数论 (1)
2022 年博主重读文章,发现有事实错误,语言表达也略欠缺,请理性对待文章内容(所以本文是议论文) .
本文数学公式较多,请耐心等待 .
好了,正片开始 .
- −1−1 前言
- 00 带余除法
- 11 整除
- 22 同余
- 2.12.1 定义
- 2.22.2 性质
- 2.32.3 拓展
- 2.3.12.3.1 同余类、剩余系、简系与欧拉函数
- 2.3.22.3.2 同余方程(组)
- 2.3.2.12.3.2.1 定义
- 2.3.2.22.3.2.2 性质
- 2.3.2.32.3.2.3 算法
- 2.3.2.3.02.3.2.3.0 [前置] 拓展欧几里得算法 exgcd
- 2.3.2.3.02.3.2.3.0 [前置] 逆元/数论倒数
- 2.3.2.3.02.3.2.3.0 [前置] 阶
- 2.3.2.3.02.3.2.3.0 [前置] 原根
- 2.3.2.3.12.3.2.3.1 形如 ax≡b(modm)ax≡b(modm) 的线性同余方程
- 2.3.2.3.22.3.2.3.2 形如 ax≡b(modm)ax≡b(modm) 的同余方程
- 2.3.2.3.32.3.2.3.3 形如 xa≡b(modm)xa≡b(modm) 的高次同余方程
- 2.3.2.3.42.3.2.3.4 形如 {x≡a1(modm1)x≡a1(modm1)…x≡an(modmn)⎧⎪ ⎪ ⎪⎨⎪ ⎪ ⎪⎩x≡a1(modm1)x≡a1(modm1)…x≡an(modmn) 的线性同余方程组
- 33 数论函数
−1−1 前言
这里的例题大部分用的是洛谷上的。
00 带余除法
若 a,b∈Za,b∈Z,我们将满足 bq≤abq≤a 的最大的 qq 记做 aa 除以 bb 的商,实际上就是 ⌊ab⌋⌊ab⌋(⌊x⌋⌊x⌋ 指 xx 向下取整),重点来了,对于这个 qq,我们记 r=a−bqr=a−bq 为aa 除以 bb 的余数,一般记做 amodbamodb。
也就是我们小学学的:
11 整除
1.11.1 定义
若 a,b∈Za,b∈Z 且存在 q∈Zq∈Z 使得 b=aqb=aq,则称 aa 整除 bb,记做 a∣ba∣b。aa 不整除 bb 记做 a∤ba∤b
若 a,b∈Za,b∈Z 且 a∣ba∣b,则我们称 aa 是 bb 的约数/因数/因子,bb 是 aa 的倍数。
1.21.2 性质
-
a∣b,b∣c⇒a∣ca∣b,b∣c⇒a∣c(传递性)。
-
a∣b,a∣c⇔∀x,y∈Z,a∣bx+cya∣b,a∣c⇔∀x,y∈Z,a∣bx+cy(线性组合)。
-
一些比较显然的其他性质:
- d∣a⇒d∣kad∣a⇒d∣ka(k∈Zk∈Z)
- d∣a,d∣b⇔d∣a±bd∣a,d∣b⇔d∣a±b
- a∣b,b∣a⇔a=ba∣b,b∣a⇔a=b。
证明:
- 因 a∣ba∣b,则存在 q1∈Zq1∈Z 使得 aq1=baq1=b(定义),同理存在 q2q2 使得 bq2=cbq2=c,代入得 aq1q2=caq1q2=c,即得 a∣ca∣c。
- 先证引理
引理 1:a∣b⇒a∣bxa∣b⇒a∣bx
证明:由定义得存在 q∈Zq∈Z 使得 aq=baq=b,代入,a∣aqxa∣aqx,证毕。
引理 2:a∣b⇒∀x∈Z,a∣b+xaa∣b⇒∀x∈Z,a∣b+xa。
证明:由定义得存在 q∈Zq∈Z 使得 aq=baq=b,代入,∀x∈Z,a∣aq+xa⇒∀x∈Z,a∣a(q+x)∀x∈Z,a∣aq+xa⇒∀x∈Z,a∣a(q+x),证毕。
有了引理,命题就很显然了,先用1再用2就证出来了。
1.31.3 拓展
1.3.11.3.1 素数
1.3.1.11.3.1.1 定义
若一个正整数 qq 只有 11 和 qq 两个因子,则称 qq 为素数(Prime)。
