AI-14. 自然语言处理:预训练
14.1. 词嵌入(word2vec)
词向量是用于表示单词意义的向量, 并且还可以被认为是单词的特征向量或表示。 将单词映射到实向量的技术称为词嵌入。然独热向量很容易构建,但它们通常不是一个好的选择。一个主要原因是独热向量不能准确表达不同词之间的相似度,比如我们经常使用的“余弦相似度”,任意两个词源直接的相似度为0.
word2vec工具是为了解决上述问题而提出的。它将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系。(说实话看到这里,我根本想象不到如何映射才能得到这种效果)
word2vec工具包含两个模型,即跳元模型(skip-gram) 和连续词袋(CBOW),由于没有标签所以它们都是自监督模型。
跳元模型:考虑了在给定中心词的情况下生成周围上下文词的条件概率。在跳元模型中,每个词都有两个d维向量表示,用于计算条件概率。更具体地说,对于词典中索引为i的任何词,分别用ui和vi表示其用作中心词和上下文词时的两个向量。
连续词袋模型:类似于跳元模型。与跳元模型的主要区别在于,连续词袋模型假设中心词是基于其在文本序列中的周围上下文词生成的。由于连续词袋模型中存在多个上下文词,因此在计算条件概率时对这些上下文词向量进行平均。
练习:
1:计算每个梯度的计算复杂度是多少?如果词表很大,会有什么问题呢?
答:每次计算梯度O(n)的复杂度,当词表很大时,计算梯度需要大量计算
2:让我们以跳元模型
为例来思考word2vec设计。跳元模型中两个词向量的点积与余弦相似度之间有什么关系?对于语义相似的一对词,为什么它们的词向量(由跳元模型训练)的余弦相似度可能很高?
答:???
14.2. 近似训练
由于softmax操作的性质,上下文词可以是词表中的任意项,上下词出现的条件概率中包含与整个词表大小一样多的项的求和。因此,跳元模型的梯度计算和连续词袋模型的梯度计算都包含求和。不幸的是,在一个词典上(通常有几十万或数百万个单词)求和的梯度的计算成本是巨大的!
为了降低上述计算复杂度,本节将介绍两种近似训练方法:负采样和分层softmax。 由于跳元模型和连续词袋模型的相似性,我们将以跳元模型为例来描述这两种近似训练方法。
