仿牛客网社区开发——第7章 项目进阶,构建安全高效的企业服务(下)
任务执行和调度

分布式环境下的定时任务问题
每个服务器的 Schedule 每隔一段时间做同样的事情,做的任务会重复
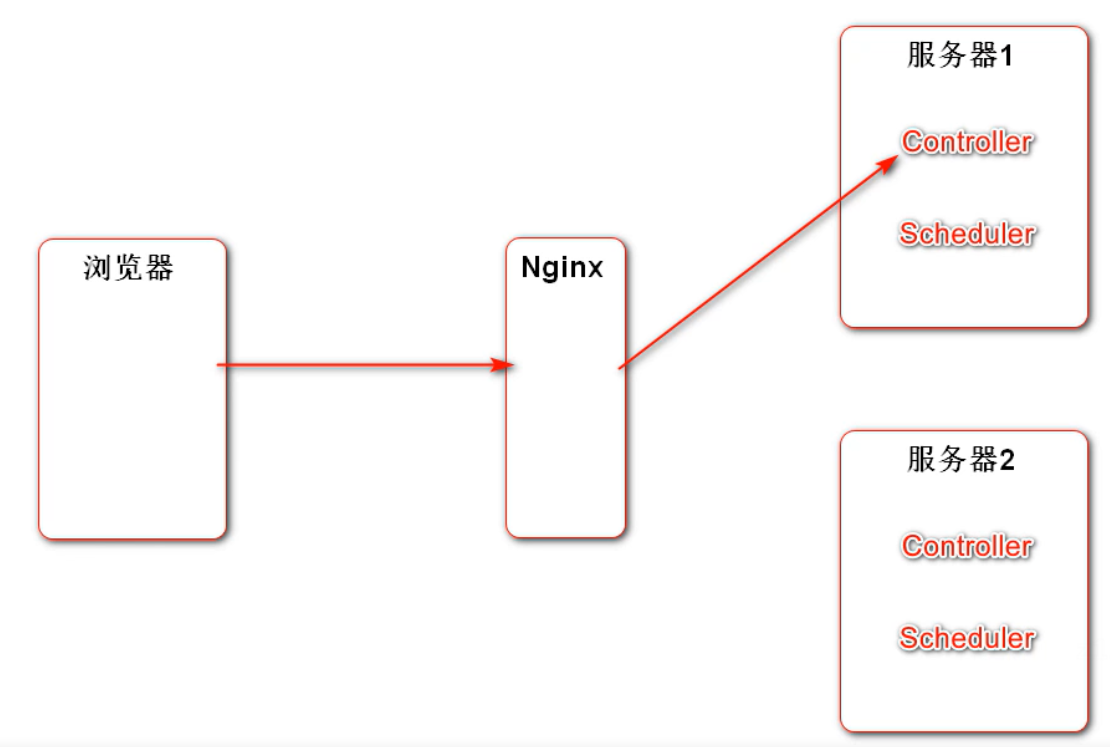
Quartz 定时任务驱动的参数存到数据库里,通过排队、加锁等这样的机制实现共享
JDK 线程池
注意:如果在 main 方法里启动了一个线程,这个线程如果不挂掉,main 方法会等着它执行,不会立刻结束;
而 junit 方法中启动的线程和当前线程和是并发的,如果测试方法后面没有逻辑,就立刻结束,不管启动的线程完没完成。
解决方法就是在测试方法启动之后,让当前线程 sleep 一会。为了方便,把 sleep 方法封装一下:
private void sleep(long m) {
try {
Thread.sleep(m);
} catch (InterruptedException e) {
e.printStackTrace();
}
}普通线程池:ExecutorService
// JDK普通线程池
private ExecutorService executorService = Executors.newFixedThreadPool(5);// 1.JDK普通线程池
@Test
public void testExecutorService() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ExecutorService");
}
};
for (int i = 0; i < 10; i++) {
executorService.submit(task);
}
sleep(10000);
}
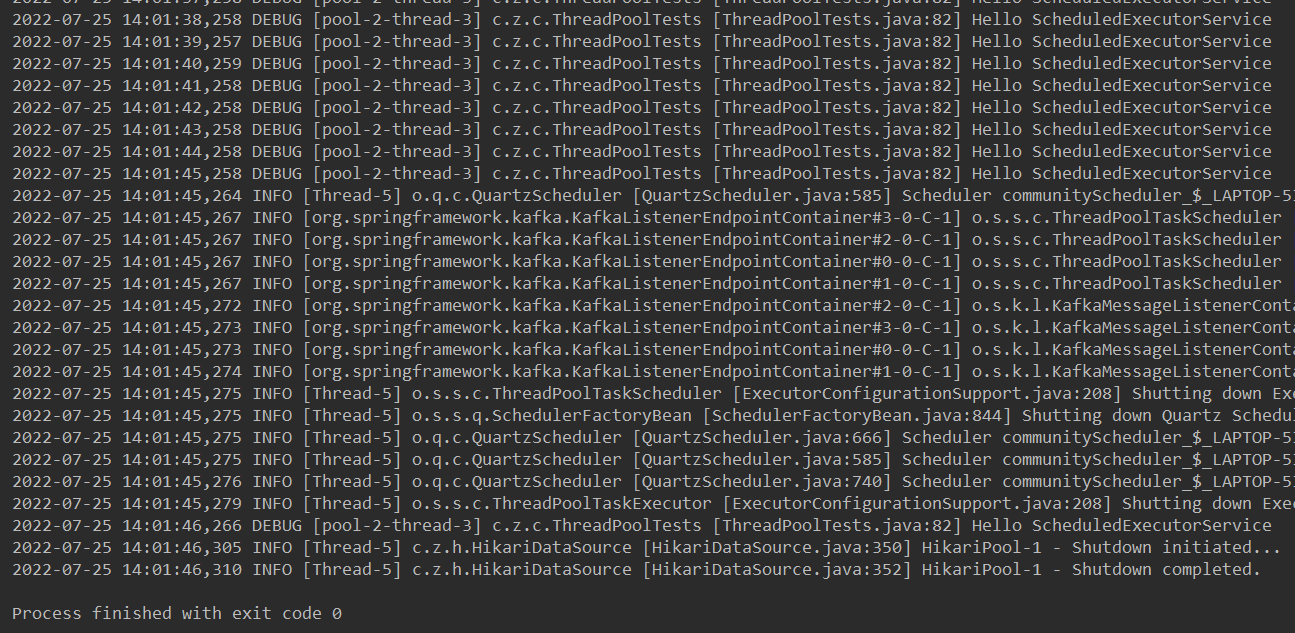
定时任务线程池:ScheduledExecutorService
// JDK可执行定时任务的线程池
private ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);延迟 10 秒执行,每隔 1 秒输出 1 次
// 2.JDK定时任务线程池
@Test
public void testScheduledExecutorService() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ScheduledExecutorService");
}
};
scheduledExecutorService.scheduleAtFixedRate(task, 10000, 1000, TimeUnit.MILLISECONDS);
sleep(30000);
}14:01:15 启动,25 秒开始每隔 1 秒输出一次,45 秒程序结束
Spring 线程池
配置文件 application.properties
- 对于普通线程池,先填充核心数量,然后填充队列,队列满了再填充才会扩充,最大不超过 max-size
- 对于定时任务线程池,因为主要是执行定时任务,线程数量肯定是预先知道的,无需这种扩充的功能
# TaskExecutionProperties
spring.task.execution.pool.core-size=5
spring.task.execution.pool.max-size=15
spring.task.execution.pool.queue-capacity=100
# TaskSchedulingProperties
spring.task.scheduling.pool.size=5配置类 ThreadPoolConfig
- @EnableScheduling:开启定时任务功能
- @EnableAsync:开启异步功能(下面会提到)
@Configuration
@EnableScheduling
@EnableAsync
public class ThreadPoolConfig {
}Spring 普通线程池:ThreadPoolTaskExecutor
Spring 已经初始化好线程池并放入容器里,直接注入即可
// Spring普通线程池
@Autowired
private ThreadPoolTaskExecutor taskExecutor;// 3.Spring普通线程池
@Test
public void testThreadPoolTaskExecutor() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ThreadPoolTaskExecutor");
}
};
for (int i = 0; i < 10; i++) {
taskExecutor.submit(task);
}
sleep(10000);
}效果同 JDK 普通线程池
Spring 定时任务线程池:ThreadPoolTaskScheduler
// Spring可执行定时任务的线程池
@Autowired
private ThreadPoolTaskScheduler taskScheduler;// 4.Spring定时任务线程池
@Test
public void testThreadPoolTaskScheduler() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ThreadPoolTaskScheduler");
}
};
Date startTime = new Date(System.currentTimeMillis() + 10000);
taskScheduler.scheduleAtFixedRate(task, startTime, 1000);
sleep(30000);
}效果同 JDK 定时任务线程池
Spring 普通线程池(简化)
在 AlphaService 中添加 execute1 方法,并加上 @Async 注解,让该方法在多线程环境下被异步的调用(上文提到的要在 ThreadPoolConfig 类中加上 @EnableAsync 才能生效)
// 让该方法在多线程环境下,被异步的调用
@Async
public void execute1() {
logger.debug("execute1");
}// 5.Spring普通线程池(简化)
@Test
public void testThreadPoolTaskExecutorSimple() {
for (int i = 0; i < 10; i++) {
alphaService.execute1();
}
sleep(10000);
}Spring 定时任务线程池(简化)
@Scheduled(initialDelay = 10000, fixedRate = 1000)
public void execute2() {
logger.debug("execute2");
}加上该注解后,程序只要启动起来,就会自动开始执行
// 6.Spring定时任务线程池(简化)
@Test
public void testThreadPoolTaskSchedulerSimple() {
sleep(30000);
}Spring Quartz
(应该不是重点,了解/会用 即可)
pom.xml 导入包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>核心组件
- Scheduler 接口:核心调度工具,所有任务由这一接口调用
- Job:定义任务,重写 execute 方法
- JobDetail 接口:对 Job 的配置:名字、组、以及其它参数
- Trigger 接口:也是对 Job 的配置:什么时候运行,以什么样的频率运行
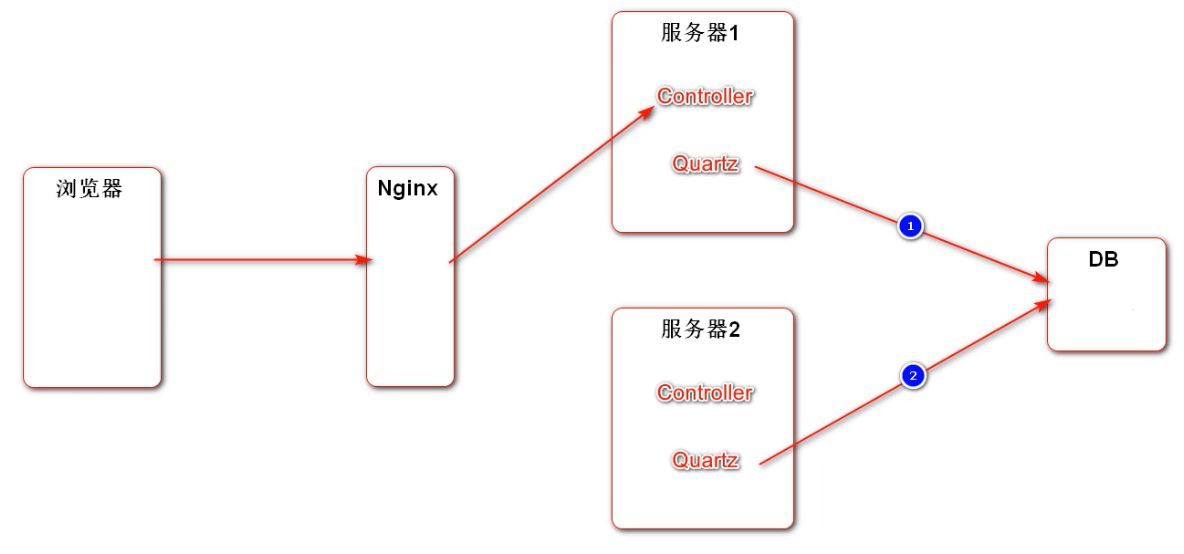
配置好以后,程序启动,Quartz 会读取配置信息,并且立刻存入数据库。以后就通过读取相应的表来执行任务,这时程序中的配置就不再使用,只是在第一次启动服务器的时候会用一下。
导入数据库
- qrtz_job_details:job 详情配置描述表
- qrtz_simple_triggers:trigger 简单的配置内容
- qrtz_triggers:trigger 完整的配置内容
- qrtz_scheduler_state:定时器的状态(Quartz 底层会定期检查是否运行正常)
- qrtz_locks:定时器锁(根据名字来加锁)
编写 AlphaJob
public class AlphaJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println(Thread.currentThread().getName() + ": execute a quartz job.");
}
}编写 QuartzConfig
FactoryBean 可简化 Bean 的实例化过程:
- 通过 FactoryBean 封装 Bean 的实例化过程
- 将 FactoryBean 装配到 Spring 容器里
- 将 FactoryBean 注入给其他的 Bean
- 该 Bean 得到的是 FactoryBean 所管理的对象实例
1. 配置 JobDetail
- 实例化 JobDetailFactoryBean
- 设置 Job 任务的类:.setJobClass
- 设置任务的名字:.setName
- 设置任务属于的组:.setGroup
- 设置任务是否长久保存:.setDurability
- 设置任务是否可恢复:.setRequestsRecovery
2. 配置 Trigger
