的精度而无须考虑图像中个体的数量。这个架构被设计成使用了两个分支的相同序列预测过程,从而来联合学习部分定位以及他们的联系。我们的方法在the inaugural COCO 2016 keypoints challenge中首次提出,并且不管在性能还是有效性上都超过了之前在MPII Multi-Person基准上的最佳方法。
1 - Introduction
人体2D姿势评估是定位解剖学上关键点或者部分的问题,其中寻找个体的身体部位被高度广度。在图像中推测多个人,特别是社群参与的个体,显示出了一个独特的挑战集合。首先,每一张图片可能包含不确定数目的人,并且这些人能够以各种尺寸出现在任何位置。其次,人与人之间的交互将产生复杂的空间推理,由于接触、咬合和肢体的关节,使得各部分的联系变得困难。第三点,运行时复杂度随着图片中个体数量的增加而变得更加复杂,从而使得做好实时性能是一个挑战。
常见的方法是运用一个人物检测器并且对于每一个检测对象执行单人的姿势评估。这种自顶向下的方法直接利用已有的技术来做单人姿势评估,但是需要前期的保证:如果人物检测器失败了(因为它很容易在人物接近时候失误),那么检测结果中将没有可以恢复本源的方法。更进一步,这些自顶向下方法的运行时间与人物的数量成比例:对于每一个检测,一个简单的人物姿势评估器需要运行,如果那里的人物越多,那么需要的计算花销越多。与之相反,自底向上方法是吸引人的,因为他们提供了早期结果的鲁棒性并且具有使得图片中人物数量与运行时间复杂性解耦合的潜力。并且,自底向上方法不用直接使用来自别的身体部分以及别的个体的全局信息。实际上,之前的自底向上方法不能保证效率的提高,因为最后的解析需要代价高昂的全局推理。例如,Pishchulin等人提出的种子工作,提出了一种联合了标签部分检测候选以及将它们联系到个体上的自底向上的方法。然而,在一个全连接图上解决整数线性规划问题是一个NP难问题,并且其平均处理时间大约需要几小时。Insafutdinov等人结合基于ResNet的有效的部分检测器以及图像从属成对分数(image-dependent pairwise scores)构建模型,极大的提高了运行效率,但是这个方法对每张图片的处理时间仍然需要几分钟,这是受限于部分检测器的数量。成对表现(pairwise representations)在[11]中使用了,其很难做精确的回归,因此需要独立的逻辑回归。
在这篇文章中,我们提出了一个用于多人体姿势评估的在多个公开基准上有着当前最佳准确率的有效方法。我们提出第一个利用Part Affinity Fields(PAFs)表示自底向上联系分数,这是一个在图片维度上编码了四肢的定位和方向的2D集合向量。我们证明了同时推到这些检测表示以及全局信息联系编码有效的允许了使用一个贪婪解析步骤去实现高质量的结果,而只需要少量的计算花销。我们已经将代码开源以至于可以完全复现,提出了用于多个体2D姿势检测的实时系统。
2 - Method
图2图解了我们方法的整体架构。这个系统将一张彩色的尺寸为$w \times h$的图像作为输入然后产生关于对于图像中的每一个个体的联系关键点的2D定位作为输出(图2 e)。首先,一个前向网络同时用来预测身体部位定位的一个2D置信度图S的集合(图2 b)以及一个部位密切关系的2D向量域L,其编码了各个部位之间的关联度(图2 c)。集合$S=(S_1, S_2, ..., S_j)$有$J$个置信度图,每个部位一个,其中$S \in R^{w \times h},j \in \{1...J\}$。集合$L=\{L_1, L_2, ..., L_C\}$有$C$个向量域,每一个一个肢体,其中$L_C \in R^{w \times h \times 2},c \in \{1...C\}$,每一张图片在定位$L_c$处编码一个2D向量(见于图1)。最后,置信度字典和关联域通过贪婪推理进行解析(图2 d)从而输出图像中所有个体的2D关键点。

