仿牛客网社区开发——第6章 Elasticsearch,分布式搜索引擎
Elasticsearch 入门
Elasticsearch 简介
- 一个分布式的、Restful 风格的搜索引擎
- 支持对各种类型的数据的检索
- 搜索速度快,可以提供实时的搜索服务
- 便于水平扩展,每秒可以处理 PB 级海量数据
Elasticsearch 术语
Elasticsearch 也能存储数据,可以看成是一个特殊的数据库
- 索引:相当于数据库中的库,6.0 版本后相当于表
- 类型:一开始相当于数据库的表,6.0 版本之后逐渐被弃用
- 文档:存储在 Elasticsearch 中的一个 JSON 格式的字符串,它就像在关系数据库中表的一行
- 字段:相当于关系数据库中表的列,每个字段都对应一个字段类型
- 集群:集群由一个或多个节点组成,对外提供服务
- 节点:节点是组成集群的基本服务单元,集群中的每个运行中的服务器都可称之为节点
- 分片:当索引的数据量太大时,受限于单个节点的内存、磁盘处理能力等,节点无法足够快地响应客户端的请求,此时需要将一个索引上的数据进行水平拆分。拆分出来的每个数据部分称之为一个分片
- 副本:对分片的备份,一个分片可以包含多个副本
下载安装 Elasticsearch
官网地址:https://www.elastic.co/cn/
- 下载前要注意版本和当前 SpringBoot 中父 Pom 中声明的版本(经过测试没问题的、兼容的版本)是否一致,Elasticsearch 在 6-7 版本有较大变化
- 配置集群的名字、存放数据的位置、存放日志的路径
cluster.name: nowcoder
path.data: D:\Java\Java\ElasticSearch\data
path.logs: D:\Java\Java\ElasticSearch\logs- 配置环境变量,将其 bin 目录加到系统变量的 Path 下
安装中文分词工具
- 在 Github 上搜索 Elasticsearch ik,注意要与 Elasticsearch 版本相对应
- 安装路径固定解压到 Elasticsearch 安装目录的 plugins 下的 ik 目录
- 可以在 IKAnalyzer.cfg.xml 中配置自己的扩展字典(或扩展停止词字典,一般不需要)

安装 Postman (方便测试,非必须)
以客户端的形式对 Elasticsearch 服务器进行操作(非必须,也可以使用命令行,但是更加麻烦)
常用命令(使用命令行)
启动服务器,执行 bat 命令
Windows 用 .bat 的,Linux / Unix 用不带 .bat 的
查看 ES 集群的健康状态
curl -X GET "localhost:9200/_cat/health?v"
查看节点
curl -X GET "localhost:9200/_cat/nodes?v"当前只有一个节点

查看索引
curl -X GET "localhost:9200/_cat/indices?v"当前没有索引

创建索引
curl -X PUT "localhost:9200/test"yellow 不是最健康的状态,没有备份

删除索引
curl -X DELETE "localhost:9200/test"
常用命令(使用 Postman)
(和上述重复的不再演示)
- 如果路径中指定了不存在的索引会自动建立索引
- _doc 是类型占位符,在 7.0 版本中删除了类型
- 在 Body 里使用 JSON 字符串添加数据
- 服务器地址/索引/占位符/id
- 更改数据可以使用 PUT,会替换旧数据
向 Elasticsearch 服务器添加数据
更新命令也一样
PUT: localhost:9200/test/_doc/3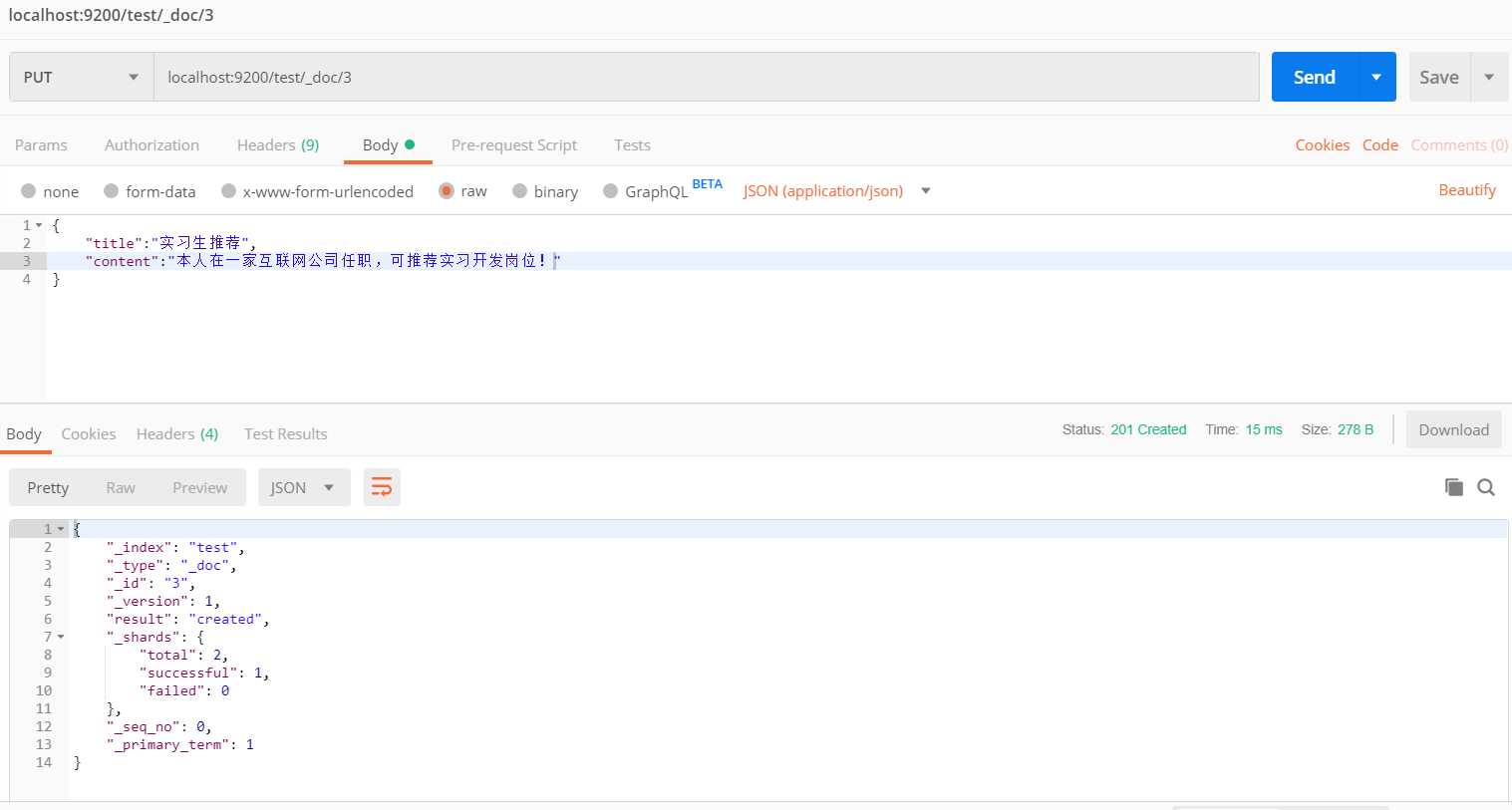
查询指定数据
GET: localhost:9200/test/_doc/3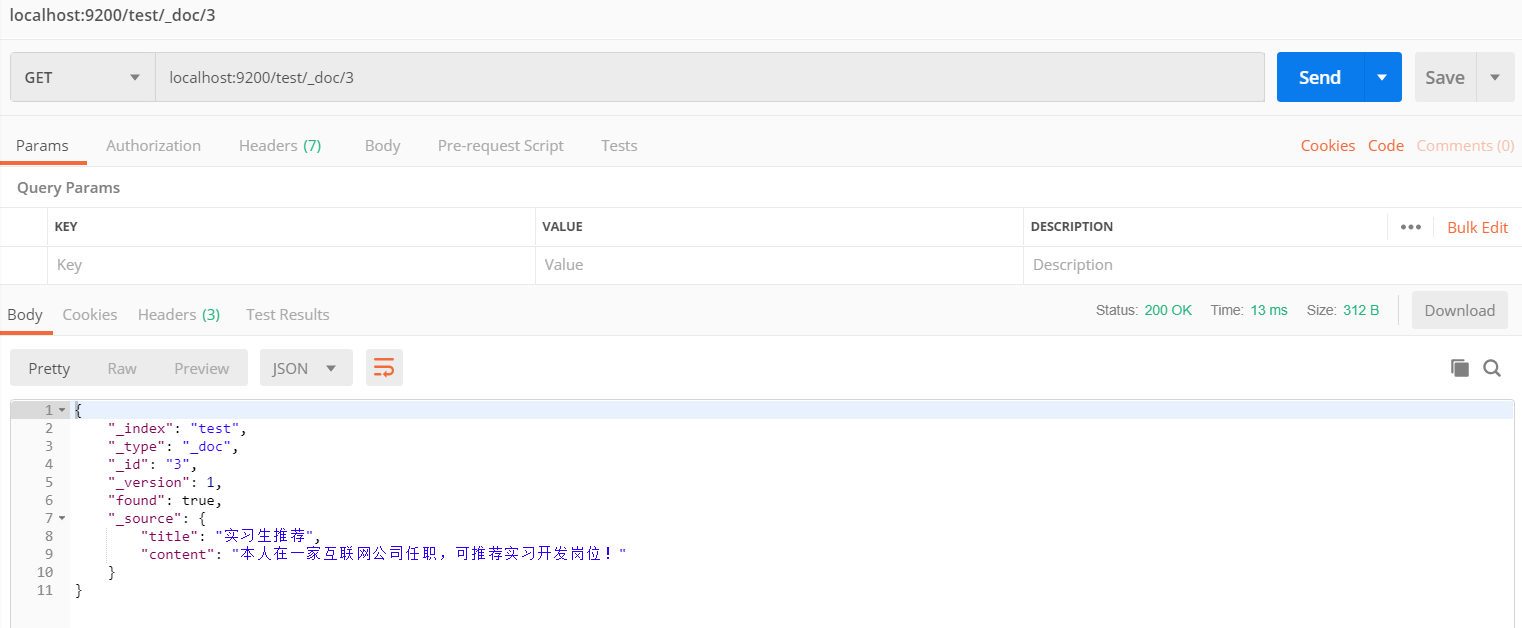
删除指定数据
DELETE: localhost:9200/test/_doc/5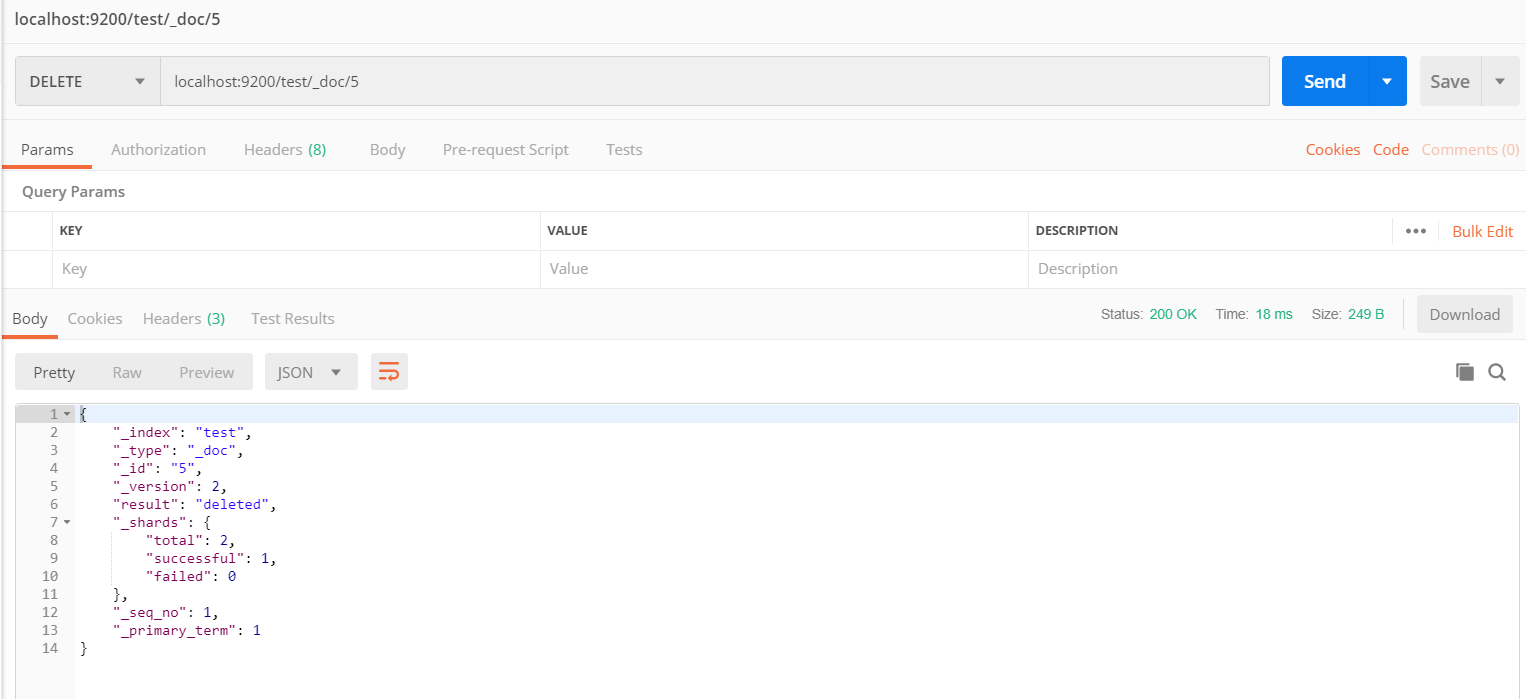
测试中文搜索分词
先添加几条数据
不加条件:
GET: localhost:9200/test/_search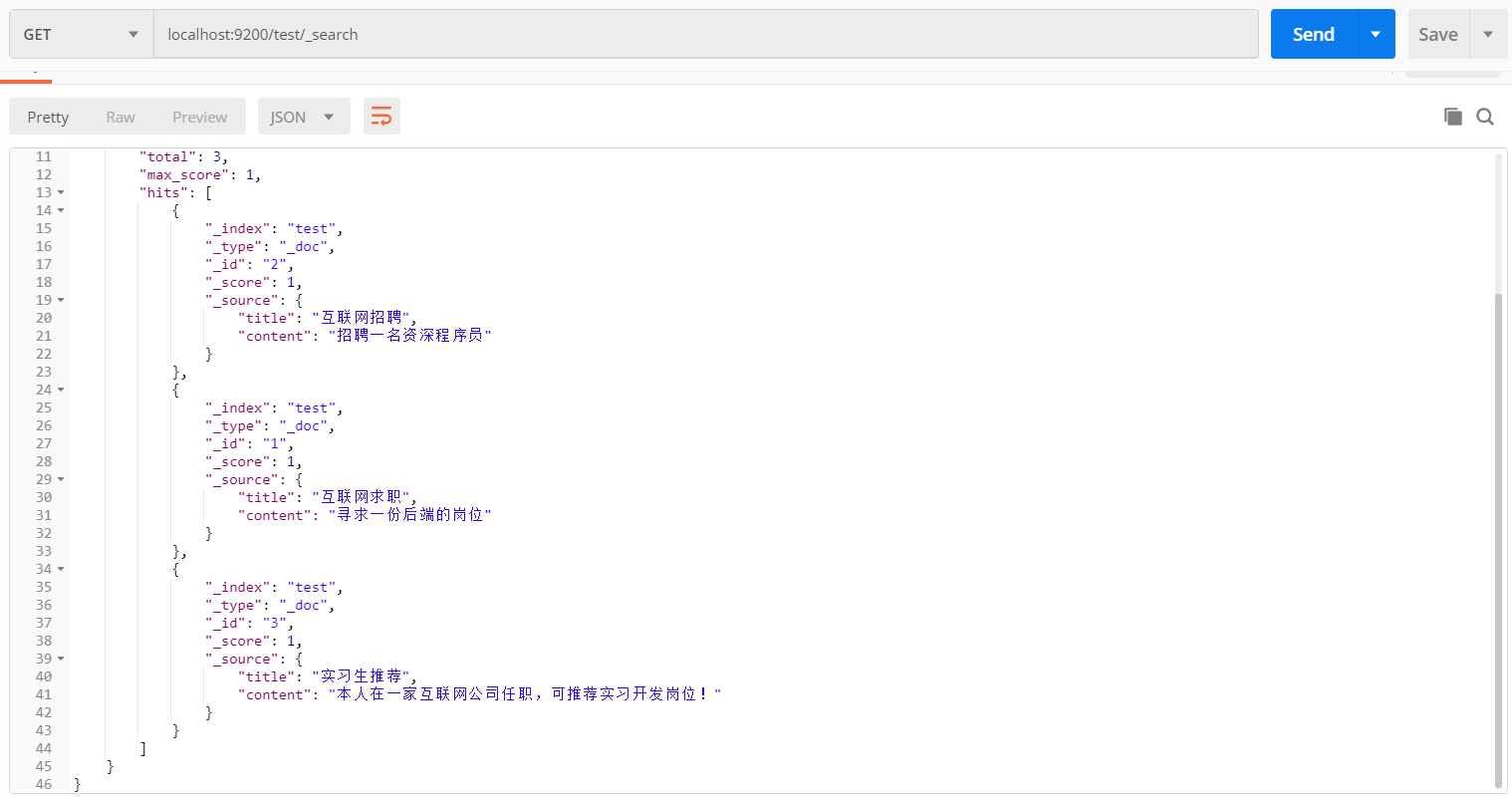
加条件:
GET: localhost:9200/test/_search?q=content:后端开发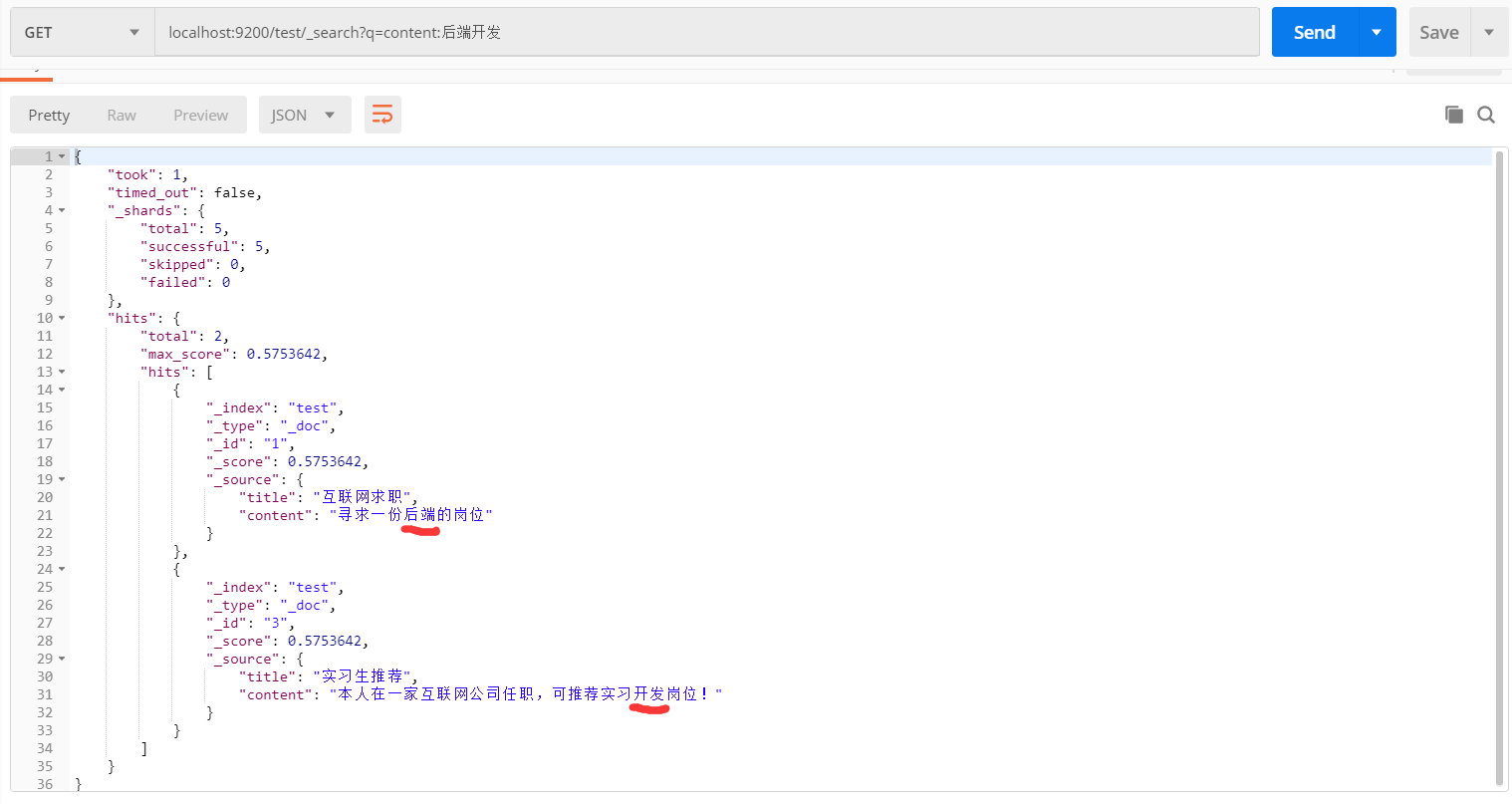
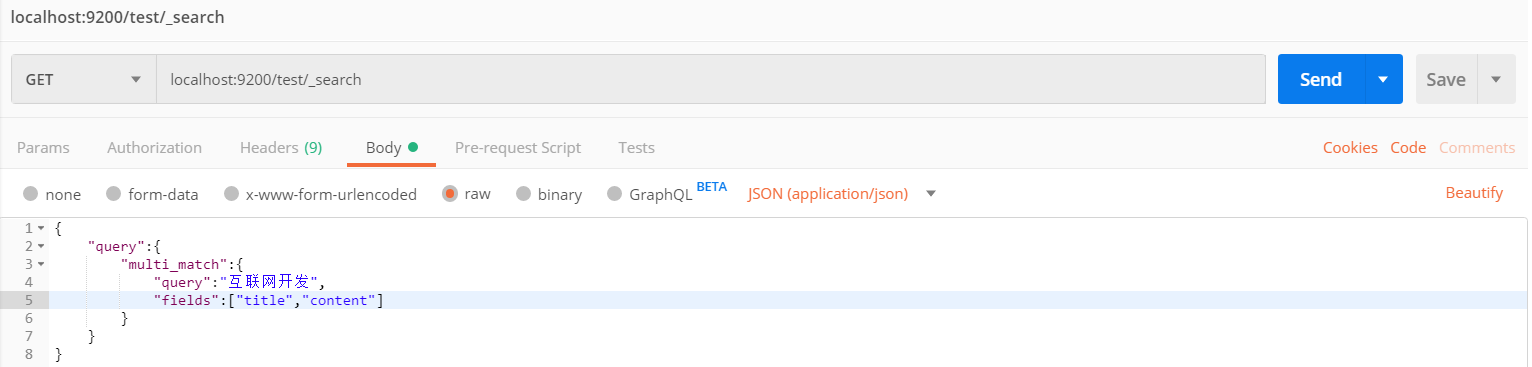
