
二分图
二分图总结
一是 太长时间不写博客,觉得对不起这个账号 二是记录一下对二分图的建边和含义的理解
首先 我们要知道二分图的三个性质
1.二分图的一组匹配 M 是最大匹配,当且仅当图中不存在 M 的增广路。
2.二分图中最小点覆盖数=最大匹配数
3.二分图中最大独立集数=n-最小点覆盖数、
然后 基于二分图的"匹配"的两点唯一对应的性质 所以我们可以将其视为一种映射
匈牙利算法
`
// 匈牙利算法求最大匹配
int xyl() {
int ans = 0; // 记录最大匹配数
for (int i = 1; i <= n; i++) {
memset(vis, 0, sizeof(vis));
// 找到一条增广路,匹配数+1
if (dfs(i)) ans++;
}
}
bool dfs(int now)
{
for (int i = head[now]; i; i = edge[i].nxt) {
int to = edge[i].to;
if (!vis[to])
{
vis[to] = true;
if (!match[to] || dfs(match(to))) {
match[to] = now;
return true;
}
}
}
return false;
}
`
理解
对于目前题库中有的题 ,所有的题都可以分为两种对应(映射) ,相同含义的对应和不同含义的对应
不同含义
如 文理分班中的人和椅子,Asteroids 穿越小行星群中的行和列,超级英雄中的题目和锦囊妙计,想这样具有不同的对应关系
注意 即使如田忌赛马中双方的马也不能认为 同类(没有具体的题,所以拿这个成语举下例子)
对于这样的题往往需要建单向边
但这样会有一个问题 点的名称重复但含义不同
例如 以 Asteroids 穿越小行星群 为例
当我们需要将 第一行 和 第三列 建立联系时 如果不加思考
会直接
add(1,3)
但 稍加思考 为了避免其重复带来的影响
add(1,3+n)//n为总列数
但 再加思考 我们会发现 这两种其实是一样的
其关键在于match数组的应用
设将行对应的点的集合设为 V1 将列对应的点设为 V2

在二分图中由add函数添加的边都为由v1指向指向v2 即未匹配边
由match 数组建立的边都为匹配边
eg add(1,3) match[4]=2
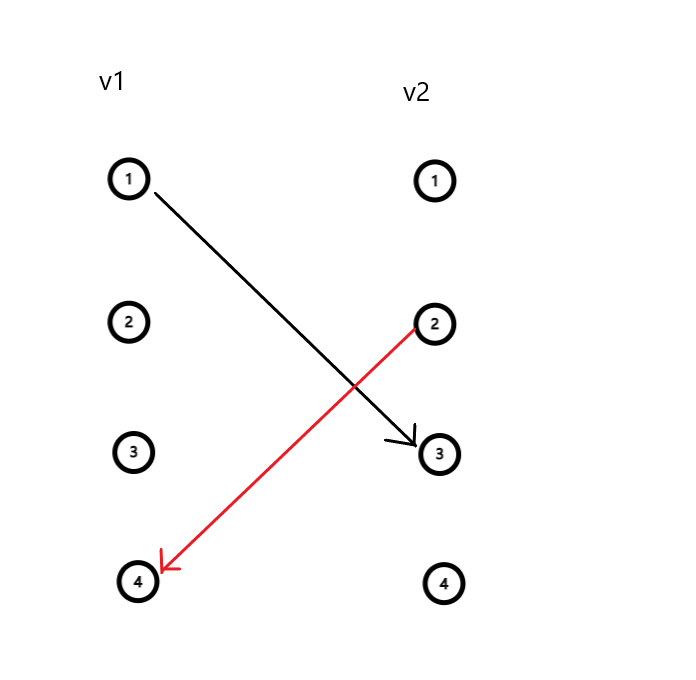
所以这就解释为什么在xyl()函数中为什么可以将n个点全部遍历 并且为什么在该类题中只能加单向边 因为每一次的寻找新匹配都由v1中的点出发,其v2中即使有名称相同的点 也会因v2中的出边都由match数组管控,而不互相影响,相当于与add()函数是两套存边系统
所以在用add()数组建完边后 全部为由v1,到v2的单向边,而 如果存在match[y]=x 那么一定有add(x,y)
此时 二分图 是 无向图的性质得以体现 ,且建立的 匹配数 即为 无向边数 且一一对应
相同含义
在相同含义的题中,要保证v1,v2中的点完全相同
如题库中 猫与狗 的人与人
而 对于 为什么 答案为 n-xly()/2 可以这样理解
对于 一对 矛盾关系 其建边方式由以下两种 来自HDK
点击查看代码
#1
for(int i=1;i<=n;++i){
for(int j=1;j<=n;++j){
if(like[i]==dislike[j]||dislike[i]==like[j]){
e[i].push_back(j);
}
}
}
#2
for(int i=1;i<=n;++i){
for(int j=1;j<=n;++j){
if(like[i]==dislike[j]){
e[i].push_back(j);
e[j].push_back(i);
}
}
}
如果 1,3 有矛盾, 那么从 V1 的‘1’到 V2 的‘3’ 和 V1 的‘3’到 V2 的‘1’ 都会建边
所以

 浙公网安备 33010602011771号
浙公网安备 33010602011771号