AI-13 计算机视觉
本章将重点介绍计算机视觉领域,并探讨最近在学术界和行业中具有影响力的方法和应用。
13.1. 图像增广
图像增广在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。 例如,我们可以以不同的方式裁剪图像,使感兴趣的对象出现在不同的位置,减少模型对于对象出现位置的依赖。
方法包括:翻转和裁剪 以及 改变图像颜色的四个方面:亮度、对比度、饱和度和色调。
练习:
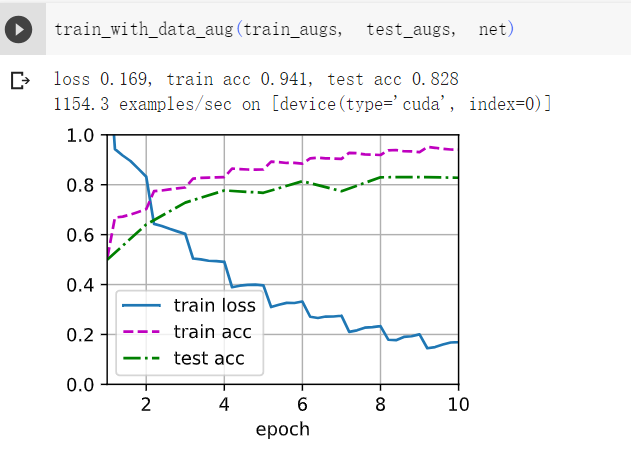
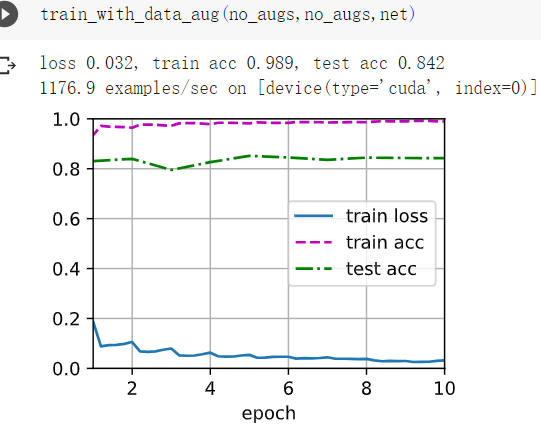
1在不使用图像增广的情况下训练模型:train_with_data_aug(no_aug, no_aug)。比较使用和不使用图像增广的训练结果和测试精度。这个对比实验能支持图像增广可以减轻过拟合的论点吗?为什么?
不使用图像增广过拟合明显
2在基于CIFAR-10数据集的模型训练中结合多种不同的图像增广方法。它能提高测试准确性吗?
可以
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),#只进行垂直翻转
torchvision.transforms.ToTensor()])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),#垂直翻转
torchvision.transforms.RandomVerticalFlip(),#水平翻转
torchvision.transforms.ToTensor()])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()])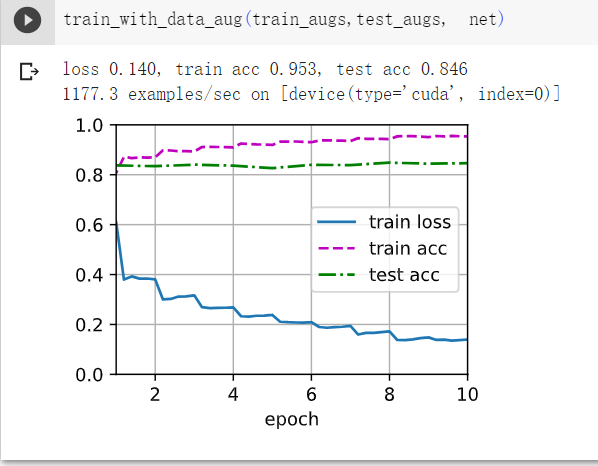
