VARIATIONAL IMAGE COMPRESSION WITH A SCALE HYPERPRIOR
简介
描述了一个变分自编码器的端到端图像压缩模型。这个模型结合了超先验来捕获潜在表示的空间依赖性,这种超先验涉及到了边信息。并且该模型与底层的自编码器结合一起进行端到端优化。
模型
熵编码依赖于编码器和解码器共享的量化表示的先验概率模型(熵模型)。这种压缩潜在表示的熵模型通常表示为联合分布,甚至全因子分布()。这里要注意区分潜在表示的实际分布和熵模型
实际的分布是数据本身的分布而熵模型则是我们为了逼近实际分布而拟合的。
- 熵模型通常被假定具有某种参数形式,参数和数据匹配
- 边际分布则是一种未知的分布,它既来自于图像的分布,也来自于用来推断替代表示y的方法。
一对编码器-解码器所能达到的最小平均编码长度由两个分布之间的香农交叉熵给出:
在这里,作者认为,边信息可以被看做是熵模型参数的先验,使他们成为潜表示的超先验。
该文章在Ballé et al. (2017)的基础上,加入了超先验,以捕捉潜在表示的空间相邻元素在尺度上趋于共同变化这一事实
量化会带来误差,这在有损压缩中是可以容忍的,从而产生了速率-失真优化问题。速率是压缩表示法的预期编码长度(比特率):假设熵编码技术能有效运行,这又可以写成交叉熵:
在这种情况下,潜在表示的边际分布来自(未知)图像分布 px 和分析变换的属性。失真度是指重建 x^ 与原始图像 x 之间的预期差异,以规范或感知度量。量化的粗糙度,或者说分析和合成变换所隐含的表示的扭曲,会影响速率和失真度,从而导致权衡,即速率越高,失真度越低
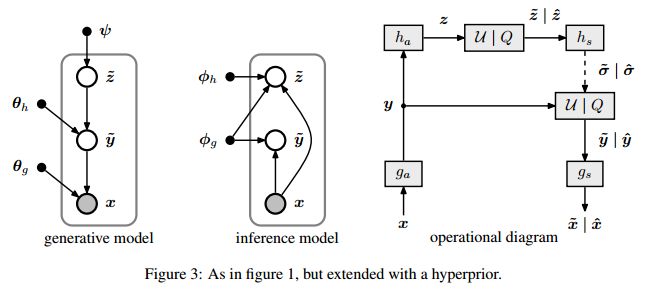
如图3所示,为了捕获潜在表示的空间依赖关系,引入了额外的随机变量z。
每个元素被建模为具有自身标准差的零均值高斯(标准差是通过对应用参数变换来预测的)
我们只需要在y的基础上堆叠另一个参数变换即可以建立一个单联合因子分解变分后验
核心代码
借鉴某位大佬的代码分析:https://blog.csdn.net/qq_42281425/article/details/110918000


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律