Dual Adaptive Pyramid Network for Cross-Stain Histopathology Image Segmentation(理解)
扫码关注下方公众号:"Python编程与深度学习",领取配套学习资源,并有不定时深度学习相关文章及代码分享。

今天分享一篇发表在MICCAI 2019上的论文:Dual Adaptive Pyramid Network for Cross-Stain Histopathology Image Segmentation (原文链接:[1])。
1 研究背景
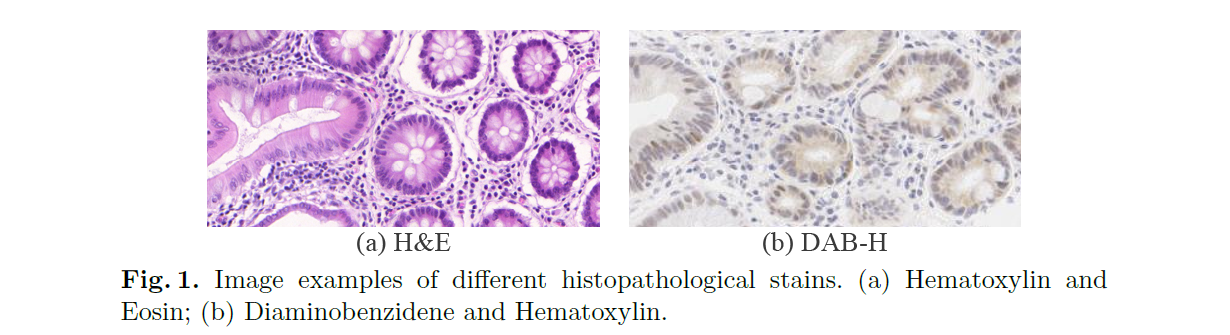
有监督的语义分割任务总是假设测试集与训练集是属于同一个数据域中的,然而在实际中,由于测试的数据与训练的数据存在分布的差距而会使得模型的性能大打折扣。例如,如上图(Fig.1)所示,不同的组织病理染色会导致图像所处的域不同,假设模型能够很好的拟合H&E染色的图像,但在DAB-H染色的图像上的性能会大大降低。一种简单的解决方案是在新的数据域上标注一些数据,而后对模型进行适应性的微调,但这需要额外的数据标注成本,特别是医学影像数据的标注还需要专家的知识。
为了解决上述问题,这篇文章提出了双自适应金字塔网络 (dual adaptive pyramid network, DAPNet)。Dual体现在域适应模块应用在了两个方面:
- 图像级适应:考虑了图像间不同的颜色和风格
- 特征级适应:考虑了两个域之间的空间不一致
这篇文章的贡献有:
- 针对病理图像分割,提出了一个深度无监督域适应算法
- 在金字塔特征的基础上,提出了两种域适应模块来缓解图像和特征层次上的域间差异
- 做了充足的实验来验证DAPNet的性能
2 方法