图1:上子图:多个体姿势评估。属于同一个个体的身体部位被连接起来。左下子图:对应于右手腕和右手肘的部位连接域(PAFs)。不同方向用不同颜色编码。右下子图:PAFs预测的放大图像。在域中的每一个像素,一个2D向量编码了肢体的位置和方向。
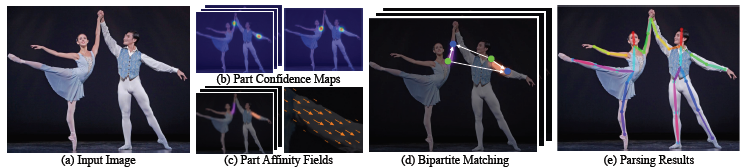
图2:整体架构。我们的方法将整张图片作为两个分支CNN的输入并且联合对于身体部位检测的预测置信图(见于(b))以及部位关系的部位联合域(见于(c))。解析步骤执行一组双边匹配,以关联身体部位候选(d)。我们最后将它们组合成图像中全部个体的全身姿势。
2.1 - Simultaneous Detection and Association
我们的架构见于图3,同时预测检测置信度字典以及编码部位到部位联系的关联域。这个网络被划分为两个分支:顶部分支,用米黄色标注,预测了置信度字典,而底部分支,用蓝色标注,预测关联域。每一个分支都是一个重复预测架构,跟随着Wei等人提出的方法,即通过依次重复步骤来调整预测结果,$t \in \{1, ... ,T\}$,在每个阶段中都加入了监督。
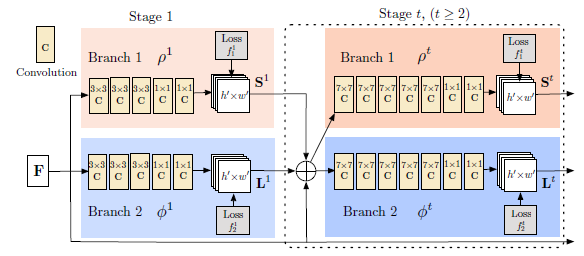
图3:两个分支多步骤CNN的架构。第一个分支中的每一个阶段预测置信字典,第二个分支的每一个阶段预测PAFs。在每个阶段之后,两个分支的预测结果加上图片特征将传递给下一个阶段。
图像首先通过一个卷积网络分析(采用VGG-19的前面10层进行初始化以及微调),产生一个集合的特征字典$F$,这个字典被作为每一个分支第一个阶段的输入。在第一个阶段中,这个网络产生了一个集合的检测置信度图$S^1=\rho^1(F)$以及一个部位关联域集合$L^1=\phi^1(F)$,其中$\rho^1$以及$\phi^1$是在第一个阶段的CNNs推理。在每一个随后的阶段中,来自前一阶段的每一个分支的预测结合原始图像特征$F$,被结合起来使用来产生确认预测,
$$S^t=\rho^t(F, S^{t-1}, L^{t-1}),\ \forall t \geq 2,\ (1)$$
$$L^t=\phi^t(F, S^{t-1}, L^{t-1}),\ \forall t \geq 2,\ (2)$$
其中$\rho^t$以及$\phi^t$是在步骤$t$中CNNs的推理。
图4展示了贯穿几个步骤的置信图以及关联域的进行设计。为了引导网络迭代地在第一个分支中预测身体部位的置信度图以及在第二个分支中预测PAFs,我们在每一个阶段的末尾加入了两个损失函数,每一个分支各有一个损失函数。我们在预测评估和真实图和域之间使用一个$L_2\ loss$。这里,我们在空间上分配损失函数的比重以解决有些数据集不能完全给所有个体打上标签的问题。特别地,在第t个阶段,在两个分支中的损失函数为:
$$f_S^t = \sum_{j=1}^{J}\sum_{P}W(p)\cdot \left \| S_j^t(P)-S_j^*(p) \right \|_2^2,\ (3)$$
$$f_L^t = \sum_{c=1}^{C}\sum_{P}W(p)\cdot \left \| L_c^t(P)-L_c^*(p) \right \|_2^2,\ (4)$$
其中$S_j^*$是真实的部位置信度图,$L_c^*$是真实的部位联系向量域,$W$是一个二进制编码,当在图像的位置$p$处缺少标注时,$W(p)=0$。该编码用来避免惩罚在训练过程中的正确的积极预测。每一个阶段的中间监督通过定期补充梯度的方式而被用来解决梯度消失问题。整体的目标如下:
$$f=\sum_{t=1}^{T}(f_S^t+f_L^t)\ (5)$$
2.2 - Confidence Maps for Part Detection
