High-Efficiency Lossy Image Coding Through Adaptive Neighborhood Information Aggregation
简介
提高压缩性能和吞吐量的关键因素是在变换和熵编码两个模块探索自适应邻域信息聚合。
这篇文章的做法是:在特征提取的变换阶段引入注意力机制,并在解码阶段使用多阶段上下文模型(可学习通道分组+改进的棋盘模型)。得到了比常用方法快60倍的解码速度。
看作者解释为什么要引入注意力机制的:卷积和注意力的组合可以进行更好的内容自适应变换,提取邻域信息。
创新点
- Integrated Convolution and Self-Attention (ICSA) unit
提出集成卷积和自注意力单元,以形成内容自适应变换,动态地描述和嵌入任何输入的邻域信息 - Multistage Context Model (MCM)
多阶段空间上下文模型(改进的棋盘模型),按照预安排的空间通道排序,进行精确的并行概率估计。
作者认为以上两个过程都与邻域信息的使用高度相关。该文章中使用,Adaptive Neighborhood Information Aggregation (ANIA)来提取邻域信息。
内容
本文关注于图像压缩的变换和熵编码阶段
变换函数:希望更充分的利用冗余信息,描述内容自适应的变换(因为不同时间输入图像是不一样的),这种自适应变换能高效的表征邻域分布。自注意机制可以动态地对相邻元素进行加权和聚合,利用该机制可以在一定程度上更好地表征瞬时内容输入。
熵上下文模型:利用邻域依赖安排上下文建模顺序,在提供准确概率估计的前提下,在熵编码过程中进行高效计算。
熵编码过程被设计为通过精准的为每个量化符号的概率分布进行建模来进一步减少统计冗余
Entropy Coding Using Multistage Context Model
如果以光栅扫描的方式进行处理,计算表是非常慢的。因此我们希望设计一种方法,既可以保持自回归模型的性能,还能实现并行处理。
自回归模型的效率来自于利用邻域的因果信息进行条件概率估计,完全忽略邻域之间的相互依赖而只简单的对每个元素独立处理,会损害压缩性能。
借鉴通道上下文模型,[10]《Channel-wise Autoregressive Entropy Models For Learned Image Compression》 和[31]《ElIC:Efficient learned image compression with unevenly grouped spacechannel contextual adaptive coding》
他们[10,31]在均匀分组的特征通道和/或均匀分组的空间邻居中安排上下文预测进行并行概率估计,提出多级上下文模型(MCM)使用不均匀分组处理通道特征。
奇怪的是:(在P6中)作者又说[10]将通道分为相等大小的分组,而[31]则手工将通道分为大小不同的分组。,而自己则是The Cosine slicing is applied to generate groups with variable channels in learning 使用余弦切片法生成可变的通道分组。
模型结构
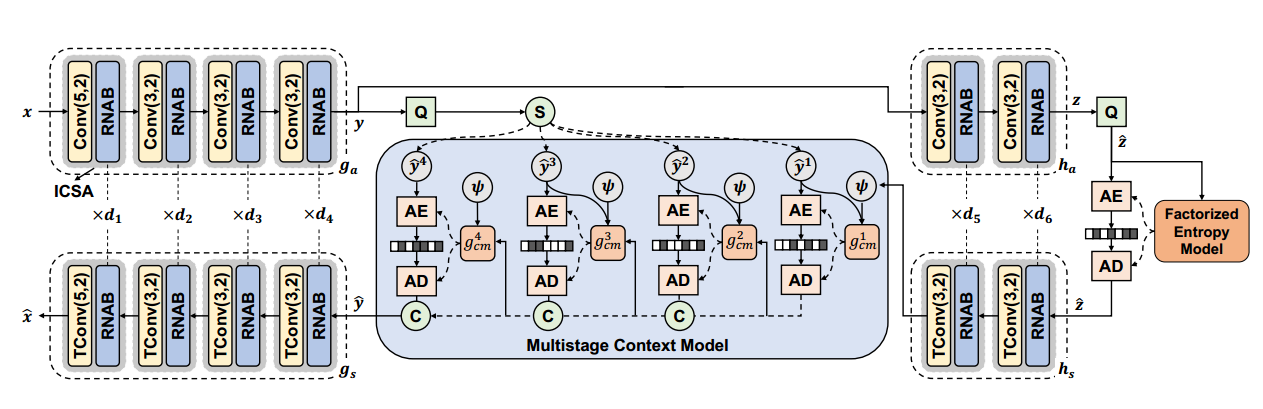
感觉是结合了<不均匀通道上下文模型>和< Swin Transformer>两篇文章
残差邻域注意力块Residual Neighborhood Attention Block RNAB
这里的RNAB设计的和Swin里的设计差不多,残差的 normlization层+注意力层+normalization层+MLP
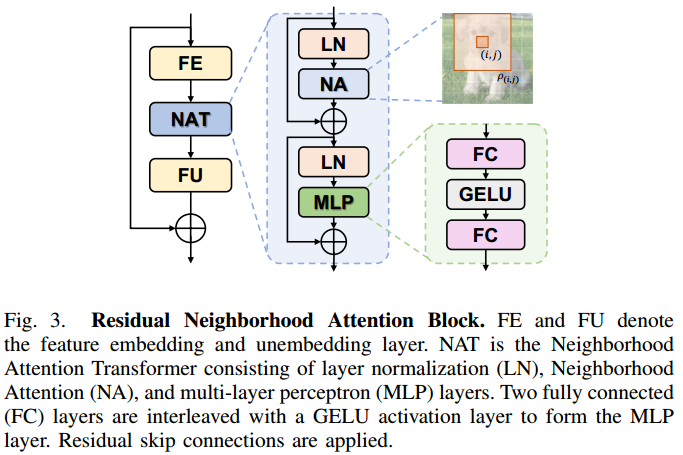
激活函数 高斯误差线性单元激活函数GELU
RNAB中用到了激活函数GELU,谷歌的BERT和OpenAI的GPT-2中都用到了该函数
\(G E L U(x)=x \times P(X<=x)=x \times \phi(x), x \sim N(0,1)\)在代码计算时,用\(G E L U(x)=0.5 x\left(1+\tanh \left(\sqrt{2 / \pi}\left(x+0.044715 x^3\right)\right)\right)\)去近似。
多阶段上下文模型 (MCM)
并行解码
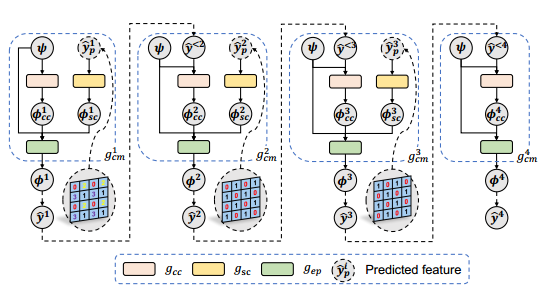
使用余弦切片法,生成可变的分组通道
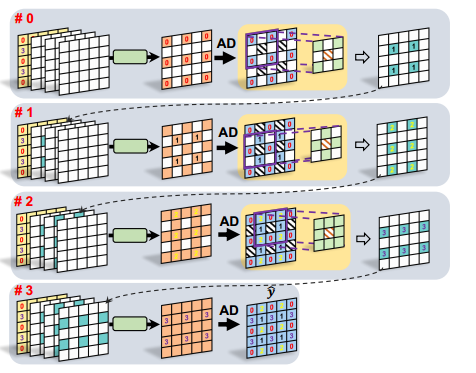
该解码过程也特别想棋盘上下文模型的并行解码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号