1.3.1.21.3.1.2 分解质因数/分解素因子
算术基本定理(唯一分解定理):对于所有 a∈N+a∈N+,aa 均可被唯一的分解为 a=O∏i=1priia=O∏i=1prii,其中 pipi 均为素数,OO 称为 aa 的素因子个数,一般记为 ω(a)ω(a),但是 OI 一般不会用到(指 ω(a)ω(a))。
板子:洛谷 P2043。
1.3.1.31.3.1.3 算法
第一!朴素的 O(√n)O(√n) 判断素数:
bool Isprime(int n)
{
for (int i=2;i*i<=n;i++) // 因子是以 i,n/i 对称的,所以只需要枚举 [1,√n] 的数即可;并且注意 i=2 开始。
if (!(n%i)) return false; // !(n%i) == (n%i==0),这句话的意思就是如果 i 是 n 的因子。
return true; // 没有其他因子,那么就是素数喽
}
第二!埃氏筛
我们考虑维护一个数组 isprime,然后直接把所有素数的倍数都标记为 false,判断时就可以直接 isprime[n] 了。
我们只需要遍历即可遍历所有素数(我们将 isprime[n]=false 的不进行筛,因为整除性),证明:
数学归纳法,[2,2][2,2] 素数显然成立,如果目前把 [2,n][2,n] 的素数都筛完了,那么如果 isprime[n+1]=false 成立;否则,如果它不是素数,那么它一定有一个 [2,n−1][2,n−1] 之内的因子,但是如果它有这个因子早就被筛掉了,证毕。
gif 图片如下:
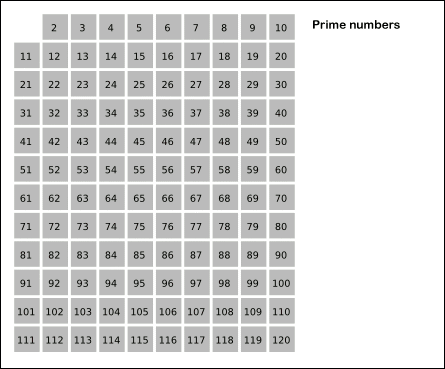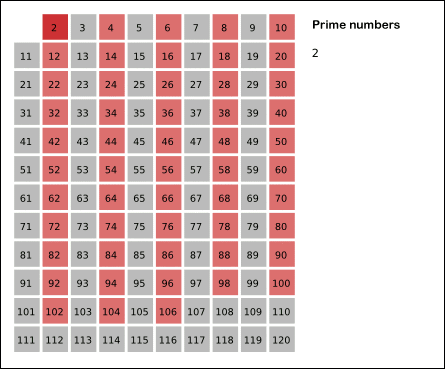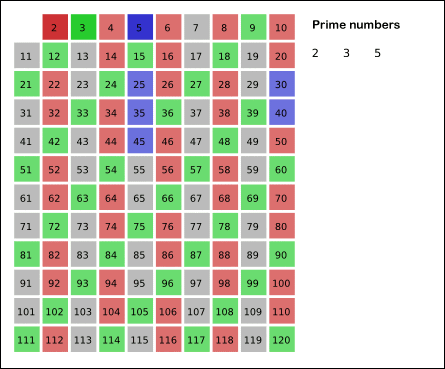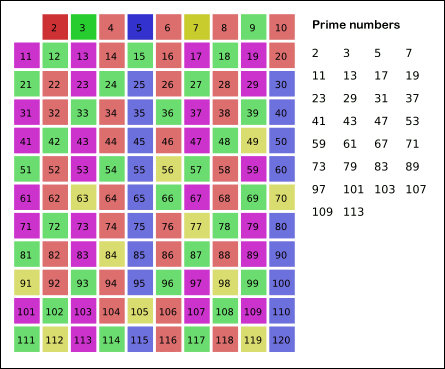
Code:
const int N=???;
bool isprime[N]; // 为了省去 memset,我们把 isprime[i]=false 当做其是素数。
int n; // 筛 1~n 素数
void GetPrime()
{
isprime[0]=isprime[1]=true;
for (int i=2;i*i<=n;i++) // 用 i*i 同上个算法。
{
if (isprime[i]) continue;
for (int j=i+i;j*j<=n;j+=i){isprime[j]=true;} // 筛
}
}
时间复杂度大约是 O(nloglogn)O(nloglogn)?因为 loglognloglogn 已经很接近 11 了,所以是近线性复杂度。
第三!真正线性的筛法!洛谷 P3383(模板)
这筛法还能顺便给个素数表。
核心:每个合数只被它最大的非自身的因数筛掉。
所以加上素数表,如果遇到素数直接 break; 即可。
const int N=???,M=???;
int prime[N],isprime[M],pi_; // pi_ 这个命名其实是表示 π(n) 函数
void GetPrime()
{
isprime[0]=isprime[1]=true;
for (int i=2;i<=n;i++)
{
if (!isprime[i]) prime[pi_++]=i;
for (int j=0;(j<pi_)&&(i*prime[j]<=N);j++) // j 用来枚举所有素数,我们都有素数表了就不用枚举了。
{
isprime[i*prime[j]]=1;
if (!(i%prime[j]))break; // Core!!!!!!!!!!!! 只筛一次!!!!!!!!!
