开窗函数_ROW_NUMBER() / RANK() / DENSE_RANK() / NTILE() ------4个排名函数训练_1
排名函数(训练,其实从SQL2005时就已经被引入)
/*
SQL Server 2012从零开始学_7.8 排序函数
*/
--DROP TABLE fruits GO Create table fruits( s_id int, f_name char(20) ) insert into fruits(s_id,f_name) values('101','apple'), ('101','blackberry'), ('101','cherry'), ('102','orange'), ('102','banana'), ('102','grape'), ('103','coconut'), ('103','apricot'), ('104','berry'), ('104','lemon'), ('105','melon'), ('101','blackberry') select * from fruits
查询结果:
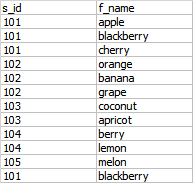
--ROW_NUMBER() --添加序号 select row_number() over (order by s_id asc) as rowid,s_id,f_name from fruits GO ----------------------------------------------------------- --RANK() 排序(对关联数据字段的值相同数据,则名次相同,隐形计算用了 sum(RankID)) SELECT rank() over (order by s_id asc) as RankID,S_ID,f_name FROM fruits; ----注意知识点,到第1个RankID=5时,ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt ----------------------------------------------------------- --DENSE_RANK() --排名,只是排名不跳顺序号(用递增号) SELECT DENSE_RANK() OVER(ORDER BY s_id) as DENSEID,s_id,f_name FROM fruits ----------------------------------------------------------- --NTILE() SELECT NTILE(5) OVER (ORDER BY s_id asc) as NTILEID,s_id,f_name FROM fruits ----------------------------------------------------------- SELECT NTILE(4) OVER (ORDER BY s_id ASC) AS NTILEID,s_id,f_name FROM fruits; ----------------------------------------------------------- --再将上面的组合到一起便于对比理解NTILE()
--函数是将有序分区中的行分发到指定个数的组中,各个组有编号,编号从1开始,类似'分区'一样 ,分为几个区,一个区会有多少个。
SELECT S_ID,f_name, row_number() over (order by s_id asc) as rowid, rank() over (order by s_id asc) as RankID, DENSE_RANK() OVER(ORDER BY s_id) as DENSEID,
NTILE(5) OVER (ORDER BY s_id asc) as NTILEID, NTILE(4) OVER (ORDER BY s_id asc) as NTILEID1, --分成4组,刚好能被12整除,每组3个,12条记录 = 4组 * 3条/组 NTILE(6) OVER (ORDER BY s_id asc) as NTILEID2, --分成6组,刚好能被12整除,每组2个,12条记录 = 6组 * 2条/组 NTILE(7) OVER (ORDER BY s_id asc) as NTILEID3 FROM fruits;
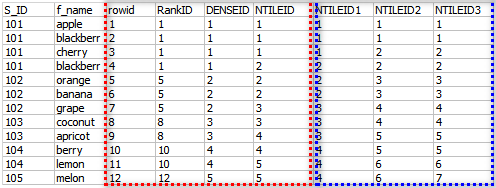
--红色虚线框中分别说明了函数的用法(将它们当做排序来理解,其次理解为排序后开窗):
ROW_NUMBER() ------>只是添加一个递增行序号
RANK() ------>排序(结合S_ID列来看),并列的名次(在S_ID不相同时,跳号)
DENSE_RANK() ------>排序(结合S_ID列来看),并列的名次(在S_ID不相同时,不跳号)
NTILE() ------>似乎理解,还不好讲解出来,但后面排序组要比前面的要小或相同
NTILEID1, NTILEID2, NTILEID3(只是试用了NTILE + ID作为了标题列头)
------------------------------------------------------------------------------------------------------------------------
下面是CTE、及窗口函数的示例
问题: 酒店每天要对在同一时间段内服务房间最多的一名服务生进行奖励。表 19-1 列出了一天中酒店服务生所服务的房间号和服务时间。
只要第 2 个房间的服务开始时间小于或等于第 1 个房间,并且结束时间大于第 1个房间的开始时间
AND W2.start_time <= W1.start_time
AND W2.end_time > W1.start_time
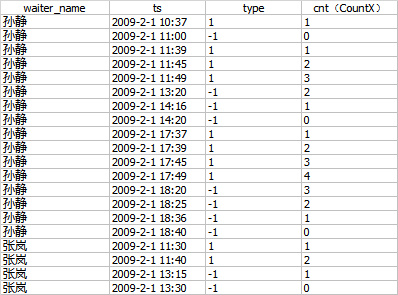
/* 学习本篇的目的: 窗口函数(学习前先来做这个例子) */ CREATE TABLE Waiters ( room_id int, waiter_name char(20), start_time datetime, end_time datetime ); INSERT INTO Waiters VALUES (1,'张岚','2009-02-01 11:30','2009-02-01 13:30'), (2,'张岚','2009-02-01 11:40','2009-02-01 13:15'), (3,'孙静','2009-02-01 11:45','2009-02-01 14:20'), (4,'孙静','2009-02-01 11:39','2009-02-01 13:20'), (5,'孙静','2009-02-01 11:49','2009-02-01 14:16'), (6,'孙静','2009-02-01 10:37','2009-02-01 11:00'), (3,'孙静','2009-02-01 17:45','2009-02-01 18:20'), (4,'孙静','2009-02-01 17:39','2009-02-01 18:25'), (5,'孙静','2009-02-01 17:49','2009-02-01 18:36'), (6,'孙静','2009-02-01 17:37','2009-02-01 18:40'); --------------------------------------------------------- select datediff(dd,'2020-05-21','2020-05-12') --------------------------------------------------------- SELECT MAX(room_id) FROM Waiters select COUNT(*) as tally FROM Waiters --------------------------------------------------------- SELECT * FROM Waiters --显示服务房间最多的数量 select --W1.waiter_name, --W1.start_time, --W1.end_time, MAX(W1.room_id) as room_id from Waiters as W1 group by w1.waiter_name order by w1.waiter_name --------------------------------------------------------- --显示了服务房间的最大数量 select w1.waiter_name, --w1.start_time, --w1.end_time, MAX(W1.room_id) as room_id from Waiters as w1 inner join Waiters as w2 on w1.waiter_name = w2.waiter_name group by w1.waiter_name order by w1.waiter_name --------------------------------------------------------- -------------------------------------------------------- --显示每个人的服务的房间号、开始时间、结束时间 