- 实例化 SimpleTriggerFactoryBean
- 设置 JobDetail:.setJobDetail
- 设置 Trigger 的名字:.setName
- 设置 Trigger 属于的组:.setGroup
- 设置 Trigger 执行的频率:.setRepeatInterval
- 设置 Trigger 底层存储 Job 状态的对象:.setJobDataMap
其中 Trigger 还有另外一种复杂的类型:CronTriggerFactoryBean,它能根据其特殊的表达式来实现复杂的逻辑。
@Configuration
public class QuartzConfig {
// 配置JobDetail
//@Bean
public JobDetailFactoryBean alphaJobDetail() {
JobDetailFactoryBean factoryBean = new JobDetailFactoryBean();
factoryBean.setJobClass(AlphaJob.class);
factoryBean.setName("alphaJob");
factoryBean.setGroup("alphaJobGroup");
factoryBean.setDurability(true);
factoryBean.setRequestsRecovery(true);
return factoryBean;
}
// 配置Trigger(SimpleTriggerFactoryBean, CronTriggerFactoryBean)
//@Bean
public SimpleTriggerFactoryBean alphaTrigger(JobDetail alphaJobDetail) {
SimpleTriggerFactoryBean factoryBean = new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(alphaJobDetail);
factoryBean.setName("alphaTrigger");
factoryBean.setGroup("alphaTriggerGroup");
factoryBean.setRepeatInterval(3000);
factoryBean.setJobDataMap(new JobDataMap());
return factoryBean;
}
}Quartz 底层线程池配置
没做相关配置时,默认将 Job 的相关配置存到了内存(memory)里
# QuartzProperties
spring.quartz.job-store-type=jdbc #存储方式(默认是memory)
spring.quartz.scheduler-name=communityScheduler #调度器名字
spring.quartz.properties.org.quartz.scheduler.instanceId=AUTO #调度器id自动生成
spring.quartz.properties.org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX #存入数据库的类
spring.quartz.properties.org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate #驱动
spring.quartz.properties.org.quartz.jobStore.isClustered=true #采用集群
spring.quartz.properties.org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool #用哪个线程池
spring.quartz.properties.org.quartz.threadPool.threadCount=5 #线程池数量删除 Job:QuartzTests
现在数据已经进表了,只要一启动读到表里的数据,定时任务就会运行(每隔一段时间输出那句话)。
有两种删除方式:手动删除表里的数据 / 写一个测试程序来调 Scheduler 去删除任务(简便、能复用)
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class QuartzTests {
@Autowired
private Scheduler scheduler;
@Test
public void testDeleteJob() {
try {
boolean result = scheduler.deleteJob(new JobKey("alphaJob", "alphaJobGroup"));
System.out.println(result);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}删完后 Job 的数据都没了,但是调度器相关的信息还是有的。
记得把 QuartzConfig 中的 2 个 @Bean 注释掉,防止下次启动时再次运行定时任务。
热帖排行
如果每个评论、点赞操作都去计算帖子分数并存到数据库中,性能会非常底下,所以采用定时任务来实现;
但如果每次定时任务都计算全部的帖子,性能也会底下,所以只去计算这段时间内发生变化的帖子(发布帖子、加精或有人评论、点赞)
统计发生变化的帖子
增加一个 RedisKey
把这段时间内发生变化的帖子放入 set 中(发生过变化都去计算一次分数,不需要重复计算多次,也无需有序)
private static final String PREFIX_POST = "post";
// 帖子分数
public static String getPostScoreKey() {
return PREFIX_POST + SPLIT + "score";
}修改对应的 Controller
发布帖子、加精、增加对帖子的评论以及对帖子点赞,都将该帖子的 id 放入集合中,以便定时任务去获取。
DiscussPostController:
发布帖子
@PostMapping("/add")
@ResponseBody
public String addDiscussPost(String title, String content) {
……
// 触发发帖事件
……
// 计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, post.getId());
// 报错的情况,将来统一处理
……
}加精
// 加精
@PostMapping("/wonderful")
@ResponseBody
public String setWonderful(int id) {
……
// 触发发帖事件
……
// 计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, id);
……
}CommentController:
必须是对帖子的评论才算
@PostMapping("/add/{discussPostId}")
public String addComment(@PathVariable("discussPostId") int discussPostId, Comment comment) {
……
// 触发评论事件
……
if (comment.getEntityType() == ENTITY_TYPE_POST) {
// 触发发帖事件
……
// 计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, discussPostId);
}
……
}LikeController:
必须是对帖子的点赞才算
@PostMapping("/like")
@ResponseBody
public String like(int entityType, int entityId, int entityUserId, int postId) {
……
// 触发点赞事件
……
if (entityType == ENTITY_TYPE_POST) {
// 计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, postId);
}
……
}定时任务
编写 PostScoreRefreshJob
公式如下:
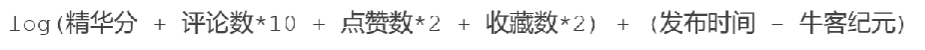
收藏数本项目没有实现该功能,所以忽略不计。
整体流程如下:
- 记日志,养成习惯
- 需要用到的各个功能的 Service 都注入进来
- 声明静态常量牛客纪元并初始化赋值
- 重写 execute 方法
- 获取帖子 id 的集合
- 如果没有任何帖子发生变化,记录日志:任务取消
- 否则开始计算其中每个帖子的分数,在计算前后都记一下日志,表示开始和结束(方便将来看日志分析情况)
- 编写计算帖子分数的方法
- 如果没查到该帖子(有可能管理员中途把该帖子删除),也记一下日志:该帖子不存在
- 是否精华、评论数量、点赞数量,由三者来计算权重
- 帖子分数 = 帖子权重 + 距离天数(注意:权重不能小于 1,否则计算出来帖子权重是负数,这里需要处理一下)
- 更改数据库中帖子的分数(在帖子的 Mapper、xml 和 Service 中增加修改帖子分数的方法),同时也要对 ES 中的帖子作修改
public class PostScoreRefreshJob implements Job, CommunityConstant {