}
}
}
MR 算法,仅供拓展。(判素用的,有点误差,但是复杂度接近 O(1)O(1)),SPOJ288 -- PON Prime or Not 模板
一想到 O(1)O(1),我们不妨试一下随机算法。
按理来讲,我们应该是在 [1,√n][1,√n] 里面随机,再通过某些方式来提高正确率的。但是这样做太慢 QAQ,我们要确保每一个在 [1,√n][1,√n]
中的数都不是 nn 的因子,显然用随机试的算法是行不通的。那么,我们该怎么办?
数论中,我们有 Fermat 小定理:
pp 是素数 ⇒xp≡p(modp)⇒xp≡p(modp),即 xp−1≡1(modp)xp−1≡1(modp)。
这个定理对于任何质数成立;但是反过来不一定。满足 Fermat 小定理的数不一定是质数。事实上,如果对任意b∈N,bp−1≡1(modp)b∈N,bp−1≡1(modp),我们就称 pp 为 Carmichael 数(伪 素 数)。运用 Fermat 小定理,我们可以判定一个数不是质数,但是不能判定一个数是质数(这个方法叫费马素性测试)。
不过,这给我们的随机枚举提供了一个不错的启示:不是随机枚举 nn 的因子,而是一个基底 bb。若对于不同的基底,都有bp−1≡1(modp)bp−1≡1(modp),pp 是质数的可能性就更大了。事实上,如果 pp 满足 bp−1≡1(modp)bp−1≡1(modp),那么 pp 就叫做"基于 bb 的伪素数"。
证明如下:

引入二次探测定理:
这个定理叫做“二次”是有原因的。其一,它是费马小定理探测质数的辅助工具,作为第二道屏障;其二,它和一个"二次同余方程"有关。定理如下:
若 x2≡1(modp)x2≡1(modp),则 x≡1(modp)x≡1(modp) 或 x≡p−1(modp)x≡p−1(modp)
这个定理比较好证明:

对于一个质数 pp,只要 pp 和二次探测定理不符,那么我们就可以肯定 pp 不是质数、事实上,我们常常直接用这个定理去判定质数,而不是用费马小定理。
无论是费马小定理还是二次探测定理,我们都需要选取若干个合适的基底来进行测试。一般而言,我们会选取这五个基底: 2,3,7,61,242512,3,7,61,24251。当需要测试的数据规模在 10161016 左右时,它的表现效果还是可以的。但当数据规模更大些时,你必须考虑将基底扩大一些。在这个基底的基础上,可以考虑选取前 10∼1510∼15大的质数,从而解决几乎 100%100% 的数据。
对于每一个基底 bb 和一个待判断的数 xx,我们进行如下测试:
- 用费马小定理判定一下这个数是不是合数。
- 如果 x−1x−1 是偶数,我们可以对费马小定理做如下变形:
bx−1≡1(modx)⇒bx−12×2≡1(modx)bx−1≡1(modx)⇒bx−12×2≡1(modx)
这样就可以用二次探测定理看一下有没有 bx−12≡1bx−12≡1 或 x−1(modx)x−1(modx) 了。如果都不满足, xx 就一定不是质数。
如果 x−12x−12 同样是一个偶数,我们可以继续将它拆成 x−14×2x−14×2,然后再用一次二次探测定理来做。
- 对于二次探测定理 Xk≡1(modx)Xk≡1(modx) ,如果 kk 是奇数或者 X≡x−1(modx)X≡x−1(modx),此时我们没有办法再拿这个数做文章了。我们只能暂时认定 xx 是质数。
注意到这就是 Miller Rabin 算法具有随机性的证据之二:对质数的判定不充分。但事实上,用上面这种方法已经可以成功地判定许多质数了,在实际应用中是值得信赖的。
上面这个算法的时间复杂度是O(log2n)O(log2n)的:瓶颈在于快速幂和分解待验证的数;但实际运行时,速度是相当快的。
显然,我们不难看出上述代码有大量需要优化的地方。就比如说,开始的那次费马小定理的判定是完全没有必要的。我们可以直接把这一过程留到二次探测定理去执行。
其次,我们使用二次探测定理时每次都要探测 lognlogn 次,这个次数是可以稍微有所优化的。
对于前者,我们直接删去开头的费马小定理判断就可以了。对于后者,网上广为流传这样一种优化技巧:
设 k=x−1=2p?dk=x−1=2p?d,dd 是一奇数,那么之前二次探测定理 X2≡1(modx)X2≡1(modx) 检测的数 XX 分别是如下几个数:b2p×d,b2p−1×d,b2p−2×d,…,bdb2p×d,b2p−1×d,b2p−2×d,…,bd。