13.2. 微调
迁移学习(transfer learning)将从源数据集学到的知识迁移到目标数据集。 例如,尽管ImageNet数据集中的大多数图像与椅子无关,但在此数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。 这些类似的特征也可能有效地识别椅子。
本节将介绍迁移学习中的常见技巧:微调(fine-tuning)微调包括以下四个步骤。
-
在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
-
向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
-
在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
练习:
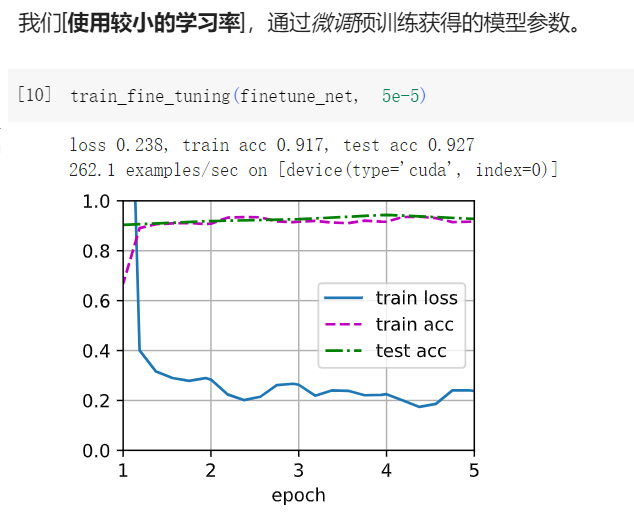
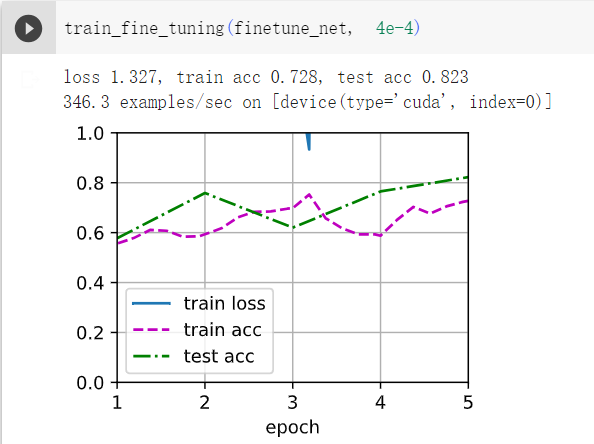
1继续提高finetune_net的学习率,模型的准确性如何变化?
答:如下图,学习率高了,模型精度反而降低了。 所以需要微调
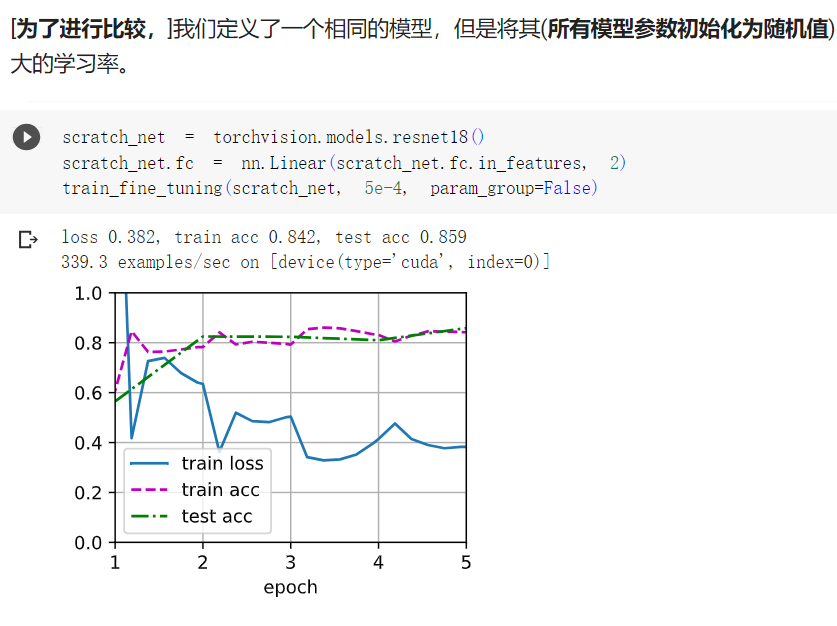
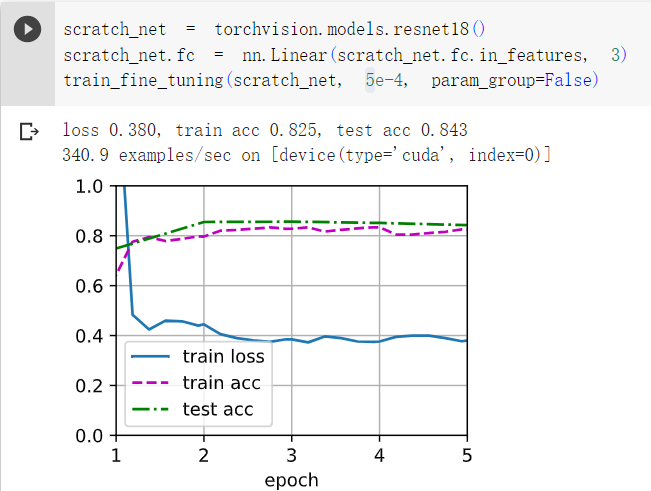
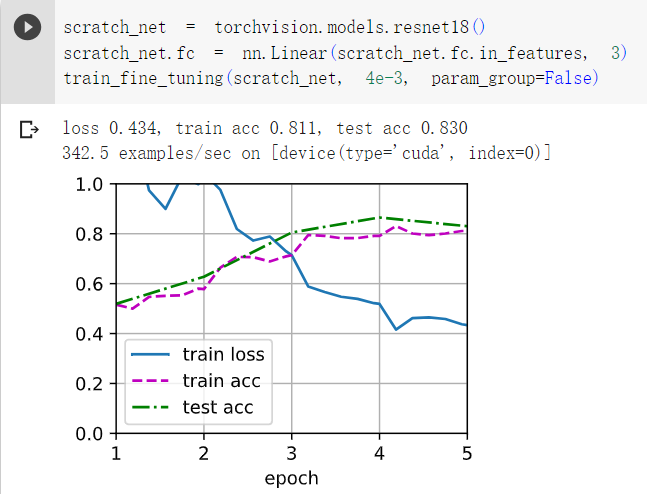
2在比较实验中进一步调整finetune_net和scratch_net的超参数。它们的准确性还有不同吗?