private static final Logger logger = LoggerFactory.getLogger(PostScoreRefreshJob.class);
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private DiscussPostService discussPostService;
@Autowired
private LikeService likeService;
@Autowired
private ElasticsearchService elasticsearchService;
// 牛客纪元
private static final Date epoch;
static {
try {
epoch = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2014-08-01 00:00:00");
} catch (ParseException e) {
throw new RuntimeException("初始化牛客纪元失败!", e);
}
}
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
String redisKey = RedisKeyUtil.getPostScoreKey();
BoundSetOperations operations = redisTemplate.boundSetOps(redisKey);
if (operations.size() == 0) {
logger.info("[任务取消] 没有需要刷新的帖子!");
return;
}
logger.info("[任务开始] 正在刷新帖子分数:" + operations.size());
while (operations.size() > 0) {
this.refresh((Integer) operations.pop());
}
logger.info("[任务结束] 帖子分数刷新完毕!");
}
private void refresh(int postId) {
DiscussPost post = discussPostService.findDiscussPostById(postId);
if (post == null) {
logger.error("该帖子不存在:id = " + postId);
return;
}
// 是否精华
boolean wonderful = post.getStatus() == 1;
// 评论数量
int commentCount = post.getCommentCount();
// 点赞数量
long likeCount = likeService.findEntityLikeCount(ENTITY_TYPE_POST, postId);
// 计算权重
double w = (wonderful ? 75 : 0) + commentCount * 10 + likeCount * 2;
// 分数 = 帖子权重 + 距离天数
double score = Math.log10(Math.max(w, 1))
+ (post.getCreateTime().getTime() - epoch.getTime()) / (1000 * 3600 * 24);
// 更新帖子分数
discussPostService.updateScore(postId, score);
// 同步搜索数据
post.setScore(score);
elasticsearchService.saveDiscussPost(post);
}
}编写 QuartzConfig
和上节的配置类似。修改一下相应的名字和任务执行的间隔
// 刷新帖子分数任务
@Bean
public JobDetailFactoryBean postScoreRefreshJobDetail() {
JobDetailFactoryBean factoryBean = new JobDetailFactoryBean();
factoryBean.setJobClass(PostScoreRefreshJob.class);
factoryBean.setName("postScoreRefreshJob");
factoryBean.setGroup("communityJobGroup");
factoryBean.setDurability(true);
factoryBean.setRequestsRecovery(true);
return factoryBean;
}
@Bean
public SimpleTriggerFactoryBean postScoreRefreshTrigger(JobDetail postScoreRefreshJobDetail) {
SimpleTriggerFactoryBean factoryBean = new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(postScoreRefreshJobDetail);
factoryBean.setName("postScoreRefreshTrigger");
factoryBean.setGroup("communityTriggerGroup");
factoryBean.setRepeatInterval(1000 * 60 * 5);
factoryBean.setJobDataMap(new JobDataMap());
return factoryBean;
}页面展现
复用查询帖子列表的方法
对查询帖子列表的方法增加一个参数:orderMode,0 表示“最新”、1 表示“最热”,仅仅是排序方式不一样
DiscussPostMapper:
List<DiscussPost> selectDiscussPosts(int userId, int offset, int limit, int orderMode);DiscussPostMapper.xml:
查看热帖时,除了置顶的帖子在前,应当按照帖子的分数倒序排序。分数一样时再按照时间倒序排序
<select id="selectDiscussPosts" resultType="com.zwc.community.entity.DiscussPost">
SELECT <include refid="selectFields"/>
FROM discuss_post
WHERE status != 2
<if test="userId != 0">
AND user_id = #{userId}
</if>
<if test="orderMode == 0">
ORDER BY `type` DESC, create_time DESC
</if>
<if test="orderMode == 1">
ORDER BY `type` DESC, score DESC, create_time DESC
</if>
limit #{offset}, #{limit}
</select>DiscussPostService:
public List<DiscussPost> findDiscussPosts(int userId, int offset, int limit, int orderMode) {
return discussPostMapper.selectDiscussPosts(userId, offset, limit, orderMode);
}HomeController:
- 第一次访问主页时,默认路径是不带 orderMode 参数的,要设置 orderMode 的默认值为 0
- 分页的路径需要添加 orderMode 参数,不能让最新和最热的帖子列表页面串起来
- 最后把 orderMode 放入 Model 传给页面
@GetMapping("/index")
public String getIndexPage(Model model, Page page,
@RequestParam(name = "orderMode", defaultValue = "0") int orderMode) {
……
page.setPath("/index?orderMode=" + orderMode);
List<DiscussPost> list = discussPostService.findDiscussPosts(0, page.getOffset(), page.getLimit(), orderMode);
……
……
model.addAttribute("orderMode", orderMode);
return "/index";
}修改 index.html
- 修改超链接的路径
- 根据 orderMode 设置 2 个页签谁被点亮
<!-- 筛选条件 -->
<ul class="nav nav-tabs mb-3">
<li class="nav-item">
<a th:class="|nav-link ${orderMode==0?'active':''}|" th:href="@{/index(orderMode=0)}">最新</a>
</li>
<li class="nav-item">
<a th:class="|nav-link ${orderMode==1?'active':''}|" th:href="@{/index(orderMode=1)}">最热</a>
</li>
</ul>注意点:
- Elasticsearch 一定要启动!!!