如果我们从后往前检测,如果其中一个数 XX 通过了二次探测定理,就直接判定 xx 是质数。
这个新算法的流程如下:
- 按上面的方法计算出 dd 和 pp。记 cur=bdcur=bd,如果 cur≡1cur≡1 或 x−1(modx)x−1(modx)就直接判定 xx 是质数。
- 每次把 curcur 赋值为 cur2modxcur2modx直到 cur=bkcur=bk。这个过程等价与将 curcur 从 bdbd 往 bkbk 的方向扫描。
- 如果 cur=x−1cur=x−1 则直接判定 xx 为质数。否则转 22。
- 如果上述测试都没有判定 xx 为质数,则直接判定 xx为合数。
代码就不给了。
1.3.1.41.3.1.4 题目
因为因子对于 i,n/i 对称,再由于埃氏筛原理,应该每个数被按开关的次数就是 d(n)d(n),因为对称,所以显然大多数 d(n)d(n) 是偶数,也就是最后是关着灯的。
当然,如果有一个 i 使得 i=nii=ni,它就是开着的那个灯了。
我们可以发现,这种 nn 只有完全平方数且 i=√ni=√n。
Code:
#include<cstdio>
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int now=1,n;
cin>>n;
while (now*now<=n) cout<<now*now<<' ',now++;
return 0;
}
1.3.21.3.2 GCD & LCM
1.3.2.11.3.2.1 定义
若 a1,a2a1,a2 是两个不全为 00 的整数,若 d∣a1d∣a1 且 d∣a2d∣a2,我们则称 dd 为 a,ba,b 的公约数,我们将最大的 dd 称为 a1,a2a1,a2 的最大公约数(GCD),数学上一般记做 (a1,a2)(a1,a2),OI 里一般记做 gcd(a1,a2)gcd(a1,a2)。
若 gcd(a1,a2)=1gcd(a1,a2)=1,则称 a1,a2a1,a2 互素/互质(可以记做 a1⊥a2a1⊥a2)。
若 a1,a2a1,a2 是两个不全为 00 的整数,若 a1∣la1∣l 且 a2∣la2∣l,我们则称 ll 为 a,ba,b 的公倍数,我们将最小的 ll 称为 a1,a2a1,a2 的最小公倍数(LCM),数学上一般记做 [a1,a2][a1,a2],OI 里一般记做 lcm(a1,a2)lcm(a1,a2)。
在这篇文章中,GCD 与 LCM 记做 gcd(a,b)gcd(a,b) 与 lcm(a,b)lcm(a,b);而 (l,r)(l,r) 与 [l,r][l,r] 表示区间。
1.3.2.21.3.2.2 性质
- 定理:对于 a,b∈N+a,b∈N+ ,我们找出 a,ba,b 的质因数分解中相同的部分,然后算出它的值,就是 gcd(a,b)gcd(a,b) 啦。
如果你把 gcd(a,b)gcd(a,b) 只算一次,然后把 a,ba,b 剩余的部分也加上,就是 lcm(a,b)lcm(a,b) 喽。 - 显然,我们由
1得到了一个重要性质:gcd(a,b)lcm(a,b)=abgcd(a,b)lcm(a,b)=ab。 - 辗转相除:gcd(a,b)=gcd(b,amodb)gcd(a,b)=gcd(b,amodb)。
- 辗转相减(
其实叫「更相减损」的;和辗转相除同出一源):gcd(a,b)=gcd(b,a−b)gcd(a,b)=gcd(b,a−b)。
1.3.2.31.3.2.3 算法
计算 gcdgcd 与 lcmlcm:
// 辗转相除,O(log n) 的,用斐波那契数列的相邻两项能卡到 n^2。
int gcd(int a,int b){return b?gcd(b,a%b):a;} // 对于 b=0 辗转相除法是要特判的
int lcm(int a,int b){return a/gcd(a,b)*b;} // 套公式 gcd(a,b)*lcm(a,b)=a*b,改变了运算顺序防止爆掉 int
但是如果用高精的话([SDOI2009] SuperGCD)就用更相减损术,减法比取模算的快。
1.3.2.41.3.2.4 题目
随便推推式子可知要最大化答案必须得寻找一个最小的 k∈N+k∈N+ 且满足 k≥6k≥6 且 k∣nk∣n 然后用 nn 除一下。
直接分解质因数大力计算即可。
#include<iostream>