复杂搜索
GET: localhost:9200/test/_search{
"query":{
"multi_match":{
"query":"互联网开发",
"fields":["title","content"]
}
}
}
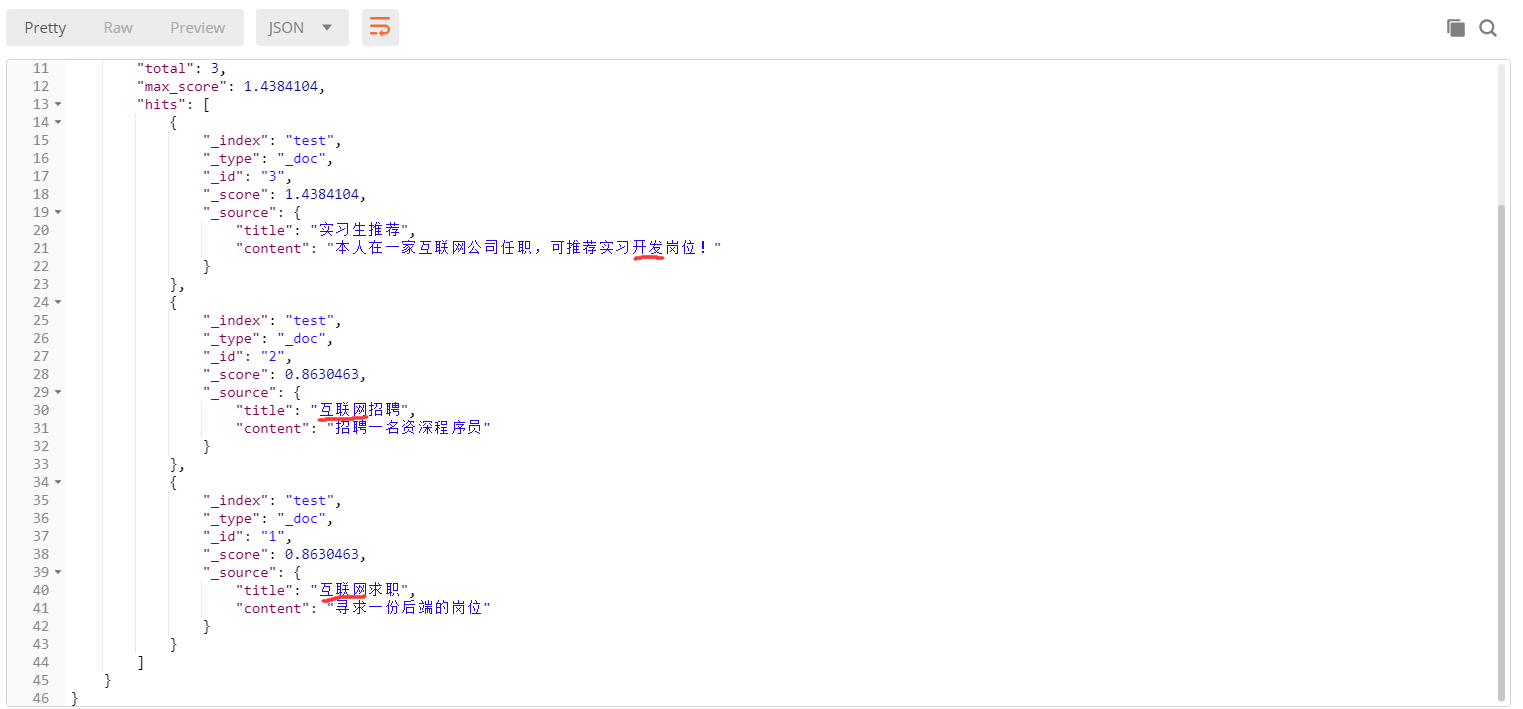
注意点:
- 索引、类型、文档、字段的含义,和数据库中各个概念的对应
- ES 的版本以及中文分词工具的版本
- Postman 的使用
- 常用命令,尤其是复杂搜索
Spring 整合 Elasticsearch
引入依赖
这里因为我原来的 SpringBoot 版本是 2.6 的,对应的 ES 版本是 7.15,所以还得降一下 SpringBoot 的版本。SpringBoot 2.1.5 对应兼容的 ES 版本才是6.4.3。
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<!--<version>2.6.7</version>-->
<version>2.1.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent><dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>配置 Elasticsearch
9200 是 HTTP 端口,9300 是 TCP 端口,这里应用服务通常用 9300 TCP 去访问
# ElasticsearchProperties
spring.data.elasticsearch.cluster-name=nowcoder
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300解决启动 Netty 的冲突
ES 和 Redis 底层都基于 Netty,这两者在使用、启动 Netty 的时候会有冲突。关键在于以下这段代码:
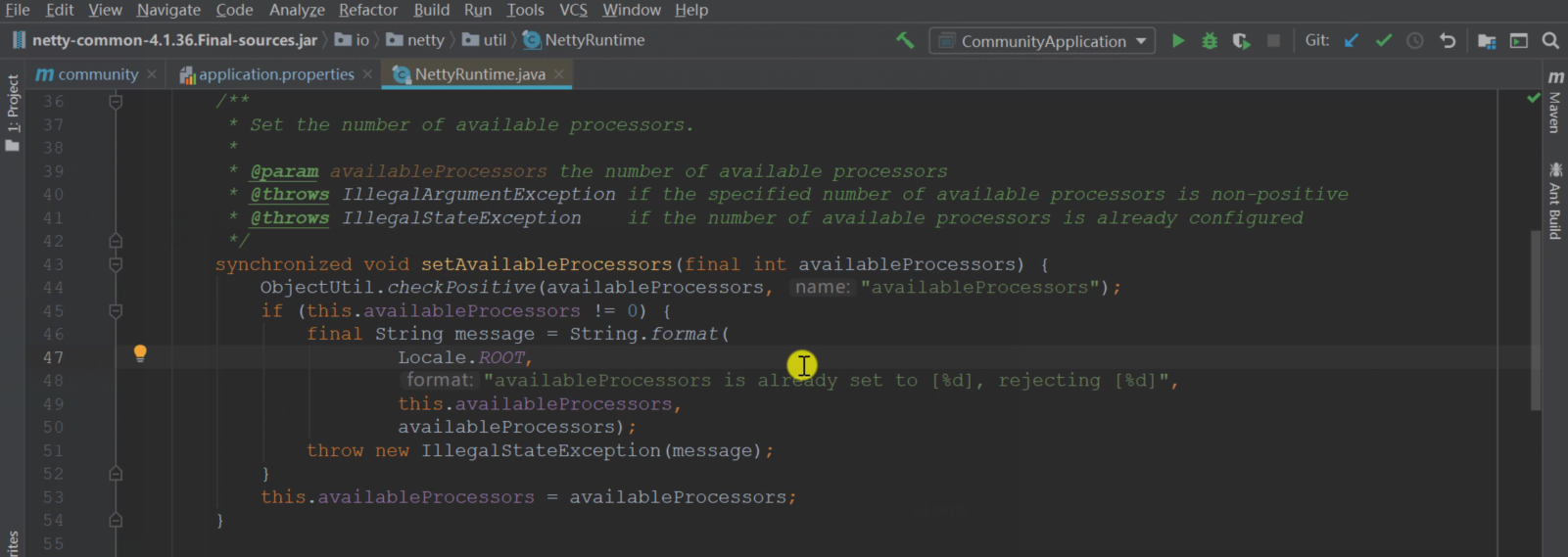
ES 在启动的时候,发现 this.availableProcessors 不为 0(Redis 也用了 Netty),就会抛异常
其实两者都可以依赖 Netty,主要是在于 ES 底层调了这个方法,所以就会报错
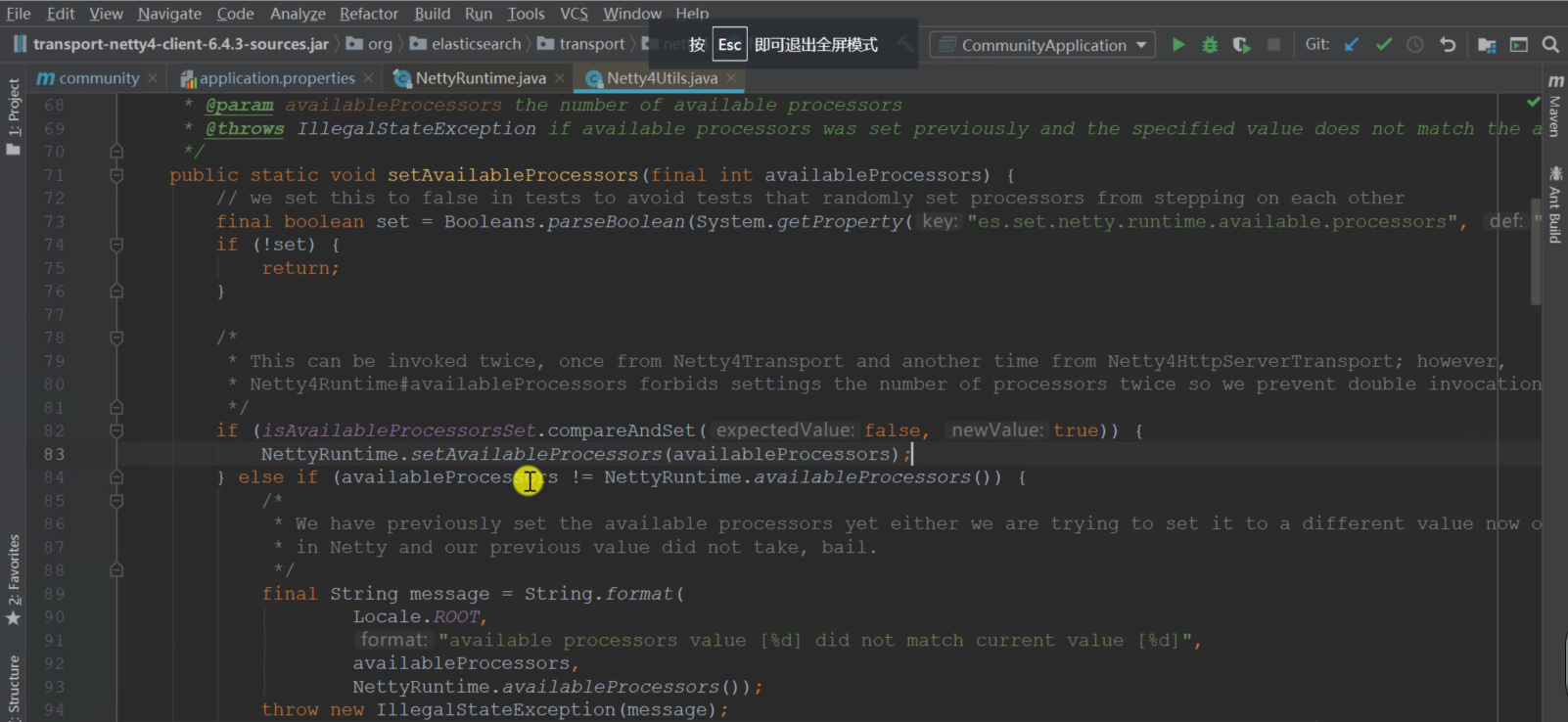
这里得到的 set 默认是 true,就会往下执行,进到 setAvailableProcessors 方法中去判断 this.availableProcessors != 0 的逻辑,然后报错。
所以,需要在合适的时机将 es.set.netty.runtime.available.processors 设置为 false,则不会往下执行,就不会报错了。
这里选择在 CommunityApplication 类中添加 @PostConstruct 注解的方法来做设置:
@SpringBootApplication
public class CommunityApplication {
@PostConstruct
public void init() {
// 解决netty启动冲突问题
// see Netty4Utils.setAvailableProcessors()
System.setProperty("es.set.netty.runtime.available.processors", "false");
}
public static void main(String[] args) {
SpringApplication.run(CommunityApplication.class, args);
}
}CommunityApplication 是整个应用的核心的入口配置类,最先被加载。在这个类的构造方法之后设置值为 false,足够早,能避免出现启动 Netty 冲突的问题。这里字符串类型的 false,底层在用到的时候会进行转型。
创建 DiscussPostRepository 接口继承 ElasticsearchRepository 接口
父接口中已经事先定义好了对 ES 服务器访问的增删改查各种方法
@Repository
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost, Integer> {
}注意:Mapper 是 MyBatis 专有的注解,而 Repository 是 Spring 提供的
对 DiscussPost 类进行修改
- 声明在 ES 中的索引名、类型(占位符,固定的)、分片数量和副本数量(这里是随意指定的,实际项目得根据实际情况来)
