正则表达式!
2、正则表达式层次
·基础正则表达式
·扩展正则表达式
3、Linux 中常用的文本处理工具
·grep
·sed
·awk
4、基础正则表达式
是常用的正则表达式部分
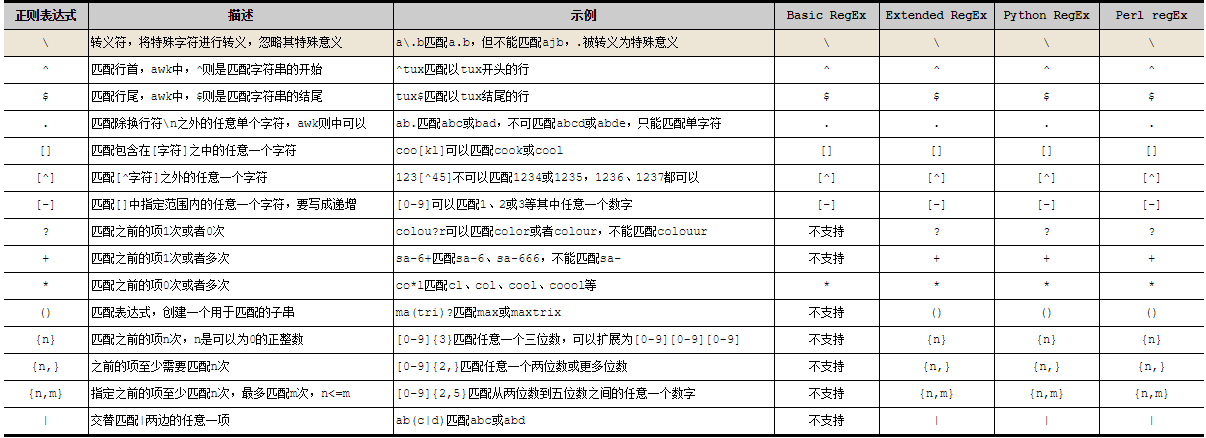
常用元字符:
\ 转义字符。例如:“\!”将逻辑否的!看做普通字符
^ 匹配字符串开始的位置,以…为开头的
$ 匹配字符串结束的位置,以…结束的
. 匹配任意的一个字符
* 匹配前面子表达式 0 词或者多次
[list] 匹配 list 列表中的一个字符,例如:[abc]、[a-z]、[a-z0-9]
[^list] 匹配任意不再 list 表中的一个字符,例如:[^a-z]、[^0-9]、[^A-Z0-9]
\{n\} 匹配前面子表达式 n 次
\{n,\} 匹配前面子表达式至少 n 次
\{n,m\} 匹配前面子表达式最少 n 次,最大 m 次
=============================================================
实例:过滤出文本text中的电话号码
[root@localhost ~]# nl text
1 192.168.200.111
2 2384732984723
3 255.255.255.0
4 192.168.200.255
5 0475-42374873
6 127.0.0.1
7 094320490324
8 255.0.0.0
9 010-4324567
[root@localhost ~]# grep "[0-9]\{3,4\}-[0-9]\{7,8\}" text [0-9]表示0-9的数字 \{3,4\}表示重复3-4次
0475-42374873
010-4324567
============================================================
[root@localhost ~]# sed -n '/$/p' text.txt
gd
god
good
goood
gooood
gold
gaad
abcdEfg
food
60115127Z
HELLO
010-66668888
0666-5666888
IP 192.168.1.108
IP 173.16.16.1
pay $180
打印出包含$的行
[root@localhost ~]# sed -n '/\$/p' text.txt pay $180
[root@localhost ~]# awk '/\$/ {print}' text.txt
pay $180
[root@localhost ~]# grep '\$' text.txt
pay $180
过滤以小字母开头的行
[root@localhost ~]# sed -n '/^[a-z]/p' text.txt gd god good goood gooood gold gaad abcdEfg food pay $180
[root@localhost ~]# grep '^[a-z]' text.txt
gd
god
good
goood
gooood
gold
gaad
abcdEfg
food
pay $180
过滤以数字结尾的行
[root@localhost ~]# grep '[0-9]$' text.txt 010-66668888 0666-5666888 IP 192.168.1.108 IP 173.16.16.1 pay $180
[root@localhost ~]# sed -n '/[0-9]$/p' text.txt
010-66668888
0666-5666888
IP 192.168.1.108
IP 173.16.16.1
pay $180
[root@localhost ~]# awk '/[0-9]$/{print}' text.txt
010-66668888
0666-5666888
IP 192.168.1.108
IP 173.16.16.1
pay $18
过滤go与d之间的字符
[root@localhost ~]# sed -n '/go。d/p' text.txt good gold
[root@localhost ~]# grep 'go.d' text.txt
good
gold
[root@localhost ~]# awk '/go.d/{print}' text.txt
good
gold
过滤出电话号码
[root@localhost ~]# sed -n '/[0-9]\{3,4\}-[0-9]\{7,8\}/p' text.txt 010-66668888 0666-5666888
[root@localhost ~]# grep '[0-9]\{3,4\}-[0-9]\{7,8\}' text.txt
010-66668888
0666-5666888
过滤出ip地址
[root@localhost ~]# sed -n '/[0-9]\{3\}\.[0-9]\{2,3\}\.[0-9]\{1,2\}\.[0-9]\{1,3\}/p' text.txt IP 192.168.1.108 IP 173.16.16.1
[root@localhost ~]# grep '[0-9]\{3\}\.[0-9]\{2,3\}\.[0-9]\{1,2\}\.[0-9]\{1,3\}' text.txt
IP 192.168.1.108
IP 173.16.16.1
=============================================================================
5、扩展正则表达式
是多对基础正则表达式的扩充深化
扩展元字符:
+ 匹配前面子表达式 1 次以上
? 匹配前面子表达式 0 次或者 1 次
() 将括号中的字符串作为一个整体
| 以或的方式匹配字条串
[root@localhost ~]# sed -n '/$/p' text.txt
gd
god
good
goood
gooood
gold
gaad
abcdEfg
food
60115127Z
HELLO
010-66668888
0666-5666888
IP 192.168.1.108
IP 173.16.16.1
pay $180
过滤出字母 g 与 与 d 之间至少有 1 个字母 o 的行 : [root@www ~]# egrep go+d test.txt [root@www ~]# awk '/go+d/{print}' test.txt god good goood gooood 过滤出 字母 g 与 与 d 之间 没有字母 o 或只有 1 个 个 o 的行 : [root@www ~]# egrep go?d test.txt [root@www ~]# awk '/go?d/{print}' test.txt gd god 过滤出字母 g 与 与 d 之间两个字母 o 一起出现至少 1 次的行: [root@www ~]# egrep "g(oo)+d" test.txt [root@www ~]# awk '/g(oo)+d/{print}' test.txt good gooood 过滤出字母 g 与 与 d 之间是 la 或者是 aa