#include<algorithm>
#include<cstdio>
using namespace std;
const int N=1e7+5;
int t,n,m,h,s[N];
int main()
{
// freopen("input.in","r",stdin);
cin>>t;
while (t--)
{
bool q=false;
cin>>n; h=0;
for (int i=1;i*i<=n;i++) // 分解
if (!(n%i)){++h; s[h]=i; ++h; s[h]=n/i;}
sort(s+1,s+1+h);
for (int i=h;i>=1;i--)
{
if (n/s[i]>5){cout<<s[i]<<'\n';q=true;break;}
} if (!q) cout<<"-1\n";
} // 反着来的
return 0;
}
众所周知 sin 用短直角边和斜边除一下就行了,也就是最短边除一下最长边。
约分同时约 gcdgcd 即可,放到例题里真没什么必要。
#include<iostream>
#include<algorithm> // <algorithm> 里面有 __gcd 直接求 GCD,但是 NOIP 不能用。
#include<cstdio>
using namespace std;
int main()
{
int a,b,c;
cin>>a>>b>>c;
cout<<min(a,min(b,c))/__gcd(min(a,min(b,c)),max(a,max(b,c)))<<'/'<<max(a,max(b,c))/__gcd(min(a,min(b,c)),max(a,max(b,c)));
return 0;
}
众所周知 gcd(a,b)lcm(a,b)=abgcd(a,b)lcm(a,b)=ab,然后暴力即可。
#include<iostream>
using namespace std;
int gcd(int x,int y) {return y==0?x:gcd(y,x%y);}
int lcm(int x,int y) {return x*y/gcd(x,y);}
int main()
{
int x0,y0,s=0;
cin>>x0>>y0;
for (int p=1;p<=y0;p++)
for (int q=1;q<=y0;q++)
if (gcd(p,q)==x0&&lcm(q,p)==y0) s++;
cout<<s;
return 0;
}
取 ⌊nk⌋,2⌊nk⌋,3⌊nk⌋,…,k⌊nk⌋⌊nk⌋,2⌊nk⌋,3⌊nk⌋,…,k⌊nk⌋ 即可,显然这些数的 gcdgcd 是 ⌊nk⌋⌊nk⌋。
Code:
#include<iostream>
using namespace std; // n / k P r o b l e m
int main()
{
int n,k;
cin>>n>>k;
cout<<n/k;
return 0;
}
22 同余
2.12.1 定义
有 m∈N+m∈N+,a,b∈Za,b∈Z,若 m∣a−bm∣a−b,则称 aa 和 bb 模 mm 同余,记做 a≡b(modm)a≡b(modm)。
其实就是 amodm=bmodmamodm=bmodm 啦。
2.22.2 性质
- a≡b(modm)⇒a±k≡b±k(modm)⇒ak≡bk(modm)⇒ak≡bk(modm)a≡b(modm)⇒a±k≡b±k(modm)⇒ak≡bk(modm)⇒ak≡bk(modm)(k∈Zk∈Z 且对于上述公式有意义)
- a≡b(modm),c≡d(modm)⇒a±c≡b±d(modm)a≡b(modm),c≡d(modm)⇒a±c≡b±d(modm)
- 若 pp 为素数,则 ap≡a(modp)ap≡a(modp),当且仅当 a⊥pa⊥p 时,ap−1≡1(modp)ap−1≡1(modp)。
2.32.3 拓展
2.3.12.3.1 同余类、剩余系、简系与欧拉函数
2.3.1.12.3.1.1 定义
定义对于给定正整数 mm,Cr={x∈Z∣x≡r(modm)}Cr={x∈Z∣x≡r(modm)} 。我们称 C0…m−1C0…m−1 为模 mm 的 同余类/剩余类,显然 C0…m−1C0…m−1 构成 ZZ 的一个划分。
取 ai∈Ciai∈Ci,即可得到模 mm 的一个完全剩余系 aa,常用的是 1,2,…m−11,2,…m−1,我们称其为模 mm 的最小完全剩余系。
