[PyTorch] DDP源码阅读
[PyTorch] DDP源码阅读
-
PyTorch的DistributedDataParallel (DDP) 允许多台机器,多台GPU之间的数据并行。本文简单讲解DDP的流程,并从代码层面理解DDP如何访问底层的通信框架。
-
DDP使用单机多进程来控制多个GPU。模型需要能放入单个GPU中。
DDP的用法
-
首先,创建多个进程,使用
torch.distributed.launch或者torch.multiprocessing.spawn -
然后,为每个进程分配GPU,可以使用
CUDA_VISIBLE_DEVICES或者torch.cuda.set_device(i) -
在每个进程,都需要初始化进程组
dist.init_process_group(backend="nccl", rank=rank, world_size=world_size)
- 然后,将模型包装成DDP
model = DistributedDataParallel(model, device_ids=[i], output_device=i)
- 最后,每个进程独立运行模型
DDP概览
参考PyTorch Distributed Overview — PyTorch Tutorials 2.6.0+cu124 documentation
- DDP依赖于PyTorch distributed communication layer (C10D) 的
ProcessGroup进行通信。 - 初始化:
- 将
state_dict()从rank0进程广播到所有进程,保证所有进程的初始状态相同 - 每个进程创建一个
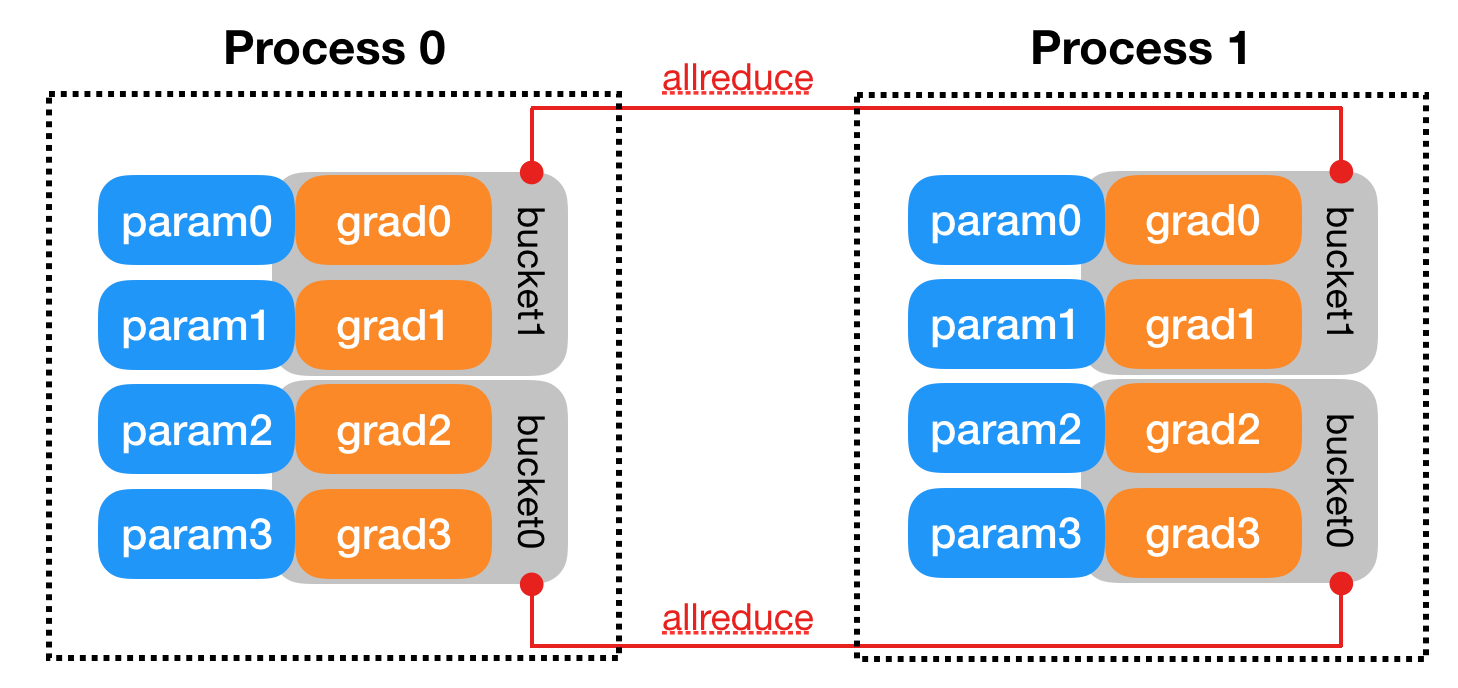
Reducer,负责反向传播阶段的梯度同步 - 为了效率,每个
Reducer将参数分为多个桶。一旦一个桶内的所有参数都完成了反向传播,就开始这个桶的梯度同步。 - 为了检测每个参数是否完成了反向传播,为每个参数都注册一个
autograd hook。
- 将
- 前向:不需要进行进程间同步
- 反向:
backward()函数位于loss的Tensor上,这不在DDP的控制范围。因此,DDP借助autograd hook来得知哪些参数已经完成了反向传播。一旦一个桶内的所有参数都完成了反向传播,Reducer就会在所有进程之间进行异步的allreduce。若所有桶都完成了反向传播,Reducer会阻塞等待allreduce结束。 - 优化:每个进程都只优化本地的模型。因为所有进程的模型都进行过梯度同步,因此他们的优化结果也相同。
- 其他:
- 一个额外的选项是
find_unused_parameters。如果模型的反向传播不会更新所有参数,则那些不更新的参数不会触发autograd hook,则Reducer可能会永远的等待这些参数。在这种情况下,用户需要设置find_unused_parameters=True。此时,模型会在前向传播时寻找所有未用到的参数,并标记这些参数是“已完成”的,Reducer不会等待这些参数。注意这个过程需要额外的搜索所有参数,会导致些许时间开销。
- 一个额外的选项是
代码解读
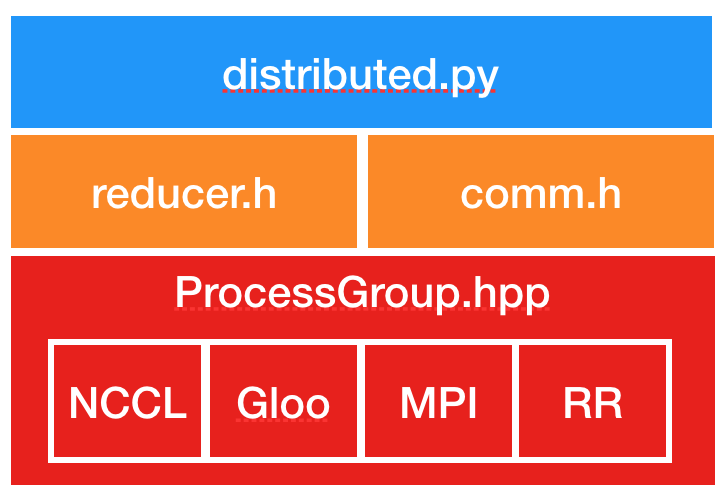
DDP的主要代码位于torch/nn/parallel/distributed.py,其中可能会用到一些其他的通信接口,但最终所有的通信都会调用ProcessGroup。
- 在
init_process_group中,会根据backend字符串,决定使用哪个process group(如ProcessGroupNCCL)。
这里只截取部分关键代码
class DistributedDataParallel(Module, Joinable):
def __init__(...):
# Build parameters for reducer.
parameters, expect_sparse_gradient = self._build_params_for_reducer()
# _build_params_for_reducer大致内容:
# 找到self.module.named_modules()中,所有的module.named_parameters()
# 且param.requires_grad=True,且不属于self.parameters_to_ignore
# 确认所有进程上的模型大小和状态相同
# All collectives during initialization are gated by this flag.
if init_sync:
# 确认模型大小
# Verify model equivalence.
_verify_param_shape_across_processes(self.process_group, parameters)
# 同步模型参数
# Sync params and buffers. Ensures all DDP models start off at the same value.
_sync_module_states(
module=self.module,
process_group=self.process_group,
broadcast_bucket_size=self.broadcast_bucket_size,
src=0,
params_and_buffers_to_ignore=self.parameters_to_ignore,
broadcast_buffers=self.broadcast_buffers,
)
# _sync_module_states大致内容:
# 获取所有module.named_parameters()与module.named_buffers()
# 然后调用torch/csrc/cuda/comm.cpp提供的broadcast_coalesced接口
# 在内部调用nccl::broadcast
# 创建reducer
# Builds reducer.
self._ddp_init_helper(
parameters,
expect_sparse_gradient,
param_to_name_mapping,
static_graph,
)
# _ddp_init_help内容如下:
"""
DDP init helper function to manage parameters, grad hooks, logging, and SyncBatchNorm.
Initialization helper function that does the following:
(1) bucketing the parameters for reductions
(2) resetting the bucketing states
(3) registering the grad hooks
(4) Logging construction-time DDP logging data
(5) passing a handle of DDP to SyncBatchNorm Layer
"""
# 内部调用torch/csrc/distributed/c10d/reducer.cpp创建Reducer
# 获取每个参数的grad函数
# auto grad_accumulator = torch::autograd::impl::grad_accumulator(variable);
# 添加autograd_hook
# grad_accumulator->add_post_hook(..., this->autograd_hook(...), ...)
# 保存将grad函数保存到grad_accumulators_
以上就是初始化部分,接下来再看一看在反向传播中,autograd_hook是如何运作的
-
autograd_hook的主要内容是mark_variable_ready- 若当前桶已经全部完成,则调用
mark_bucket_ready mark_bucket_ready内部进行all_reduce_bucket- 调用
ProcessGroup的allreduce()- 具体地,
ProcessGroupNCCL有自己的allreduce_impl,执行nccl:all_reduce
- 具体地,
- 若当前桶已经全部完成,则调用
-
mark_variable_ready还会检查是否所有桶都已准备好,若所有的桶都已经准备好了,则在所有参数的梯度更新完成后,调用this->finalize_backward(),其内部等待所有的桶的任务完成
另外,ProcessGroup是异步提交通讯任务的。那怎样得知一个任务是否完成呢?
-
在
ProcessGroupNCCL创建任务时,会将其加入未完成队列,并记录它的事件work->ncclEndEvent_->record(ncclStream) -
在
ProcessGroupNCCL初始化时,还会创建一个ncclCommWatchdog,每隔一段时间,就检测未完成任务队列中的任务是否完成。 -
检测任务完成是通过
work->ncclEndEvent_->query()判断的,其内部最终调用cudaEventQuery()来判断任务的事件是否完成
| 欢迎来原网站坐坐! >原文链接<



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架