为了在训练过程中评估公式(5)中的$f_S$,我们从有标注的2D关键点来生成真实置信图$S^*$。每一个置信图是一个对特定身体部位出现在每一个像素位置的可信度的2D表示。理想上,如果一个个体出现在图片中,只要其相应部位是可见的,那么在每一个置信图中将会有一个峰值出现。如果有多个个体出现,那么对于每一个个体$k$的每一个可见部位$j$都有一个相对应的峰值。
我们首先为每一个个体$k$产生个体的置信图$S_{j,k}^*$。用$x_{j,k} \ in R^2$表示个体$k$的身体部位$j$的真实位置。在$S_{j,k}^*$中的位置$p \in R^2$的值定义为:
$$S_{j,k}^*(p)=exp\left (-\frac{\left \| p-x_{j,k} \right \|^2_2}{\sigma^2}\right )\ (6)$$
其中$\sigma$控制峰值的传播。网络预测的置信图是通过一个最大操作(取最大值)将各个置信图聚合在一起:
$$S_j^*(p)=\mathop{max}\limits_{k}S^*_{j,k}(p)\ (7)$$
我们采用置信图的最大值而不是平均值从而使得将近峰值的精确度是不同的,如右图所示(下图)。在测试时,我们预测置信图(如图4第一行所示),并且通过非极大值抑制来获得身体部位候选。
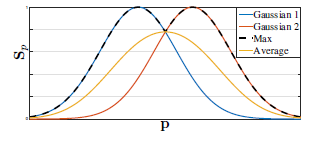
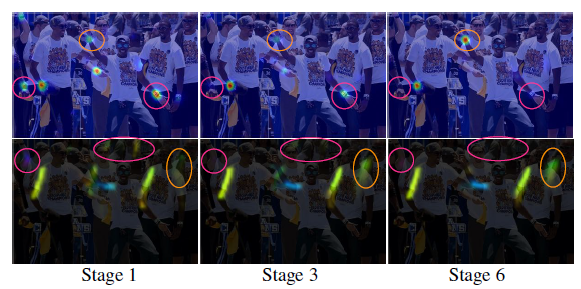
图4:贯穿各个阶段的(第一行)右手腕的置信图以及右前臂PAFs(第二行)。虽然在早先阶段中有着左右身体部位和肢体的混淆,但是通过在后续的全局推理中,评估结果得到了改善,如上图圈出的区域。
2.3 - Part Affinity Fields for Part Association
给定一个集合的身体部位检测结果(如图5中红色和蓝色点所示),怎样在不知道个体数量的情况下去整合它们从而构成各个个体整个身体的姿势?我们需要一个对于每一对身体部位检测联合的置信度衡量,也就是它们属于同一个个体。一种可能的方案是通过检测一个额外的在肢体上的每对部位的中点,并且检查其在候选部位检测之间的发生率,如图5b所示。然而,但个体拥挤到一块(因为他们很容易这样做),这些中点有可能表达了错误的联系(如图5b中绿线所示)。这些错误联系会因为两个表达局限性而增加:(1)它只对每一个肢体的位置编码,而不对方向编码;(2)它将一个肢体的支持域缩小到一个简单的点。

图5:部位联系策略。(a)对于两个身体部位类别的身体部位检测候选区域(红点和蓝点)以及所有候选连接(灰色线)。(b)使用中点(黄点)的连接结果表示:正确连接(黑线)以及错误连接(绿线),绿线其实也满足发生率约束。(c)使用PAFs的结果(黄色箭头)。通过肢体的支持,对位置和方向进行编码,PAFs消除了错误关联。
为了解决这些局限性,我们提出一种新颖的特征表达,叫做part affinity fields,其不仅保存了肢体支持域的位置信息,并且保存了方向信息(如图5c所示)。对于每一个肢体的部位联系是一个2D向量域,如图1d所示:对于区域内的每一个像素,其属于某一个特定肢体,一个2D向量编码了肢体中从一个部位到另一个部位的方向。每一个类型的肢体都有对应的联系域来联系其关联的两个部位。
考虑下图所示的简单肢体。让$x_{j_1,k}$和$x_{j_2,k}$表示个体$k$的肢体$c$的部位$j_1$和$j_2$的真是坐标。如果一个点$p$落在肢体上,则$L_{c,k}^*(p)$的值是一个从$j_1$指向$j_2$的单位向量;对于其它点,向量的值为0。

为了在训练过程中评估公式5中的$f_L$,我们定义真实部位联合向量域,$L_{c,k}^*$,对于图片中的点$p$有:
$$L_{c,k}^*(p)=\begin{cases} v\ if\ p\ on\ limb\ c,k\\ 0\ otherwise \end{cases}\ \ (8)$$