对于取的 ai⊥mai⊥m 的情况,aiai 称为模 mm 的一个简系。
欧拉函数 φ(n)φ(n) 是一个定义在正整数集上的函数,模 mm 的一个简系的元素个数称为 φ(n)φ(n),也可称作 1∼n1∼n 与 nn 互素的数的个数(也可写作 0∼n−10∼n−1 与 nn 互素的数的个数),可表示为 φ(n)=n∑i=1[i⊥n]φ(n)=n∑i=1[i⊥n]。
[x][x] 为条件符号,若 xx 为真则返回 11,否则返回 00,相当于 bool(x)。
2.3.1.22.3.1.2 性质
剩余系什么的没啥性质,主要是欧拉函数。
- 若 m,nm,n 互质,则 φ(nm)=φ(n)φ(m)φ(nm)=φ(n)φ(m)(积性函数)
- 若 nn 为奇数,则 φ(2n)=φ(n)φ(2n)=φ(n)。
- 通式:若 n=s∑i=1paiin=s∑i=1paii,则 φ(n)=ns∏i=1(1−1pi)φ(n)=ns∏i=1(1−1pi)。
- 欧拉定理:若 a,m∈N+a,m∈N+,a⊥ma⊥m,m≥2m≥2,则 aφ(m)≡1(modm)aφ(m)≡1(modm)
- 1∼n1∼n 与 nn 互素的数之和为 12nφ(n)12nφ(n)。
- 对于任意正整数 nn,∑d∣nφ(d)=n∑d∣nφ(d)=n。
2.3.1.32.3.1.3 算法
首先当然是普通求 φ(n)φ(n) 的算法:
// 第一种写法:暴力
// 时间复杂度:O(nlogn)
int phi(int n)
{
int ans=0;
for (int i=1;i<=n;i++) if (gcd(i,n)==1) ++ans; // gcd 这里没写
return ans;
}
// 第二种写法:套通式
// 时间复杂度:O(sqrt(n))
int phi(int n)
{
int ans=n;
for (int i=2;i*i<=n;i++) // 分解素因子
if(!(n%i))
{
ans=ans/i*(i-1);
while (!(n%i)) n/=i;
}
if (n>1) ans=ans/n*(n-1);
return ans;
}
线性筛欧拉函数(埃氏筛同理)。
根据欧拉函数和素因子的关系(通式),就仿照线性筛素数做就行。
const int N=???
int n,phi[N],prime[N],tot,ans;
bool isprime[N];
void getphi() // and prime???
{
phi[1]=1;
for (int i=2;i<=N;i++)
{
if (!isprime[i]){prime[++tot]=i; phi[i]=i-1;} // phi 一个素数答案显然是 n-1(2~n)
for (int j=1;j<=tot;j++)
{
if (i*prime[j]>N) break;
isprime[i*prime[j]]=1;
if (i%prime[j]) phi[i*prime[j]]=phi[i]*(prime[j]-1); // 这里用了欧拉函数的积性
else{phi[i*prime[j]]=phi[i]*prime[j]; break;}
}
}
}
2.3.1.42.3.1.4 题目
不难得出判定的写法是互质,然后随便推一下就会发现答案就是 2n−1∑i=0φ(i)+12n−1∑i=0φ(i)+1。
主要是套板子,代码就不给了。
2.3.22.3.2 同余方程(组)
2.3.2.12.3.2.1 定义
设整系数多项式 f(x)=n∑i=0aixif(x)=n∑i=0aixi,同余式 f(x)≡0(modm)f(x)≡0(modm) 称为模 mm 的同余方程,若整数 x0x0 满足 f(x0)≡0(modm)f(x0)≡0(modm),则称 x0x0 为同余方程的解。显然 x≡x0(modm)x≡x0(modm) 都是同余方程的解,我们把它看做同余方程的 同一个解。
2.3.2.22.3.2.2 性质
- f(x)≡0(modm)f(x)≡0(modm) 最多有 mm 个解(显然)
- 若 f(x),g(x)f(x),g(x) 都是整系数多项式,f(x)≡0(modm)⇔f(x)+ms(x)≡0(modm)⇔f(x)+s(x)≡s(x)(modm)f(x)≡0(modm)⇔f(x)+ms(x)≡0(modm)⇔f(x)+s(x)≡s(x)(modm)
