SAM学习笔记
SAM学习笔记
后缀自动机(模板)NSUBSTR(Caioj1471 || SPOJ 8222)
【题意】
给出一个字符串S(S<=250000),令F(x)表示S的所有长度为x的子串中,出现次数的最大值。求F(1)..F(Lengh(S));
【输入格式】
一个字符串
【输出格式】
依次输出答案
【样例输入】
ababa
【样例输出】
3
2
2
1
1
【算法分析】
相信大家在学习这个专题时已经接触过很多有关解决字符串问题的其它算法了。但是我们接下来要学的这个专题对于解决字符串的一系列难题都是一件利器----SAM后缀自动机(单词的有向无环图)。
为啥要学习这个算法呢?因为使用后缀自动机来解决字符串的问题很多情况下都可以在线性时间内解决。也就是O(n)差不多啦~(关于具体证明可以参考国家集训队陈立杰的后缀自动机论文)
后缀自动机的基本概念:
能够接收一个串S的所有后缀,可以包含所有S子串的信息,并且它的状态数最少的有向无环图。如果从初始状态root由任意路径走到一个状态(点),按顺序写出所有经过的字符,最后得出来的必然是原串的某一子串;如果走到了终止状态,那么这时所形成的必然是后缀。(建成如下)
再简单粗暴的概括一下大致做法:
假设当前建好了S的其中一个前缀的后缀自动机A,再添加一个字符x,那么就应该得到S的另一个前缀Ax的后缀自动机。像这样按顺序一个一个插入,最后把所有的都建好了之后,就得到了字符串S的后缀自动机。
那么回过头来看我们就很容易发现,这个构造过程其实是在线的,可以在任意时刻询问当前S串的信息,也可以再次在末尾插入字符。(感觉好像树结构一样)不过删除的操作在这里时不支持的。
基础数据结构:
直接上重点:right集合。这个东西在自动机构造里面并没有很明显的使用,但是right集合的中心思想也正是构造SAM的核心思路。
对于图中任意的一个点都可以(因为询问所经过的路径不同)表示成原串的一个或多个子串, 那么这个点的right集合就可以表示为由点为末尾组成的字符串后在原串中右端点(末尾)的位置。那么right集合的重要性主要体现在构造时对这个核心思路的使用;次要的作用就是,我们可以通过right集合的大小,求出某个子串在原串中出现的次数(对于给出的模板题就大有用处了)。
last:上一个建立的节点。
deep[ ]:询问到某个节点所能够经过的最大长度。
ch[ ].son[ ]:(son[i]表示一个字符)表示此节点是否能联通某个字符。
fail[ ]:这个数组也至关重要。先将定义,fail[i]表示i这个节点上一次出现的位置,也就是当前right集合位置的前一个。返回的节点也是上一个可以接收新节点的节点(如果当前节点可以接收成功,那么所返回的节点一定也可以)。
具体做法:
为了让大家更好的理解接下来的构造方法,这里给大家疏通一些主要性质。
1、从初始状态(用root表示)往后询问,到任意节点p的所有路经上所组成的字符串,都是子串之一。(根据这个性质,还可以推出性质2)
2、如果到节点p可以成为新后缀,那么从root到任意节点p(要注意和p相同的节点的存在)的每条路经所组成的所有字符串,都是后缀。
3、如果当前字符结点p可以接收新字符成为后缀,那么p的fail指向的结点也可以接收后缀,反过来就不行。
下面讲正式做法:
现在要插入字符x,也就是把A的后缀自动机变为Ax的后缀自动机。我们把要插入的节点储存为np,找到last,让last不断找fail(直到有x儿子或root才停止寻找)。假设当前fail找到了p节点(还没有停止),如果这个p没有x儿子,那么我们就把x的儿子赋值为np。停止寻找后,我们就要处理当前跳到的有x儿子的p(这个p是最终的)了。