- id 字段加上 @Id 注解,在 ES 中也是 id 字段;其它字段都加上 @Field 注解
- 对于普通类型(Integer、Double)以及日期类型,type = FieldType.xxx(各自的类型)
- 字符串类型,type = FieldType.Text。这里的标题和内容,也是要进行分片、搜索的字段,analyzer 是存储时的解析器。在保存的时候要尽可能拆分出更多的关键词,增加搜索的范围,所以用 "ik_max_word";而在进行搜索的时候没必要拆分的那么细,拆分的聪明一点、符合预期就行了,所以 searchAnayzer 即搜索时的解析器采用 "ik_smart"
@Document(indexName = "discusspost", type = "_doc", shards = 6, replicas = 3)
public class DiscussPost {
@Id
private int id;
@Field(type = FieldType.Integer)
private int userId;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;
@Field(type = FieldType.Integer)
private int type;
@Field(type = FieldType.Integer)
private int status;
@Field(type = FieldType.Date)
private Date createTime;
@Field(type = FieldType.Integer)
private int commentCount;
@Field(type = FieldType.Double)
private double score;
……
}编写测试类 ElasticsearchTests
注意:测试的时候 Elasticsearch 要启动(Kafka 也要启动)
测试增删改数据
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class ElasticsearchTests {
@Autowired
private DiscussPostRepository discussPostRepository;
@Autowired
private DiscussPostMapper discussPostMapper;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testInsert() {
discussPostRepository.save(discussPostMapper.selectDiscussPostById(274));
discussPostRepository.save(discussPostMapper.selectDiscussPostById(275));
discussPostRepository.save(discussPostMapper.selectDiscussPostById(276));
discussPostRepository.save(discussPostMapper.selectDiscussPostById(277));
}
@Test
public void testInsertList() {
discussPostRepository.saveAll(discussPostMapper.selectDiscussPosts(0, 0, 200));
}
@Test
public void testUpdate() {
DiscussPost discussPost = discussPostMapper.selectDiscussPostById(281);
discussPost.setTitle("123");
discussPostRepository.save(discussPost);
}
@Test
public void testDelete() {
discussPostRepository.deleteById(281);
// discussPostRepository.deleteAll();
}
}用 Repository 搜索数据(结果不含高亮显示)
- 构造搜索条件:复杂搜索的内容和字段、排序方式、分页以及高亮显示
- 其中高亮显示设置需要高亮显示的字段以及前后添加的标签
- 最后得到 Page 对象(不是我们自己定义的 Page 类)进而得到各个参数,以及遍历搜索到的数据
@Test
public void testSearchByRepository() {
