爬虫之js破解 非常详细
前言
我们在写爬虫的时候经常会遇到各种反爬措施,比如现在各种大型网站越来越多的js加载令人十分头疼。
这些网站的数据不像简单的网站一样可以直接拿取,我们经常会找不到数据源头,难道只能使用selenium来模拟浏览器拿取吗?当然不是的。
本文就以如何破解有道翻译的参数为例来一步步完成js的破解。
网页分析
首先打开chrome调试台,随便在目标网址种输入一句话让它翻译过来,看一下请求的构造。(一般查看Network下的XHR选项,这是用于与服务器交互数据)

看到一个名字为translate开头的文件,猜测这就是我们要找的东西,接下来点开这个文件看看返回的响应是什么
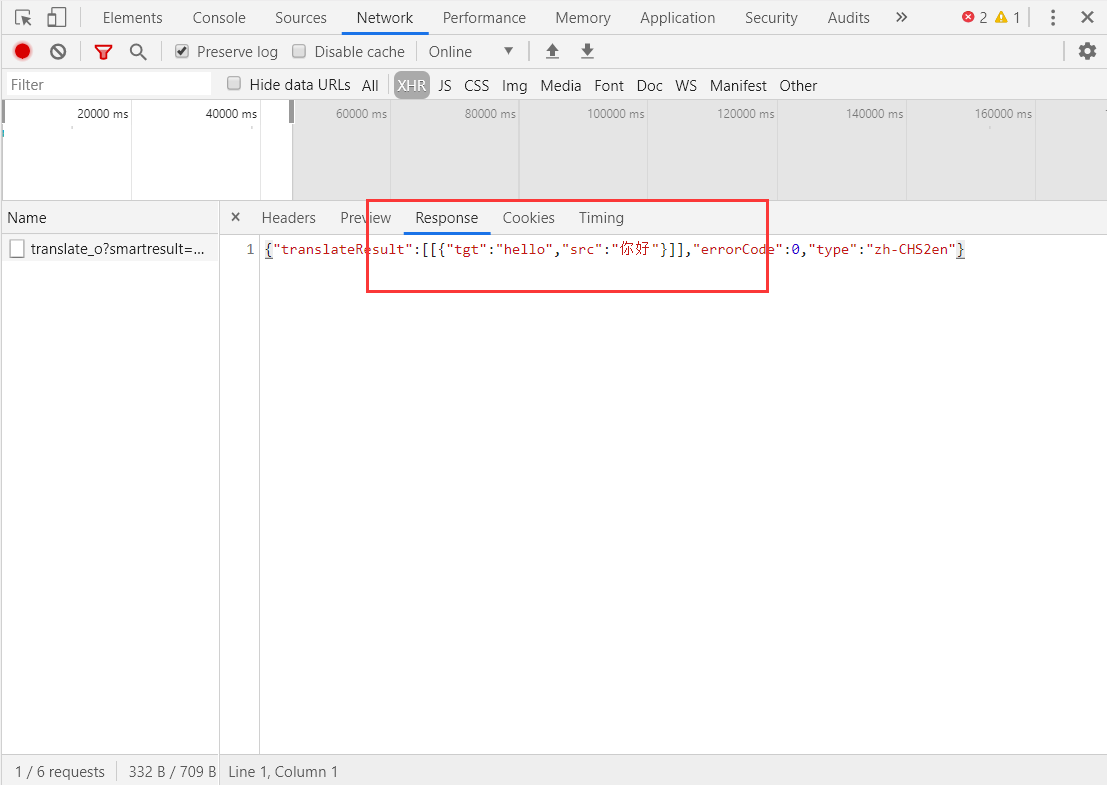
没错,我们可以看出来这返回的json数据就是我们要的数据,包含了需要翻译的语句与翻译后的语句,接下来我们来分析这个请求
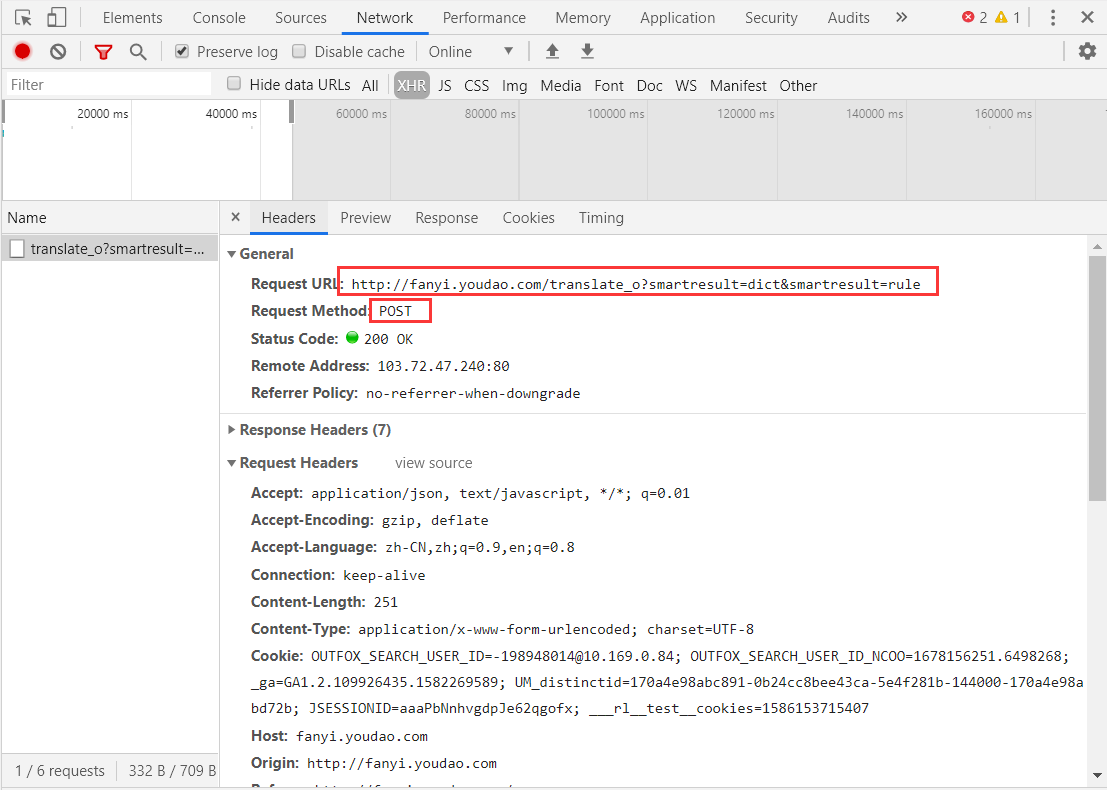
我们可以得到这个请求的网址,同时可以看出来请求是post方式,那么它post了哪些数据呢?我们继续往下看。
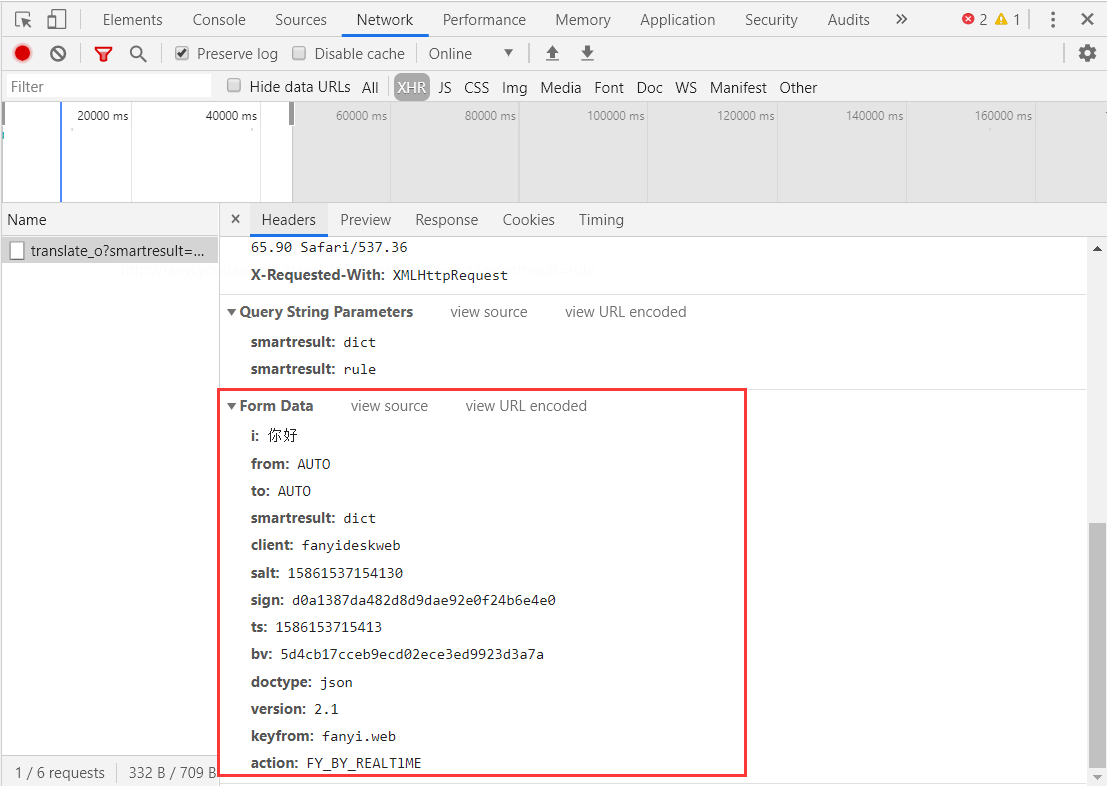
接下来我们先使用下requests来构造下请求,看看能否直接构造成功。
import requests url='http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' headers={ "Accept":"application/json, text/javascript, */*; q=0.01", "Accept-Encoding":"gzip, deflate", "Accept-Language":"zh-CN,zh;q=0.9,en;q=0.8", "Connection":"keep-alive", "Content-Length":"251", "Content-Type":"application/x-www-form-urlencoded; charset=UTF-8", "Cookie":"OUTFOX_SEARCH_USER_ID=-198948014@10.169.0.84; OUTFOX_SEARCH_USER_ID_NCOO=1678156251.6498268; _ga=GA1.2.109926435.1582269589; UM_distinctid=170a4e98abc891-0b24cc8bee43ca-5e4f281b-144000-170a4e98abd72b; JSESSIONID=aaaPbNnhvgdpJe62qgofx; ___rl__test__cookies=1586153715407", "Host":"fanyi.youdao.com", "Origin":"http://fanyi.youdao.com", "Referer":"http://fanyi.youdao.com/", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36", "X-Requested-With":"XMLHttpRequest", } data={ "i":"你好", "from":"AUTO", "to":"AUTO", "smartresult":"dict", "client":"fanyideskweb", "salt":"15861537154130", "sign":"d0a1387da482d8d9dae92e0f24b6e4e0", "ts":"1586153715413", "bv":"5d4cb17cceb9ecd02ece3ed9923d3a7a", "doctype":"json", "version":"2.1", "keyfrom":"fanyi.web", "action":"FY_BY_REALTlME", } res=requests.post(url=url,headers=headers,data=data) print(res.text)
看一下运行结果
{"translateResult":[[{"tgt":"hello","src":"你好"}]],"errorCode":0,"type":"zh-CHS2en"}
看起来没毛病啊,难道真的这么简单吗?其实不然,当我们把我们需要翻译的数据从 你好 变成其他的语句时候就会发现出问题了,网页会返回错误代码。
所以我们需要分析到底什么地方出了问题,因为这是post方式,我们猜测是data数据种某些参数发生了变化,我们再次回到浏览器输入其他语句看一下会有什么变化。
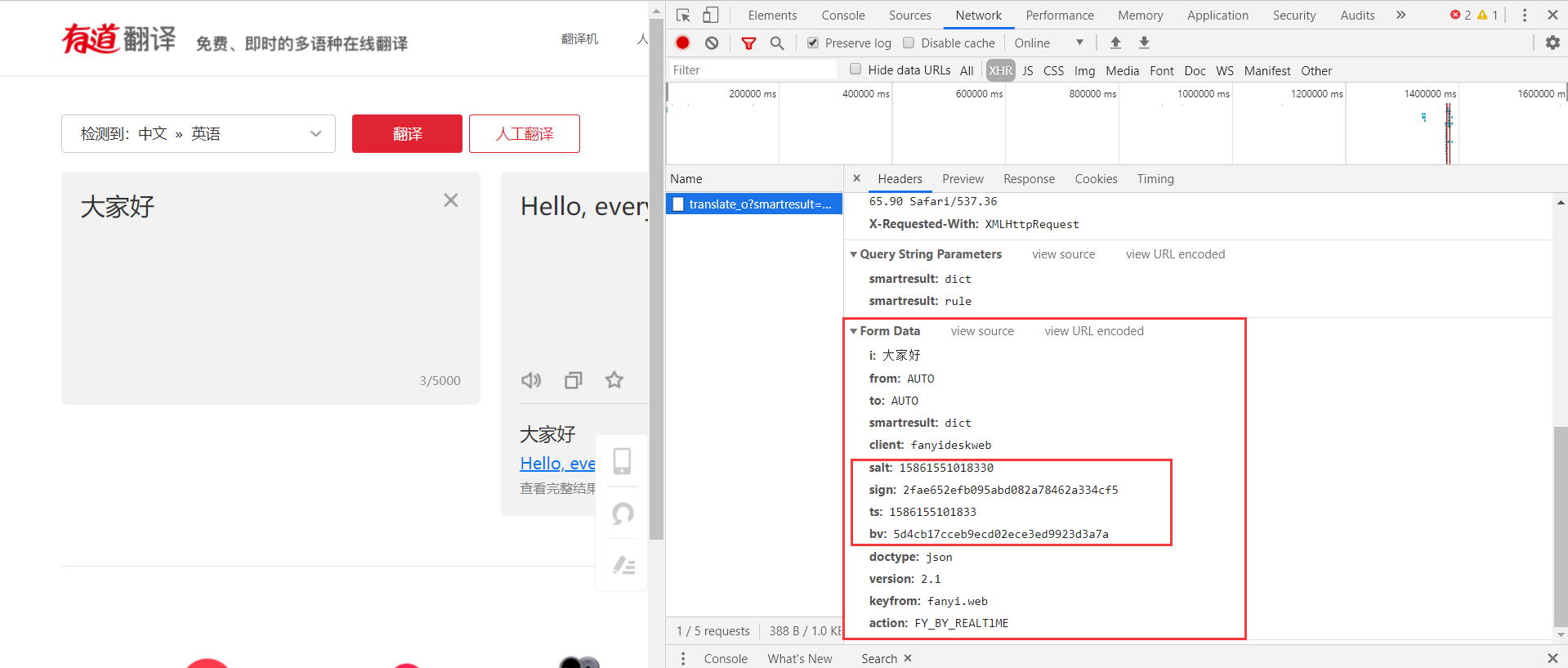
我们通过对比上一次翻译的请求就会发现,post的data数据中有几个参数好像每次都不一样,那么这些参数是如何构造出来的呢?