这篇文章的目标是在某种染色类型的图片中训练一个分割模型,而后可以用于其他不同染色类型的数据上。将训练数据作为源域$\mathcal S$ (source domain),将测试数据作为目标域$\mathcal T$ (target domain)。在源域$\mathcal S$中,图像$X_{\mathcal S}$有对应的标注$Y_{\mathcal S}$,而在目标域$\mathcal T$中,只有图像数据$X_{\mathcal T}$,而没有对应的标注。
2.1 整体流程
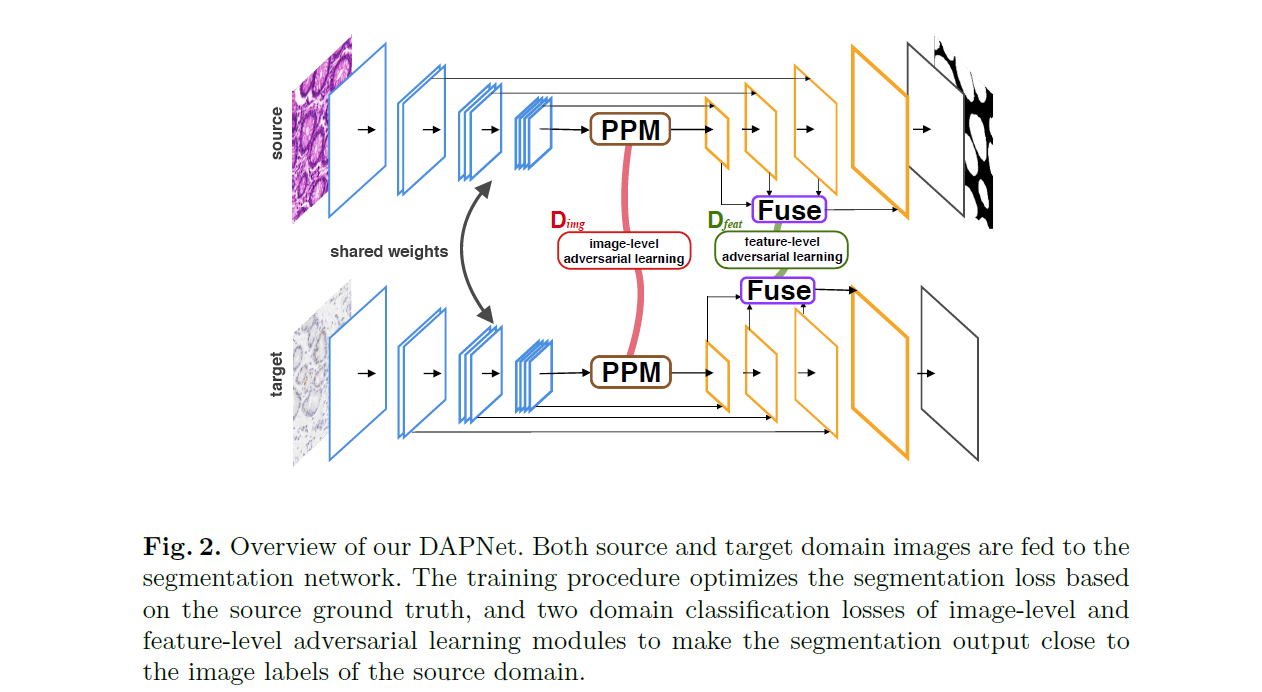
如上图(Fig.2)所示,整个流程包含一个语义分割网络$G$和两个对抗学习模型$D_{img}$和$D_{feat}$。在训练过程中,源域的图像$x_{\mathcal s}$和目标域的图像$x_{\mathcal t}$作为网络$G$的输入,采用源域图像$x_{\mathcal s}$对应的标签$y_{\mathcal s}$来学习分割任务,同时源域图像$x_{\mathcal s}$和目标域图像$x_{\mathcal t}$都用来作为$D_{img}$和$D_{feat}$对抗学习的数据。
2.2 分割网络
分割网络采用dilated ResNet-18作为骨干网络来编码输入的图像,为了获得更大的感受野,在骨干网络之后加入了PSPNet中的金字塔池化模块 (Pyramid Pooling Module, PPM)。PPM将特征图分成不同的金字塔级别的表示,然后将不同层次的特征上采样并连接成金字塔特征。在上下采样之间,采用U-Net中的跳层连接和金字塔特征融合结构来实现这个过程。最后通过一个$1\times 1$卷积层产生预测结果。综上所述,该方法包括了下采样金字塔特征提取和上采样金字塔特征融合。
分割任务的优化目标是在源域上同时最小化交叉熵损失和Dice系数损失,有:
$$\mathcal{L}_{seg}=\mathbb{E}_{x_{\mathcal s}\sim X_{\mathcal S}}[-y_{\mathcal s}log(\tilde{y}_{\mathcal s})]+\alpha\mathbb{E}_{x_{\mathcal s}\sim X_{\mathcal S}}[-\frac{2y_{\mathcal s}\tilde{y}_{\mathcal s}}{y_{\mathcal s}+\tilde{y}_{\mathcal s}}]$$
其中$y_{\mathcal s}$表示标签数据,$\tilde{y}_{\mathcal s}$表示预测结果,$\alpha$是trade-off参数。
2.3 域适应
图像级域适应: 文中采用分割网络$G$中的PPM模块的输出作为图像级的特征表达。图像级域适应有助于减少源域和目标域之间由于图像颜色和图像样式等全局图像信息差异而产生的偏移。为了消除源域和目标域之间的分布不匹配,采用了判别器$D_{img}$来辨别从两个分布中生成的特征表达(即PPM的输出)。这里借鉴了PatchGAN,将训练$D_{img}$的损失函数形式化为:
$$\mathcal{L}_{img}=\mathbb{E}_{x_{\mathcal t}\sim X_{\mathcal T}}[logD_{img}(p_{\mathcal t})]+\mathbb{E}_{x_{\mathcal s}\sim X_{\mathcal S}}[log(1-D_{img}(p_{\mathcal s}))]$$
其中$p_{\mathcal s}$和$p_{\mathcal t}$分别是分割网络$G$中PPM模块对于源域和目标域图像生成的特征表达。