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(0, 10))
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
Page<DiscussPost> page = discussPostRepository.search(searchQuery);
System.out.println(page.getTotalElements());
System.out.println(page.getTotalPages());
System.out.println(page.getNumber());
System.out.println(page.getSize());
for (DiscussPost discussPost : page) {
System.out.println(discussPost);
}
}
但是这种方式得到的搜索结果中并没有在关键词前后添加标签。实际上它底层确实返回了带有标签的数据,但是它没有把这个内容合到 Page 里。即 ES 返回给我们的结果包含一个原始的结果,也会单独有一个带有标签的结果,一共两份数据,但是它的默认实现类没有把带有标签的结果整合进去。所以我们接下来要用 ElasticsearchTemplate 去自己作整合。
用 Template 搜索数据(结果包含高亮显示)
上面 Repository 的 search 方法的底层调用了 elasticsearchTemplate.queryForPage(searchQuery, class, SearchResultMapper) 方法。
查到的数据由 SearchResultMapper 去作进一步的处理,所以如果想把高亮显示的数据整合进去,需要在 SearchResultMapper 中去作处理(但是 Repository 并没有去作处理),如下:
核心就在于 mapResults 方法,其它部分和 Repository 的一样
- 如果命中数据,则需要把各个字段整合到 DiscussPost 的各个属性中(ES 在存日期格式类型的数据时会转换成 long,注意转换回日期格式)
- 先把不带高亮显示(标签)的数据设置到 DiscussPost 中,后面如果发现带有高亮显示,则做覆盖
- getFragments() 得到的是一个数组,多段匹配的内容,返回第一段即可。我们实际在搜索中,返回匹配的也是一小段内容,没必要返回整篇文章
- 最后返回的对象以及各个参数的设置需要注意
@Test
public void testSearchByTemplate() {
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(0, 10))
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
Page<DiscussPost> page = elasticsearchTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits();
if (hits.getTotalHits() <= 0)
return null;
List<DiscussPost> list = new ArrayList<>();
for (SearchHit hit : hits) {
DiscussPost post = new DiscussPost();
String id = hit.getSourceAsMap().get("id").toString();
post.setId(Integer.valueOf(id));
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.valueOf(userId));
String title = hit.getSourceAsMap().get("title").toString();
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();
post.setTitle(content);
String type = hit.getSourceAsMap().get("type").toString();
post.setType(Integer.valueOf(type));
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.valueOf(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.valueOf(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.valueOf(commentCount));
