文件读写
A 读取文件
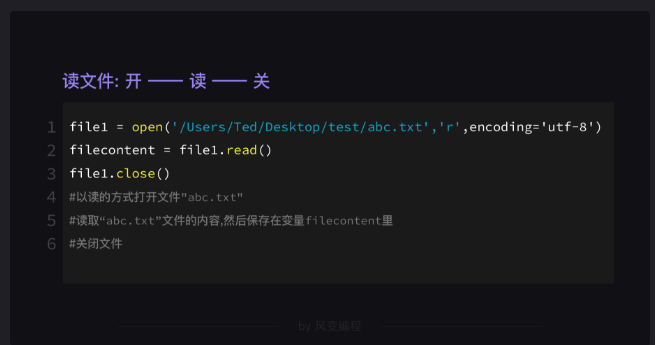
读文件三步:开——读——关。
file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8')
第一个参数是文件的保存地址
第二个参数表示打开文件时的模式(r(读),w(写入),a(追加))
第三个参数encoding='utf-8',表示的是返回的数据采用何种编码,一般采用utf-8或者gbk
——————————————————————————————
mac
open('/Users/Ted/Desktop/test/abc.txt'') #绝对路径
open('abc.txt') #相对路径
#相对路径也可以写成open('./abc.txt')
windows
Windows系统里,常用\来表示绝对路径, /来表示相对路径
C:\Users\Ted\Desktop\test\abc.txt #\在Python中是转义字符,Windows的绝对路径通常要稍作处理
写成以下两种格式
open('C:\\Users\\Ted\\Desktop\\test\\abc.txt')
#将'\'替换成'\\'
open(r'C:\Users\Ted\Desktop\test\abc.txt')
#在路径前加上字母
——————————————————————————————
获取文件路径方法
用VS Code打开文件夹,在文件点击右键
或者
将文件拖入终端窗口,获得文件的绝对路径
——————————————————————————————
B 写入文件
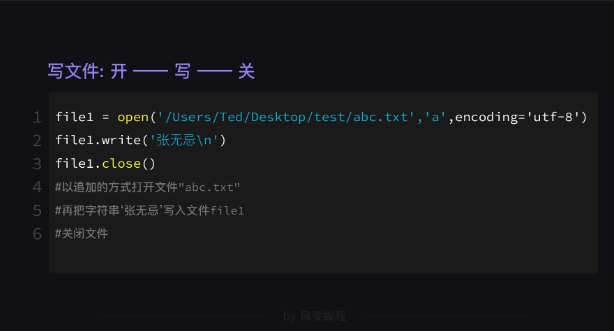
【第1步-开】以写入的模式打开文件。
file1 = open('/Users/Ted/Desktop/test/abc.txt','w',encoding='utf-8')
【第2步-写】往文件中写入内容,使用write()函数。
file1.write('张无忌\n')
#file1 = open('/Users/Ted/Desktop/test/abc.txt', 'a',encoding='utf-8')
#以追加的方式打开文件abc.txt
file1.write('张无忌\n')
#把字符串'张无忌'写入文件file1
【第3步-关】还是要记得关闭文件,使用close()函数
file1.close()
#注意事项:
1.write()函数写入文本文件的也是字符串类型。
2.在'w'和'a'模式下,如果你打开的文件不存在,那么open()函数会自动帮你创建一个
————————————————————————————————————————
为了避免打开文件后忘记关闭,占用资源或
当不能确定关闭文件的恰当时机的时候,我们可以用到关键字with
