Lossless Recompression of JPEG Images Using Transform Domain Intra Prediction
简介
\(\quad\)JPEG图像编码格式由于其简单高效在各种设备和网站上被广泛使用,随着互联网的发展和移动设备的普及大量用户生成的JPEG图像被上传到各社交网站或者储存在个人设备上。以上原因导致图像储存成本的增加。
但JPEG与性能与最先进的编码方法相差甚远。如果能在保存图像原有信息的前提下对这些JPEG图像再压缩,将会缩减储存成本。
该文章提出了一张变换域(DCT系数域)内预测的JPEG图像无损再压缩混合编码框架,框架包括:块划分和内预测、变换、量化以及熵编码。实验结果表明,LLJPEG在Kodak和DIV 2K数据集上的存储空间分别减少了29.43%和26.40%,且对JPEG图像没有任何损失,同时保持了较低的解码复杂度
引入
有损JPEG压缩会导致信息的永久性丢失,在医学研究和刑事犯罪等领域,这是不可接受的。因此该文章关注于JEPG图像的无损再压缩,着力于减少JPEG文件中变换系数(DCT系数)的冗余。
文章贡献
- 与 HEVC 或 VVC 在空间域减少块间冗余不同,LLJPEG 在变换域使用内部预测来减少块间冗余。
- 为提高性能,提出了一些新的内部预测编码工具,如 DC 模式的新决策和内部预测后的滤波(与原数据做差)。此外,还提出了两阶段内部预测模式决策,以降低编码复杂度。
- 重新设计了熵编码,包括变换残差的重组、跳过标志的编码和系数扫描顺序。
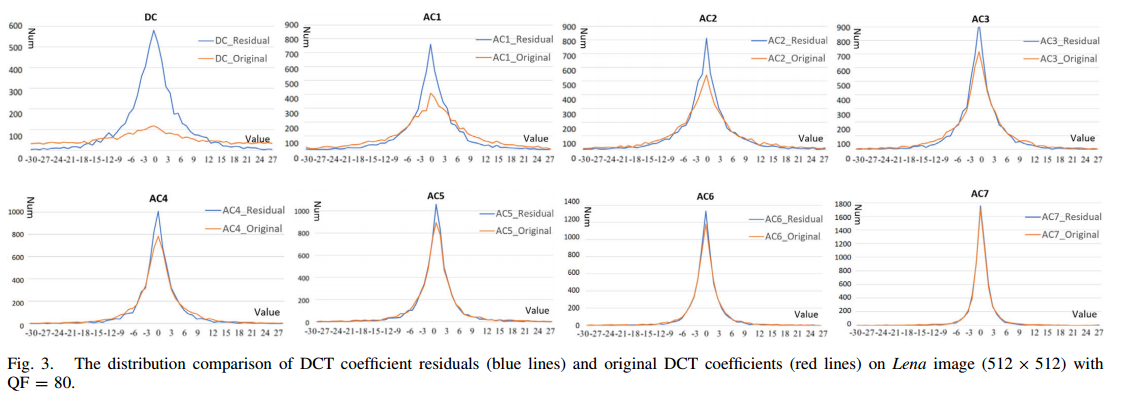
对 DCT 系数残差进行编码比对原始 DCT 系数进行编码更有利于压缩
我们做了以下实验。首先,对于一个 8 × 8 块,有四种模式: 在内部预测中应用 HEVC 中的直流、平面、垂直和水平四种模式,得到四个预测块。然后,对预测块进行 DCT 和量化(基于从 JPEG 文件中提取的量化表),得到预测的 DCT 系数块。然后,从相应的原始系数中减去每个预测 DCT 系数块中的预测 DCT 系数,得到四个 DCT 系数残差块。最后,选出平方误差之和最小的 DCT 系数残差块。其分布如图 3 所示,。可以看出,DCT 系数残差的分布更集中在 0 处,更有利于压缩。
模型框架
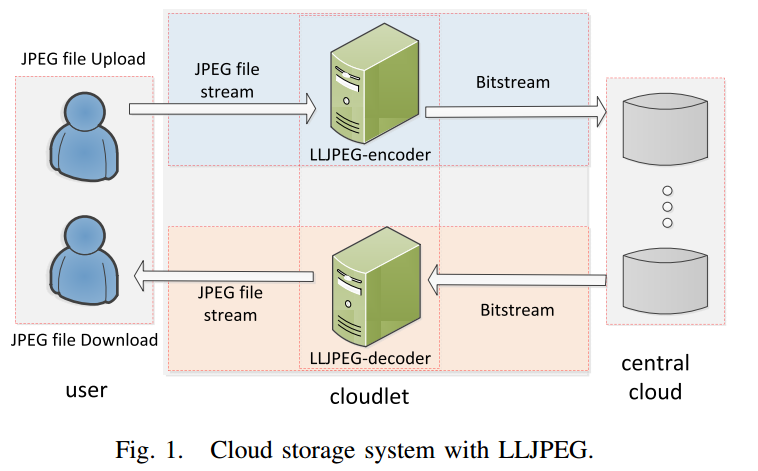
模型的应用场景
作为一个贴在云外部的外接软件,将云上存储的图像进一步压缩。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号