AI-5 深度学习计算
5.1块和层
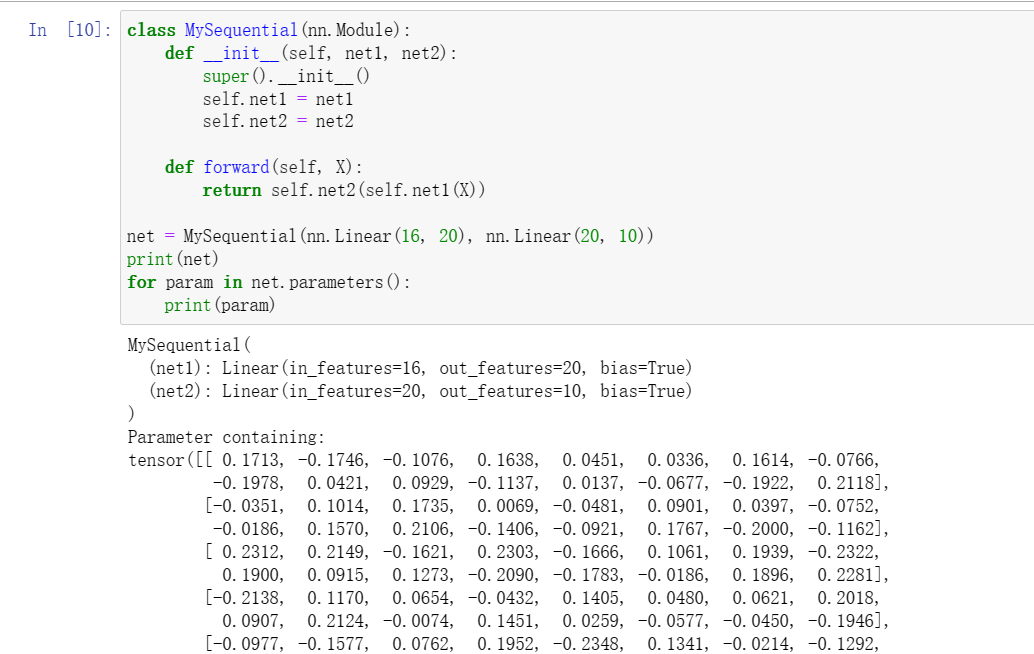
我们一直在通过net(X)调用我们的模型来获得模型的输出。 这实际上是net.__call__(X)的简写。 这个前向传播函数非常简单: 它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)块的一个主要优点是它的多功能性。 我们可以子类化块以创建层(如全连接层的类)、 整个模型(如上面的MLP类)或具有中等复杂度的各种组件。
Sequential的设计则是为了把其他模块串起来。
5.1练习
1如果将MySequential中存储块的方式更改为Python列表,会出现什么样的问题?
将无法通过parameters()迭代器访问参数。

2实现一个块,它以两个块为参数,例如net1和net2,并返回前向传播中两个网络的串联输出。这也被称为平行块。
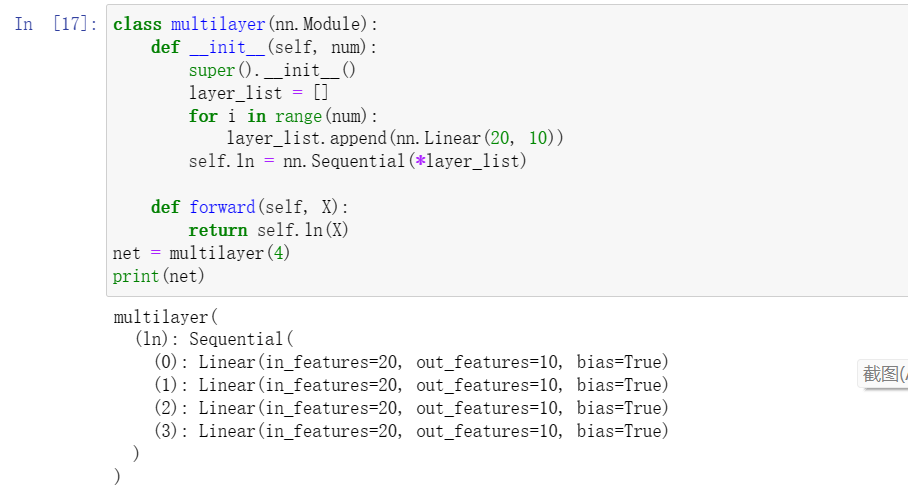
3假设我们想要连接同一网络的多个实例。实现一个函数,该函数生成同一个块的多个实例,并在此基础上构建更大的网络。
通过sequential连续定义多个块
5.2. 参数管理
经过训练后,我们将需要使用这些参数来做出未来的预测。 此外,有时我们希望提取参数,以便在其他环境中复用它们, 将模型保存下来,以便它可以在其他软件中执行, 或者为了获得科学的理解而进行检查。
