
理解爬虫原理
2019-03-27 13:39 CMis180kg 阅读(210) 评论(0) 收藏 举报作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2851
1. 简单说明爬虫原理
通用程序模拟浏览器请求站点的行为,采集信息,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
第一步 :发送请求 第二步:获取响应内容 第三步:解析内容 第四步:保存数据
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
HTTP协议的工作原理:
a)连接:Web浏览器与Web服务器建立连接,打开一个称为socket(套接字)的虚拟文件,此文件的建立标志着连接建立成功。
b)请求:Web浏览器通过socket向Web服务器提交请求。HTTP的请求一般是GET或POST命令(POST用于FORM参数的传递)。GET命令的格式为:GET 路径/文件名 HTTP/1.0。文件名指出所访问的文件,HTTP/1.0指出Web浏览器使用的HTTP版本。
c)应答:Web浏览器提交请求后,通过HTTP协议传送给Web服务器。Web服务器接到后,进行事务处理,处理结果又通过HTTP传回给Web浏览器,从而在Web浏览器上显示出所请求的页面。
d)送GET命令: GET /mydir/index.html HTTP/1.0。主机名为www.mycomputer.com的Web服务器从它的文档空间中搜索子目录mydir的文件index.html。如果找到该文件,Web服务器把该文件内容传送给相应的Web浏览器。
e)关闭连接:当应答结束后,Web浏览器与Web服务器必须断开,以保证其它Web浏览器能够与Web服务器建立连接。
2).使用 requests 库抓取网站数据;
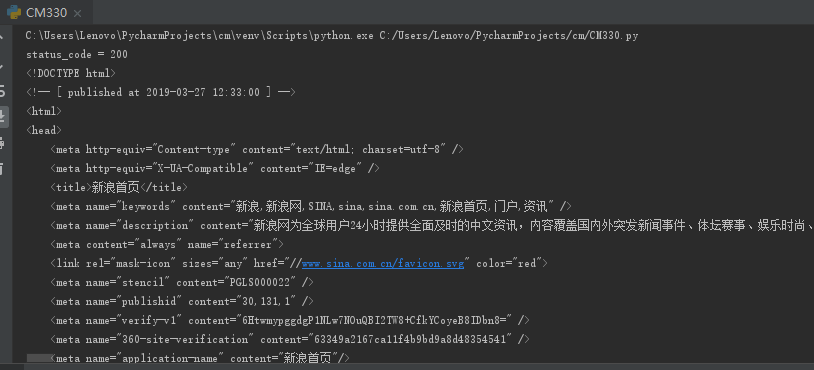
requests.get(url) 获取校园新闻首页html代码
import requests url='https://www.sina.com.cn/' res = requests.get(url) print("status_code = {}".format(res.status_code)) type(res) res.encoding='utf-8' print(res.text)
执行结果如下图所示:
3).了解网页
写一个简单的html文件,包含多个标签,类,id
html_sample = ''' <html> <head> <h1 id="title">标题</h1> </head> <body> <div> <p1>段落<p1><br> <a href="http://www.baidu.com" >百度</a> </div> </body> </html>
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
a=soup.select('h1')[0].text print(a)
找出含有特定类名的html元素
for i in range(len(soup.select('.link'))): b=soup.select('.link')[i].text print(b)
找出含有特定id名的html元素
c=soup.select('#title')[0].text print(c)
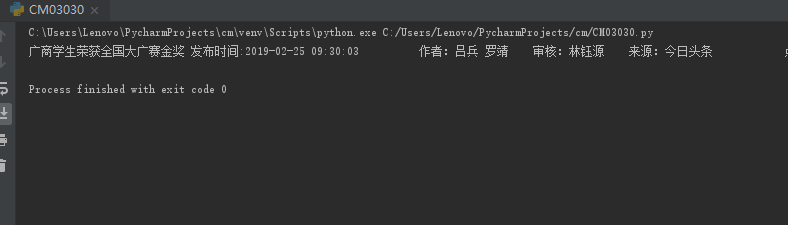
3.提取一篇校园新闻的标题、发布时间、发布单位
import requests from bs4 import BeautifulSoup url='http://news.gzcc.cn/html/2019/meitishijie_0225/10895.html' res=requests.get(url) res.encoding='utf-8' soup1=BeautifulSoup(res.text,'html.parser') a=soup1.select('.show-title')[0].text b=soup1.select('.show-info')[0].text print(a,b)
执行效果如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号