答:如下图,增加层数和增大学习率并没有提高其精确度。
3将输出层finetune_net之前的参数设置为源模型的参数,在训练期间不要更新它们。模型的准确性如何变化?提示:可以使用以下代码。
答:如下图所示,如果不更新模型主体参数,则模型精度会下降。
finetune_net = torchvision.models.resnet18(pretrained=True)
#for param in finetune_net.parameters():
# param.requires_grad = False
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight); 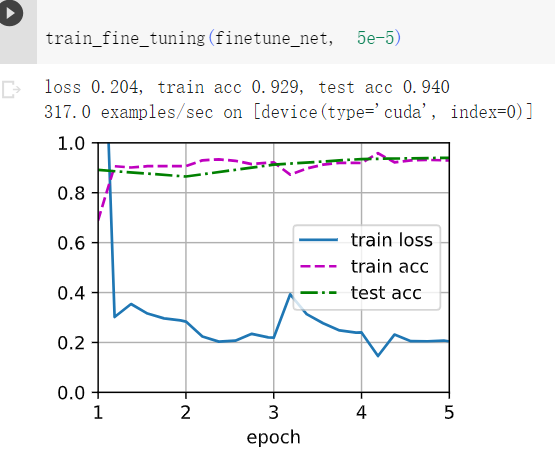
finetune_net = torchvision.models.resnet18(pretrained=True)
for param in finetune_net.parameters():
param.requires_grad = False
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight);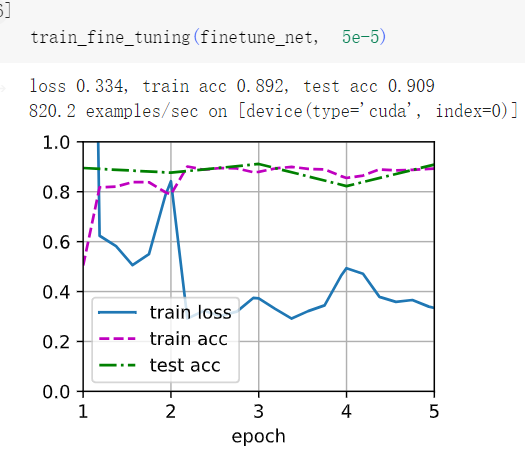
13.3. 目标检测和边界框
我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。 在计算机视觉里,我们将这类任务称为目标检测(object detection)或目标识别(object recognition)。
练习:
1找到另一张图像,然后尝试标记包含该对象的边界框。比较标注边界框和标注类别哪个需要更长的时间?