当通过Sequential类定义模型时,可以像访问列表一样访问模型的参数。
print(net[2].state_dict())另外,这一节还有一些参数初始化的方法。
5.2. 练习
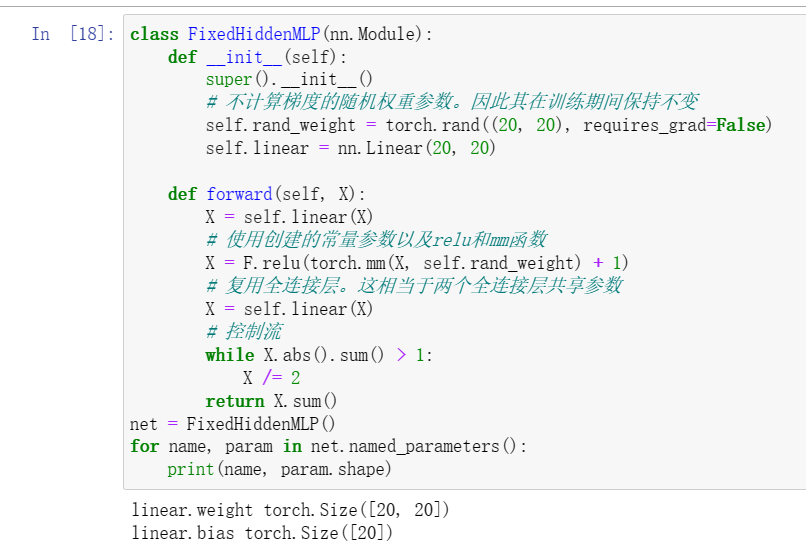
1使用 5.1节 中定义的FancyMLP模型,访问各个层的参数。
2查看初始化模块文档以了解不同的初始化方法。
包括初始化为1,0,推荐增益值等等,链接:torch.nn.init — PyTorch 2.0 documentation
3构建包含共享参数层的多层感知机并对其进行训练。在训练过程中,观察模型各层的参数和梯度。
共享参数层的参数是具有相同的内存地址,他们的参数回同步改变。
4为什么共享参数是个好主意?
也许可以减小参数所占空间?
5.3. 延后初始化
我们定义了网络架构,但没有指定输入维度。我们添加层时没有指定前一层的输出维度。我们在初始化参数时,甚至没有足够的信息来确定模型应该包含多少参数。直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小。
练习
1如果指定了第一层的输入尺寸,但没有指定后续层的尺寸,会发生什么?是否立即进行初始化?
框架会自动设置后续尺寸。
2如果指定了不匹配的维度会发生什么?
会报错
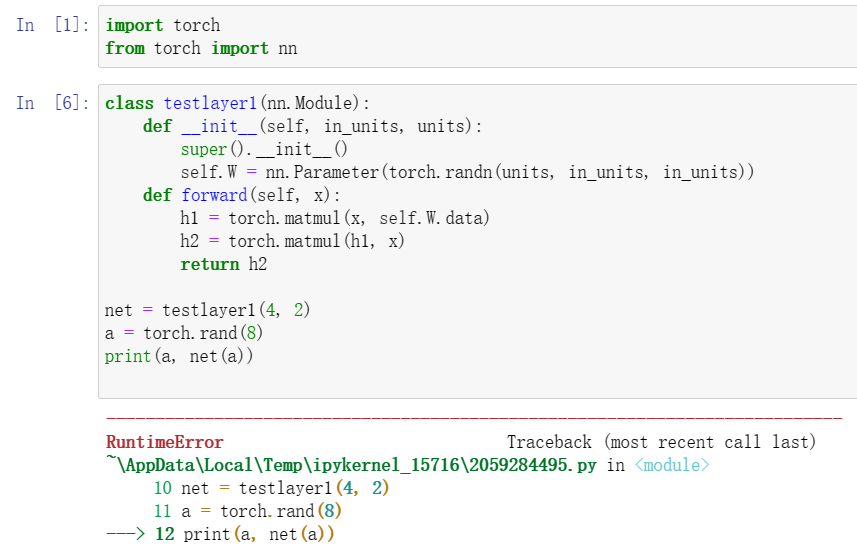
3如果输入具有不同的维度,需要做什么?提示:查看参数绑定的相关内容。
会共享参数?