SELECT * FROM Waiters select w1.waiter_name, w1.start_time, w1.end_time, MAX(W1.room_id) as room_id, COUNT(*) as tally from Waiters as w1 inner join Waiters as w2 on w1.waiter_name = w2.waiter_name and w2.start_time <= w1.end_time --->>>此处理解错误,应该是: and w2.start_time <= w1.start_time and w2.end_time > w1.start_time group by w1.waiter_name,w1.start_time,w1.end_time,w1.room_id order by w1.waiter_name,w1.start_time,room_id --------------------------------------------------------- -- SELECT W1.waiter_name, W1.start_time, W1.end_time, MAX(W1.room_id) AS room_id, COUNT(*) AS tally FROM Waiters AS W1 INNER JOIN Waiters AS W2 ON W1.waiter_name = W2.waiter_name AND W2.start_time <= W1.start_time AND W2.end_time > W1.start_time GROUP BY W1.waiter_name, W1.start_time, W1.end_time, W1.room_id ORDER BY W1.waiter_name, W1.start_time, room_id; --------------------------------------------------------- --得出同一时间服务房间数量最多的个数 select T1.waiter_name,MAX(T1.TALLY) as Tally FROM (SELECT W1.waiter_name, W1.start_time, W1.end_time, COUNT(*) AS tally FROM Waiters AS W1 INNER JOIN Waiters AS W2 ON W1.waiter_name = W2.waiter_name AND W2.start_time <= W1.start_time AND W2.end_time > W1.start_time GROUP BY W1.waiter_name, W1.start_time, W1.end_time) AS T1 GROUP BY T1.waiter_name; --------------------------------------------------------- with T1(waiter_name,start_time,end_time,tally) AS ( SELECT W1.waiter_name, W1.start_time, W1.end_time, COUNT(*) AS tally FROM Waiters AS W1 INNER JOIN Waiters AS W2 ON W1.waiter_name = W2.waiter_name AND W2.start_time <= W1.start_time AND W2.end_time > W1.start_time GROUP BY W1.waiter_name, W1.start_time, W1.end_time ) select waiter_name,MAX(tally) from T1 group by T1.waiter_name; --------------------------------------------------------- --使用CTE,这个是书本内容,自己独立写一次看看 WITH T1 (waiter_name, start_time, end_time, tally) -- 定义 CTE 表达式的名称和列 AS ( SELECT W1.waiter_name, W1.start_time, W1.end_time, COUNT(*) AS tally FROM Waiters AS W1 INNER JOIN Waiters AS W2 ON W1.waiter_name = W2.waiter_name AND W2.start_time <= W1.start_time AND W2.end_time > W1.start_time GROUP BY W1.waiter_name, W1.start_time, W1.end_time ) SELECT waiter_name, MAX(tally) AS tally FROM T1 GROUP BY T1.waiter_name; --------------------------------------------------------- --窗口函数使用前的预习 select waiter_name,start_time as ts from Waiters select waiter_name,start_time as ts,+1 as type --如果是开始时间,则 type设置 为 1 from Waiters select waiter_name,end_time as ts,-1 as type --如果是结束时间,则 type设置 为 -1 from Waiters select *, sum(type) over(partition by waiter_name order by ts,type) --------------------------------------------------------- -- WITH T1 AS ( SELECT waiter_name, start_time AS ts, +1 AS type FROM Waiters UNION ALL SELECT waiter_name, end_time, -1 AS type FROM Waiters ), T2 AS ( SELECT *, SUM(type) OVER(PARTITION BY waiter_name ORDER BY ts, type ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt FROM T1 ) SELECT * FROM T2 --------------------------------------------------------- --窗口函数使用 with T1 as ( select waiter_name,start_time as ts,+1 as type from Waiters Union all select waiter_name,end_time as ts,-1 as type from Waiters ), T2 as ( SELECT *, SUM(type) OVER(PARTITION BY waiter_name --sum(type),相当于在求和 ORDER BY ts, type ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt --此处cnt修改成另外一个别名便于理解: CountX FROM T1 ) select * from T2
运行结果:
![]()
---------------------------------------------------------
--最终完整的SQL WITH T1 AS ( SELECT waiter_name, start_time AS ts, 1 AS type FROM Waiters UNION ALL SELECT waiter_name, end_time, -1 AS type FROM Waiters ), T2 AS ( SELECT *, SUM(type) OVER(PARTITION BY waiter_name ORDER BY ts, type ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt FROM T1 ) SELECT waiter_name, MAX(cnt) AS tally FROM T2 GROUP BY waiter_name;
运行结果:
waiter_name tally
孙静 4
张岚 2
---------------------------------------------------------
--------------------------------------------------------- ---------------------------------------------------------
参考书目《SQL Server 2012从零开始学》7.8 排序函数
《锋利的SQL_第2版_张洪举_王晓文_著》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号