打开调试台搜索如参数 sign 操作如下。
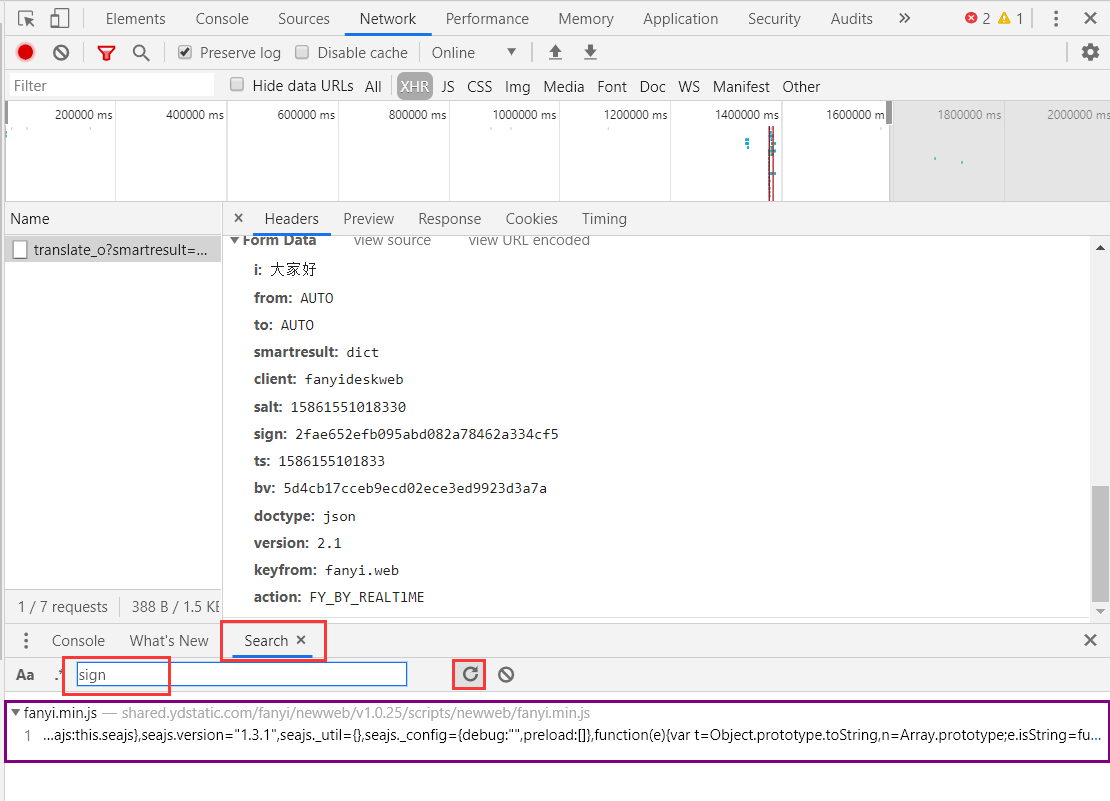
我们发现在某个js文件中有这个参数,猜测此文件就是构造参数的文件,打开这个文件(双击紫色框圈选部分即可)看看代码。
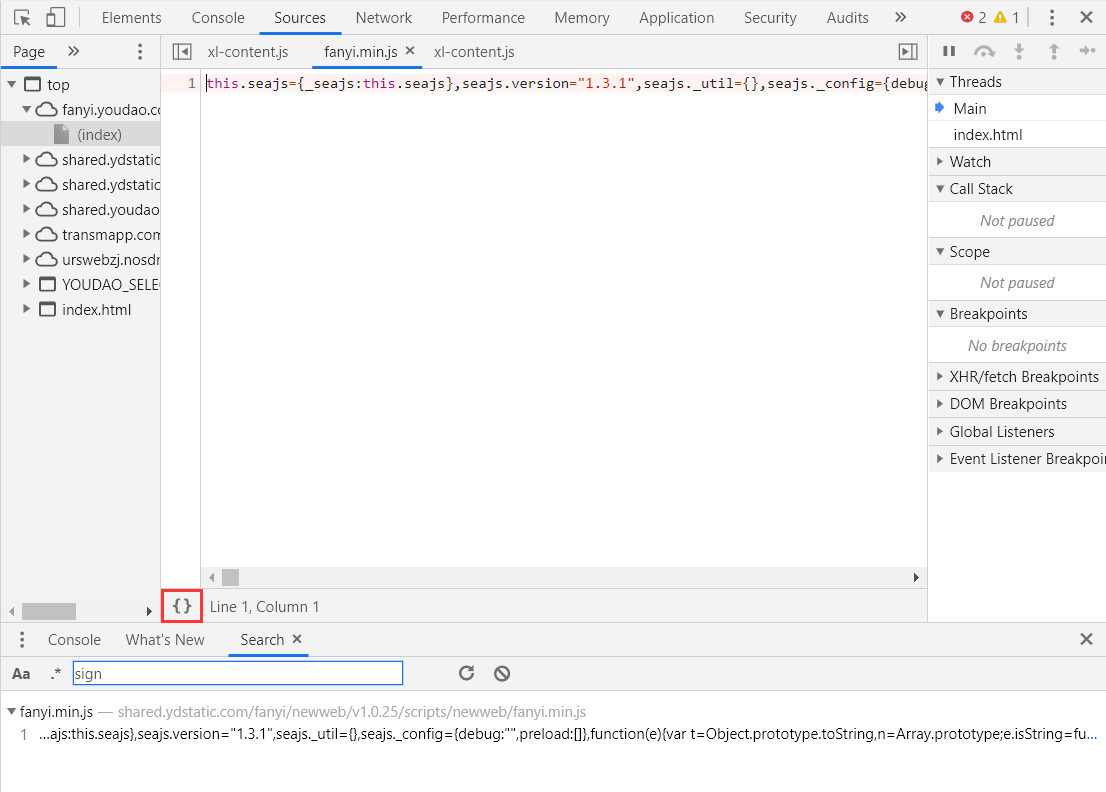
代码只显示了一行好奇怪,没关系,我们点击红色框的按钮即可格式化代码。