其中,$v=(x_{j_2,k}-x_{j_1,k})/\left \| x_{j_2,k}-x_{j_1,k} \right \|$是肢体的单位向量。肢体上的点集合定义为那些线段在距离阈值内的点,也即是说,那些点$p$可以定义为:
$$0 \leq v \cdot (p-x_{j_1,k}) \leq l_{c,k} \ and \ \left | v_{\perp} \cdot (p-x_{j_1,k}) \right | \leq \sigma_l$$
其中,肢体宽度$\sigma_l$是像素级上的距离,肢体长度$l_{c,k}=\left \| x_{j_2,k}-x_{j_1,k} \right \|_2$,并且$v_{\prep}$是正交于$v$的向量。
真实部位联合域平均了图片中所有个体的联合域:
$$L_c^*(p)=\frac{1}{n_c(p)}\sum_{k}L_{c,k}^*(p)$$
其中$n_c(p)$是所有$k$个个体中在点$p$不为0的向量的数量(也即是,不同个体肢体重叠的平均像素)。
在测试时,我们通过计算对应PAF的沿着部位坐标的线段的线积分来测量候选部位检测之间的联系。也就是,我们测量了预测PAF和通过联系检测的身体部位构成的候选肢体间的一致性。特别地,对于两个候选部位位置$d_{j_1}$和$d_{j_2}$,我们从预测部位联系域中取样,$L_c$沿着线段去衡量它们间联系的置信度:
$$E=\int_{u=0}^{u=1}L_c(p(u))\cdot \frac{d_{j_2}-d_{j_1}}{\left \| d_{j_2}-d_{j_1} \right \|_2}du,\ (10)$$
其中$p(u)$是在两个身体部位$d_{j_1}$和$d_{j_2}$间插入的位置:
$$p(u)=(1-u)d_{j_1}+ud_{j_2}.\ (11)$$
实际上,我们通过抽样和求和等间距的$u$的值来近似积分。
2.4 - Multi-Person Parsing using PAFs
我们在检测置信图上运用非极大值抑制来获得对于候选部位位置的离散集合。对于每一个部位,我们可能有多个候选位置,因为在图像中有多个个体或者错误定位(如图6b所示)。这些候选部位定义了一个可能肢体的大集合。我们使用在PAF上的线积分运算来给每一个候选肢体打分,由公式10定义。找到最理想的解析存在的问题对应于一个K维度匹配问题,这是一个NP难问题(如图6c所示)。在这篇文章中,我们提出了一种贪婪松弛策略其始终可以产生高质量的匹配。我们推测其原因是,成对的联系分数能够潜在地编码全局信息,因为PAF网络有着大的接收域。
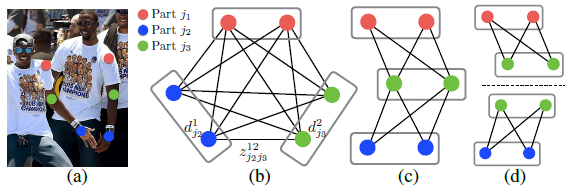
图6:图匹配。(a)标上部位检测结果的原图(b)K分割图(c)三种构造(d)一个二分图集合
形式上,我们获得了对于多个体的一个身体部位检测候选集合$D_J$,其中$D_J=\{d_j^m\ :\ for\ j \in \{1...J\},m \in \{1...N_j\}\}$,$N_j$是候选部位$j$的数量,并且$d_j^m \in R^2$是对于候选身体部位$j$的第$m-th$个检测的坐标。这些候选的身体部位检测仍然需要同同一个体的其它部位相联系,换句话说,我们需要去找到成对的部位检测,它们事实上就是在同一个肢体上的。我们定义一个变量$z_{j_1j_2}^{mn} \in \{0,1\}$来表示两个候选检测$d_{j_1}^m$和$d_{j_2}^n$是否能够连接,同时我们的目标是去找到最优的可能连接分配,$Z = \{z_{j_1j_2}^{mn}\ :\ for\ j_1,j_2 \in \{1...J\},m \in \{1...N_{j_1}\},n \in \{1...N_{j_2}\}\}$。
