[LLM] ZeRO-DP技术简析
[LLM] ZeRO-DP技术简析
本文对ZeRO: Memory Optimizations Toward Training Trillion Parameter Models中提出的ZeRO-DP进行简要总结。相关的讲解其实网上也有很多了,不过只看网上的终究还是有点走马观花,所以我还是决定自己写一篇博客,记录一下我自己的理解。这篇博客讲的不会太细,但是希望能用更易于理解的方式,讲明白文中的重要内容。
为什么需要ZeRO-DP?
-
数据并行(DP)是分布式训练中最基本的并行方式,它通过把数据分发到不同的GPU上从而提升效率。但数据并行不会降低每个GPU的显存开销。在一个数据并行组中,不同的GPU保存的模型参数、优化器状态、和梯度其实都是同一份。每次迭代时,需要对模型参数进行All-Reduce来同步状态。
-
为了避免存储冗余状态,降低显存开销,ZeRO-DP选择把这些状态也分割到不同的GPU上(注意:这不同于模型并行MP。ZeRO-DP本质上还是DP,它是把状态在DP组内进行分割,它可以于MP同时存在。)在前向传播的时候,每个GPU从其他GPU那里获取到全部状态并进行计算;在反向传播的时候,只把划分后的状态发给每个GPU。
概述
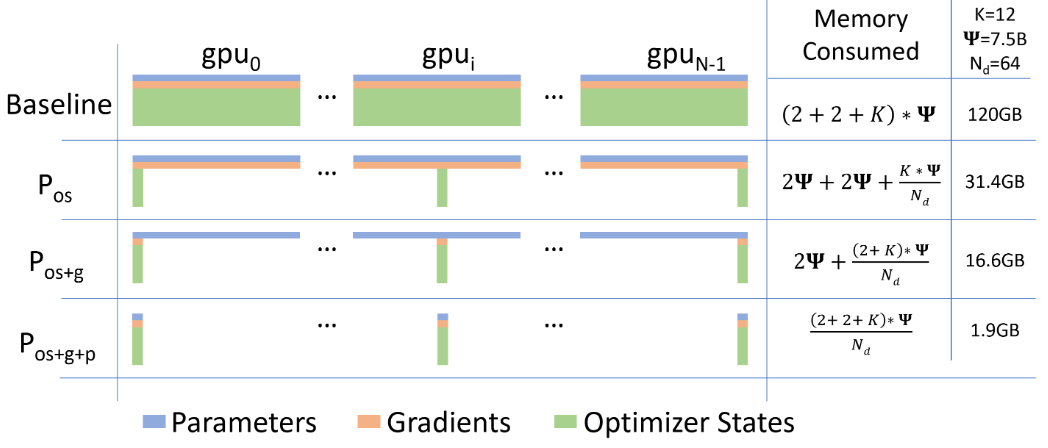
-
图中,代表模型参数量,图中使用fp16参数,所以模型参数占用内存为;表示DP度数(DP组的大小);表示优化器状态的参数量是模型参数量的多少倍,图中使用Adam优化器中。
-
ZeRO-DP一共分为三个阶段:
- 对优化器状态进行划分。
- 对优化器状态和梯度进行划分。
- 对优化器状态,梯度和模型参数进行划分。
-
图中可以明显的看出每个阶段的划分所带来的显存降低收益。
通信量分析
- 很明显的,ZeRO-DP将状态划分到不同的GPU上,从而降低了显存开销。但是在这个过程中,拉取和分发状态是否会导致额外的通信开销呢?所以我们来分析一下ZeRO-DP的通信开销。