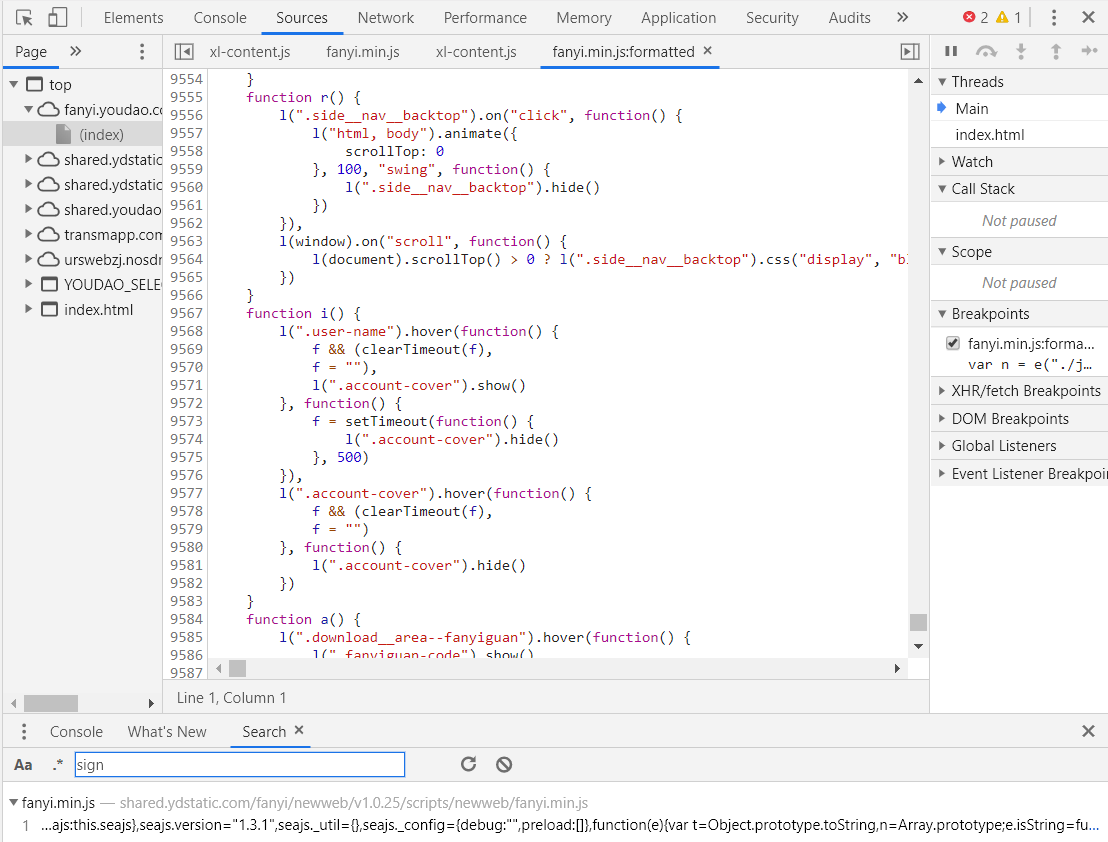
发现这是一个接近一万行的js代码,但是我们只需要构造4个参数呀,在这接近一万行的代码中怎么分析呢?我们继续在代码中搜索参数名称试一试。
鼠标点击一下代码部分,然后键盘按ctrl-f即会出现代码部分的搜索框。搜索结果大概十几个的样子,我们多观察下搜索结果就会找到有用的函数。
如下图中的函数,怎么样,一看竟然出现了 ts、bv、salt、sign 四个参数,这不正是我们要找的构造函数吗?