特征级域适应: 特征级域适应作用在最终分割分类器之前的特征图上,对齐特征级表示有助于减少全局和局部上下文中的分割差异。与训练图像级的判别器$D_{img}$类似,特征级判别器$D_{feat}$的损失函数可以表达为:
$$\mathcal{L}_{feat}=\mathbb{E}_{x_{\mathcal t}\sim X_{\mathcal T}}[logD_{feat}(f_{\mathcal t})]+\mathbb{E}_{x_{\mathcal s}\sim X_{\mathcal S}}[log(1-D_{feat}(f_{\mathcal s}))]$$
2.4 训练目标
文中将$G,D_{img},D_{feat}$进行联合训练,整个框架的优化目标为:
$$\min_{G}\max_{D_{img},D_{feat}}\mathcal{L}_{seg}(x_{\mathcal s},y_{\mathcal s})+\lambda_1\mathcal{L}_{img}(x_{\mathcal s},x_{\mathcal t})+\lambda_2\mathcal{L}_{feat}(x_{\mathcal s}, x_{\mathcal t})$$
其中$\lambda_1$和$\lambda_2$分别是两个trade-off参数。在训练过程中采用最小-最大化博弈来进行对抗训练;测试过程中,直接采用分割网络$G$对图像进行预测。
3 实验结果
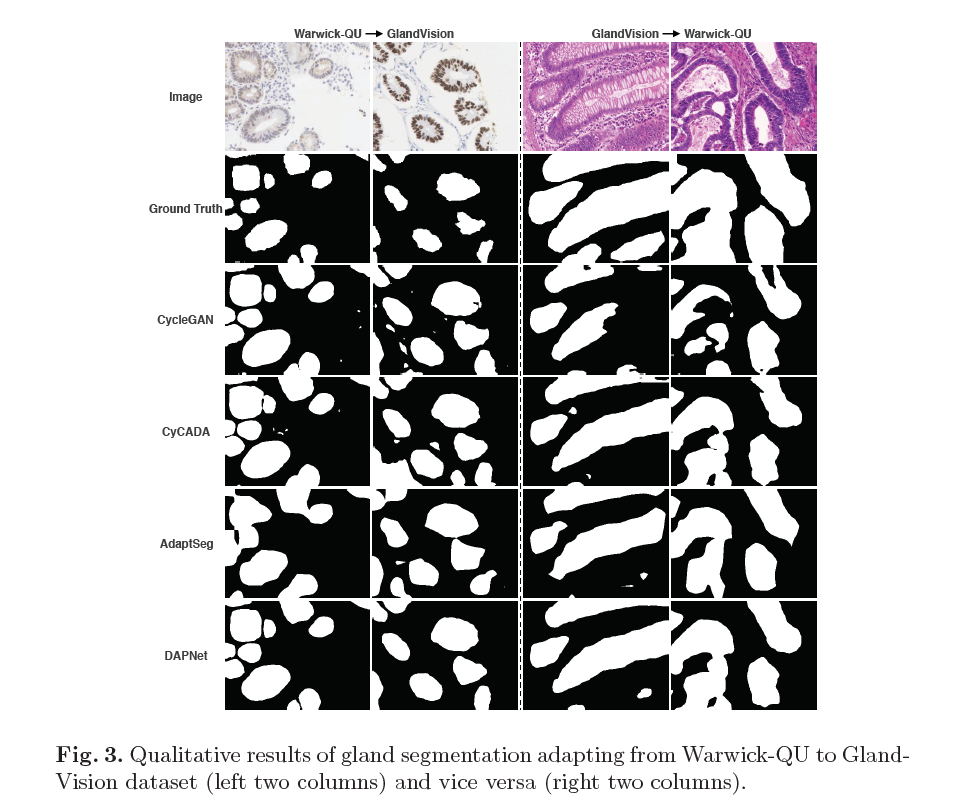
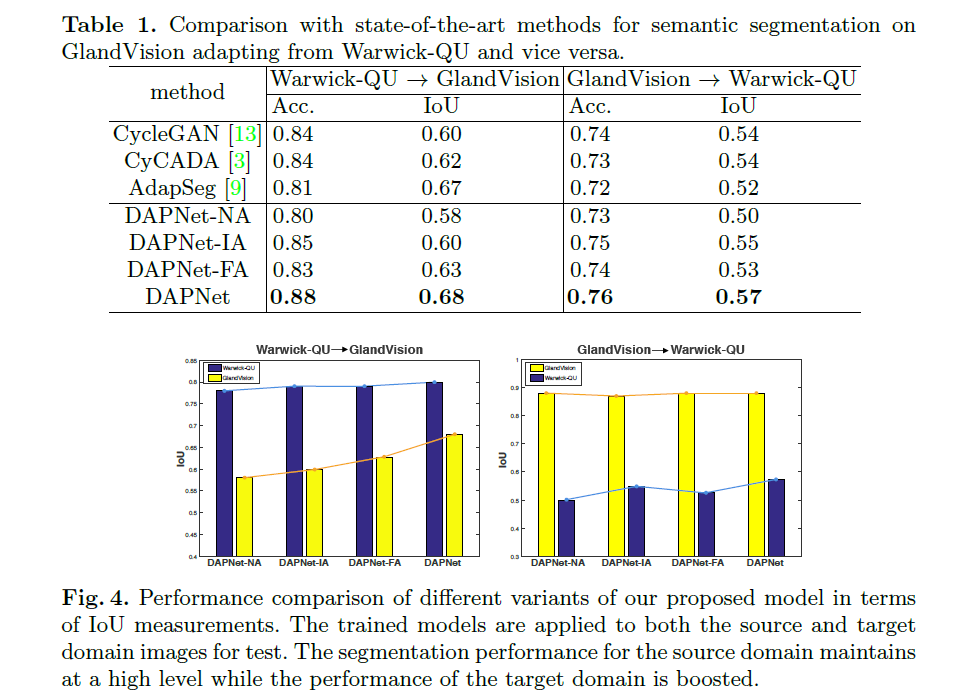
这里我只给出论文中的部分实验结果,具体的实验结果分析以及实验和参数的设置请看原文。
4 参考资料
[1] https://arxiv.org/pdf/1909.11524

 浙公网安备 33010602011771号
浙公网安备 33010602011771号