String score = hit.getSourceAsMap().get("score").toString();
post.setScore(Double.valueOf(score));
// 处理高亮显示的结果
HighlightField titleField = hit.getHighlightFields().get("title");
if (titleField != null) {
post.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if (contentField != null) {
post.setContent(contentField.getFragments()[0].toString());
}
list.add(post);
}
return new AggregatedPageImpl(list, pageable, hits.getTotalHits(),
response.getAggregations(), response.getScrollId(), hits.getMaxScore());
}
});
System.out.println(page.getTotalElements());
System.out.println(page.getTotalPages());
System.out.println(page.getNumber());
System.out.println(page.getSize());
for (DiscussPost discussPost : page) {
System.out.println(discussPost);
}
}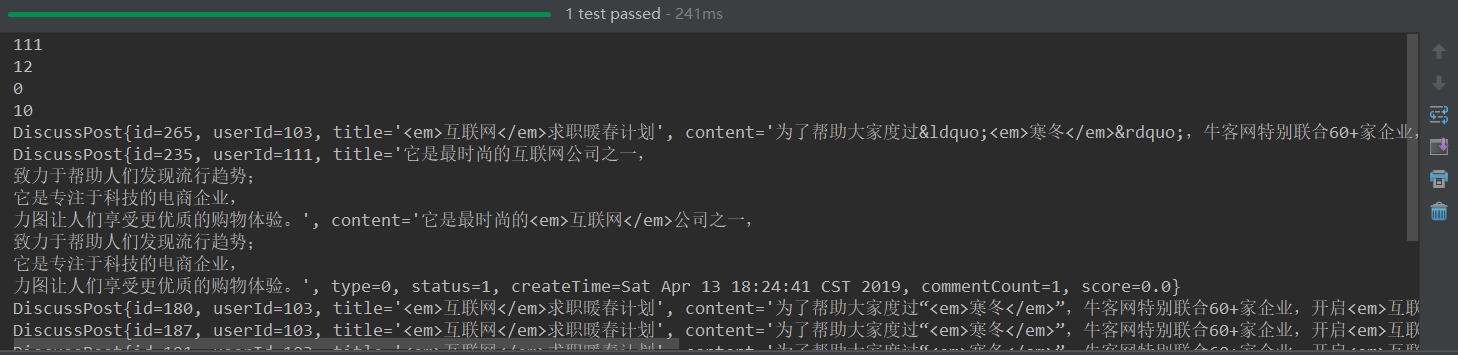
结果带上了标签
注意点:
- Elasticsearch 和 SpringBoot 的版本兼容问题
- Elasticsearch 的配置,9300 端口
- Netty 的冲突问题的原因与解决办法
- 使用 Repository 搜索之前,定义一个 xxxRepository 继承 ElasticsearchRepository 接口。使用时注入 XXXRepository,用它来调相应的方法
- 对 DiscussPost 类的修改,尤其是 title 和 content 字段
- 测试 or 运行时需要去启动 Elasticsearch 服务器
- 搜索时,注意搜索条件的构造与高亮显示的处理
- 使用 Repository 搜索时,结果没有整合上带有高亮显示的数据。所以使用 ElasticsearchTemplate 来搜索,去做高亮显示结果的整合。注意其处理方式
开发社区搜索功能
处理遗留的小问题:
增加帖子的方法中要声明 keyProperty="id",以便 MyBatis 知道哪个是主键,增加完帖子后把生成的主键的值存到实体类中去
<insert id="insertDiscussPost" keyProperty="id">
INSERT INTO discuss_post(<include refid="insertFields"/>)
VALUES (#{userId}, #{title}, #{content}, #{type}, #{status}, #{createTime}, #{commentCount}, #{score})
</insert>编写 ElasticsearchService
实现增加 / 更新、删除以及搜索帖子的方法
@Service
public class ElasticsearchService {
@Autowired
private DiscussPostRepository discussPostRepository;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
public void saveDiscussPost(DiscussPost post) {
discussPostRepository.save(post);
}
public void deleteDiscussPost(int id) {
discussPostRepository.deleteById(id);
}
public Page<DiscussPost> searchDiscussPost(String keyword, int current, int limit) {