# 普通写法
1 file1 = open('abc.txt','a') 2 file1.write('张无忌') 3 file1.close()
# 使用with关键字的写法
1 with open('abc.txt','a') as file1: 2 #with open('文件地址','读写模式') as 变量名: 3 #格式:冒号不能丢 4 file1.write('张无忌') 5 #格式:对文件的操作要缩进 6 #格式:无需用close()关闭

—————————————————————————————————————————
scores.txt
罗恩 23 35 44
哈利 60 77 68 88 90
赫敏 97 99 89 91 95 90
马尔福 100 85 90
1 file = open('./scores.txt','r',encoding='utf-8') 2 file_lines = file.readlines() #函数readlines(),“按行读取” 3 file.close() 4 5 final_scores = [] 6 7 for i in file_lines: 8 data =i.split() #split()把字符串分开,把字符串切分成更细的一个个的字符串 9 sum = 0 10 for score in data[1:]: #遍历列表中第1个数据和之后的数据 11 sum = sum + int(score) #然后依次加起来,但分数是字符串,所以要转换 12 result = data[0]+str(sum)+'\n' #结果就是学生姓名和总分 13 final_scores.append(result) #每统计一个学生的总分,就把姓名和总分写入空列表 14 15 winner = open('./winner.txt','w',encoding='utf-8') 16 winner.writelines(final_scores) #writelines()函数,此处final_scores是一个列表,write()的参数必须是一个字符串,而writelines()可以是序列 17 winner.close()
——————————————————————
扩展
join()函数,字符串合并
语法:str.join(sequence)
str代表在这些字符串之中,你要用什么字符串连接
sequence代表数据序列
1 a=['c','a','t'] 2 b='' 3 print(b.join(a)) 4 c='-' 5 print(c.join(a))
6 cat 7 c-a-t
######################################################
