ENTROFORMER: A TRANSFORMER-BASED ENTROPY MODEL基于transformer的熵模型
简介
\(\quad\)由于cnn在捕获全局依赖关系方面效率低,因此该文章提出了基于tansformer的熵模型——Entoformer;并针对图像压缩进行了top-k self-attention(自注意力)和菱形相对位置编码(a diamond relative position encoding)的优化;同时使用双向上下文模型加快解码。
1使用具有top-k选择的多头注意来提取表征子空间中的信息
2为了继承cnn的局部偏置,设计了一种新的位置编码单元,为图像压缩提供更好的空间表示。
3使用双解码,使用棋盘模型并行上下文解码。
模型
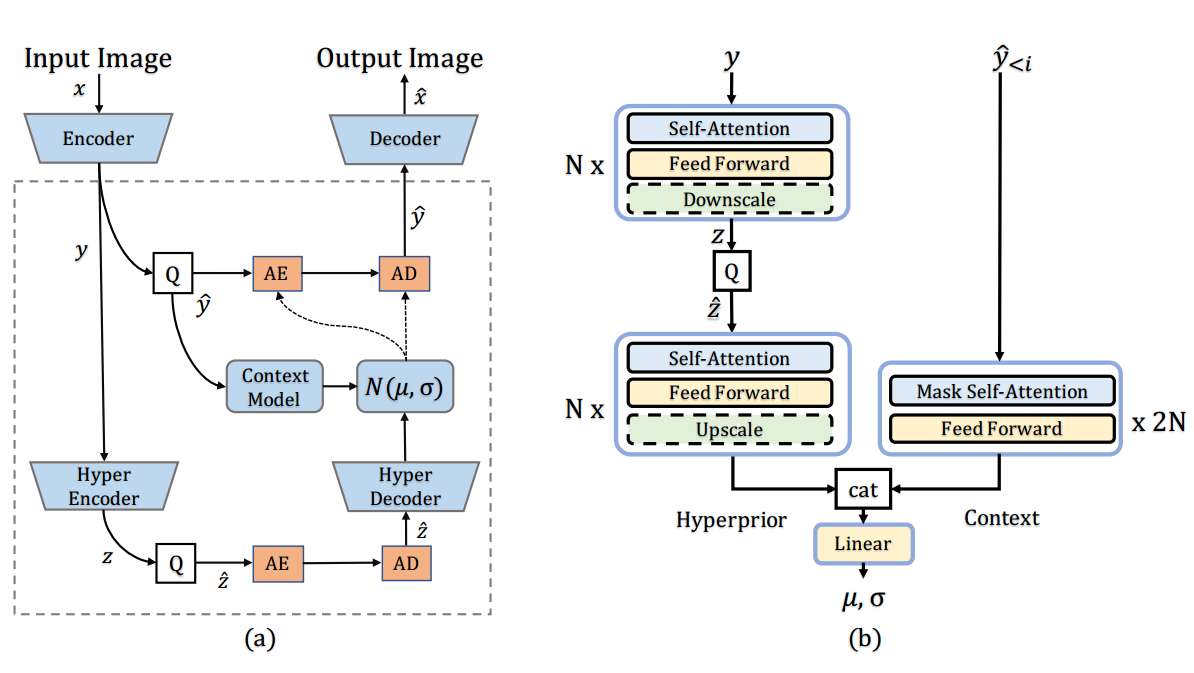
主体的Encoder和Decoder中,沿用了之前的方法encoder和decoder都是CNN。
在概率模型方面,使用了纯Transformer的结构,结合了上下文预测模块(Context Model)和超先验概率模块(Hyperprior)。
损失函数为:
使用高斯模型建模\(\hat y_ i\),其中\(\mu 和 \sigma\)由熵模型预测,\(\theta\)是熵模型的参数:
在模型中,使用菱形相对位置编码和top—k方法,并将棋盘上下文模型拓展为并行上下文模型
Transformer中使用Self-attention模块来进行特征的学习,形式如下:
其中,X为模块的输入特征,分别为$W^Q ,W^K ,W^V $分别是Query, Key, Value的参数矩阵。
引入Transformer之后,虽然对全局相关性能够更好地建模,但也引入了很多不相关的噪声。为了过滤这部分噪声,我们改进了Self-attention,只选择相似度最高的k个特征。
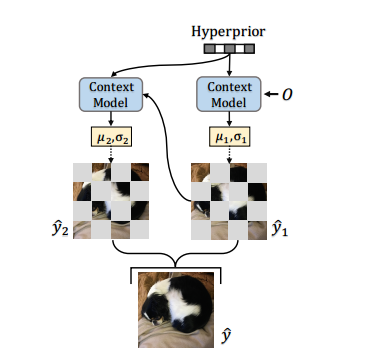
解码时,借鉴了CVPR21的方法(Checkerboard Context Model),在压缩效果和速度性能上进行平衡。
如图所示,压缩特征被分为两部分。第一部分只用hyperprior进行参数的估计。然后第二部分特征用第一部分特征作为context,结合hyperprior进行参数的估计。由于预测第二部分参数时所有context都已可见,所以可以并行计算。
核心代码
使用非参数的完全因子分解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号