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery(keyword, "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))
.withPageable(PageRequest.of(current, limit))
.withHighlightFields(
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
return elasticsearchTemplate.queryForPage(searchQuery, DiscussPost.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits();
if (hits.getTotalHits() <= 0)
return null;
List<DiscussPost> list = new ArrayList<>();
for (SearchHit hit : hits) {
DiscussPost post = new DiscussPost();
String id = hit.getSourceAsMap().get("id").toString();
post.setId(Integer.valueOf(id));
String userId = hit.getSourceAsMap().get("userId").toString();
post.setUserId(Integer.valueOf(userId));
String title = hit.getSourceAsMap().get("title").toString();
post.setTitle(title);
String content = hit.getSourceAsMap().get("content").toString();
post.setTitle(content);
String type = hit.getSourceAsMap().get("type").toString();
post.setType(Integer.valueOf(type));
String status = hit.getSourceAsMap().get("status").toString();
post.setStatus(Integer.valueOf(status));
String createTime = hit.getSourceAsMap().get("createTime").toString();
post.setCreateTime(new Date(Long.valueOf(createTime)));
String commentCount = hit.getSourceAsMap().get("commentCount").toString();
post.setCommentCount(Integer.valueOf(commentCount));
String score = hit.getSourceAsMap().get("score").toString();
post.setScore(Double.valueOf(score));
// 处理高亮显示的结果
HighlightField titleField = hit.getHighlightFields().get("title");
if (titleField != null) {
post.setTitle(titleField.getFragments()[0].toString());
}
HighlightField contentField = hit.getHighlightFields().get("content");
if (contentField != null) {
post.setContent(contentField.getFragments()[0].toString());
}
list.add(post);
}
return new AggregatedPageImpl(list, pageable, hits.getTotalHits(),
response.getAggregations(), response.getScrollId(), hits.getMaxScore());
}
});
}
}触发发帖事件
发布帖子或增加评论(要修改帖子的评论数量)时,要将帖子异步的提交到 Elasticsearch 服务器。还是利用 Kafka 实现。另外再定义一个主题常量:
// 主题:发帖
String TOPIC_PUBLISH = "publish";@PostMapping("/add")