答:标注类别更快它只需要确定一个参数,而标注边界需要同时确定四个参数
2为什么box_corner_to_center和box_center_to_corner的输入参数的最内层维度总是4?
答:输入必须是(x1,y1),(x2,y2)或(x,y,h,w) 保证位置不变要保证变换是线性映射维度不变。
13.4. 锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含目标,并调整区域边界从而更准确地预测真实边界框(ground-truth bounding box)。这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。 这些边界框被称为锚框(anchor box)。
当中心位置给定时,已知宽和高的锚框是确定的。要生成多个不同形状的锚框,让我们设置许多缩放比(scale)。
衡量锚框和真实边界框之间的相似性呢?一般采用杰卡德系数(Jaccard),它可以衡量两组之间的相似性。 给定集合A和B,他们的杰卡德系数是他们交集的大小除以他们并集的大小。
预测期间可以使用非极大值抑制(NMS)来移除类似的预测边界框,从而简化输出。非极大值抑制的工作原理为: 对于一个预测边界框B,目标检测模型会计算每个类别的预测概率。 假设最大的预测概率为p1,则该概率所对应的类别class1即为预测的类别。 具体来说,我们将p1称为预测边界框B的置信度(confidence)。 在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表L。
练习:
1在multibox_prior函数中更改sizes和ratios的值。生成的锚框有什么变化?
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.50, 0.5, 0.25], ratios=[1, 1, 0.5])
Y.shape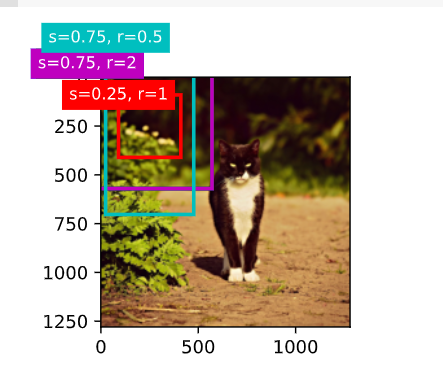
2构建并可视化两个IoU为0.5的边界框。它们是怎样重叠的?
答:重合面积与未重合面积相等。
3修改变量anchors,结果如何变化?
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率 
anchors = torch.tensor([[0.1, 0.08, 0.42, 0.92], [0.08, 0.2, 0.46, 0.95],
[0.15, 0.3, 0.42, 0.91], [0.55, 0.2, 0.4, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率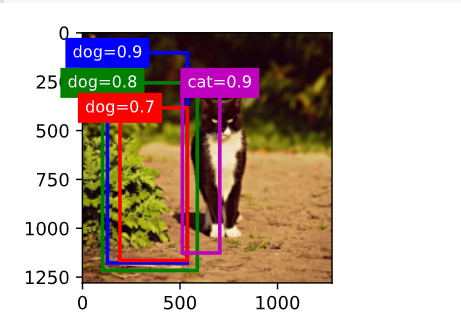
4非极大值抑制是一种贪心算法,它通过移除来抑制预测的边界框。是否存在一种可能,被移除的一些框实际上是有用的?如何修改这个算法来柔和地抑制?可以参考Soft-NMS (Bodla et al., 2017)。
答:可能
13.5. 多尺度目标检测
如果为每个像素都生成的锚框,我们最终可能会得到太多需要计算的锚框。我们可以在输入图像中均匀采样一小部分像素,并以它们为中心生成锚框。 此外,在不同尺度下,我们可以生成不同数量和不同大小的锚框。
卷积图层的二维数组输出称为特征图。 通过定义特征图的形状,我们可以确定任何图像上均匀采样锚框的中心。
练习:
1根据我们在 7.1节中的讨论,深度神经网络学习图像特征级别抽象层次,随网络深度的增加而升级。在多尺度目标检测中,不同尺度的特征映射是否对应于不同的抽象层次?为什么?
