
【hadoop】MapReduce分布式计算框架原理
PS:实操部分就省略了哈,准备最近好好看下理论这块,其实我是比较懒得哈!!!
<?>MapReduce的概述
MapReduce是一种计算模型,进行大数据量的离线计算。
MapReduce实现了Map和Reduce两个功能:
其中Map是滴数据集上的独立元素进行指定的操作,生成键——值对形式中间结果。
其中Reduce则对中间结果中相同“键”的所有“值”进行规约(分类和归纳),以得到最终结果。
<?>如何进行并行分布式计算?
并行计算(如SPARK)
是相对于串行计算而言,一般可分为时间并行和空间并行。时间并行可以看做是流水线操作,类似CPU执行的流水线,而空间并行则是目前大多数研究的问题,例如一台机器拥有多个处理器,在多个CPU上执行计算,例如MPI技术,通常可分为数据并行和任务并行。
分布式计算(如HADOOP)
是相对单机计算而言的,利用多台机器,通过网络连接和消息传递协调完成计算。把需要进行大量计算的工程数据分区成小块,由多台计算机分别计算,再上传运算结果后,将结果统一合并得出最终结果。
<?>如何分发待处理数据?
在大规模集群环境下,如何解决大数据的划分、存储、访问管理
<?>如何处理分布式计算中的错误?
* 大数据并行计算系统使用,因此,节点出错或失效是常态,不能因为一个节点失效导致数据丢失、程序终止或系统崩溃。因此,系统需要有良好的可靠性设计和有效的失效检测和恢复计算。
* 设1万个服务器节点,每个服务器的平均无故障时间是1千天,则平均每天10个服务器出错!
<?>MapReduce是什么?
* 一种编程模型:不是一门语言,是一个模型
* 处理大数据集
* 部署于大规模计算机集群
* 分布式处理方式
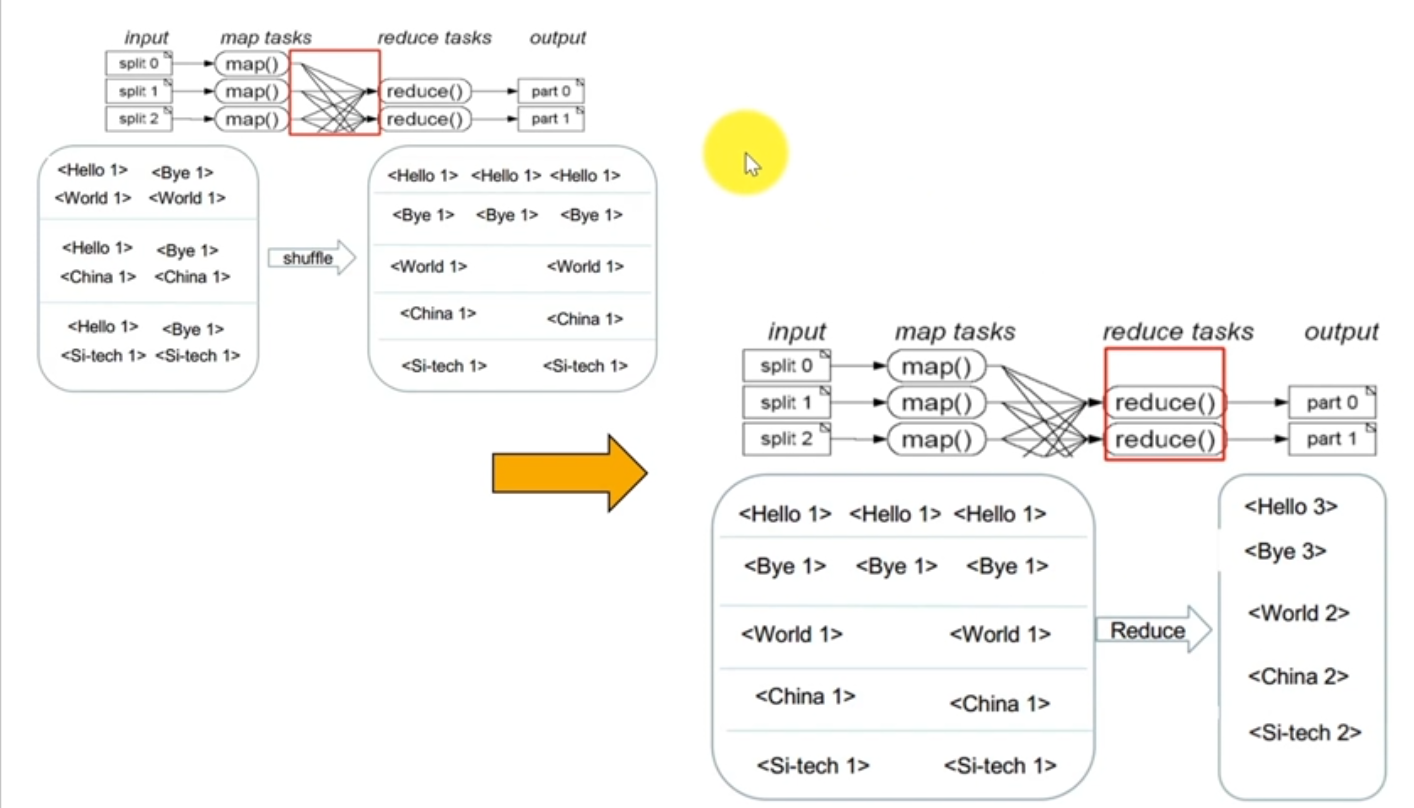
MapReduce核心代码:
输入数据:
hello word bye world
hello china bye china 经过mapreduce处理后 :hello:3,bye:3,word:2,china:2,chongqing:2
hello chongqing bye chongqing
Map核心代码:
Map(Key,Value){
for(each word ‘word’ in value)
collect(‘word’,1);
}
Reduce核心代码:
Map(Key,Value[]){
int count=0;
for(each w in value)
count++;
collect(Key,count);