# 下面注释掉的代码,皆为检验代码(验证每一步的思路和代码是否达到目标,可解除注释后运行)。
1 file1 = open('winner.txt','r',encoding='utf-8') 2 file_lines = file1.readlines() 3 file1.close() 4 5 dict_scores = {} 6 list_scores = [] 7 final_scores = [] 8 9 # print(file_lines) 10 # print(len('\n')) 11 12 # 打印结果为:['罗恩102\n', '哈利383\n', '赫敏570\n', '马尔福275\n'] 13 # 经过测试,发现'\n'的长度是1。所以,名字是“第0位-倒数第5位”,分数是“倒数第4位-倒数第二位”。 14 # 再根据“左取右不取”,可知:name-[:-4],score-[-4:-1] 15 16 for i in file_lines: # i是字符串。 17 print(i) 18 name = i[:-4] # 取出名字(注:字符串和列表一样,是通过偏移量来获取内部数据。) 19 score = int(i[-4:-1]) # 取出成绩 20 print(name) 21 print(score) 22 dict_scores[score] = name # 将名字和成绩对应存为字典的键值对(注意:这里的成绩是键) 23 list_scores.append(score) 24 25 # print(list_scores) 26 list_scores.sort(reverse=True) # reverse,逆行,所以这时列表降序排列,分数从高到低。 27 # print(list_scores) 28 29 for i in list_scores: 30 result = dict_scores[i] + str(i) + '\n' 31 # print(result) 32 final_scores.append(result) 33 34 print(final_scores) # 最终结果 35 36 winner_new = open('winner_new.txt','w',encoding='utf-8') 37 winner_new.writelines(final_scores) 38 winner_new.close()
锦瑟
[唐] 李商隐
锦瑟无端五十弦,
一弦一柱思华年。
庄生晓梦迷蝴蝶,
望帝春心托杜鹃。
沧海月明珠有泪,
蓝田日暖玉生烟。
此情可待成追忆,
只是当时已惘然。
1 list_test = ['一弦一柱思华年。\n','只是当时已惘然。\n'] # 将要默写的诗句放在列表里。 2 3 with open ('poem2.txt','r',encoding='utf-8') as f: 4 lines = f.readlines() 5 print(lines) #显示完整的诗 6 with open('poem2.txt','w',encoding='utf-8') as new: 7 for line in lines: 8 if line in list_test: # 属于默写列表中的句子,将其替换成横线。 9 new.write('____________。\n') 10 else: 11 new.write(line)