答:不是,不同尺度的特征映射对应于不同大小的卷积核。它只是感受野比较大。
2在 13.5.1节中的实验里的第一个尺度(fmap_w=4, fmap_h=4)下,生成可能重叠的均匀分布的锚框。
3给定形状为1×c×ℎ×w的特征图变量,其中c、ℎ和w分别是特征图的通道数、高度和宽度。怎样才能将这个变量转换为锚框类别和偏移量?输出的形状是什么?
答:
13.6. 目标检测数据集
标签的小批量的形状为(批量大小,m,5),其中m是数据集的任何图像中边界框可能出现的最大数量。
小批量计算虽然高效,但它要求每张图像含有相同数量的边界框,以便放在同一个批量中。 通常来说,图像可能拥有不同数量个边界框;因此,在达到m之前,边界框少于m的图像将被非法边界框填充。
练习:
1在香蕉检测数据集中演示其他带有真实边界框的图像。它们在边界框和目标方面有什么不同?
答:大小,位置都不同。
2假设我们想要将数据增强(例如随机裁剪)应用于目标检测。它与图像分类中的有什么不同?提示:如果裁剪的图像只包含物体的一小部分会怎样?
答:会导致标签出现错误,图像被裁减后标签中的边框信息也需要被修改。
13.7单发多框检测(SSD)
设目标类别的数量为q。这样一来,锚框有q+1个类别,其中0类是背景。 在某个尺度下,设特征图的高和宽分别为ℎ和w。 如果以其中每个单元为中心生成a个锚框,那么我们需要对ℎwa个锚框进行分类。
边界框预测层的设计与类别预测层的设计类似。 唯一不同的是,这里需要为每个锚框预测4个偏移量,而不是q+1个类别
目标检测有两种类型的损失:
第一种有关锚框类别的损失:我们可以简单地复用之前图像分类问题里一直使用的交叉熵损失函数来计算;
第二种有关正类锚框偏移量的损失:预测偏移量是一个回归问题。使用L1范数损失,即预测值和真实值之差的绝对值。
最后,我们将锚框类别和偏移量的损失相加,以获得模型的最终损失函数。
13.8. 区域卷积神经网络(R-CNN)系列
