Learning Content-Weighted Deep Image Compression
Abstruct 基于学习的像压缩 通常涉及rate-distortion的联合优化,并应对图像内容的空间变化和学习编码间的上下文依赖。大多数深度上下文模型计算成本高,无法有效的对并行符号解码。该文章提出了内容加权的编码器-解码器模型,量化器中采用信道多值量化技术对解码器特征进行离散化,并引入重要性映射自我来生成用于空间变换代码剪枝的重要性掩码。为了压缩编码,文章提出上三角掩蔽卷积网络(triuMCN),用于大上下文模型。
内容加权图形压缩网络(CWIC)包括三个部分:
- 编码器子网络 (包括共享部分和特定编码部分)
- 重要性映射子网络
- 解码器子网络
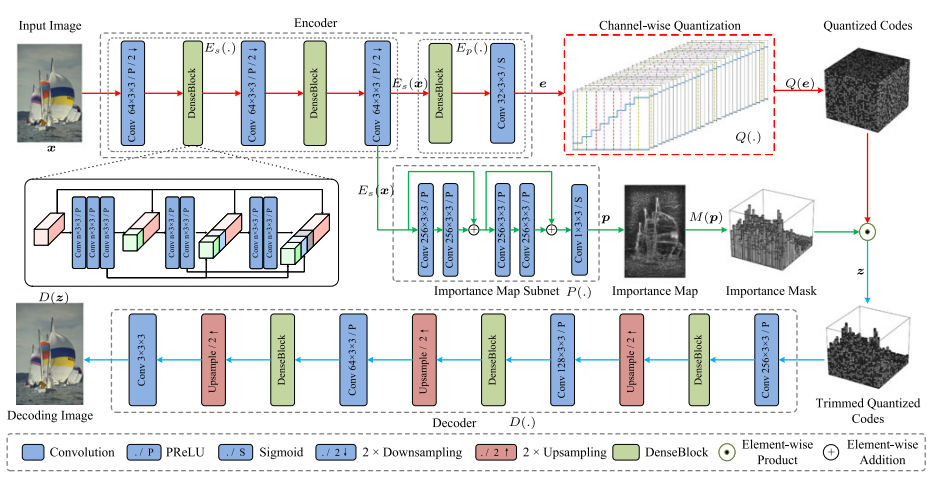
为了生成离散编码,编码器和重要性映射子网络的输出进行了量化操作。
编码器子网和解码器子网
- 编码器子网E(x)由两部分组成:共享部分和特点编码部分组成
- 解码子网为编码子网的镜像

重要性子网
- 一般来说,图像传递的信息内容在空间上是有差异的。从图 3 中可以看出,有房子的区域比较突出,内容密集,而有天空的区域比较简单,信息含量少。在较低的比特率下,编码器特征图的通道数通常不应过多,以满足比特率限制。
- 因此,这可能会导致在保留突出结构和精细细节方面表现不佳,我们引入了重要性图子网来生成重要性图,以指导空间变化编码剪枝。在重要性图的指导下,为区域房屋分配更多比特、为区域天空分配更少比特是合理的。为此,我们采用了一种空间变化代码剪枝方法,即重要性图值越高,存储的量化表示通道越多
- 如图2所示,他将中间特征图作为输入,包括两个残差块和sigmoid的卷积层。重要性图p和编码器特征图e具有相同的大小为,值为(0,1).
量化
- 对于e,使用通道多值量化Q,参数={,,...,} 表示第k个信道,第t个量化区间的大小.其中T是量化等级。第k个信道,第t个量化中心表示为
第k个信道的元素的量化等级....
整体来说,图像X输入后,得到 -> e和p,特征图e被映射为Q(e),重要性图被映射为二元变量M(p)(重要则为1,不重要则为0),最终编码的结果为z=Q(e)* M(p). z作为解码子网络的输入,最终可将图形重构。
模型学习的量化宽松
如何解决量化带来的0梯度问题?提出两种宽松方法
- 为了放宽特征图的量化,引入基于直通估计的代理函数。
- 为了放宽重要性图的量化,采用两阶段放宽方法。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
2017-10-23 LCA 离线做法tarjan
2017-10-23 运输计划
2017-10-23 括号序列
2017-10-23 秘密信息
2017-10-23 大奖赛
2017-10-23 订单
2017-10-23 摆花