AI-4多层感知机
4.1笔记
在线性网络中,任何特征的增大都会导致模型输出的增大或减小。这种想法在某些情况下不在适用,例如x和y并非线性关系、或者是x和y并不具有单调性、以及x1、x2会对y产生交互作用时。
为解决该问题,有人提出在网络中加入隐藏层,来克服线性模型的限制,使其能够处理更多变的函数关系。为防止多个隐藏层退化为单一的线性映射,在每个隐藏单元加入激活函数(非线性的),让模型更具表达力。
(即使是网络只有一个隐藏层,给定足够的神经元和正确的权重, 我们可以对任意函数建模...... from d2l , why?)实际上,通常使用更深的(而不是更广的)网络。
几个常用的激活函数:ReLU函数,sigmoid函数,tanh函数
、
4.1练习
1算pReLU激活函数的导数。

2证明一个仅使用ReLU(或pReLU)的多层感知机构造了一个连续的分段线性函数。
任意形式的ReLU可视为原始ReLU的放缩与平移
当x>=0时,ReLU(x)=x, 当x<0时,ReLU(x)=0,则仅需证明其在x=0出的连续性。
ReLU(0+)=0,ReLU(0-)=0,故lim x->0,ReLU(x)=0.极限值存在且等于函数值.
因此,函数ReLU连续.
3证明tanh(x)+1=2sigmoid(2x)。 (见第一题图片)
4假设我们有一个非线性单元,将它一次应用于一个小批量的数据。这会导致什么样的问题?
数据可能会被剧烈的拉伸或者压缩,可能会导致分布的偏移,若数据都小于0,则激活函数ReLU无法激活;若数据较大,则在激活函数sigmoid或者tanh中,结果区分度较低。与后面的神经元对接后可能会损失一定的特征。
4.2多层感知机的从零开始实现
4.2练习
1在所有其他参数保持不变的情况下,更改超参数num_hiddens的值,并查看此超参数的变化对结果有何影响。确定此超参数的最佳值。
num_inputs, num_outputs, num_hiddens = 784, 10, 256/1024
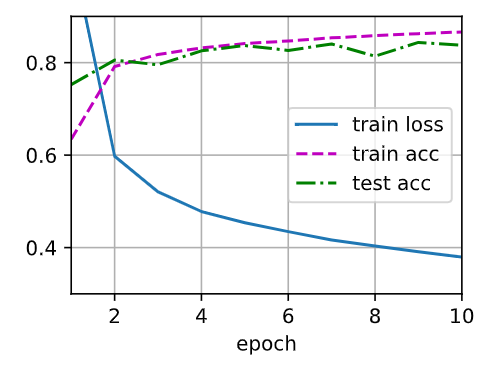

2尝试添加更多的隐藏层,并查看它对结果有何影响。
3改变学习速率会如何影响结果?保持模型架构和其他超参数(包括轮数)不变,学习率设置为多少会带来最好的结果?
4通过对所有超参数(学习率、轮数、隐藏层数、每层的隐藏单元数)进行联合优化,可以得到的最佳结果是什么?
5描述为什么涉及多个超参数更具挑战性。
6如果想要构建多个超参数的搜索方法,请想出一个聪明的策略。
4.3
4.3练习
-
尝试添加不同数量的隐藏层(也可以修改学习率),怎么样设置效果最好?
-
尝试不同的激活函数,哪个效果最好?
-
尝试不同的方案来初始化权重,什么方法效果最好?
4.4模型选择、欠拟合和过拟合