先通过选择性搜索找到多个提议区域,然后分别独立预测。
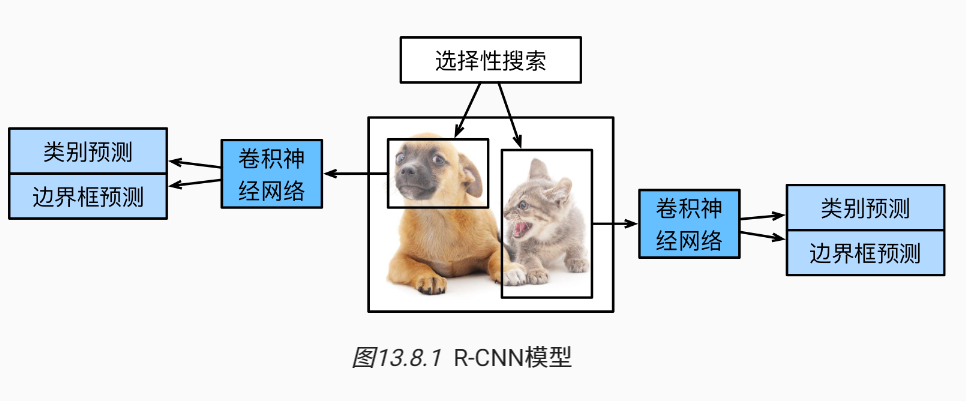
Fast的改进在于,第一步的多个提议区域会重复计算,因此将提议区域的搜索放到卷积网络后,只对整张图前向传播。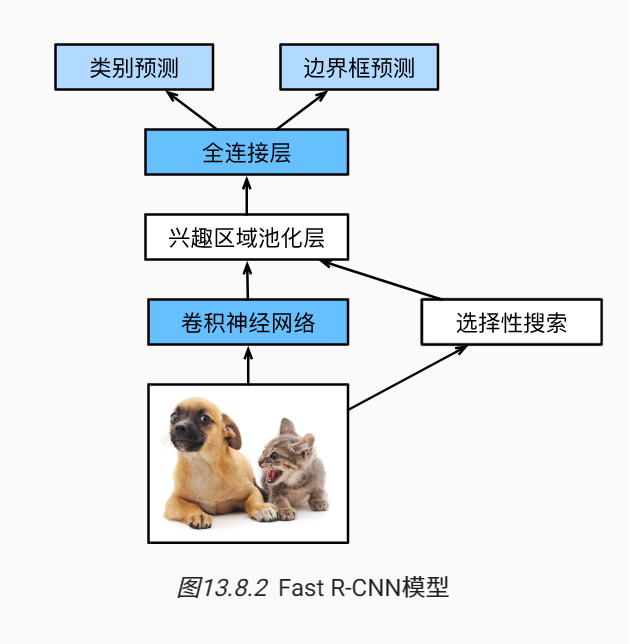
进一步的,Faster 将选择性搜索替换为区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。
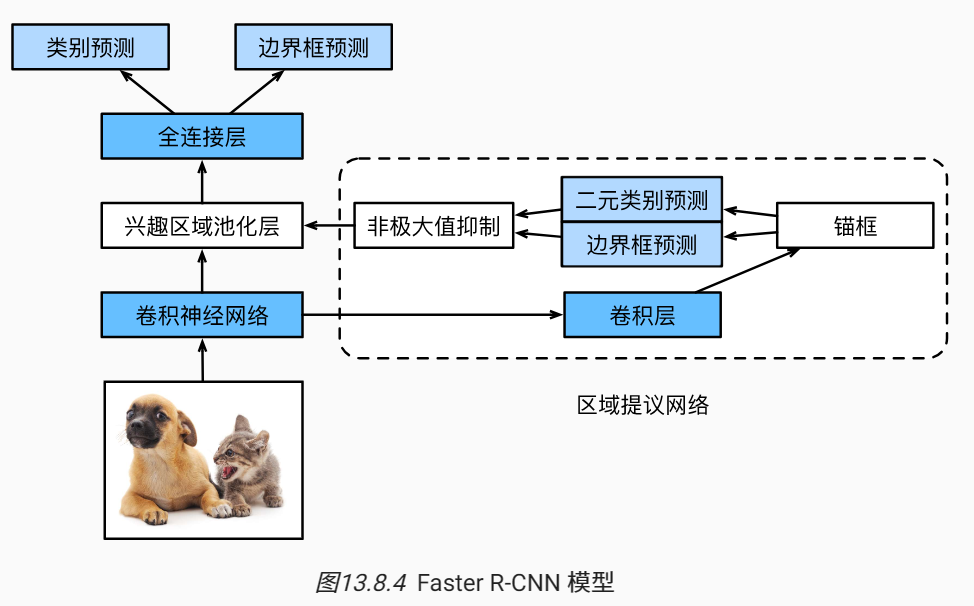
练习:
-
我们能否将目标检测视为回归问题(例如预测边界框和类别的概率)?可以参考YOLO模型 (Redmon et al., 2016)的设计。
在YOLO和SSD中,基于回归问题对目标进行检测。
-
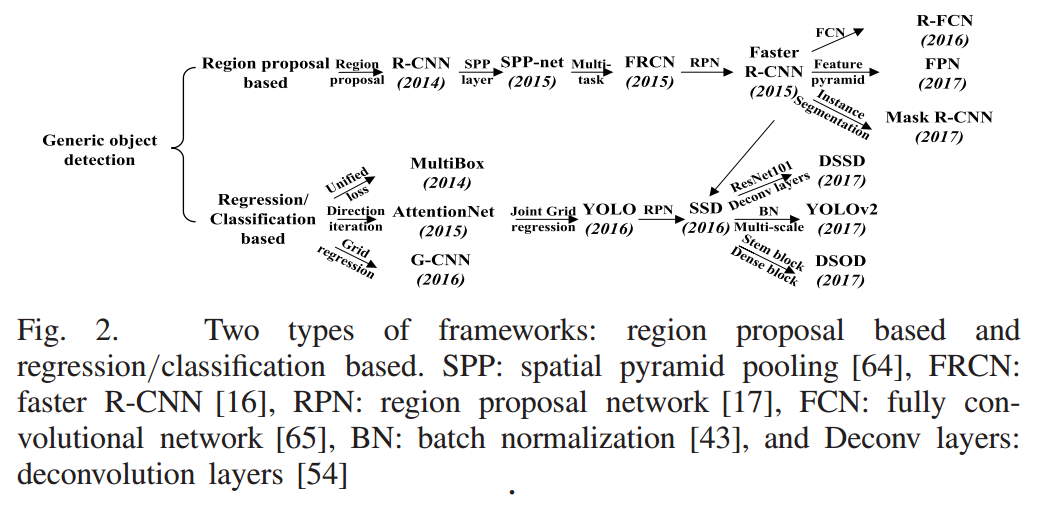
将单发多框检测与本节介绍的方法进行比较。他们的主要区别是什么?可以参考 (Zhao et al., 2019)中的图2
如图所示,R-CNN和SSD的区别在于前者基于提议区域进行预测而后者基于回归分类。
13.9. 语义分割和数据集
本节将探讨语义分割(semantic segmentation)问题,它重点关注于如何将图像分割成属于不同语义类别的区域。 与目标检测不同,语义分割可以识别并理解图像中每一个像素的内容:其语义区域的标注和预测是像素级的。
图像分割将图像划分为若干组成区域,这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。
实例分割也叫同时检测并分割(simultaneous detection and segmentation),它研究如何识别图像中各个目标实例的像素级区域。例如,如果图像中有两条狗,则实例分割需要区分像素属于的两条狗中的哪一条。