- 采用定时任务来实现计算帖子分数的逻辑,并且每次只计算这段时间内发生变化的帖子
- 在各个属于帖子变化的操作的方法(注意有哪些操作属于)中,把当前帖子 id 放入 set 集合中,以便定时任务中去获取并处理
- PostScoreRefreshJob 中的逻辑,尤其是如何计算帖子分数
- 复用查询帖子列表方法时各处修改需要注意,尤其 HomeController 中:orderMode 默认为 0、分页路径带上 orderMode 以及将其放到 Model 里供页面获取
生成长图

一般生成长图有两种方式:客户端 app 将当前界面截图;在服务端通过工具将 HTML 转换为 PDF 或图片。
因为我们的项目没有 app,所以就采用第二种方式。
安装 wkhtmltox
打开 .exe 文件安装,安装完后配置环境变量,然后创建 PDF/图片 的存放路径
命令行方式生成长图

生成的图片大小太大,可以选择质量保留 75%(与原图几乎没区别),文件大小从十几 M 减小到几百 K。

在 Java 中调用命令生成长图
命令的路径要写全了
public class WkTests {
public static void main(String[] args) {
String cmd = "D:/Java/software/wkhtmltopdf/bin/wkhtmltoimage --quality 75 https://www.nowcoder.com D:/Java/data/wk-images/3.png";
try {
Runtime.getRuntime().exec(cmd);
System.out.println("ok.");
} catch (IOException e) {
e.printStackTrace();
}
}
}这里运行的结果是先输出了 ok. 后生成了图片。因为这行代码只是把该命令提交给本地的操作系统,剩下的事就由操作系统去执行。这时 Java 程序不会等操作系统执行完成,所以直接向下执行输出 ok。即两者是并发的、异步的。
编写生成长图的业务
application.properties
配置命令和图片存放目录
# wk
wk.image.command=D:/Java/software/wkhtmltopdf/bin/wkhtmltoimage
wk.image.storage=D:/Java/data/wk-imagesWkConfig
在服务启动时检查目录是否存在。不存在就创建
@Configuration
public class WkConfig {
private static final Logger logger = LoggerFactory.getLogger(WkConfig.class);
@Value("${wk.image.storage}")
private String wkImageStorage;
@PostConstruct
public void init() {
// 创建WK图片目录
File file = new File(wkImageStorage);
if (!file.exists()) {
file.mkdir();
logger.info("创建WK图片目录:" + wkImageStorage);
}
}
}ShareController 的 share 方法
生成图片是耗时操作,需要做成异步的(老师这里没说清楚,前面提到了命令是提交给操作系统异步去执行,为何这里还需要用 Kafka 实现异步)
@Controller
public class ShareController implements CommunityConstant {
private static final Logger logger = LoggerFactory.getLogger(ShareController.class);
@Autowired
private EventProducer eventProducer;
@Value("${community.path.domain}")
private String domain;
@Value("${server.servlet.context-path}")
private String contextPath;
@Value("${wk.image.storage}")
private String wkImageStorage;
@GetMapping("/share")
@ResponseBody
public String share(String htmlUrl) {
// 文件名
String fileName = CommunityUtil.generateUUID();
// 异步生成长图
Event event = new Event()
.setTopic(TOPIC_SHARE)
.setData("htmlUrl", htmlUrl)
.setData("fileName", fileName)
.setData("suffix", ".png");
eventProducer.fireEvent(event);
// 返回访问路径
Map<String, Object> map = new HashMap<>();
map.put("shareUrl", domain + contextPath + "/share/image/" + fileName);
return CommunityUtil.getJSONString(0, null, map);
}
……(见后)
}EventConsumer
要先在常量类中增加一个“分享”的主题
@KafkaListener(topics = {TOPIC_SHARE})
public void handleShareMessage(ConsumerRecord record) {
if (record == null || record.value() == null) {
logger.error("消息的内容为空!");
return;
}
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
if (event == null) {
logger.error("消息格式错误!");
return;
}
Map<String, Object> data = event.getData();
String htmlUrl = (String) data.get("htmlUrl");
String fileName = (String) data.get("fileName");
String suffix = (String) data.get("suffix");
String cmd = wkImageCommand + " --quality 75 "
+ htmlUrl + " " + wkImageStorage + "/" + fileName + suffix;
try {
Runtime.getRuntime().exec(cmd);
logger.info("生成长图成功:" + cmd);
} catch (IOException e) {