########################################################################
csv是一种文件格式,你可以把它理解成“简易版excel”
如果要手动新建csv文件,我们可以先新建一个excel表格,然后选择另存为“csv”格式即可
一张csv格式的表格,我们也可以选择另存为“excel”格式
用csv模块读写csv文件
英文教程:https://docs.python.org/3.6/library/csv.html
中文教程:https://yiyibooks.cn/xx/python_352/library/csv.html#module-csv
先看案例

##########################################################################
csv文件内容:
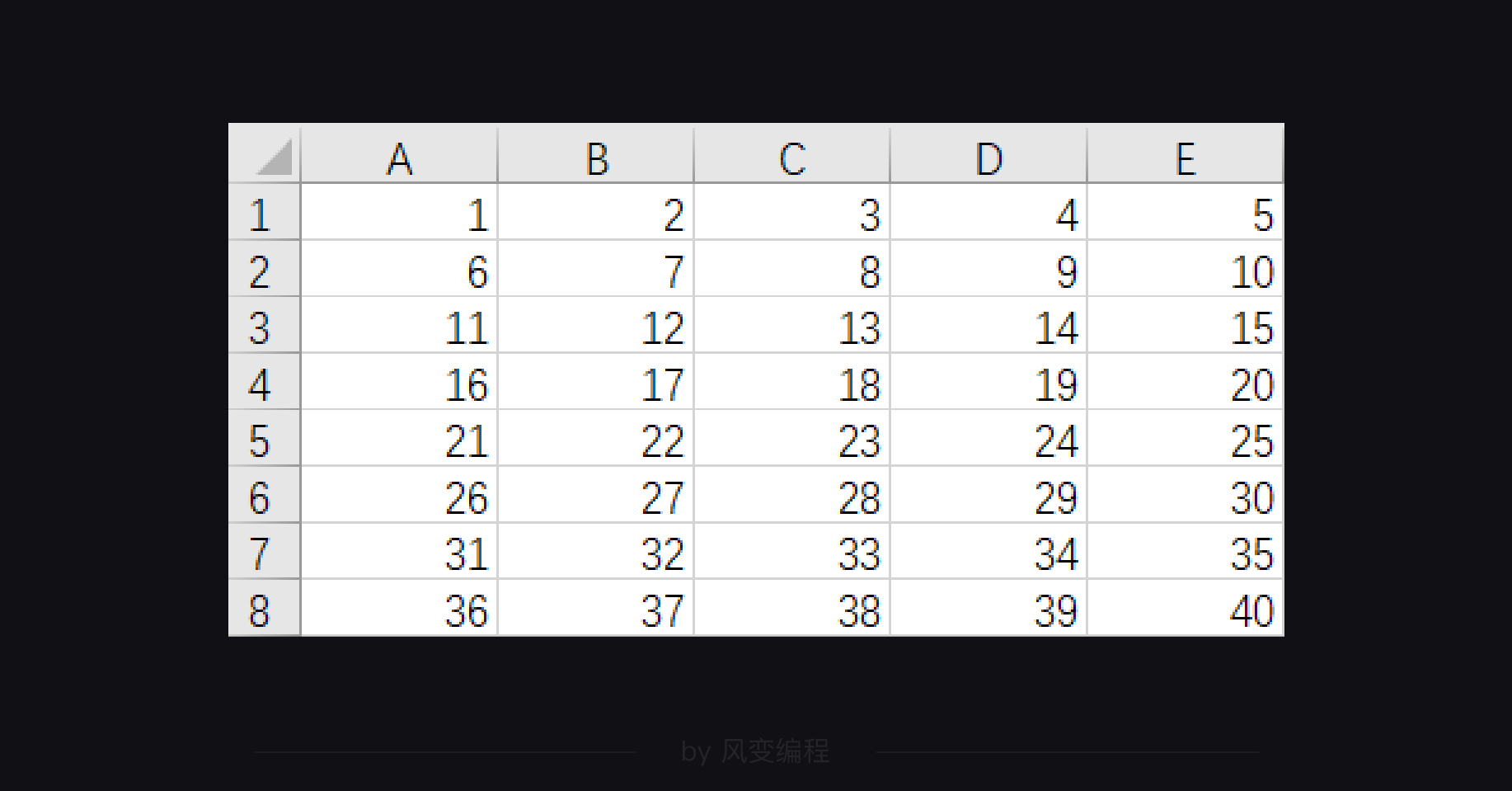
1 import csv
2
3 with open("test.csv",newline = '') as f:
4 reader = csv.reader(f)
5 #使用csv的reader()方法,创建一个reader对象
6 for row in reader:
7 #遍历reader对象的每一行
8 print(row)
#####################################################################
往csv格式文件写入数据
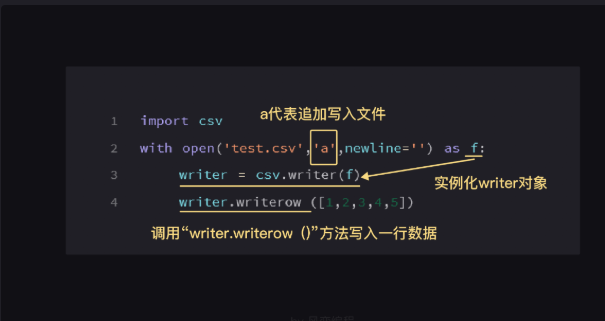
csv文件内容:
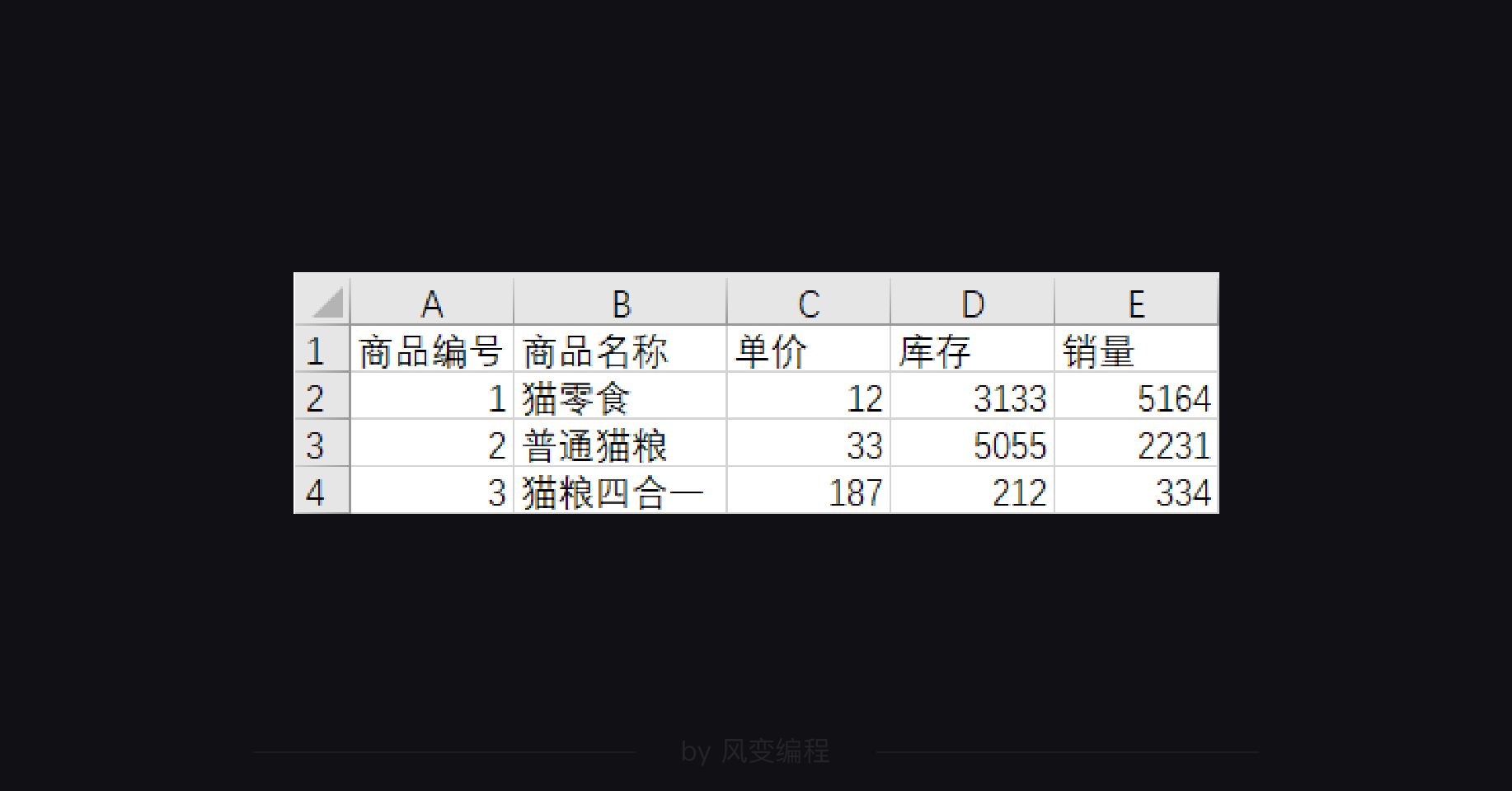
追加写入两行列表
1 import csv
2 with open('test.csv','a', newline='',encoding='utf-8') as f:
3 writer = csv.writer(f)
4 writer.writerow(['4', '猫砂', '25', '1022', '886'])
5 writer.writerow(['5', '猫罐头', '18', '2234', '3121'])
writerow()和writerows的区别
(1)writerow() 括号内的内容为列表;
(2)writerows() 括号内的内容为元组,且元组内的元素由两个以上的列表组成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号