前置知识
-
为了方便,我们这里先不考虑模型并行MP,只考虑数据并行DP。这里的通信开销指的是每台GPU所需的通信量。
-
All-reduce的通信开销是。Reduce-scatter和All-gather的通信开销都是。
传统DP的通信开销
在下面图中,表示数据,表示模型参数,表示梯度,表示优化器参数。下标表示数据划分的第块,上标表示模型划分的第块。这里只考虑2个GPU。
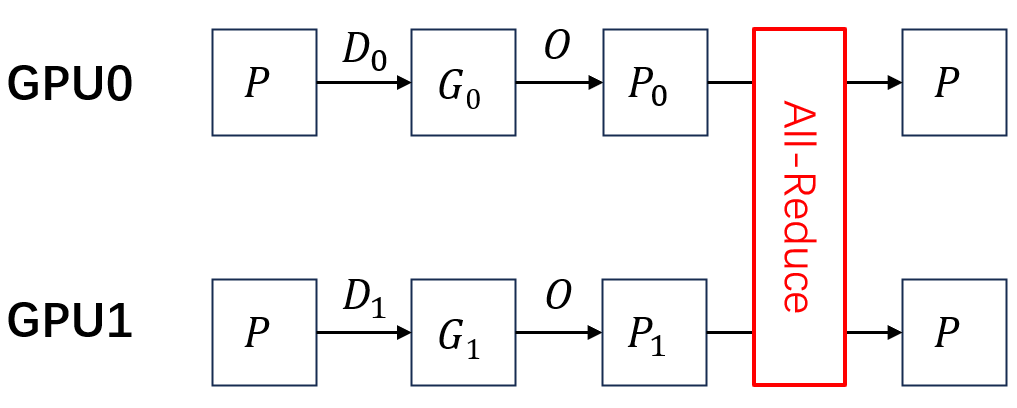
在传统DP中,正向传播不需要任何通信。但是在反向传播中,由于所有GPU上的模型参数是副本关系,所以它们要进行All-reduce完成同步,所需通信量是。
的通信开销
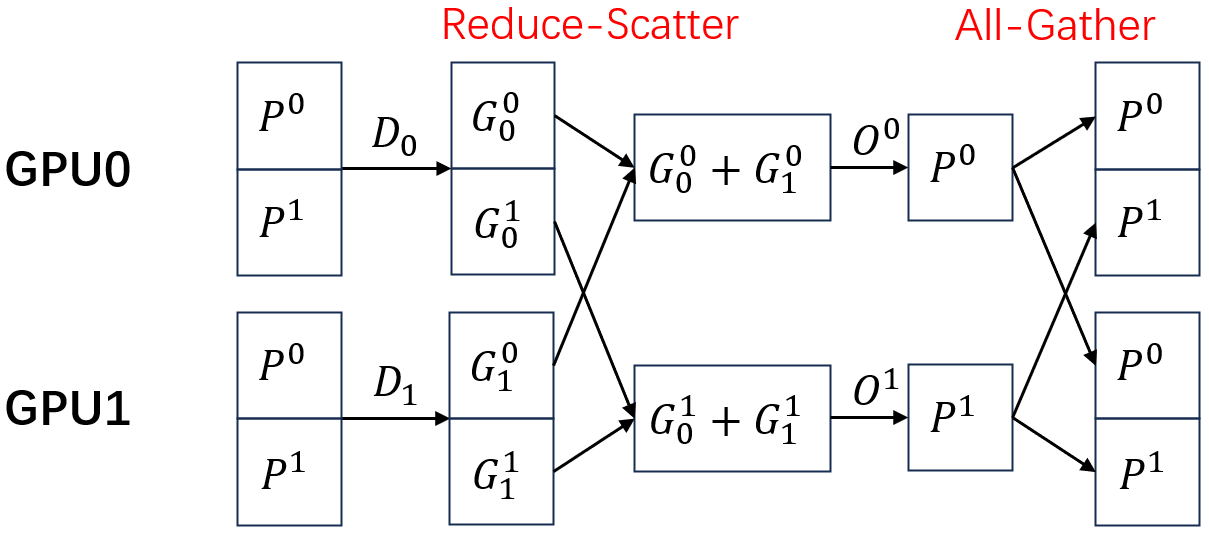
和的通信量相同。在前向,每个GPU都能计算完整的梯度。在反向,需要对梯度进行reduce-scatter,每个GPU对自己的部分梯度进行聚合,使用自己的优化器得到参数。最后再对参数进行all-gather发给每个GPU。总的通信量为,和传统DP是一样的。
的通信开销
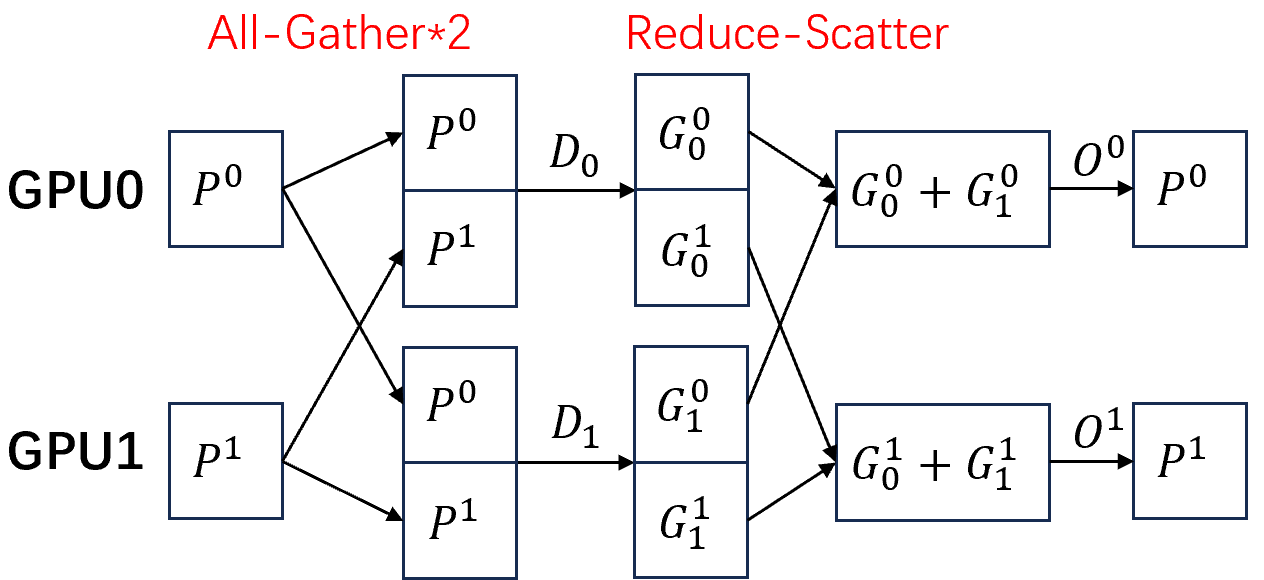
接着考虑对模型参数进行划分。在前向,在一开始额外对参数进行一次all-gather,使每个GPU获取到全部的参数。在反向,依然对梯度进行reduce-scatter。
注意到模型有很多层。在前向,在我们使用了一层的全部参数计算完成后,我们可以直接释放掉这些参数的显存,接着算后面的层,防止这些参数一直占用着显存。但这样的话,在反向,我们需要再进行一次all-gather重新获得这一层的参数才行。因此,总的通信量是。
| 欢迎来原网站坐坐! >原文链接<



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架