在语义分割中,我们将图像裁剪为固定尺寸,而不是再缩放。 具体来说,我们使用图像增广中的随机裁剪,裁剪输入图像和标签的相同区域。
练习:
1回想一下 13.1节中对数据增强的描述。图像分类中使用的哪种图像增强方法是难以用于语义分割的? 裁剪
13.10. 转置卷积
转置卷积与之前学的卷积不同,它是用输入的每个元素分别与卷积核相乘,从而达到扩大输出的目的。
而其步幅是影响的每个卷积核乘积如何相加。
练习:
1在 13.10.3节中,卷积输入X和转置的卷积输出Z具有相同的形状。他们的数值也相同吗?为什么?
答:不相同,Z是若干个X中元素与卷积核乘积然后相加的结果
2使用矩阵乘法来实现卷积是否有效率?为什么?
答:是相对高效的,因为矩阵乘法比较快。
13.11. 全卷积网络
与卷积神经网络不同,全卷积网络通过转置卷积将中间层特征图的高和宽变换回输入图像的尺寸 因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。
在图像处理中,我们有时需要将图像放大,即上采样(upsampling)。 双线性插值(bilinear interpolation) 是常用的上采样方法之一,它也经常用于初始化转置卷积层。
练习:
1如果将转置卷积层改用Xavier随机初始化,结果有什么变化?
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);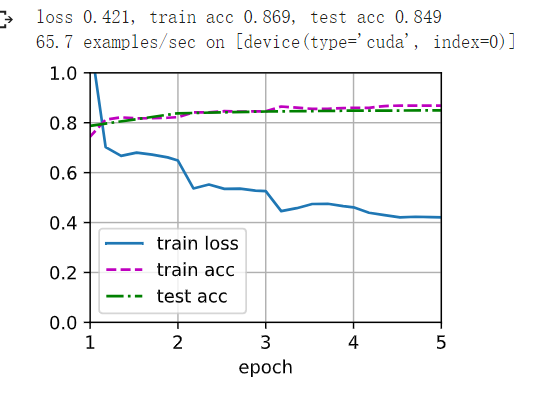
W = bilinear_kernel(num_classes, num_classes, 64)
torch.nn.init.xavier_uniform_(W, gain=1)
net.transpose_conv.weight.data.copy_(W);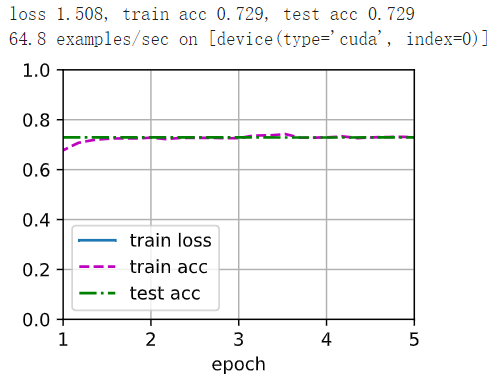
2调节超参数,能进一步提升模型的精度吗?