logger.error("生成长图失败:" + e.getMessage());
}
}ShareController 的 getShareImage 方法
与获取头像图片的请求方法(/header/{fileName})类似
注意要设置 ContentType,并且获取字节流,getOutputStream,不是 getWriter
@GetMapping("/share/image/{fileName}")
public void getShareImage(@PathVariable("fileName") String fileName, HttpServletResponse response) {
if (StringUtils.isBlank(fileName)) {
throw new IllegalArgumentException("文件名不能为空!");
}
response.setContentType("image/png");
File file = new File(wkImageStorage + "/" + fileName + ".png");
try {
OutputStream os = response.getOutputStream();
FileInputStream fis = new FileInputStream(file);
byte[] buffer = new byte[1024];
int b = 0;
while ((b = fis.read(buffer)) != -1) {
os.write(buffer, 0, b);
}
} catch (IOException e) {
logger.error("获取长图失败:" + e.getMessage());
}
}注意点
- 注意路径的拼接、不要漏斜杠和空格
- Runtime.getRuntime().exec(cmd),提交给操作系统去执行,Java 程序直接往下继续执行。两者是异步的
- 上述 cmd 的命令路径要写全了
- 项目启动时要创建好图片存放路径,wk 不会帮我们创建
- 从配置文件中获取值,@Value("${xxx}),要加 ${}
- 获取生成的长图的方法的处理(setContentType、字节流)
将文件上传至云服务器

引入依赖
<dependency>
<groupId>com.qiniu</groupId>
<artifactId>qiniu-java-sdk</artifactId>
<version>7.2.23</version>
</dependency>配置 application.properties
配置密钥、空间名字和 url
# qiniu
qiniu.key.access=yVjnhzfsaIVWaUnImWbrzj6phyfRBfySCGSxebp8
qiniu.key.secret=yhu1Bx0Nu1rhQhE-ukRwKOAWc84eA2CyRLrMDsbj
qiniu.bucket.header.name=zwc-community-header
qiniu.bucket.header.url=http://rfthef8s3.hd-bkt.clouddn.com
qiniu.bucket.share.name=zwc-community-share
qiniu.bucket.share.url=http://rfthv4q4n.hd-bkt.clouddn.com客户端上传:上传头像
UserController
- 废弃掉原来的 uploadHeader 和 getHeader 方法
- 注入配置文件的几个属性
- 修改 getSettingPage,要给页面传一个凭证
- 增加更新头像路径的方法
这里文件名随机生成,不采用用户的 id。理由有:① 覆盖旧头像,如果将来开发查看历史头像的功能则无法找到以前的头像;② 云服务器都有缓存,直接用原来的名字,可能短时间内头像不会更新。
具体代码见下
@Value("${qiniu.key.access}")
private String accessKey;
@Value("${qiniu.key.secret}")
private String secretKey;
@Value("${qiniu.bucket.header.name}")
private String headerBucketName;
@Value("${qiniu.bucket.header.url}")
private String headerBucketUrl;
@LoginRequired
@GetMapping("/setting")
public String getSettingPage(Model model) {
// 上传文件名称
String fileName = CommunityUtil.generateUUID();
// 设置响应信息
StringMap policy = new StringMap();
policy.put("returnBody", CommunityUtil.getJSONString(0));
// 生成上传凭证
Auth auth = Auth.create(accessKey, secretKey);
String uploadToken = auth.uploadToken(headerBucketName, fileName, 3600, policy);
model.addAttribute("uploadToken", uploadToken);
model.addAttribute("fileName", fileName);
return "/site/setting";
}
// 更新头像路径
@PostMapping("/header/url")
@ResponseBody
public String updateHeaderUrl(String fileName) {
if (StringUtils.isBlank(fileName)) {
return CommunityUtil.getJSONString(1, "文件名不能为空!");
}
String url = headerBucketUrl + "/" + fileName;
userService.updateHeader(hostHolder.getUser().getId(), url);
return CommunityUtil.getJSONString(0);
}setting.html
- 表单采用异步方式提交
- hidden 标签带上凭证和文件名
- 文件的标签的 name 要改成 "file"
- 文件末尾添加 <script th:src="@{/js/setting.js}"></script>
<form class="mt-5" id="uploadForm">
<div class="form-group row mt-4">
<label for="head-image" class="col-sm-2 col-form-label text-right">选择头像:</label>
<div class="col-sm-10">
