

【idea】scala&sbt+idea+spark使用过程中问题汇总(不定期更新)
本地模式问题系列:
问题一:会报如下很多NoClassDefFoundError的错误,原因缺少相关依赖包

Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream at org.apache.spark.SparkConf.loadFromSystemProperties(SparkConf.scala:76) at org.apache.spark.SparkConf.<init>(SparkConf.scala:71) at org.apache.spark.SparkConf.<init>(SparkConf.scala:58) at com.hadoop.sparkPi$.main(sparkPi.scala:9) at com.hadoop.sparkPi.main(sparkPi.scala) Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ... 5 more
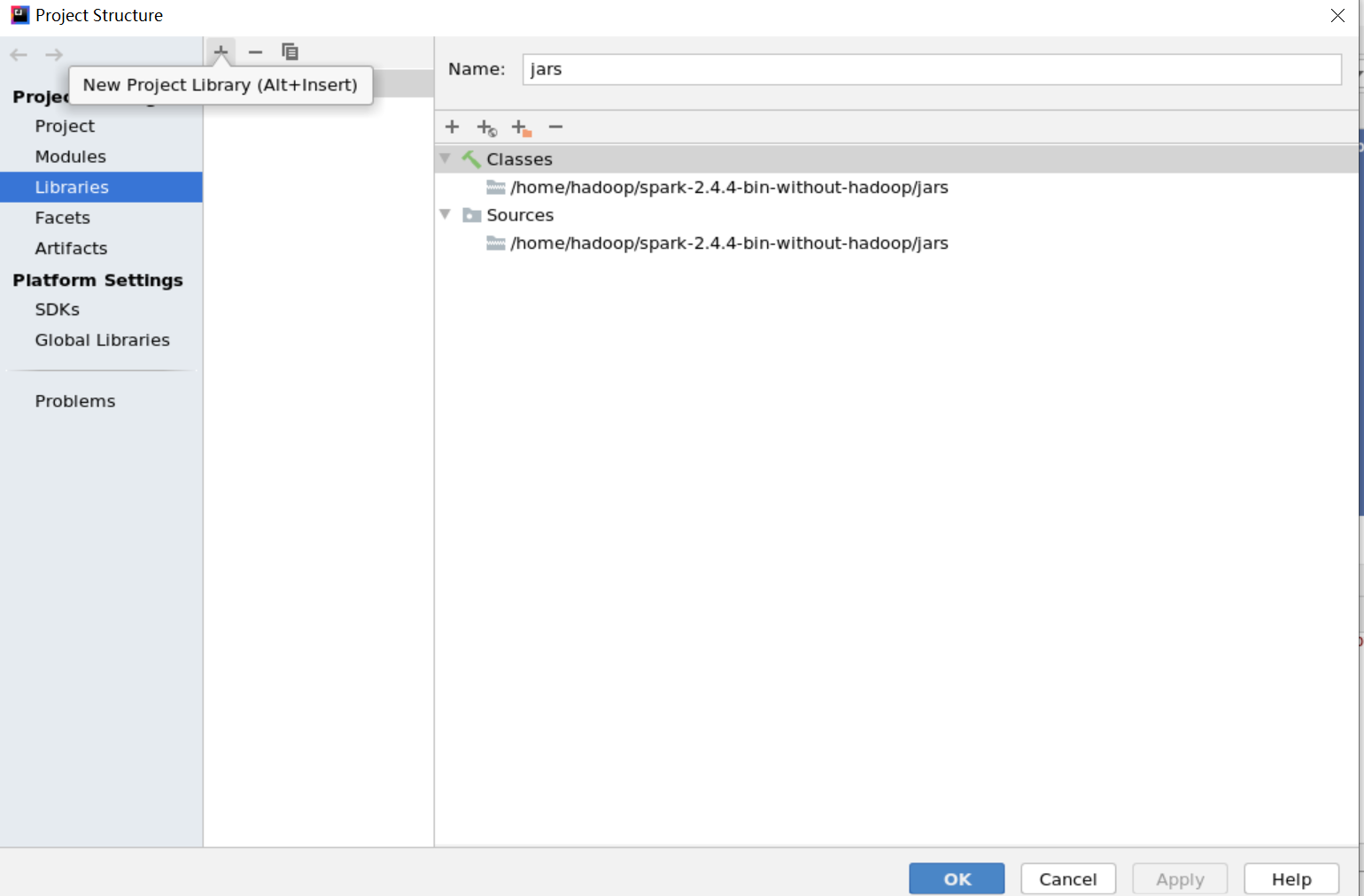
解决办法:下载相关缺少的依赖包,并在idea工程界面加入依赖包,路径为:file -- project structure -- libraries 中,点击左上角“+”符号添加依赖包的路径