}
图解如下:

MapReduce的优势:
1、通过MapReduce这个分布式处理框架,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,比如:自动并行化、负载均衡和灾备管理,这将极大地简化程序员的开发工作
2、MapReduce的伸缩性非常好,也就是:每增加一台服务器,就能将差不多的计算能力接入到集群中,而过去大部分分布式处理框架,在伸缩性方面都与MapReduce相差甚远
MapReduce的不足:
1、不适合事务/单一请求处理
MapReduce绝对是一个离线批处理系统,对于批处理数据应用的很好,MapReduce(不论是Google的还是Hadoop的)是用于处理不适合传统数据库的海量数据的理想技术,但它又不适合事务/单一请求。(Hbase使用了来自Hadoop核心的HDFS,在其常用操作中并没有使用MapReduce)
2、不能随即读取
3、以蛮力代替索引
在索引是更好的存取机制时,MapReduce将劣势尽显
4、low-level语言和操作
“直接开始你想要的 —— 而不是展现一个算法, 解释如何工作的。”(关系型数据库的观点) —— High level(DBMS) “展示数据存取的算法”(Codasyl 的观点)—— Low level (MapReduce)
5、性能问题
想想N 个map实例产生M个输出文件,每个最后由不同的reduce 实例处理,这些文件写到运行map实例机器的本地磁盘。如果N是1000,M是500,map阶段产生500,000个本地文件,当reduce阶段开始,500个reduce实例每个需要读入1000个文件,并用类似FTP协议把它要的输入文件从map实例运行的节点上pull取过来,假如同时有数量级为100的reduce实例运行,那么2个或者2个以上的reduce实例同时访问一个map阶段来获取输入文件是不可避免的——导致大量的硬盘查找,有效的硬盘运转速度至少降低20%。
6、仅提供了现在DBMS功能的一部分
作为用于分布式处理的算法技术,MapReduce不是数据库,不支持索引、数据更新、事务及完整性约束,且与多数DBMS工具不兼容。
7、不适合一般的web应用
大部分的web应用,只是对数据进行简单的访问,每次请求处理所耗费的资源其实非常小,它的问题是高并发,所以采用负载均衡技术来分担负载。只有当特殊情况下,比如建索引、进行数据分析等,才可能用MR.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号