<div class="custom-file">
<input type="hidden" name="token" th:value="${uploadToken}">
<input type="hidden" name="key" th:value="${fileName}">
<input type="file" class="custom-file-input" name="file" id="head-image" lang="es" required="">
<label class="custom-file-label" for="head-image" data-browse="文件">选择一张图片</label>
<div class="invalid-feedback">
图片错误
</div>
</div>
</div>
</div>
<div class="form-group row mt-4">
<div class="col-sm-2"></div>
<div class="col-sm-10 text-center">
<button type="submit" class="btn btn-info text-white form-control">立即上传</button>
</div>
</div>
</form>setting.js
- $("#uploadForm").submit(upload); 的意思是:当点击提交按钮,触发表单的提交事件时,这个事件由这个函数(upload)来定义
- processData: false 不要把表单的内容转为字符串
- contentType: false 不让jQuery设置上传的类型,浏览器会自动进行设置
- new FormData($("#uploadForm")[0]):封装表单数据
- 成功后更新头像访问路径
$(function () {
$("#uploadForm").submit(upload);
});
function upload() {
$.ajax({
url: "http://upload.qiniup.com",
method: "post",
processData: false,
contentType: false,
data: new FormData($("#uploadForm")[0]),
success: function (data) {
if (data && data.code == 0) {
// 更新头像访问路径
$.post(
CONTEXT_PATH + "/user/header/url",
{"fileName":$("input[name='key']").val()},
function (data) {
data = $.parseJSON(data);
if (data.code == 0) {
window.location.reload();
} else {
alert(data.msg);
}
}
);
} else {
alert("上传失败!");
}
}
});
return false;
}服务端直传:上传分享图片
ShareController
修改分享图片的访问路径
@GetMapping("/share")
@ResponseBody
public String share(String htmlUrl) {
// 文件名
String fileName = CommunityUtil.generateUUID();
// 异步生成长图
Event event = new Event()
.setTopic(TOPIC_SHARE)
.setData("htmlUrl", htmlUrl)
.setData("fileName", fileName)
.setData("suffix", ".png");
eventProducer.fireEvent(event);
// 返回访问路径
Map<String, Object> map = new HashMap<>();
// map.put("shareUrl", domain + contextPath + "/share/image/" + fileName);
map.put("shareUrl", shareBucketUrl + "/" + fileName);
return CommunityUtil.getJSONString(0, null, map);
}EventConsumer
- 采用定时任务来不断尝试上传至云服务器。因为上节提到,exec 方法将任务交给操作系统去执行,Java 代码直接继续往下执行。如果用 sleep 来等的话,程序阻塞在这边,性能会很低。所以采用定时任务来实现。这里也不需要考虑分布式部署的问题,因为这个逻辑并不是每个服务器都去执行的,请求只会被其中一台服务器抢到去处理
- 执行时间过长或上传次数过多,都会终止任务
- 终止任务,使用传进来的 future 调用 cancel(true)
- 这里的机房设置,注意华东是 zone0
- 开始第几次上传、第几次成功与失败都需要记日志
- 上传成功也需要终止任务
@Value("${qiniu.key.access}")
private String accessKey;
@Value("${qiniu.key.secret}")
private String secretKey;
@Value("${qiniu.bucket.share.name}")
private String shareBucketName;
@Autowired
private ThreadPoolTaskScheduler taskScheduler;
@KafkaListener(topics = {TOPIC_SHARE})
public void handleShareMessage(ConsumerRecord record) {
if (record == null || record.value() == null) {
logger.error("消息的内容为空!");
return;
}
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
if (event == null) {
logger.error("消息格式错误!");
return;
}
Map<String, Object> data = event.getData();
String htmlUrl = (String) data.get("htmlUrl");
String fileName = (String) data.get("fileName");
String suffix = (String) data.get("suffix");
String cmd = wkImageCommand + " --quality 75 "
+ htmlUrl + " " + wkImageStorage + "/" + fileName + suffix;
try {
Runtime.getRuntime().exec(cmd);
logger.info("生成长图成功:" + cmd);