如果我们对于第$c$个肢体考虑一个单一部位对$j_1$和$j_2$(例如,颈部和右肩),找到最佳的联系从而转换成最大化权重二分图匹配问题。这种情形如图5b所示。在这个图匹配问题中,图的结点是身体部位候选检测$D_{j_1}$和$D_{j_2}$,而边是在成对的候选检测中的所有可能的连接。此外,每一条边通过公式10分配权重——the part affinity aggregate。在二分图中的一个匹配是一个没有两条边共享一个结点的边选择的子集。我们的目标是去寻找一个匹配使得对于所有选择的边有最大权重:
$$\begin{matrix}\mathop{max}\limits_{Z_c}E_c=\mathop{max}\limits_{Z_c}\sum_{m \in D_{j_1}}\sum_{n \in D_{j_2}}E_{mn}\cdot z_{j_1j_2}^{mn},\ (12)\\s.t.\ \forall m \in D_{j_1}, \sum_{n \in D_{j_2}}z_{j_1j_2}^{mn} \leq 1,\ (13)\\\forall n \in D_{j_2}, \sum_{n \in D_{j_2}}z_{j_1j_2}^{mn} \leq 1,\ (14)\end{matrix}$$
其中$E_c$是从肢体类型$c$中进行匹配的总权重,$Z_c$是肢体类型$c$中的子集$Z$,$E_{mn}$是通过公式10定义的在身体部位$d_{j_1}^m$和$d_{j_2}^n$之间的联系。公式13和公式14规定了两条边不能共享一个结点,即是说,没有两个属于同一种类型的肢体(例如左前臂)共享一个部位。我们能够使用匈牙利算法去获得最佳匹配。
就寻找多个体整体身体姿势来说,需要在K维度匹配问题中测定$Z$。这个问题是NP难问题并且有许多松弛(relaxations)存在。在我们的工作中,我们加入了两个松弛去做优化,特别是对于我们的维度。首先,我们选择一个最小限度的边数量去获得一个个体姿势生成树概要而不是使用全图,如图6c所示。其次,我们进一步分解匹配问题为一个集合的二分图匹配子问题并且独立地在相邻树决定匹配问题,如图6d所示。我们在3.1部分将展示详细的比对结果,其证明了最小贪婪推理近似于全局处理而计算开销只有全局处理的一小部分。其原因在于临近树结点的联系明确地通过PAFs建模,但是其内部,不相邻的树结点由CNN明确建模。这个属性的出现是因为CNN是基于一个大接收域进行训练的,并且来源于不相邻树结点的PAFs也会受已预测的PAF影响。
加入这两个松弛之后,优化可以简单分解为:
$$\mathop{max}\limits_{Z}E=\sum_{c=1}^{C}\mathop{max}\limits_{Z_c}E_c.\ (15)$$
我们因此可以独立地使用公式12-14对于每一个肢体类别获得肢体联系候选。有了全部的候选肢体连接,我们就可以将共享同个候选检测部位的连接综合起来形成对于多个体的全身姿势检测。我们在三个结构上的优化策略比在整个连接图上的优化快了几个数量级。
3.2 - Results on the COCO Keypoints Challenge
COCO训练集包含了超过10万个个体实例以及总共超过一百万的标注的关键点(也即是身体部位)。测试集合包括了“test-challenge","test-dev"以及"test-standard"三个子集,每一个子集大约有2万张图片。COCO验证定义了object keypoint similarity(OKS)以及在10个OKS阈值上使用平均准确率(AP)来作为主要计算度量标准。OKS在目标检测中有着与IoU相同的作用。其是通过个体规模以及预测点和GT点之间的距离来计算的。表3展示了在挑战中最好的几个结果。值得注意的是,我们的方法的准确率低于对较小尺度($AP^M$)的个体的自顶向下方法。其原因是我们的方法需要处理在所有个体在一张图片的一个对焦中的更大的范围尺度。相反,自顶向下方法能够将每一个检测区域放缩到一个更大的尺寸因此相比小尺度受到更少的影响。

表4:在COCO验证集上的比较实验。