答:提高迭代次数可以提升精度
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
num_epochs, lr, wd, devices =20, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)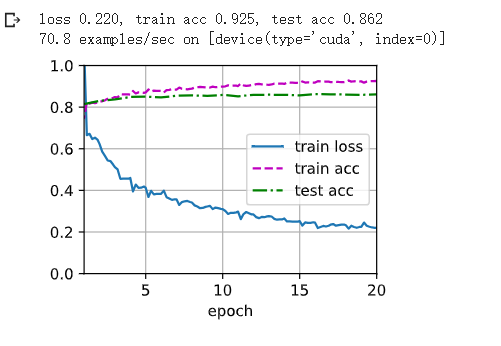
13.12. 风格迁移
使用卷积神经网络,自动将一个图像中的风格应用在另一图像之上,即风格迁移(style transfer) (Gatys et al., 2016)。 这里我们需要两张输入图像:一张是内容图像,另一张是风格图像。 我们将使用神经网络修改内容图像,使其在风格上接近风格图像。
如图所示,内容图像和样式图像的卷积层参数并没有改变,合成图像的模型参数在更新。
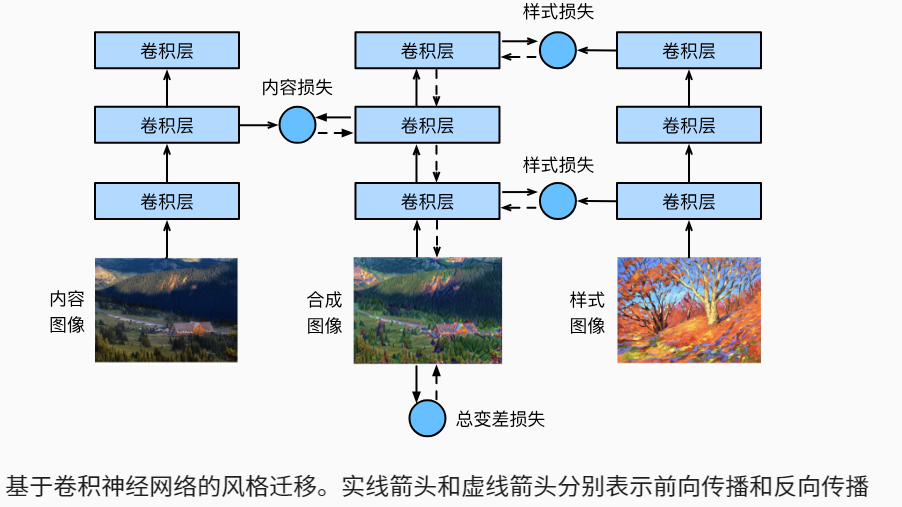
一般来说,越靠近输入层,越容易抽取图像的细节信息;反之,则越容易抽取图像的全局信息。 为了避免合成图像过多保留内容图像的细节,我们选择VGG较靠近输出的层,即内容层,来输出图像的内容特征。 我们还从VGG中选择不同层的输出来匹配局部和全局的风格,这些图层也称为风格层。
风格迁移常用的损失函数由3部分组成:(1)内容损失使合成图像与内容图像在内容特征上接近;(2)风格损失令合成图像与风格图像在风格特征上接近;(3)全变分损失则有助于减少合成图像中的噪点。
练习:
1选择不同的内容和风格层,输出有什么变化?
2调整损失函数中的权重超参数。输出是否保留更多内容或减少更多噪点?
3替换实验中的内容图像和风格图像,能创作出更有趣的合成图像吗?
4我们可以对文本使用风格迁移吗?提示:可以参阅调查报告 (Hu et al., 2020)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App