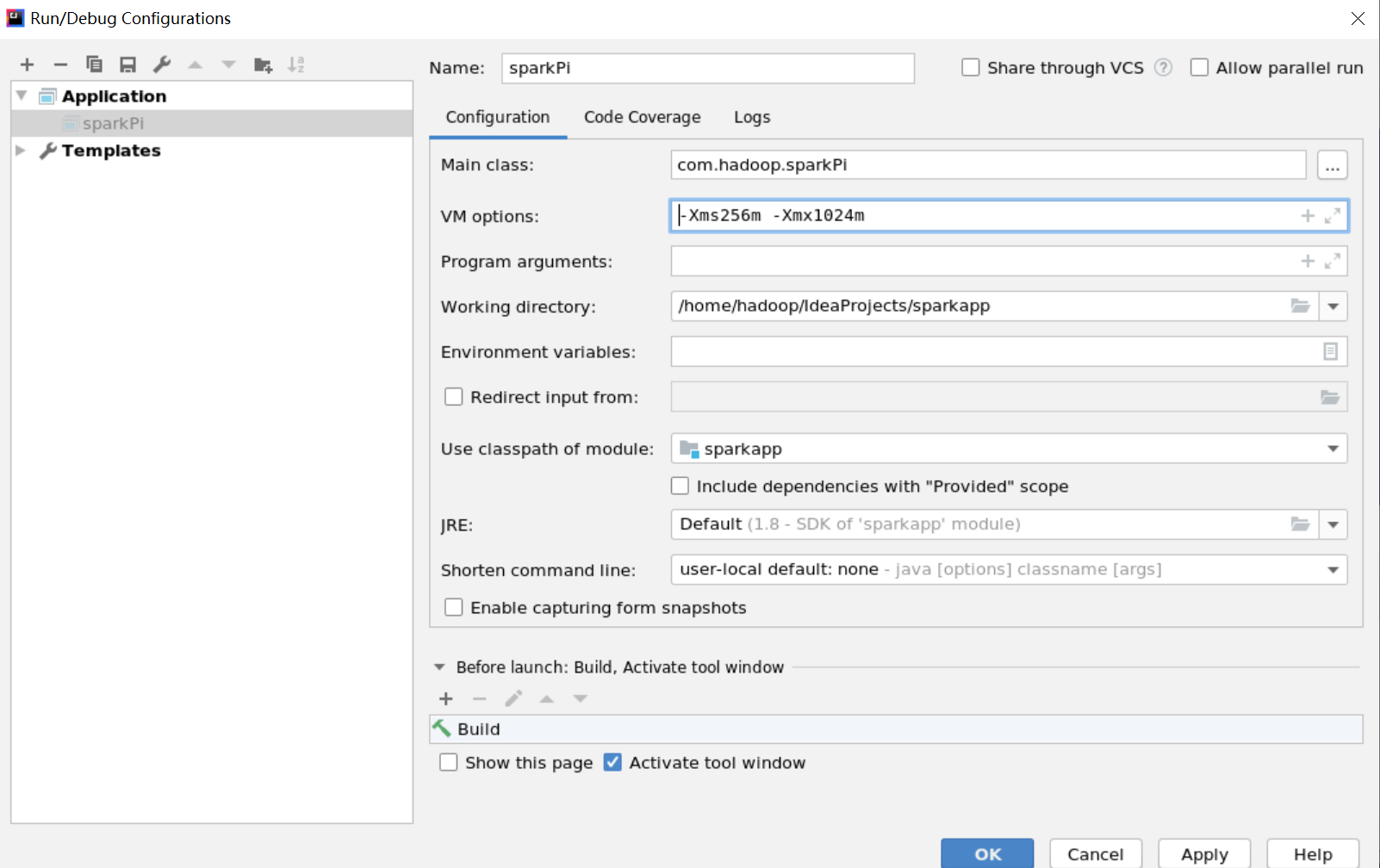
问题二:Spark是非常依赖内存的计算框架,在虚拟环境下使用local模式时,实际上是使用多线程的形式模拟集群进行计算,因而对于计算机的内存有一定要求,这是典型的因为计算机内存不足而抛出的异常。
Exception in thread "main" java.lang.IllegalArgumentException: System memory 425197568 must be at least 471859200.
Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
解决办法:修改代码或者设置-Xms256m -Xmx1024m
val conf = new SparkConf().setMaster("local").setAppName("sparkPi") //修改之前
val conf = new SparkConf().setMaster("local").setAppName("sparkPi").set("spark.testing.memory","2147480000") //修改之后
或
study just for life!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具