处理的时候会出现两种情况。(假设p的x儿子是q节点)
1、deep[q]=deep[p]+1;也就是说q是从p的路径上直接过来的,p和q直接没有其他字符。那么q节点原本不一定可以接收新字符成为后缀,但p可以接收后缀x,如果当前经过p直接来到q,就可以看作是在A的某个后缀后面插入了x(现在q就是那个x),并且在下一次插入的时候,q也可以接收后缀(因为它现在可以被视为x的结点了),所以就把np的fail指向q。
2、另外一种情况显然就是p和q之间仍然存在其它字符,如果仍然按照情况1来假设,那么就不一定可以保证性质2了。其实也并不难解决,给他一个万能节点nq,nq的作用就是用来替代q的大部分功能,让nq和p连接成为p的儿子,把这种情况模仿成情况1相同的做法(deep[nq]==deep[p]+1)。
看图解吧!以下是完整的构造图解(实边是son边,虚边是fail):
构造的字符串为ACADD:
(1)插入A
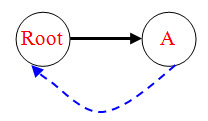
(2)插入C:节点C的fail只能是根,所以C的fail指向root,deep=2。 注意在寻找fail的过程中,root和A都和C相连。
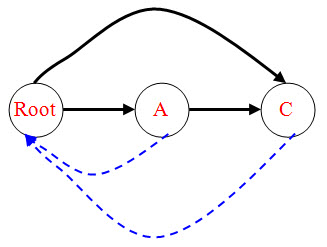
(3)插入A:节点A找last,也就是C,然后找到p指针所在的root,判断是情况1还是2,显然是1。直接进行操作。
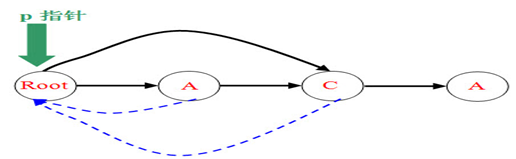
操作后新插入的new A节点的fail就是root的儿子节点A(第一个),那第一个A就有了两个身份,1是后缀A的末尾字符,2是后缀ACA的末尾字符(代替了new A,保证状态最简,root就不用和new A相连)。
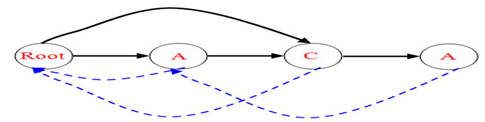
(4)插入D(情况1)
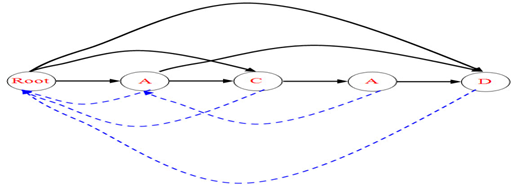
(5)插入D(情况2)
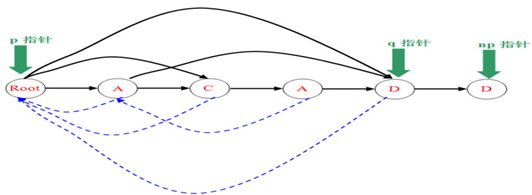
确定了是情况2,那么就要建立nq节点,图中可以很好的体现nq代替q的大部分功能(节点q的指针给nq,nq的fail改为p,q和np的fail改为nq)。
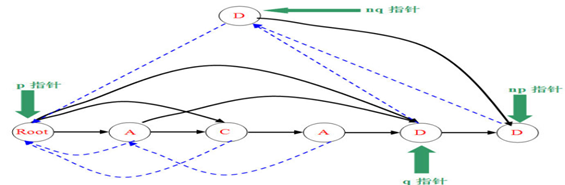
最后,从当前p开始根据fail边往上跳,边把问到的儿子为q的结点的儿子改为nq。(实际上就是保证性质2成立)
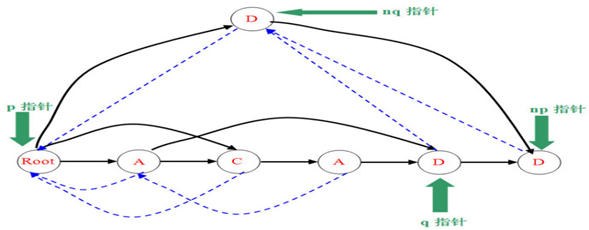
BINGO!~终于完成啦~~~
PS: 感谢大佬functioner%%%
学会了后缀自动机,开始做题吧:
这道模板题其实很简单,主要是利用了right集合的性质,很容易就可以想到一个子串right集合的大小其实就是出现的次数,dp求一下就ok啦。
【参考程序】
1 #include<iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<cstdlib> 5 #include<algorithm> 6 #include<cmath> 7 #define N 500005 8 #define ll long long 9 using namespace std; 10 char s[N]; 11 int root,cnt,last; 12 int