5.4. 自定义层
自己定义一个层,从而灵活的实现想要的功能。
可以定义无参数层
import torch
import torch.nn.functional as F
from torch import nn
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean()验证其功能
layer = CenteredLayer()
layer(torch.FloatTensor([1, 2, 3, 4, 5]))也可以定义有参数的
class MyLinear(nn.Module):
def __init__(self, in_units, units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, units))
self.bias = nn.Parameter(torch.randn(units,))
def forward(self, X):
linear = torch.matmul(X, self.weight.data) + self.bias.data
return F.relu(linear)可以实例化,并访问参数
linear = MyLinear(5, 3)
linear.weight通过建好的层,可以直接前向传播
linear(torch.rand(2, 5))也可以使用自定义层去建立网络
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
net(torch.rand(2, 64))练习
1设计一个接受输入并计算张量降维的层
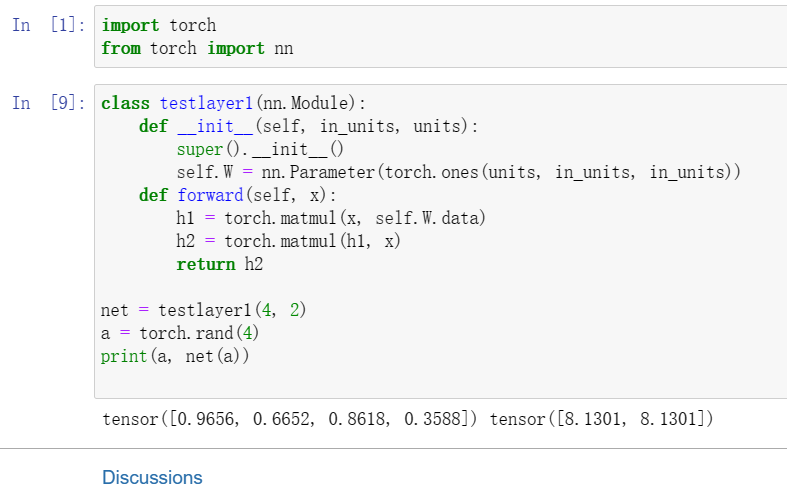
2设计一个返回输入数据的傅立叶系数前半部分的层。
前半部分?
5.5. 读写文件
对于单个张量,我们可以直接调用load和save函数分别读写它们
我们甚至可以写入或读取从字符串映射到张量的字典(确实用的很灵活)
mydict = {'x': x, 'y': y}
torch.save(mydict, 'mydict')
mydict2 = torch.load('mydict')
mydict2练习
1即使不需要将经过训练的模型部署到不同的设备上,存储模型参数还有什么实际的好处?
也许,便于长期多次的训练
2假设我们只想复用网络的一部分,以将其合并到不同的网络架构中。比如想在一个新的网络中使用之前网络的前两层,该怎么做?
可以直接复制其参数
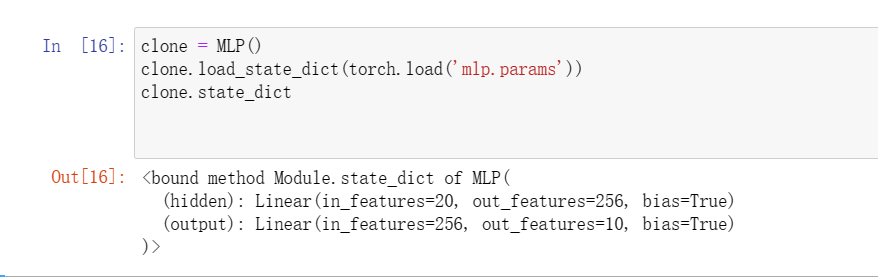
3如何同时保存网络架构和参数?需要对架构加上什么限制?

5.6. GPU
这两个代码允许我们在不存在所需所有GPU的情况下运行代码。
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices = [torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()当两个变量相加的时候要确保他们在同一个设备里,(在同一个GPU)
只要所有的数据和参数都在同一个设备上, 我们就可以有效地学习模型
练习
1尝试一个计算量更大的任务,比如大矩阵的乘法,看看CPU和GPU之间的速度差异。再试一个计算量很小的任务呢?
大规模的矩阵乘法GPU块于CPU
2我们应该如何在GPU上读写模型参数?
直接标注GPU?X = torch.ones(2, 3, device=try_gpu())
3测量计算1000个100×100矩阵的矩阵乘法所需的时间,并记录输出矩阵的Frobenius范数,一次记录一个结果,而不是在GPU上保存日志并仅传输最终结果。
4测量同时在两个GPU上执行两个矩阵乘法与在一个GPU上按顺序执行两个矩阵乘法所需的时间。提示:应该看到近乎线性的缩放。
存在接近两倍的关系

 浙公网安备 33010602011771号
浙公网安备 33010602011771号