Convolutional Pose Machines(理解)
0 - 背景
人体姿态识别存在遮挡以及关键点不清晰等主要挑战,然而,人体的关键点之间由于人体结构而具有相互关系,利用容易识别的关键点来指导难以识别关键点的检测,是提高关键点检测的一个思路。本文通过提出序列化结构模型,来提高人体姿态识别任务的效果。
1 - 贡献
- 使用一个序列卷积结构模型学习表达空间信息
- 采用系统的方法来设计和训练模型,以学习图像特征和依赖图像空间模型进行结构化预测的任务
- 在MPII/LSP/FLIC等数据集上实现了最好的性能
- 分析了联合训练一个多阶段、中间重复监督的架构的效果
2 - 整体思路
2.1 - CPM(Convolutional Pose Machines)
Convolutional Pose Machines(CPM)算法思想来自于Pose Machine,其网络结果如下图:

图中(a)和(b)是pose machine中的结构,(c)和(d)是其对应的卷积网络结构,(e)展示了图片在网络中传输的不同阶段的感受野。
- Stage 1:对输入图片做处理,其中$X$代表经典的VGG结构,并且最后采用$1 \times 1$卷积输出belief map,如果人体有$k$个关键带来,则$belief map$的通道数为$k$
- Stage T:对于Stage 2以后的Stage,其结构都统称为Stage T,其输入为上一个Stage的输出以及对原始图片的特征提取的联合,输出于Stage 1一致

2.2 - 损失函数
损失函数公式如下:
$$f_t=\sum_{p=1}^{P+1}\sum_{z\in Z}\begin{Vmatrix}b_t^p(z)-b_*^p(z)\end{Vmatrix}^2_2$$
3 - 实验
3.1 - intermediate supervision
如果直接对整个网络进行梯度下降,输出层的误差经过多层反向传播会大幅减小,而发生梯度消失现象。
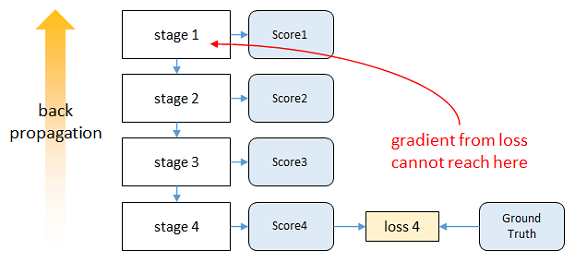
本文为了解决这个问题,提出了中间监督方法,从而保证底层参数的正常更新。
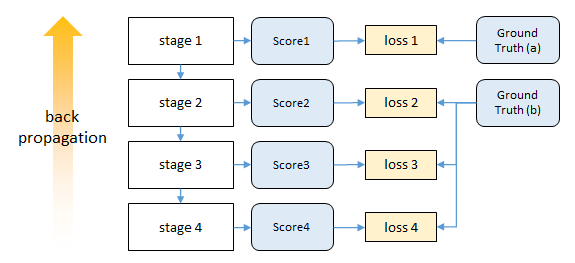
效果如下图,可以看到,加入中间监督之后,在靠近输入的stage,其梯度比没有中间监督大很多,从而保证学习的效果。

3.2 - 感受野
CPM采用大卷积核获得大感受野,对于被遮挡的关键点检测很有效果。并且本文通过实验表明了随着感受野的增大,预测的准确率上升,如下图:

文中提出增大感受野有如下几种方式:
- 增大pool,但会损失较多信息从而减小了精度
- 增大卷积核,同时会增加参数量
- 增加卷积层,层数过多容易产生梯度消失等问题
4 - 参考资料
https://arxiv.org/abs/1602.00134
https://blog.csdn.net/cherry_yu08/article/details/80846146
https://blog.csdn.net/shenxiaolu1984/article/details/51094959
https://www.cnblogs.com/JillBlogs/p/9098989.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号