a[N],Rsort[N],f[N],sa[N],fail[N],deep[N],r[N]; 13 struct SAM 14 { 15 int son[26]; 16 }ch[N]; 17 void add(int k) 18 { 19 int x=a[k]; 20 int p=last,np=++cnt;//上一个节点,新节点 21 deep[np]=k; 22 while(p>0 && ch[p].son[x]==0)ch[p].son[x]=np,p=fail[p]; 23 //不停往上跳p,如果我跳到的节点包含当前字符 停止 24 if(p==0)fail[np]=root;//如果我没有另一条返回的路径,那么就直接指向根 25 else 26 { 27 int q=ch[p].son[x];//q记录已选择的返回节点 28 if(deep[p]+1==deep[q])fail[np]=q;//如果q和p正好在一条路上(深度比q小1),直接指向它 29 else//否则...GG~~ (建一个万能的新节点) 30 { 31 int nq=++cnt;//新节点 32 deep[nq]=deep[p]+1;//这个新节点和p节点同一路径,深度+1 33 ch[nq]=ch[q];fail[nq]=fail[q];//替代q的功能 34 fail[np]=fail[q]=nq;//让新节点和可选择的节点都指向nq 35 while(ch[p].son[x]==q)ch[p].son[x]=nq,p=fail[p];//维护 让nq替代q大部分的功能 36 } 37 } 38 last=np; 39 } 40 int main() 41 { 42 scanf("%s",s+1); 43 last=root=++cnt; 44 int len=strlen(s+1); 45 for(int i=1;i<=len;i++)a[i]=s[i]-'a';//转化为数字,为什么??? 46 //答:“因为要放进数组啊!” 47 for(int i=1;i<=len;i++)add(i);//建立SAM 48 //将深度基排 49 for(int i=1;i<=cnt;i++)Rsort[deep[i]]++; 50 for(int i=1;i<=len;i++)Rsort[i]+=Rsort[i-1]; 51 for(int i=1;i<=cnt;i++)sa[Rsort[deep[i]]--]=i;//sa表示深度排名为i的位置 52 53 //处理right集合 54 for(int i=1,p=root;i<=len;i++)p=ch[p].son[a[i]],r[p]++;//从小到大按顺序处理子节点 55 for(int i=cnt;i;i--)r[fail[sa[i]]]+=r[sa[i]];//反过来更新父亲 56 57 //dp f[i]就是最终答案 58 memset(f,0,sizeof(f)); 59 for(int i=1;i<=cnt;i++)f[deep[i]]=max(f[deep[i]],r[i]); 60 //从小到大枚举所有的点,每个点的deep值代表一个字串长度,用right集合更新 61 for(int i=len;i;i--)f[i]=max(f[i+1],f[i]);//维护一下正确答案 62 63 for(int i=1;i<=len;i++)printf("%d\n",f[i]); 64 return 0; 65 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号