字典树(前缀树)的实现
字典树(前缀树)的实现
题目:字典树的实现
《程序员代码面试指南》第100题 P320 难度:尉★★☆☆
字典树是一种树形结构,优点是利用字符串的公共前缀来节约存储空间,比如加入“abc”、“abcd”、“abd”、“b”、“bcd”、“efg”、“hik”之后,字典树如图:
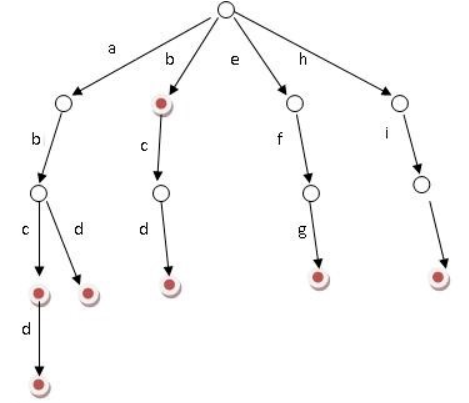
字典树的基本性质如下:
- 根节点没有字符路径。除根节点外,每一个节点都被一个字符路径找到。
- 从根节点出发到任何一个节点,如果将沿途经过的字符连接起来,一定为某个加入过的字符串的前缀。
- 每个节点向下所有的字符路径上的字符都不同。
在字典树上搜索添加过的单词的步骤如下:
- 从根节点开始搜索。
- 取得要查找单词的第一个字母,并根据该字母选择对应的字符路径向下继续搜索。
- 字符路径指向的第二层节点上,根据第二个字母选择对应的字符路径向下继续搜索。
- 一直向下搜索,如果单词搜索完后,找到的最后一个节点是一个终节点,比如图中的实心节点,说明字典树中含有这个单词,如果找到的最后一个节点不是一个终止节点,说明单词不是字典树中添加过的单词。如果单词没搜索完,但是已经没有后续的节点了,也说明单词不是字典树中添加过的单词。
字典树节点的类型参见如下代码中的TrieNode类:
public class TrieNode {
public int path;
public int end;
public TrieNode[] map;
public TrieNode() {
path = 0;
end = 0;
map = new TrieNode[26];
}
}path表示有多少个单词共用这个节点,end表示有多少个单词以这个节点结尾,map是一个哈希表结构,key代表该节点的一条字符路径,value表示字符路径指向的节点(本题字符种类不多,采用长度为26的数组)。
Trie树类的全部实现过程如下(具体解释见书P322):
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
public void insert(String word) {
if (word == null) {
return;
}
char[] chs = word.toCharArray();
TrieNode node = root;
node.path++;
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';
if (node.map[index] == null) {
node.map[index] = new TrieNode();
}
node = node.map[index];
node.path++;
}
node.end++;
}
public void delete(String word) {
if (search(word)) {
char[] chs = word.toCharArray();
TrieNode node = root;
node.path--;
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';
if (node.map[index].path-- == 1) {
node.map[index] = null;
return;
}
node = node.map[index];
}
node.end--;
}
}
public boolean search(String word) {
if (word == null) {
return false;
}
char[] chs = word.toCharArray();
TrieNode node = root;
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';
if (node.map[index] == null) {
return false;
}
node = node.map[index];
}
return node.end != 0;
}
public int prefixNumber(String pre) {
if (pre == null) {
return 0;
}
char[] chs = pre.toCharArray();
TrieNode node = root;
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';
if (node.map[index] == null) {
return 0;
}
node = node.map[index];
}
return node.path;
}
}对比我自己的实现和题解的实现,我代码中的delete和prefixNumber都用了递归,耗时较长,而题解在TrieNode中定义的path很巧妙,可以利用path直接得到prefixNumber,并且delete中可以通过判断path是否为0而直接断开后面的路径,不需要再往后遍历。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号