- 若 a⊥ma⊥m,则 f(x)≡0(modm)⇔af(x)≡0(modm)f(x)≡0(modm)⇔af(x)≡0(modm)。
2.3.2.32.3.2.3 算法
2.3.2.3.02.3.2.3.0 [前置] 拓展欧几里得算法 exgcd
拓展欧几里得算法(exgcd),可以用来找到形如 ax+by=gcd(a,b)ax+by=gcd(a,b) 的方程的一组特解。
由裴蜀定理知,原方程一定有解。
我们利用辗转相除法(普通欧几里得算法)。
我们设 d=gcd(a,b)d=gcd(a,b)。
我们可以知道,我们辗转相除法的边界是 a=d,b=0a=d,b=0,此时我们可以知道 aa 就是最大公约数,我们还可以知道,在这时一定有一解为 x=1,y=0x=1,y=0,即 1×a+0×b=d1×a+0×b=d。
我们知道 gcd(a,b)=gcd(b,amodb)gcd(a,b)=gcd(b,amodb),如果我们可以推导出每一次的解 xx 和 yy,与相除后的解 x′x′ 和 y′y′ 的关系;我们就可以算出其中的一个解了,(xx 和 yy 相当于是 aa 和 bb 的解,x′x′ 和 y′y′ 是 aa 变成了 bb,bb 变成了 amodbamodb 时的解(辗转相除))。
轻易得知:
{ax+by=dbx′+(amodb)y′=d{ax+by=dbx′+(amodb)y′=d
则:
然后我们知道 xx 与 x′x′, yy 与 y′y′, 的关系后就可以求解了:
#include<iostream>
#include<cstdio>
using namespace std;
void exgcd(int a,int b,int& x,int& y) //x.y也可以用pair返回,这里用了引用
{
if (!b){x=1;y=0;return ;} //边界
gcd(b,a%b); //辗转相除
int tmp=y; y=x-(a/b)*y; x=tmp; //套公式
}
int main()
{
int a,b,x,y;
scanf("%d %d",&a,&b);
exgcd(a,b,x,y);
printf("%d %d",x,y);
return 0;
}
2.3.2.3.02.3.2.3.0 [前置] 逆元/数论倒数
1.定义
我们称满足 aa−1≡1(modm)aa−1≡1(modm) 的 a−1a−1 称为 aa 模 mm 意义下的逆元(也叫数论倒数)。
逆元是模意义下的除法。
2.算法
普通求逆元用 exgcd 求解即可:
#include<iostream>
#include<cstdio>
using namespace std;
void exgcd(int a,int b,int& x,int& y) //拓展欧几里得
{
if (!b){x=1;y=0;return ;}
exgcd(b,a%b);
int tmp=x; x=y; y=tmp-a/b*y;
}
int main()
{
int a,b,x,y;
scanf("%d %d",&a,&b);
exgcd(a,b,x,y);
printf("%d",(x+b)%b);
return 0;
}
素数的逆元:众所周知,费马小定理是:
若 pp 为素数,则 xp≡x(modp)xp≡x(modp)。
当且仅当 x∤px∤p 时:xp−1≡1(modp)xp−1≡1(modp)
然后我们用后面的式子同除以一个 xx,可以得到 x−1≡xp−2(modp)x−1≡xp−2(modp),所以我们只要求出 xp−2modpxp−2modp 就可以了,用快速幂求解即可。
Code:
#include<iostream>
#include<cstdio>
using namespace std;
typedef long long ll;
ll qpow(ll x,ll y,ll mod) //快速幂
{
ll ans=1,base=x;
while (y)
{
if (y&1) ans*=base;
base*=base;y>>=1;
}
return ans;
}
int main()
{
ll x,p;
scanf("%lld %lld",&x,&p);
printf("%lld",qpow(x,p-2,p));
return 0;
}
线性筛逆元
线性筛肯定是 O(n)O(n) 的嘛。