4.4练习
1这个多项式回归问题可以准确地解出吗?提示:使用线性代数。
2考虑多项式的模型选择。
2.1绘制训练损失与模型复杂度(多项式的阶数)的关系图。观察到了什么?需要多少阶的多项式才能将训练损失减少到0?
2.2在这种情况下绘制测试的损失图。
2。3生成同样的图,作为数据量的函数。
4如果不对多项式特征进行标准化,会发生什么事情?能用其他方法解决这个问题吗?
这样可以避免很大的i带来的特别大的指数值,如果不对此进行标准化,在优化的时候可能会带来特别大的非常大的梯度值或损失值;
5泛化误差可能为零吗?
数据总会有一定的噪声导致数据偏移,而且训练数据的分布和真实分布不可能完全相同。
4.5. 权重衰减
为了缓解过拟合问题,我们可以搜集更多的数据,也可以采用一下正则化技术。
其中,权重衰减(也称L2正则化)
为了惩罚权重向量的大小, 我们必须以某种方式在损失函数中添加||w||2, 但是模型应该如何平衡这个新的额外惩罚的损失? 实际上,我们通过正则化常数来描述这种权衡, 这是一个非负超参数.
4.5练习
1在本节的估计问题中使用的值进行实验。绘制训练和测试精度关于的函数。观察到了什么?
2使用验证集来找到最佳值。它真的是最优值吗?这有关系吗?
不一定是,验证集的数据分布并不见得与真实分布完全相同。
3如果我们使用L1范数作为我们选择的惩罚(正则化),那么更新方程会是什么样子?
对比L2和L1
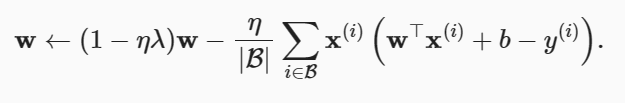
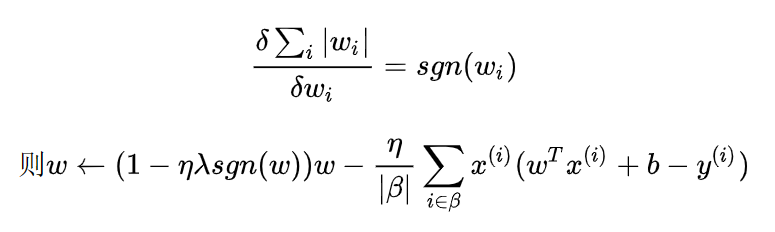
4回顾训练误差和泛化误差之间的关系。除了权重衰减、增加训练数据、使用适当复杂度的模型之外,还能想出其他什么方法来处理过拟合?
下一章的暂退法
4.6暂退法(Dropout)
我们期待“好”的预测模型能在未知的数据上有很好的表现: 经典泛化理论认为,为了缩小训练和测试性能之间的差距,应该以简单的模型为目标。
暂退法在前向传播过程中,计算每一内部层的同时注·入噪声,这已经成为训练神经网络的常用技术。 这种方法之所以被称为暂退法,因为我们从表面上看是在训练过程中丢弃(drop out)一些神经元。 在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。
4.6练习
1如果更改第一层和第二层的暂退法概率,会发生什么情况?具体地说,如果交换这两个层,会发生什么情况?设计一个实验来回答这些问题,定量描述该结果,并总结定性的结论。
借鉴自
2增加训练轮数,并将使用暂退法和不使用暂退法时获得的结果进行比较。
3当应用或不应用暂退法时,每个隐藏层中激活值的方差是多少?绘制一个曲线图,以显示这两个模型的每个隐藏层中激活值的方差是如何随时间变化的。
4为什么在测试时通常不使用暂退法?
因为训练时为了得到更好的模型参数,所以使用暂退法加入噪声。而测试的时候网络模型参数已经确定固定的,对输入数据不需要再使用Dropout加入噪声了,这样得到的结果也会更准确。
5以本节中的模型为例,比较使用暂退法和权重衰减的效果。如果同时使用暂退法和权重衰减,会发生什么情况?结果是累加的吗?收益是否减少(或者说更糟)?它们互相抵消了吗?
结果会更好,效果会累计。因为它们防止过拟合的思考点不同,暂退法是通过引入一定的噪声,增加模型对输入数据的扰动鲁棒性,权重衰减在于约束模型参数来防止模型过拟合。
6如果我们将暂退法应用到权重矩阵的各个权重,而不是激活值,会发生什么?
7发明另一种用于在每一层注入随机噪声的技术,该技术不同于标准的暂退法技术。尝试开发一种在Fashion-MNIST数据集(对于固定架构)上性能优于暂退法的方法。
maybe i can try several years later...
4.7前向传播 反向传播和计算图
前向传播(forward propagation或forward pass) 指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
反向传播(backward propagation或backpropagation)指的是计算神经网络参数梯度的方法。 简言之,该方法根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。
反向传播重复利用前向传播中存储的中间值,以避免重复计算。 带来的影响之一是我们需要保留中间值,直到反向传播完成。 这也是训练比单纯的预测需要更多的内存(显存)的原因之一。
4.7练习
1假设一些标量函数X的输入X是n×m矩阵。f相对于X的梯度维数是多少?
对矩阵中每一个元素分别求导,所以梯度任然是n*m
2向本节中描述的模型的隐藏层添加偏置项(不需要在正则化项中包含偏置项)。
2.1画出相应的计算图。2.2推导正向和反向传播方程。
3计算本节所描述的模型,用于训练和预测的内存占用。
训练需要的:x,z,h,o,y,L,s,J,W(1),W(2),dJ/dW(1),dJ/dW(2)
预测需要的:x,z,h,o,y,W(1),W(2)
4假设想计算二阶导数。计算图发生了什么?预计计算需要多长时间?
需要保留所有的一阶导数,需要二倍甚至更多
5假设计算图对当前拥有的GPU来说太大了。
5.1请试着把它划分到多个GPU上 5.2与小批量训练相比,有哪些优点和缺点
使用MPI实现多个进程之间的并行运算,从而将大任务分割为多个小任务同时进行。
优点是可以训练较大的模型,缺点是多接点进程之间需要通讯,限制其速度。
4.8. 数值稳定性和模型初始化
初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要
梯度爆炸(gradient exploding)问题: 参数更新过大,破坏了模型的稳定收敛.
梯度消失(gradient vanishing)问题: 参数更新过小,在每次更新时几乎不会移动,导致模型无法学习.
4.8练习
1除了多层感知机的排列对称性之外,还能设计出其他神经网络可能会表现出对称性且需要被打破的情况吗?
其他神经网络的参数初始化也可能hi表现出对称性,从而影响模型效果。可以通过随机初始化来解决。
2我们是否可以将线性回归或softmax回归中的所有权重参数初始化为相同的值?
不行,如果初始值相同,会导致元素及其梯度也相同导致模型效果下降。
3在相关资料中查找两个矩阵乘积特征值的解析界。这对确保梯度条件合适有什么启示?
4如果我们知道某些项是发散的,我们能在事后修正吗?看看关于按层自适应速率缩放的论文 (You et al., 2017) 。
可以自适应调整学习率
4.9 环境和分布偏移
真实的数据分布与训练数据可能会发生偏移,常见现象包括:协变量偏移,标签偏移,概念偏移
4.9练习
1当我们改变搜索引擎的行为时会发生什么?用户可能会做什么?广告商呢?
2实现一个协变量偏移检测器。提示:构建一个分类器。
3实现协变量偏移纠正。
4除了分布偏移,还有什么会影响经验风险接近真实风险的程度
文化,观念之类

 浙公网安备 33010602011771号
浙公网安备 33010602011771号