@ResponseBody
public String addDiscussPost(String title, String content) {
User user = hostHolder.getUser();
if(user == null) {
CommunityUtil.getJSONString(403, "你还没有登录哦!");
}
……
// 触发发帖事件
Event event = new Event()
.setTopic(TOPIC_PUBLISH)
.setUserId(user.getId())
.setEntityType(ENTITY_TYPE_POST)
.setEntityId(post.getId());
eventProducer.fireEvent(event);
// 报错的情况,将来统一处理
return CommunityUtil.getJSONString(0, "发布成功!");
}增加评论时,需要判断评论的对象是帖子时才触发事件
@PostMapping("/add/{discussPostId}")
public String addComment(@PathVariable("discussPostId") int discussPostId, Comment comment) {
User user = hostHolder.getUser();
……
// 触发评论事件
……
if (comment.getEntityType() == ENTITY_TYPE_POST) {
// 触发发帖事件
event = new Event()
.setTopic(TOPIC_PUBLISH)
.setUserId(user.getId())
.setEntityType(ENTITY_TYPE_POST)
.setEntityId(discussPostId);
eventProducer.fireEvent(event);
}
return "redirect:/discuss/detail/" + discussPostId;
}消费发帖事件
将帖子保存到 Elasticsearch 服务器中以供搜索
// 消费发帖事件
@KafkaListener(topics = {TOPIC_PUBLISH})
public void handlePublishMessage(ConsumerRecord record) {
if(record == null || record.value() == null) {
logger.error("消息的内容为空!");
return;
}
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
if(event == null) {
logger.error("消息格式错误!");
return;
}
DiscussPost post = discussPostService.findDiscussPostById(event.getEntityId());
elasticsearchService.saveDiscussPost(post);
}编写 ElasticsearchController
处理搜索的请求:
- 搜索帖子
- 将帖子信息与用户信息以及点赞数量整合起来
- 最后不要忘了设置分页信息
// search?keyword=xxx
@GetMapping("/search")
public String search(String keyword, Page page, Model model) {
// 搜索帖子
org.springframework.data.domain.Page<DiscussPost> searchResult =
elasticsearchService.searchDiscussPost(keyword, page.getCurrent() - 1, page.getLimit());
// 聚合数据
List<Map<String, Object>> discussPosts = new ArrayList<>();
if(searchResult != null) {
for (DiscussPost post : searchResult) {
Map<String, Object> map = new HashMap<>();
// 帖子
map.put("post", post);
// 作者
map.put("user", userService.findUserById(post.getUserId()));
// 点赞数量
