
大数据应用期末总评Hadoop综合大作业
2019-06-12 10:38 CMis180kg 阅读(1191) 评论(0) 收藏 举报作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
1.将爬虫大作业产生的csv文件上传到HDFS
此次作业选取的是爬虫《人性的弱点全集》短评数据生成的cm.csv文件;爬取的数据总数为10991条。
cm.csv文件数据如下图所示:
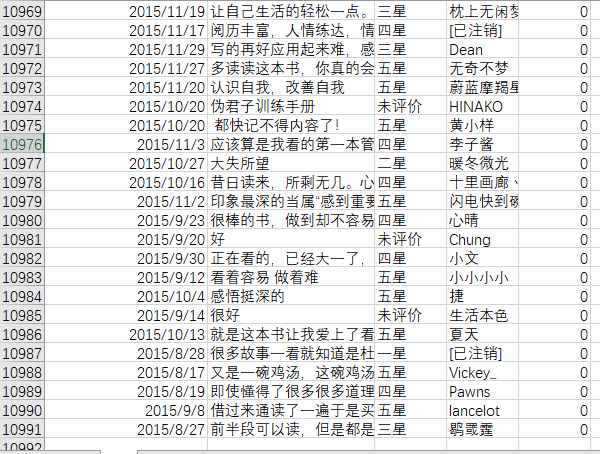
将cm.csv文件上存到HDFS
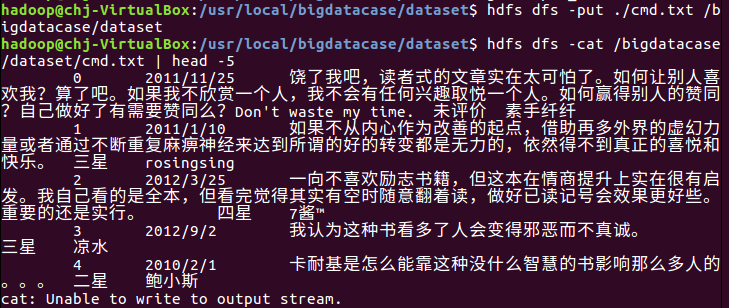
2.对CSV文件进行预处理生成无标题文本文件
csv文件数据预处理,删除第一行字段名称

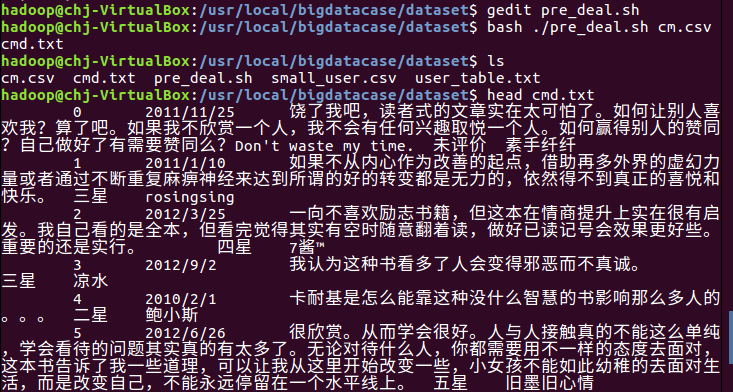
编辑pre_deal.sh文件进行数据的取舍处理

让pre_deal.sh文件生效,并显示前面几条数据
3.把hdfs中的文本文件最终导入到数据仓库Hive中
在hive中创建bdlab数据库,显示如下:

因为此次使用的是bdlab的数据库,所以在bdlab中创建相应的表为bigdata_cmd

4.在Hive中查看并分析数据
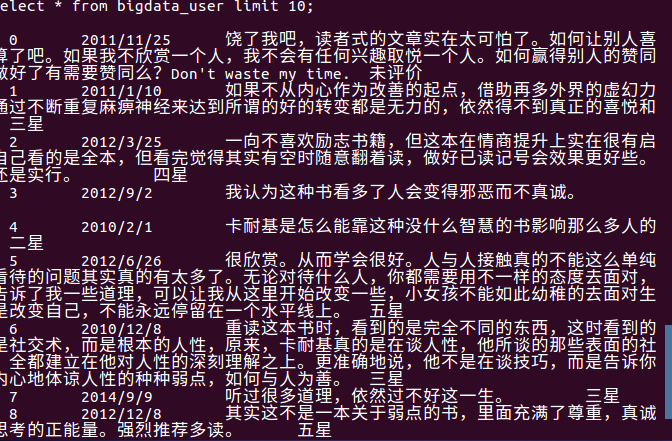
数据分析:图上显示,该爬取的数据属性主要包括评价的日期、评价的内容、用户名称和星级(一些无关分析的属性在进行数据预处理的时候已经去除,剩下的是有关数据分析的属性)。以上显示的数据可以看到一些读者对《人性的弱点全集》这本书的一些好的坏的态度。以下利用Hive进行更进一步的数据分析。
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
(1)查询前20条用户的星级评价
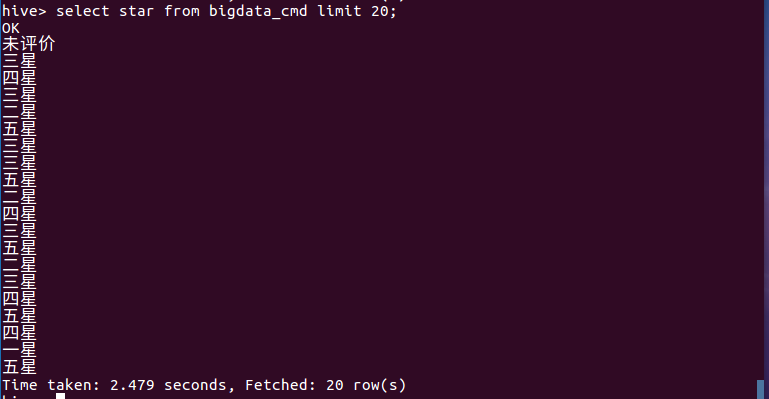
分析:上图所示的查询内容显示,评星三星以上的占较大的一部分;四星、五星的总占比约占一半(五星为满星),这说明读者们对于《人性的弱点全集》这本书的评价还是算中上等水平的,这也从侧面反映出该书是一本不错的书。
(2)查询读者给该书一星评星的短评


分析:上图所示的查询内容显示,读者们给该书评一星的原因是读者们认为这本书一味的励志,一味的给读者灌输一些通俗易懂却光说不练的道理,过于的心灵鸡汤。这是读者们反感它的地方以及给出一星评价的原因。
(3)查询读者给该书三星(即中评,不喜不厌的态度)评星的短评


分析:上图所示的查询内容显示,读者们认为该书的内容是有用的,对于人的成长也是有一定的帮助的,但是对于书本推销式的表达方式读者还是略显反感;整本书读下来也略显枯燥。这些都是读者们评三星的不喜不厌的原因。
(4)查询读者给该书五星评星的短评