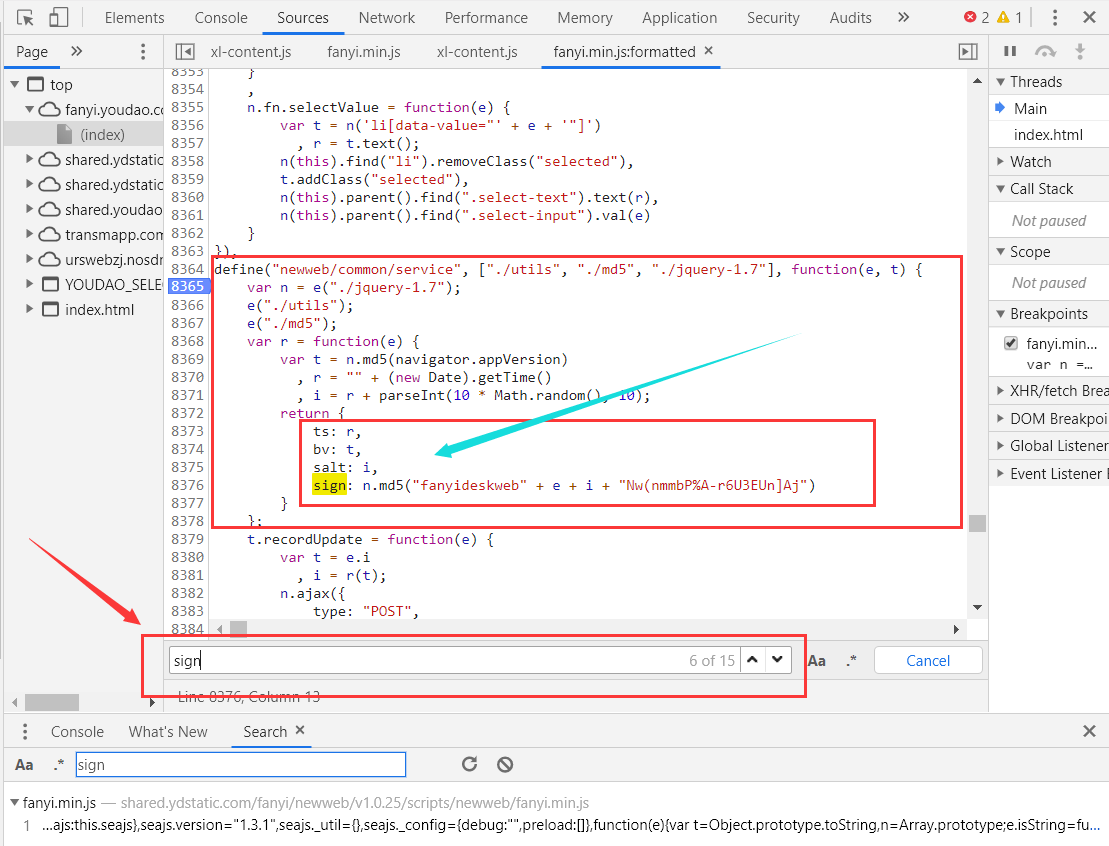
我们把这一段函数拿出来放进notepad++中分析一下
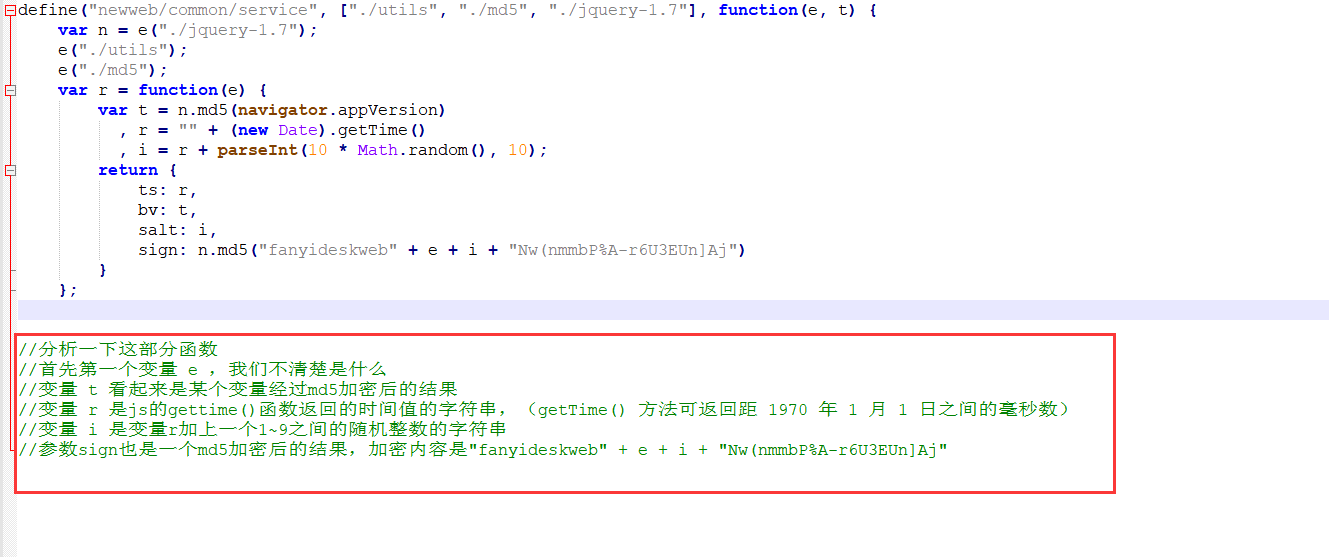
所以目前看起来我们只需要搞清楚变量 e与变量 t 中的 navigator.appVersion 是什么就可以搞定构造函数了。
其实现在已经成功一半了,我们已经找到了参数的构造方法,不过接下来的任务也不简单,我们需要搞清楚两个变量的内容是什么。
我们使用chrome调试台的debug功能来调试一下看看这两个变量是什么,首先在关键代码打上断点(在对应代码前点下鼠标出现蓝色标识即可)。
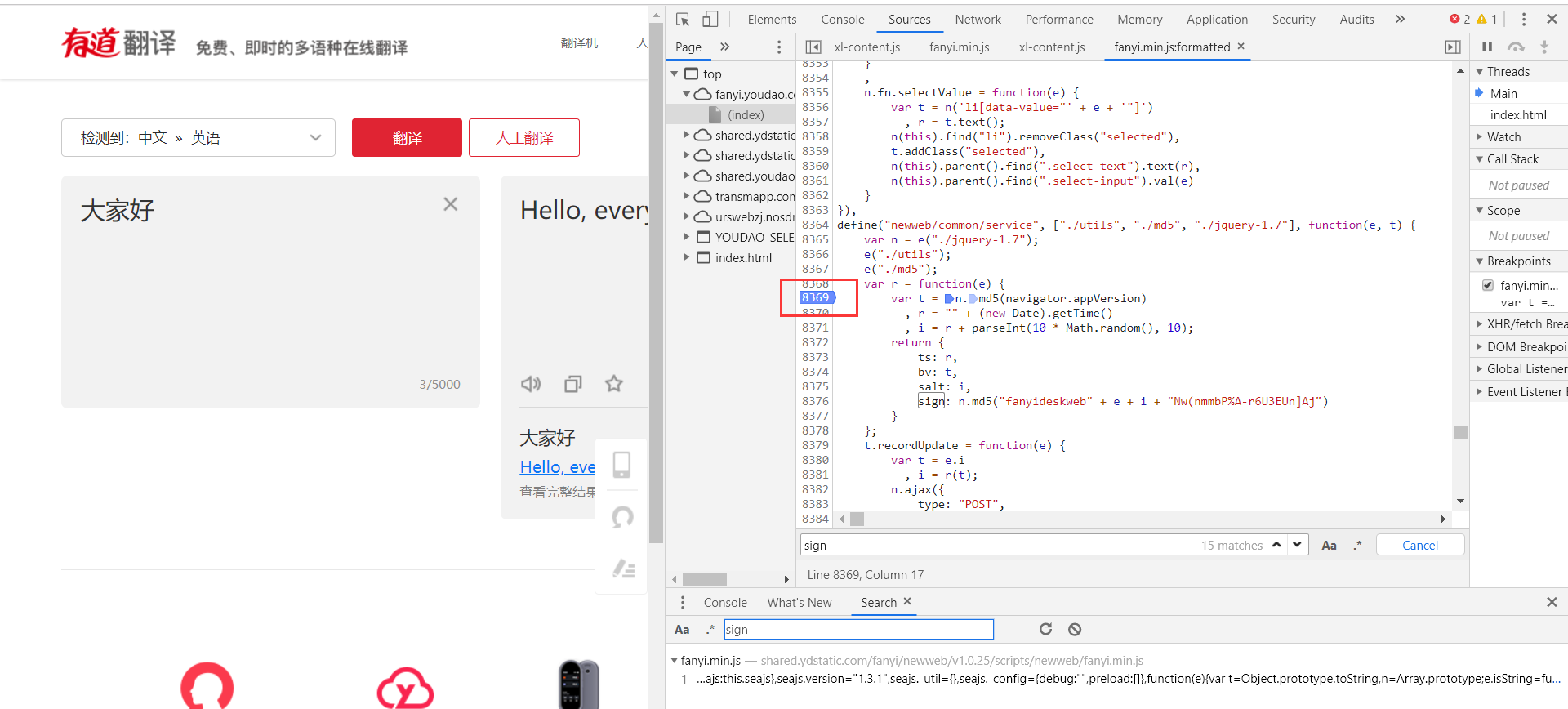
接下来我们再次点击左边页面中的翻译按钮让页面执行一次,看看变量会是什么(注意有可能需要点击debug的下一步让页面继续执行才可以看到参数)。
有两种方法查看变量如下图,一种是将鼠标移动到变量上即可,还有一种是在调试台打上变量名称即可。

可以看出变量e是我们需要翻译的语句,同理我们看下navigator.appVersion ,哦吼原来是user-agent。
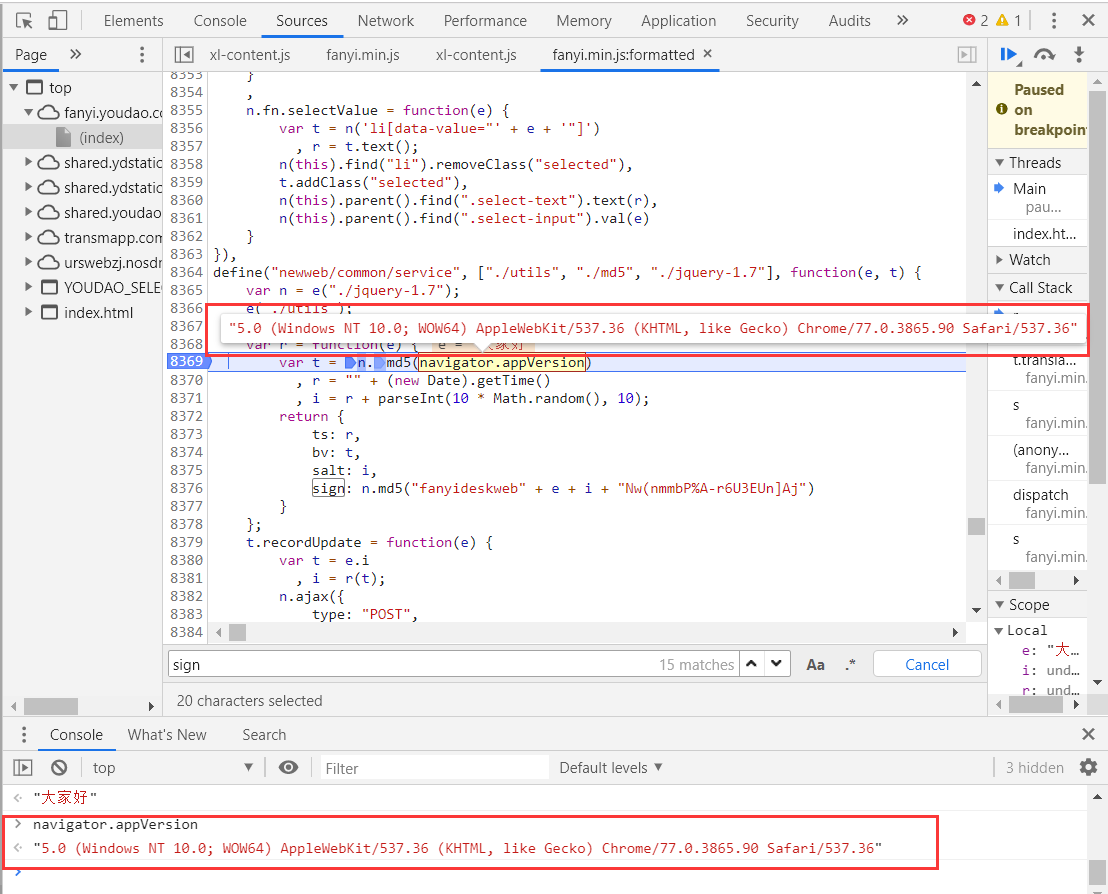
现在我们已经搞清楚了所有的问题,那么接下来就是见证奇迹的时刻,我们将js的函数使用python构造出来,看下是否可以得到我们想要的参数结果。
import hashlib#用于md5加密 import time import random def md5_b(str): hash=hashlib.md5() hash.update(str.encode('utf-8')) return hash.hexdigest() data={} def get_data_params(t_str): user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" e=t_str t=md5_b(user_agent) r=str(int(time.time()*1000))#毫秒所以*1000 i=r+str(random.randint(0,10)) data['ts'] = r data['bv'] = t data['salt'] = i data['sign'] = md5_b("fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj") get_data_params('大家好') print(data)