} catch (IOException e) {
logger.error("生成长图失败:" + e.getMessage());
}
// 启用定时器,监视该图片,一旦生成了,则上传至七牛云
UploadTask task = new UploadTask(fileName, suffix);
Future future = taskScheduler.scheduleAtFixedRate(task, 500);
task.setFuture(future);
}
class UploadTask implements Runnable {
// 文件名称
private String fileName;
// 文件后缀
private String suffix;
// 启动任务的返回值
private Future future;
// 开始时间
private long startTime;
// 上传次数
private int updateTimes;
public UploadTask(String fileName, String suffix) {
this.fileName = fileName;
this.suffix = suffix;
this.startTime = System.currentTimeMillis();
}
public void setFuture(Future future) {
this.future = future;
}
@Override
public void run() {
// 生成失败
if (System.currentTimeMillis() - startTime > 30000) {
logger.error("执行时间过长,终止任务:" + fileName);
future.cancel(true);
return;
}
// 上传失败
if (updateTimes >= 3) {
logger.error("上传次数过多,终止任务:" + fileName);
future.cancel(true);
return;
}
String path = wkImageStorage + "/" + fileName + suffix;
File file = new File(path);
if (file.exists()) {
logger.info(String.format("开始第%d次上传[%s].", ++updateTimes, fileName));
// 设置响应信息
StringMap policy = new StringMap();
policy.put("returnBody", CommunityUtil.getJSONString(0));
// 生成上传凭证
Auth auth = Auth.create(accessKey, secretKey);
String uploadToken = auth.uploadToken(shareBucketName, fileName, 3600, policy);
// 指定上传机房
UploadManager manager = new UploadManager(new Configuration(Zone.zone0()));
try {
// 开始上传图片
Response response = manager.put(
path, fileName, uploadToken, null, "image/" + suffix.substring(1), false);
// 处理响应结果
JSONObject json = JSONObject.parseObject(response.bodyString());
if (json == null || json.get("code") == null || !json.get("code").toString().equals("0")) {
logger.info(String.format("第%d次上传失败[%s].", updateTimes, fileName));
} else {
logger.info(String.format("第%d次上传成功[%s].", updateTimes, fileName));
future.cancel(true);
}
} catch (QiniuException e) {
logger.info(String.format("第%d次上传失败[%s].", updateTimes, fileName));
}
} else {
logger.info("等待图片生成[" + fileName + "].");
}
}
}注意点
- 理清客户端上传与服务器上传的概念、区别
- 密钥和空间名与 url 要配置好
- 客户端上传时,要给页面传一个凭证,凭凭证才能成功上传
- setting.html 结尾记得加上 setting.js,要用 js 异步提交表单
- js 中 upload 函数的逻辑
- 服务器上传的具体逻辑(华东zone0 or 其它服务器,不要配错了)
- 服务器上传成功后也需要终止任务
优化网站的性能

介绍
- 本地缓存性能最好
- 分布式缓存比本地缓存性能低一点,主要是因为网络开销
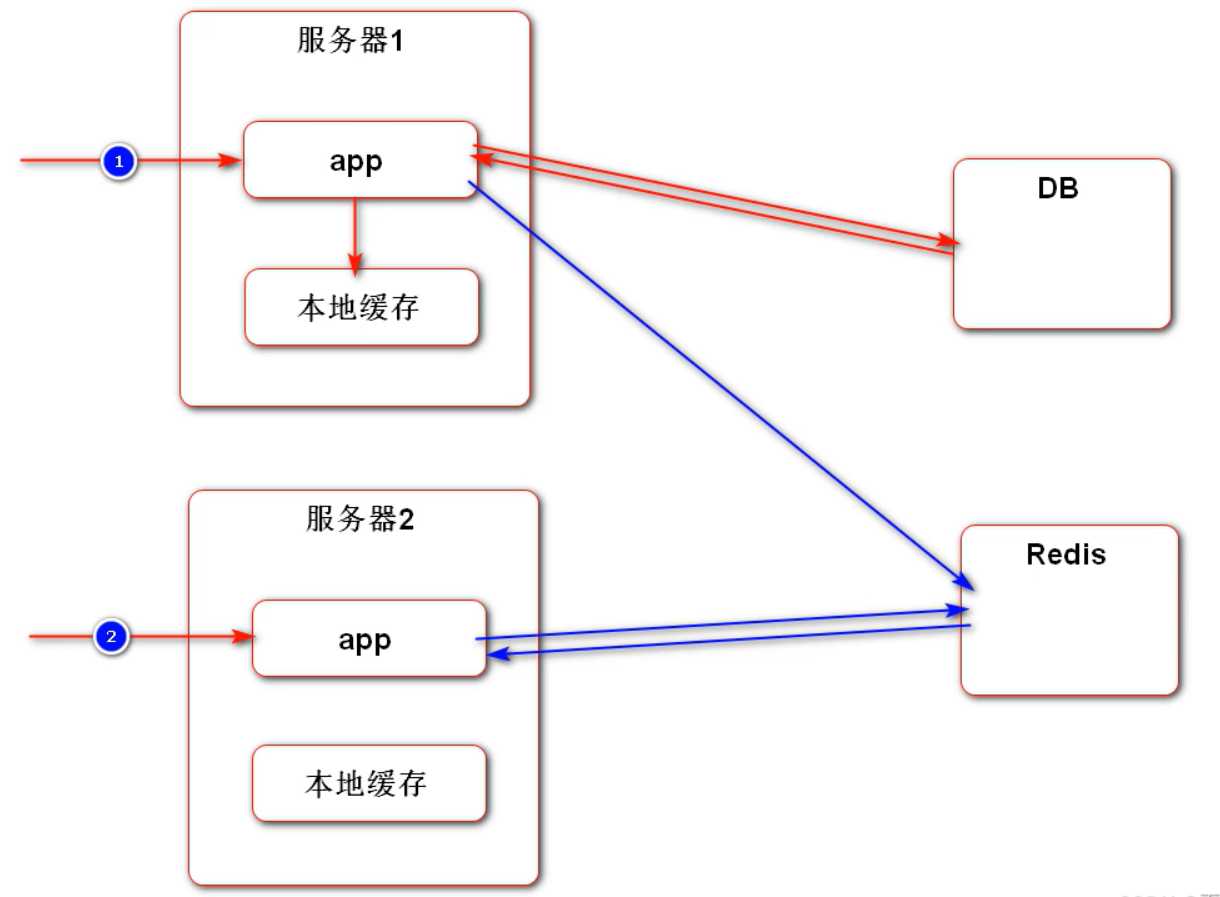
- 使用本地缓存,如果存的是用户信息相关数据,先访问了某一台服务器并存入,然后访问另一台服务器。这台服务器缓存中没有用户相关数据,就无法登录。而如果是热门帖子等信息,使用本地缓存没事,用户和数据本身不是有强关联可以本地缓存
- 使用 Redis 进行缓存则没有上述情况。Redis 可以跨服务器,如下图:
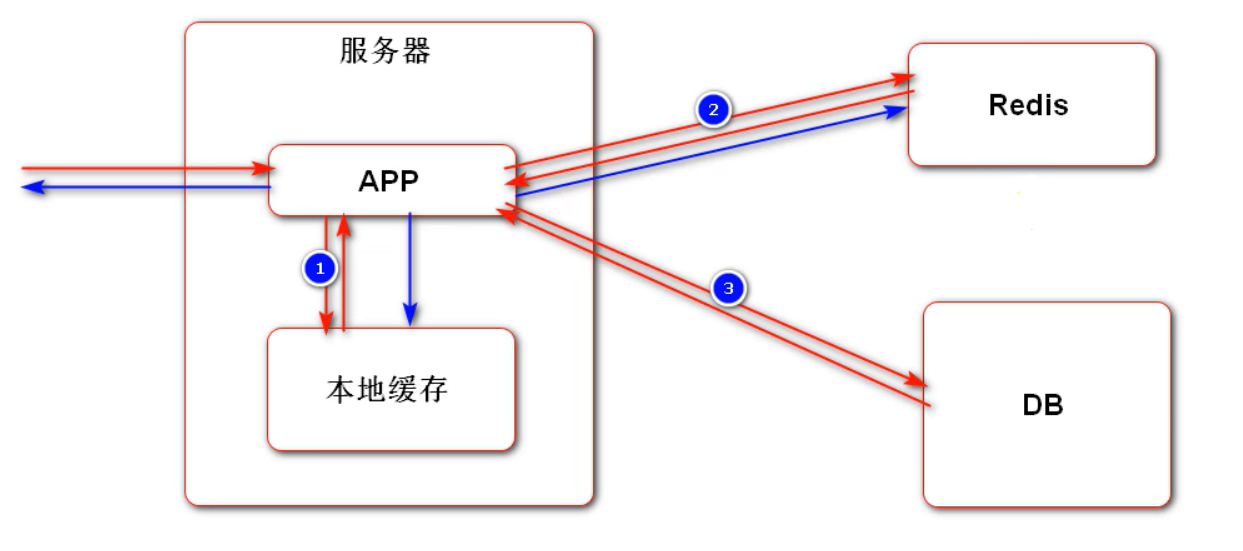
多级缓存的示意图如下:
优化热门帖子列表
引入依赖
这里单独引入 caffeine,不用 Spring 整合,否则所有缓存都由一个缓存管理器管理,不合适,改成多个缓存管理器又比较麻烦。
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.7.0</version>
</dependency>添加配置
- max-size:缓存空间缓存数量
- expire-seconds:过期时间。不采用数据变化淘汰,因为缓存的是一整页,有一个帖子变化就全部淘汰不是很合适
# caffeine
caffeine.posts.max-size=15
caffeine.posts.expire-seconds=180修改 DiscussPostService
- 声明日志、注入参数
- LoadingCache:同步缓存,AsyncLoadingCache:异步缓存(这里用同步,等待取好值再返回)
- 声明帖子列表缓存和帖子总数缓存
- 初始化缓存
- .newBuilder:初始化
- .maximumSize:最大缓存数
- .expireAfterWrite:过期时间
- new CacheLoader 接口的匿名实现
