Sora文本生成视频模型
参考openAi提供的技术文档:https://openai.com/research/video-generation-models-as-world-simulators
简介
Sora 是一种通用的视觉数据模型,它可以生成跨越不同持续时间、纵横比和分辨率的视频和图像,最多可生成一整分钟的高清视频。
训练过程
Sora在大规模数据以及大量算力的支持下,产生了惊人的效果。
将可视化数据转化为patch
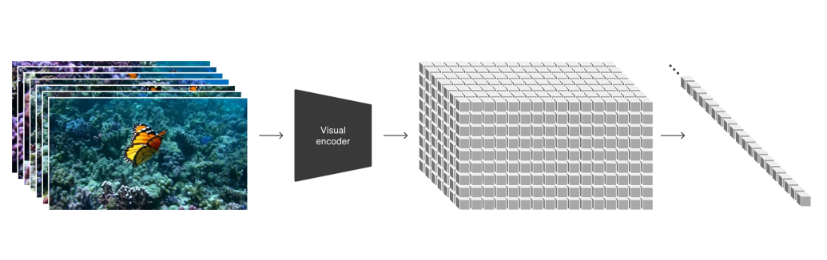
首先将视频数据转化为低维空间中的patches,然后将这种表示分解为timespace patches(具体如何分解的)。训练了一个编码器,它以原视频为输入,将其输出为空间上和时间上都被压缩的潜在表示。
然后Sora在潜在表示的空间上进行训练,并生成视频。(Sora作为扩散模型,对于给定的提示信息,它被用来训练产生相关的以及拓展的patches)
Sora将一系列的时空区块patches当做一个个的token,这种方法可以使Sora可以针对不同分辨率、持续时间和纵横比的视频和图像进行训练和内容生成。
使用不同分辨率、持续时间及纵横比的视频数据的优势
- 采样灵活性: Sora 可以直接以原始纵横比为不同设备创建内容。并且在生成全分辨率内容潜可以以小尺寸快速制作内容原型。
- 改进的取景和构图 如果将所有训练视频裁剪为正方形,那有时生成的视频内容会仅显示主体而忽略取景和构图。
与DALL-E3类似,我们还利用 GPT 将简短的用户提示转换为更长的详细字幕,然后发送到视频模型。这使 Sora 能够准确遵循用户提示生成高质量的视频。
另外还训练了相应的解码器模型,它可以将这种潜在表示重新映射回原像素空间。
关键点
- 语言理解:为了训练文本到视频生成系统,需要大量的视频和相应的文本标题。研究者们应用了在 DALL·E 3 中引入的重新描述技术,首先训练一个高度描述性的标题生成器,然后为训练集中的所有视频生成文本标题。对高度描述性视频字幕的培训可以提高文本保真度以及视频的整体质量。
- 模拟能力:当视频模型在大规模训练时,它们展现出了一些有趣的新兴能力,使得 Sora 能够模拟物理世界中的某些方面,如动态相机运动、长期一致性和对象持久性等。
- 尽管 Sora 展示了作为世界模拟器的潜力,但它仍然存在许多局限性,例如对物理规律的描述能力不足。研究者们认为,继续扩展视频模型是构建物理世界通用模拟器的一条有前途的途径。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号