map.put("likeCount", likeService.findEntityLikeCount(ENTITY_TYPE_POST, post.getId()));
discussPosts.add(map);
}
}
model.addAttribute("discussPosts", discussPosts);
model.addAttribute("keyword", keyword);
// 分页信息
page.setPath("/search?keyword=" + keyword);
page.setRows(searchResult == null ? 0 : (int) searchResult.getTotalElements());
return "/site/search";
}修改页面
修改 index.html
- 修改表单提交方式为 get、提交的路径
- input 中的 name 与后端参数名相对应,另外默认显示搜索的关键词(null 则不显示)
<!-- 搜索 -->
<form class="form-inline my-2 my-lg-0" method="get" th:action="@{/search}">
<input class="form-control mr-sm-2" type="search" aria-label="Search" name="keyword" th:value="${keyword}"/>
<button class="btn btn-outline-light my-2 my-sm-0" type="submit">搜索</button>
</form>修改 search.html
- 声明 thymeleaf 模板、修改相对路径、头部和分页部分的替换与之前类似
- 帖子列表去作遍历与动态取值
<!-- 帖子列表 -->
<ul class="list-unstyled mt-4">
<li class="media pb-3 pt-3 mb-3 border-bottom" th:each="map:${discussPosts}">
<img th:src="${map.user.headerUrl}" class="mr-4 rounded-circle" alt="用户头像" style="width:50px;height:50px;">
<div class="media-body">
<h6 class="mt-0 mb-3">
<a th:href="@{|/discuss/detail/${map.post.id}|}" th:utext="${map.post.title}">
备战<em>春招</em>,面试刷题跟他复习,一个月全搞定!
</a>
</h6>
<div class="mb-3" th:utext="${map.post.content}">
金三银四的金三已经到了,你还沉浸在过年的喜悦中吗? 如果是,那我要让你清醒一下了:目前大部分公司已经开启了内推,正式网申也将在3月份陆续开始,金三银四,<em>春招</em>的求职黄金时期已经来啦!!! 再不准备,作为19应届生的你可能就找不到工作了。。。作为20届实习生的你可能就找不到实习了。。。 现阶段时间紧,任务重,能做到短时间内快速提升的也就只有算法了, 那么算法要怎么复习?重点在哪里?常见笔试面试算法题型和解题思路以及最优代码是怎样的? 跟左程云老师学算法,不仅能解决以上所有问题,还能在短时间内得到最大程度的提升!!!
</div>
<div class="text-muted font-size-12">
<u class="mr-3" th:utext="${map.user.username}">寒江雪</u>
发布于 <b th:text="${#dates.format(map.post.createTime,'yyyy-MM-dd HH:mm:ss')}">2019-04-15 15:32:18</b>
<ul class="d-inline float-right">
<li class="d-inline ml-2">赞 <i th:text="${map.likeCount}">11</i></li>
<li class="d-inline ml-2">|</li>
<li class="d-inline ml-2">回复 <i th:text="${map.post.commentCount}">7</i></li>
</ul>
</div>
</div>
</li>
</ul>注意点:
- 增加帖子的方法中要声明 keyProperty 主键
- 进一步熟练 Kafka 和 Elasticsearch 的使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号