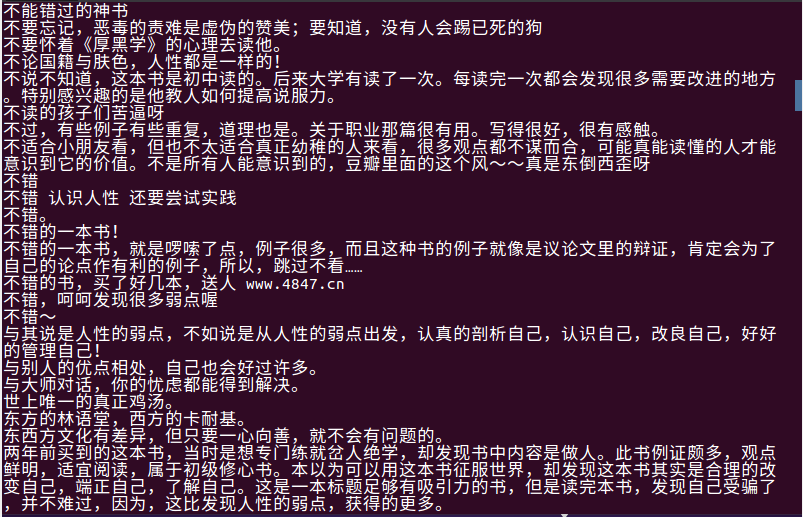

分析:上图所示的查询内容显示,读者们给该书评五星的原因是读者们认为这是一本不错的书,也非常的经典,能给人深省和能读懂一些道理会让读者有一些感触,是值得一看的经典之书。所以读者买账的地方可能就是该书能给读者带来一些感触反省和一些道理。
(5)查询读者高评星与低评星数量(高低评星以三星为界限)
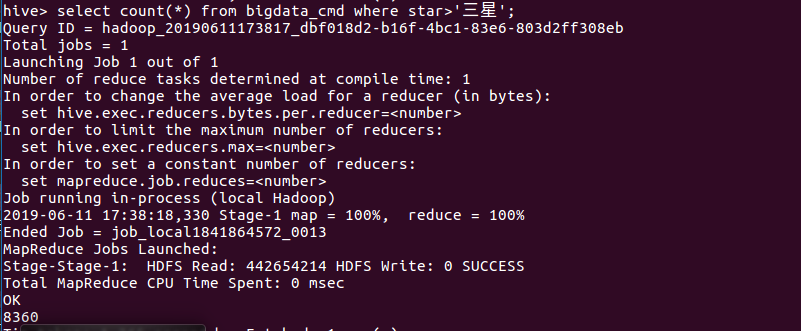
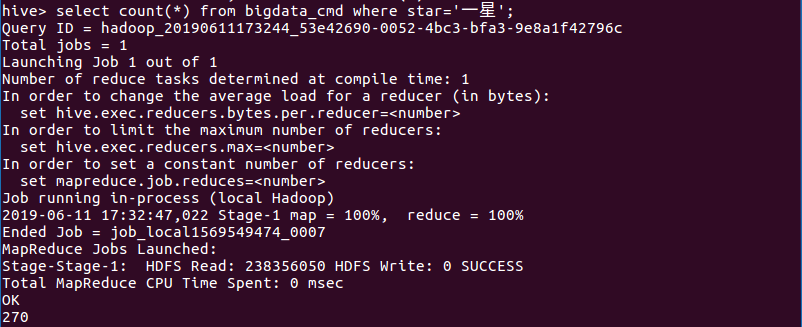

分析:上图所示查询内容显示,高评星(4星、5星)的数量为8360条,低评星(1星、2星)的数量为722条。从数量上比较可以知道读者对于《人性的弱点全集》这本书大体是持好的敏感度的,大多的读者认为这是一本好书,总体的评价也是好的趋向的。
(6)查询评五星的用户名


(7)查询cm.csv文件数据中用户名不重复的数据量

分析:上图所示查询内容显示,用户名不重复评论的数据为4958条,差不多占数据量的一半,说明爬取的数据中因用户名重复的数据还是较多的,也说明的是同一个用户有过多次评论的可能,衍生的一个可能是同一个用户名的用户不同时间多次阅读该书从而发表的不同的评价;如果是这个可能同一个用户评论的内容也还是拥有参考价值的,但是还是要注意过多的数据重复。
(8)查询cm.csv文件数据中评论不重复的数据量

分析:上图所示查询内容显示,评论内容不重复的数据为5627条,占爬取总数据的一半往上。说明有5627条读者评论数据不存在重复,可用性的数据量还是较大的;较大的可用性数据量在做数据分析的时候是能够更准确的把握读者的对该书的态度和总体的评价的,所以此次的可用性数据和此次的数据分析是有一定的意义和参考价值的。
(9)查询读者给该高评价的短评



分析:上图所示查询内容显示,让人受益匪浅、启发、励志、实用和值得深思等是读者给该书高评价的原因,这些都是读者买该书账的地方。一个繁杂的社会、一个谁都不容易的社会氛围需要一些正面的东西来给人们一些前进的力量,读者可能可以在书中找到内心共鸣的地方所以喜欢这本书也所以给该书高的评价。
(10)查询三星评价数量
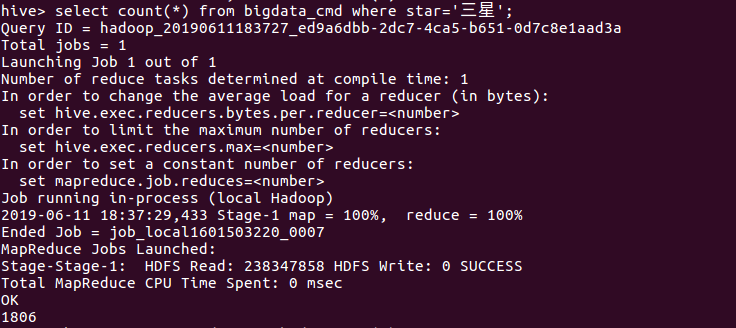
分析:上图所示查询内容显示,三星评价的数据量为1806条,约占总数据量的10%,比例不大;这也说明有将近一成的读者对于《人性的弱点全集》这本书不感冒。
(11)查询五星评价处于表格的序号


以上为此次Hadoop综合大作业的所有内容。从Ubuntu到MySQL到Hadoop到hbase到hive再到整个Hadoop整个环境的配置完成,这一路下来都是为最后的这个综合作业做准备。这期间,遇到过这个系统环境安装配置好到进不去hive,遇到过输入法的输入出错,遇到过格式化丢失Datanode等一系列的问题;这个过程必须是细心谨慎的,要不就是一步错后面就会卡死无法进行下去。学了几次这些内容,这次是比较有条理的一次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号