在表4中,我们展示了在COCO验证集子集上的比较结果,也即是,随机选取1160张图片。我们使用了GT边界框以及一个单一人体CPM,我们使用CPM能够实现的自顶向下性能上界是62.7%的AP。如果我们使用当前最先进的目标检测器,Single Shot MultiBox Detector(SSD),性能下降了10%。这个比较表明了自顶向下方法很依赖于个体检测器。相反,我们的自底向上方法是达到了58.4%的AP。如果我们通过应用一个简单的人体CPM对从我们方法的结果解析出的每一个评估个体的每一个尺度区域进行确认,我们获得了2.6%的AP提升。注意到我们只更新了对这两种方法有足够优化的预测评估,使得其提高准确率和召回率。我们一个更大的尺度搜索能够进一步提高我们的自底向上方法的性能。图8展示了我们方法在COCO验证数据集上的错误。除了背景混淆之外,大部分的错误来自于不精确定位。这说明了在空间依赖捕获上相比身体部位识别有着更大的提高空间。
3.3 - Runtime Analysis
为了衡量我们方法的运行性能,我们收集了有不同数量个体的视频。每一个原始帧的尺寸为$1080 \times 1920$,在测试时候为了适应GPU的内存将其放缩到$368 \times 654$。实时分析在有着一块NVIDIA GeForce GTX-1080 GPU的笔记本上进行。在图8d,我们使用了个体检测以及单一个体CPM作为自顶向下的代表方法的与我们的方法进行比较,其运行时间大致和图片中出现的个体数量成比例。相反,我们的自底向上方法的运行时间几乎不随个体数量的增加而增加。运行时间主要包括两个部分:(1)CNN处理时间,其运行复杂度为$O(1)$而不管什么数量的个体;(2)多个体解析时间的运行复杂度为$O(n^2)$,其中n表示个体数量。然而,解析时间并不会很是影响整体时间,因为它比CNN处理时间小了两个数量级,例如,对于9个个体,解析用了0.58ms而CNN用了99.6ms。我们的方法对于有19个个体的视频达到了8.8fps的速度。
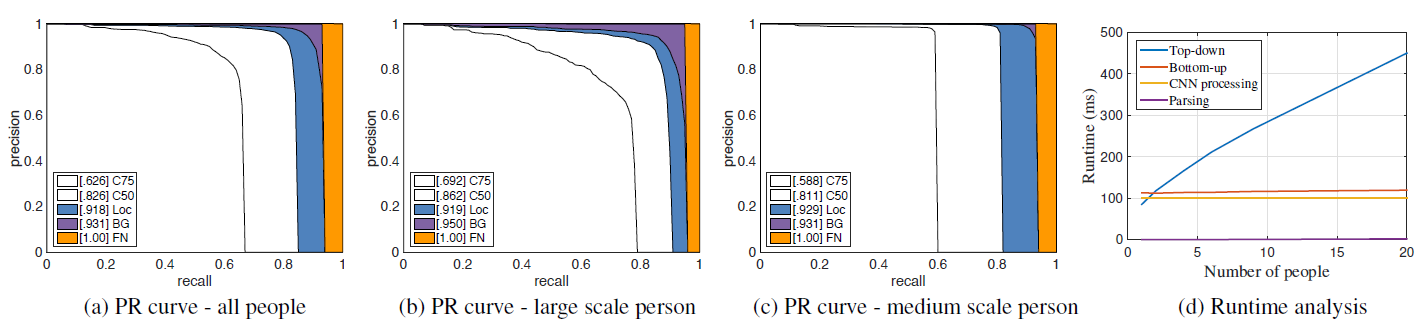
图8:在COCO验证集上的AP性能(a)(b)(c),部分3.2,运行性能分析(d),部分3.3。
4 - Discussion
具有社会意义的时刻相比于任何其它东西都更能促使人们做出图片和视频。我们的图片收集总是趋向于捕获某个个体具有意义的时刻:生日,结婚,假期,游玩,运动事件,毕业,全家福等等。为了使得机器能够解释这些图片,他们需要对图像中的人有一个了解。机器,在现实中被赋予此类感觉,便能够对这些东西做出反应甚至是参加到人类的个体和社会行为中去。
在这篇文章中,我们考虑感觉的一个关键组成部分:用于检测图片中多个体的2D姿势的实时算法。我们提出了一种明确的非参数化的关键点联系表示,其将个体肢体的位置和方向进行编码。其次,我们设计了一个架构用来融合部位检测和部位联系。并且,我们证明了贪婪解析算法能够有效地产生高质量个体姿势解析,并且随着图像中个体数量的增长,其依然保持有效。我们在图9中展示了典型的错误情况。我们已经将我们的代码开源(https://github.com/ZheC/Realtime_Multi-Person_Pose_Estimation)(包括训练模型),从而去保证整个模型的复现性以及激励在该领域更深入的研究。

图9:常见错误类型:(a)少有的姿势或者外观,(b)缺少或者错误的部位检测,(c)重叠部位,也就是说,同一个部位检测被两个个体共享,(d)两个个体间错误的部位连接,(e-f)错误的检测到雕像或者动物。
Acknowledgements
我们由衷感谢MPII和COCO人体姿势数据集的作者。这些数据集使得自然情况下进行2D人体姿势评估变得可能。这个研究在一定程度上得到了ONR Grants N00014-15-1-2358和N00014-14-1-0595的支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号