- load 方法是当缓存中没有时调用的查询方法(这里老师也在评论区里说了:当使用 Caffeine 的 API 构建缓存时,在 load 方法内所返回的数据,会被自动装载进去。所以不需要在查到数据后手动添加)
- 可以加上二级缓存,先访问 Redis,如果 Redis 没有再访问数据库
- load 方法是当缓存中没有时调用的查询方法(这里老师也在评论区里说了:当使用 Caffeine 的 API 构建缓存时,在 load 方法内所返回的数据,会被自动装载进去。所以不需要在查到数据后手动添加)
- .newBuilder:初始化
- 修改方法 findDiscussPosts,如果是首页访问(userId == 0,即非特定用户的帖子列表)且按热度排行就调取 caffeine 缓存
- 修改方法 findDiscussPostRows,如果首页访问就调取 caffeine 缓存
@Value("${caffeine.posts.max-size}")
private int maxSize;
@Value("${caffeine.posts.expire-seconds}")
private int expireSeconds;
// Caffeine核心接口:Cache, LoadingCache, AsyncLoadingCache
// 帖子列表缓存
private LoadingCache<String, List<DiscussPost>> postListCache;
// 帖子总数缓存
private LoadingCache<Integer, Integer> postRowsCache;
@PostConstruct
public void init() {
// 初始化帖子列表缓存
postListCache = Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build(new CacheLoader<String, List<DiscussPost>>() {
@Override
public List<DiscussPost> load(@NonNull String key) throws Exception {
if (key == null || key.length() == 0)
throw new IllegalArgumentException("参数错误!");
String[] params = key.split(":");
if (params == null || params.length != 2)
throw new IllegalArgumentException("参数错误!");
int offset = Integer.valueOf(params[0]);
int limit = Integer.valueOf(params[1]);
// 二级缓存:Redis -> mysql
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(0, offset, limit, 1);
}
});
// 初始化帖子总数缓存
postRowsCache = Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build(new CacheLoader<Integer, Integer>() {
@Override
public Integer load(@NonNull Integer key) throws Exception {
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPostRows(key);
}
});
}
public List<DiscussPost> findDiscussPosts(int userId, int offset, int limit, int orderMode) {
if (userId == 0 && orderMode == 1) {
return postListCache.get(offset + ":" + limit);
}
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(userId, offset, limit, orderMode);
}
public int findDiscussPostRows(int userId) {
if (userId == 0) {
return postRowsCache.get(userId);
}
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPostRows(userId);
}JMeter 压力测试
放入 30 万条测试数据
数据量过小则压力测试效果不明显
@Test
public void initDataForTest() {
for (int i = 0; i < 300000; i++) {
DiscussPost post = new DiscussPost();
post.setUserId(111);
post.setTitle("互联网求职暖春计划");
post.setContent("今年的就业形势,确实不容乐观。过了个年,仿佛跳水一般,整个讨论区哀鸿遍野!19届真的没人要了吗?!18届被优化真的没有出路了吗?!大家的“哀嚎”与“悲惨遭遇”牵动了每日潜伏于讨论区的牛客小哥哥小姐姐们的心,于是牛客决定:是时候为大家做点什么了!为了帮助大家度过“寒冬”,牛客网特别联合60+家企业,开启互联网求职暖春计划,面向18届&19届,拯救0 offer!");
post.setCreateTime(new Date());
post.setScore(Math.random() * 2000);
postService.addDiscussPost(post);
}
}测试前最好再注释掉 ServiceLogAspect,以防每次访问都打印日志影响测试
JMeter 相关设置
为方便阅读可首先将语言设置成中文。
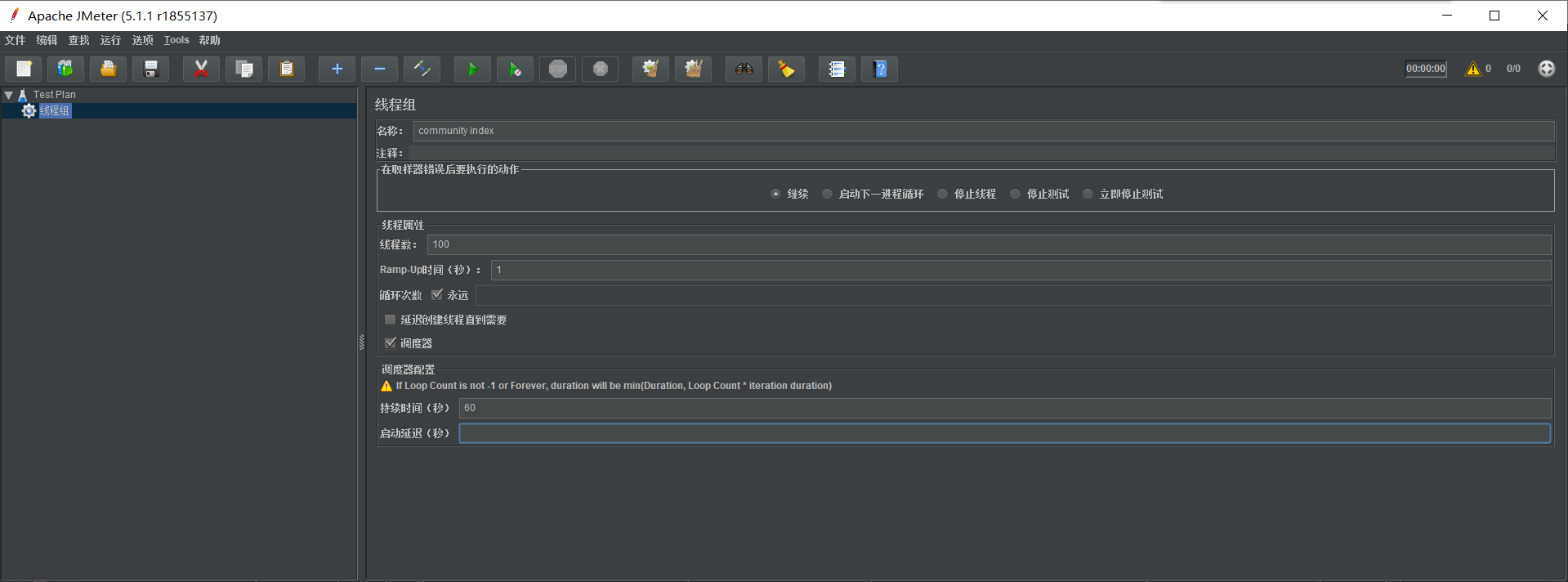
设置线程组名称、线程数量、循环次数与持续时间
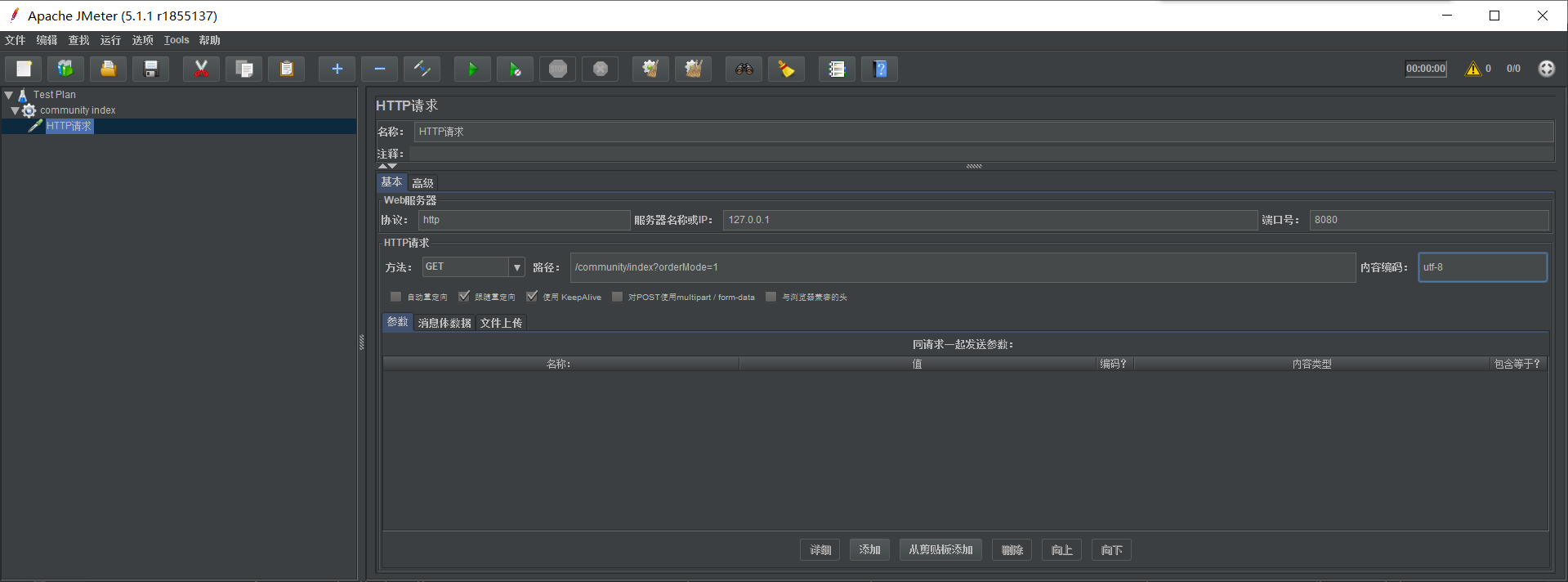
设置协议、服务器 IP、端口号、请求方法、路径以及内容编码
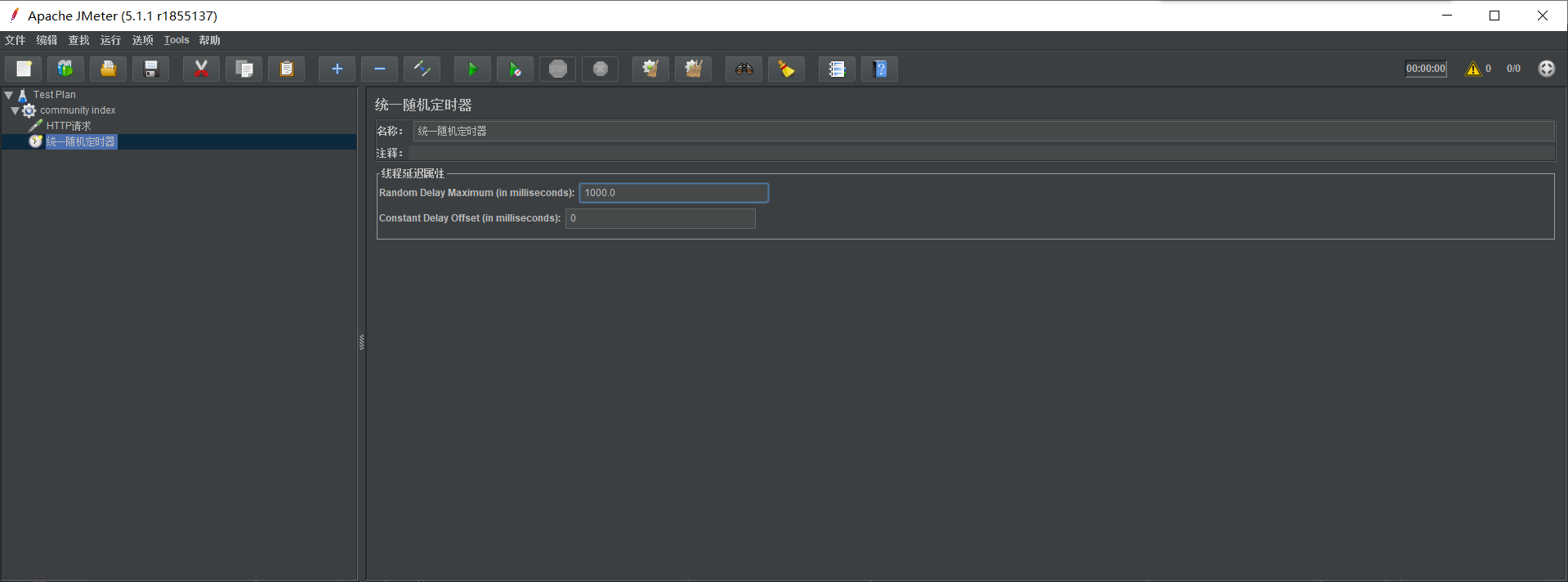
设置随机定时器,随机 0 ~ 1000 毫秒
最后创建聚合报告,着重看吞吐量
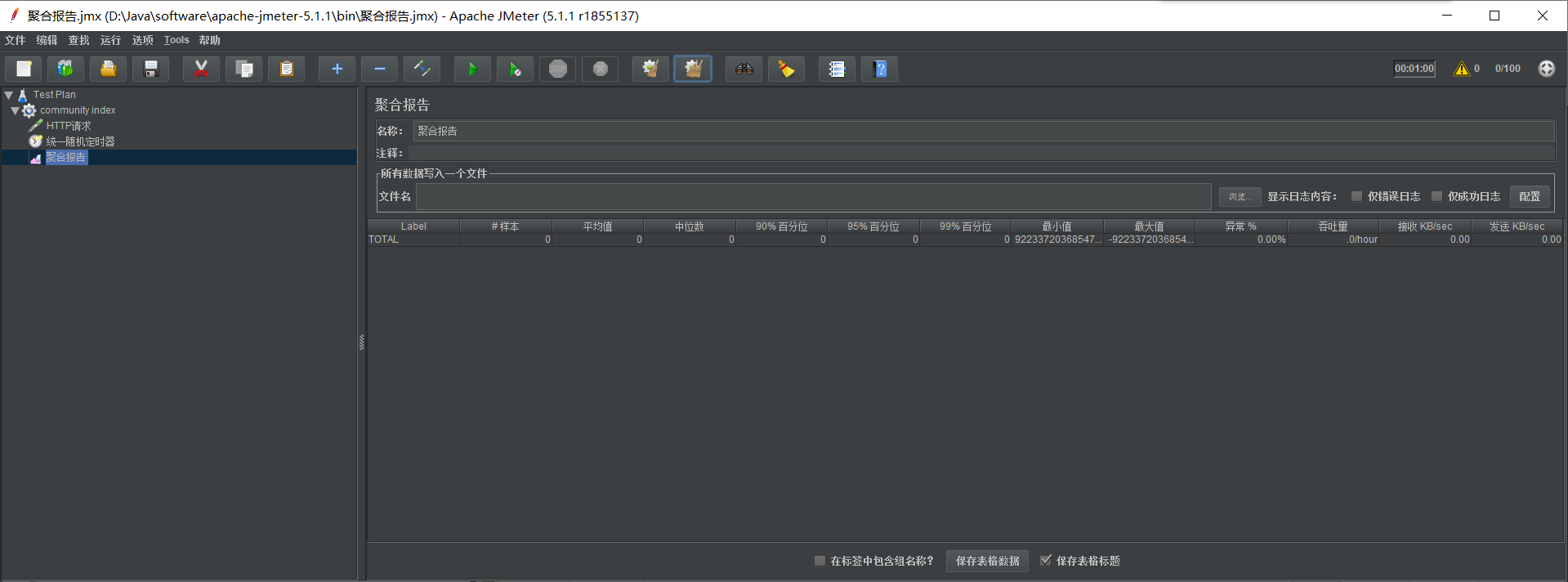
进行测试
- 首先不用 caffeine 缓存,我测试下来的结果是吞吐量只有 1.5/sec
- 用上 caffeine 缓存后,再进行测试(注意要清除前一次的记录,否则再测试就在这基础上累加了),结果有 170/sec 左右
注意点
- 本地缓存、分布式缓存和多级缓存
- 注意何时需要上缓存
- load 方法中可以尝试加一下二级缓存 Redis
- 学会 JMeter 的使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号