这就是我们的复刻版构造函数了,我们看下结果是什么。
{'ts': '1586159044056', 'bv': '58ecb303644f080054fa932285a108a5', 'salt': '15861590440560', 'sign': 'dfac0f829d89a3f31ccb25a0eb16fd51'}
嗯,看起来挺像,那么我们接下来把其他不变的参数也添加进去,看看能否构造请求成功,接下来是完整代码。
import requests import hashlib#用于md5加密 import time import random url='http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' headers={ "Accept":"application/json, text/javascript, */*; q=0.01", "Accept-Encoding":"gzip, deflate", "Accept-Language":"zh-CN,zh;q=0.9,en;q=0.8", "Connection":"keep-alive", "Content-Length":"251", "Content-Type":"application/x-www-form-urlencoded; charset=UTF-8", "Cookie":"OUTFOX_SEARCH_USER_ID=-198948014@10.169.0.84; OUTFOX_SEARCH_USER_ID_NCOO=1678156251.6498268; _ga=GA1.2.109926435.1582269589; UM_distinctid=170a4e98abc891-0b24cc8bee43ca-5e4f281b-144000-170a4e98abd72b; JSESSIONID=aaaPbNnhvgdpJe62qgofx; ___rl__test__cookies=1586153715407", "Host":"fanyi.youdao.com", "Origin":"http://fanyi.youdao.com", "Referer":"http://fanyi.youdao.com/", "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36", "X-Requested-With":"XMLHttpRequest", } #data中的from与to参数代表着从什么语言翻译到什么语言,默认是中英互译 data={ "from":"AUTO", "to":"AUTO", "smartresult":"dict", "client":"fanyideskweb", "doctype":"json", "version":"2.1", "keyfrom":"fanyi.web", "action":"FY_BY_REALTlME", } #该函数用于字符串的md5加密 def md5_b(str): hash=hashlib.md5() hash.update(str.encode('utf-8')) return hash.hexdigest() def get_data_params(t_str): user_agent="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" e=t_str t=md5_b(user_agent) r=str(int(time.time()*1000))#毫秒所以*1000 i=r+str(random.randint(0,10)) data['i'] = e data['ts'] = r data['bv'] = t data['salt'] = i data['sign'] = md5_b("fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj") return data res=requests.post(url=url,headers=headers,data=get_data_params('你好啊,你在干什么呀?')) print(res.text)
看下运行结果:
{"translateResult":[[{"tgt":"Hello. What are you doing?","src":"你好啊,你在干什么呀?"}]],"errorCode":0,"type":"zh-CHS2en"}
好了,发现已经可以得到返回的json了,可以自己使用json库继续进行提取了,这样我们就破解了有道翻译的js加密,其他网站也类似这样操作就可以。