负采样这里没太看懂...
层序softmax:使用二叉树,树的每个叶节点表示词表中的一个词。幸运的是,由于二叉树结构,L(wo)−1大约与O(log2|V|)是一个数量级。当词表大小V很大时,与没有近似训练的相比,使用分层softmax的每个训练步的计算代价显著降低.
14.3. 用于预训练词嵌入的数据集
文本数据通常有“the”“a”和“in”等高频词:它们在非常大的语料库中甚至可能出现数十亿次。然而,这些词经常在上下文窗口中与许多不同的词共同出现,提供的有用信息很少。高频词在训练中可能不是那么有用。我们可以对他们进行下采样,以便在训练中加快速度。
练习:
1如果不使用下采样,本节中代码的运行时间会发生什么变化?
答:模型运行慢。
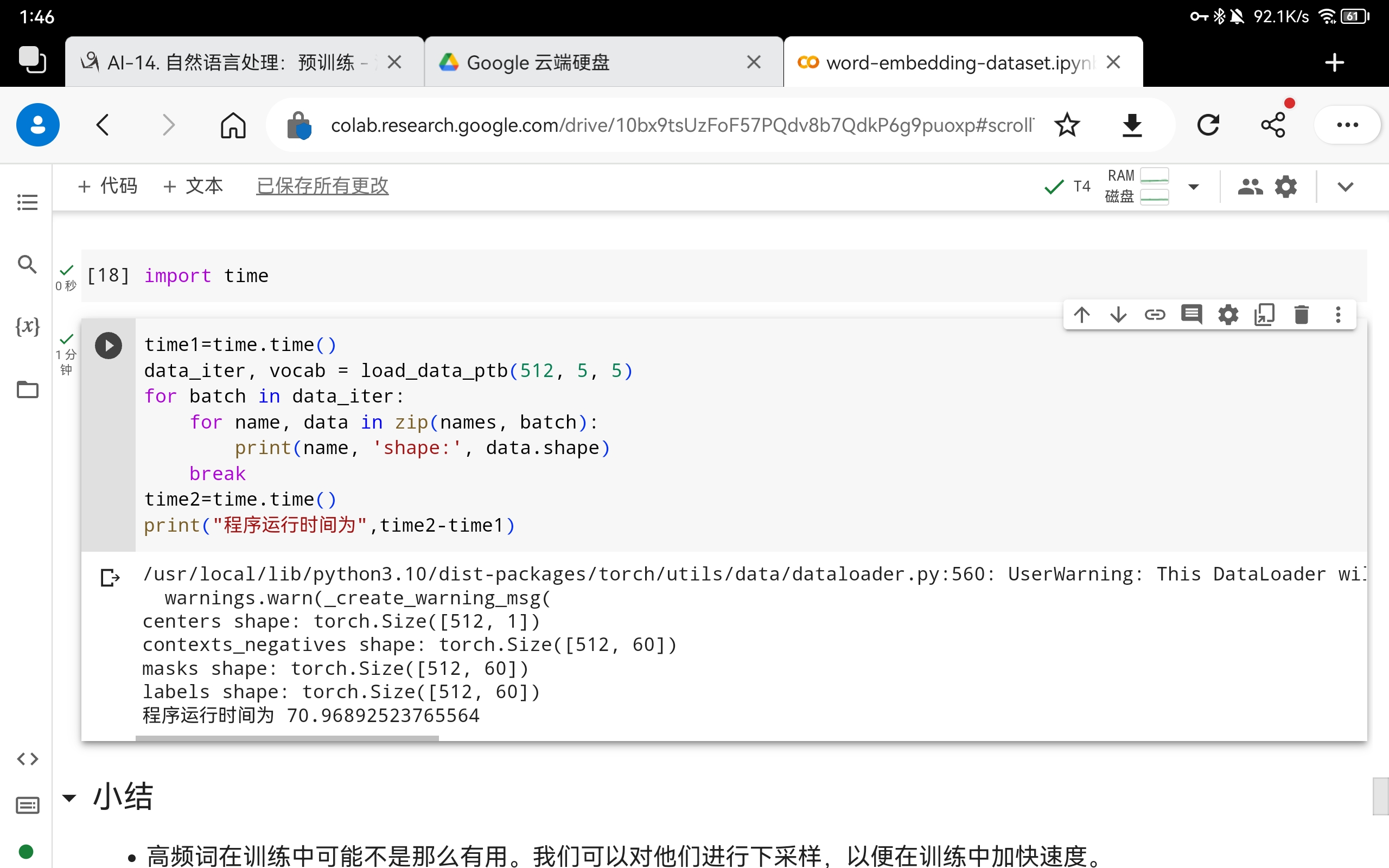
2RandomGenerator类缓存k个随机采样结果。将k设置为其他值,看看它如何影响数据加载速度。
将k减小为100后数据加载时间明显增大
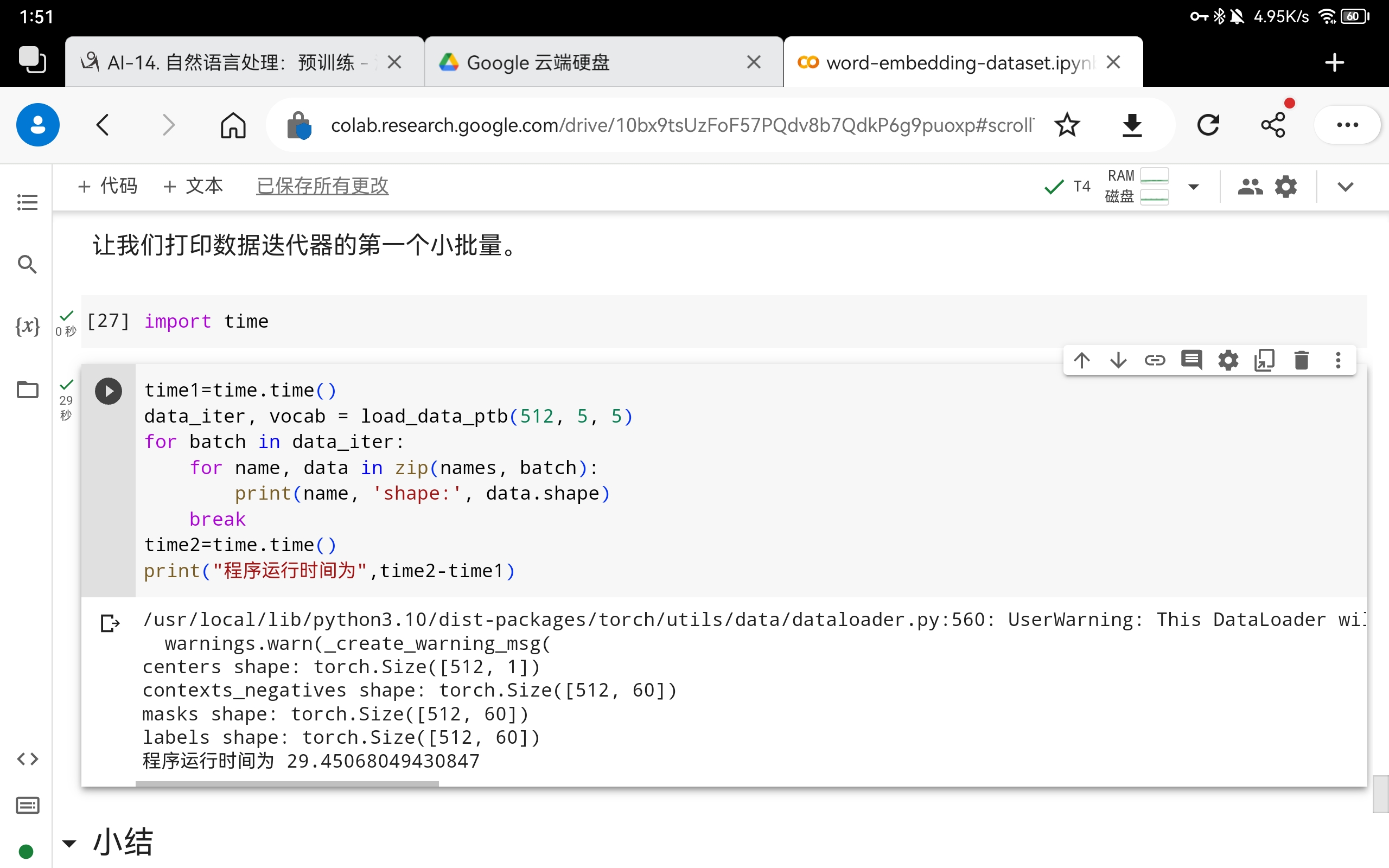
3本节代码中的哪些其他超参数可能会影响数据加载速度?
答:批量大小等
14.4预训练word2vec
对训练好的模型,我们可以通过词向量的余弦相似度来从词表中搜索与输入单词相似度最高的单词。
14.5全局向量的词嵌入(GloVe)
本节介绍了一种新的损失函数,通过全局预料统计数据,近似的去模拟全局条件分布。(通过这种方式模型可得到近似的条件概率,同时也降低了计算量)
14.6子词嵌入
在英语中,helps,helping,helped 都是help的变体。但word2vec和GloVe都没考虑该情况。
fastText模型提出一种字词嵌入方法,fastText可以被认为是子词级跳元模型,而非学习词级向量表示,其中每个中心词由其子词级向量之和表示。为了在固定大小的词表中允许可变长度的子词,我们可以应用一种称为字节对编码(Byte Pair Encoding,BPE)的压缩算法来提取子词 (Sennrich et al., 2015)。字节对编码执行训练数据集的统计分析,以发现词内的公共符号。作为一种贪心方法,字节对编码迭代地合并最频繁的连续符号对。
14.7. 词的相似性和类比任务
通过预先训练的词向量,我们可以应用于下游的自然语言处理任务,例如 词相似度和词类比。
14.8. 来自Transformers的双向编码器表示(BERT)
上下文无关表示具有明显的局限性。例如,在“a crane is flying”(一只鹤在飞)和“a crane driver came”(一名吊车司机来了)的上下文中,“crane”一词有完全不同的含义;因此,同一个词可以根据上下文被赋予不同的表示。
这推动了“上下文敏感”词表示的发展,其中词的表征取决于它们的上下文。因此,词元x的上下文敏感表示是函数f(x,c(x)),其取决于x及其上下文c(x)。
通过使用预训练的Transformer编码器,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT在两个方面与GPT相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。其次,对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。
为了双向编码上下文以表示每个词元,BERT随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。此任务称为掩蔽语言模型。但是虽然掩蔽语言建模能够编码双向上下文来表示单词,但它不能显式地建模文本对之间的逻辑关系。为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测。在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
14.10. 预训练BERT
原始的BERT有两个版本,其中基本模型有1.1亿个参数,大模型有3.4亿个参数。在实验中,同一个词元在不同的上下文中具有不同的BERT表示。这支持BERT表示是上下文敏感的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号