首先我们设 p=ki+rp=ki+r,然后可以知道 ki+r≡0(modp)ki+r≡0(modp)(因为 ki+r=pki+r=p,所以 pmodp=0pmodp=0)。
然后我们两边同乘 r−1i−1r−1i−1,就得到 kr−1+i−1≡0(modp)kr−1+i−1≡0(modp),移项得到 i−1≡−kr−1(modp)i−1≡−kr−1(modp)。
我们可以知道 k=⌊pi⌋,r=pmodik=⌊pi⌋,r=pmodi,所以我们得到公式:i−1≡−⌊pi⌋×pmodi−1(modp)i−1≡−⌊pi⌋×pmodi−1(modp)。
#include<iostream>
#include<cstdio>
using namespace std;
const int N=???;
typedef long long ll;
ll inv[N];
void GetInv(ll n,ll p)
{
for (int i=2;i<=n;i++)
inv[i]=(-(p/i)*inv[p%i]%p+p)%p;
}
线性筛阶乘逆元
也就是线性筛 n!−1n!−1。
我们设 inviinvi 表示 i!i! 的逆元,我们可以轻易知道 invi+1=(1i+1)!−1invi+1=(1i+1)!−1,我们同乘 i+1i+1 就变成了,invi+1(i+1)=(1i!)−1=inviinvi+1(i+1)=(1i!)−1=invi,所以我们可以得到:invi+1(i+1)=inviinvi+1(i+1)=invi。
所以我们先求出 n!n! 的逆元,再倒推回来即可。
#include<iostream>
#include<cstdio>
using namespace std;
const int N=???
typedef long long ll;
ll inv[N];
void GetFactInv()
{
inv[1]=inv[0]=1;
for (int i=1;i<=n;i++) //求阶乘
inv[i]=(inv[i-1]*i)%p;
inv[n]=GetInv(inv[n],p); //求n!的逆元
for (int i=n-1;i>=1;i--)//倒推
inv[i]=(inv[i+1]*(i+1))%p;
return 0;
}
2.3.2.3.02.3.2.3.0 [前置] 阶
定义:满足 ax≡1(modp)ax≡1(modp) 的最小正整数 xx 称作 aa 模 pp 的阶,写作 ⟨a⟩⟨a⟩(显然条件是 a⊥pa⊥p)。
性质:
- ⟨a⟩∣φ(p)⟨a⟩∣φ(p)
- a0,a1,a2,…,a⟨a⟩−1a0,a1,a2,…,a⟨a⟩−1 两两不同。
- ax≡ay(modp)ax≡ay(modp) 的充要条件是 x≡y(mod⟨a⟩)x≡y(mod⟨a⟩)。
2.3.2.3.02.3.2.3.0 [前置] 原根
定义:满足 gg 关于模 pp 的阶等于 φ(p)φ(p) 的 gg 是 pp 的一个原根。
性质:
- gr≡x(modp)gr≡x(modp) 的 rr 是唯一的,反之亦然(gg 是 pp 的原根),x<px<p,r<φ(p)r<φ(p)。
- 质数的原根个数是 φ(φ(p))φ(φ(p))。
- 一个模数存在原根的充要条件是,这个模数可以表示为1,2,4,p,2p,pn1,2,4,p,2p,pn其中 pp 是奇质数,nn 是任意正整数。
算法:考虑到最小的原根一般比较小,所以我们枚举原根然后判断。
假设我们当前枚举到 ii,判断的时候只需要枚举 φ(p)φ(p) 的质因子 p1…kp1…k。然后判断 iφ(p)pjiφ(p)pj 是不是全部都不是 11,如果全部都不是 11,ii 就是 pp 的一个原根。
2.3.2.3.12.3.2.3.1 形如 ax≡b(modm)ax≡b(modm) 的线性同余方程
定理:
a,b∈Za,b∈Z,一元一次同余方程 ax≡b(modm)ax≡b(modm) 有解的充要条件是 gcd(a,m)∣pgcd(a,m)∣p,其解数为 gcd(a,m)gcd(a,m)。
若 x0x0 为其一解,那么他的 gcd(a,m)gcd(a,m) 个解分别为 x≡x0+mgcd(a,m)×t(modm)x≡x0+mgcd(a,m)×t(modm),其中 t=0,1,…,gcd(a,m)−1t=0,1,…,gcd(a,m)−1。
读者自证不难(逃)。
有了后面这个关系就可以 exgcd 求所有解,比如 NOIp2012 提高组 洛谷 P1082 就是个 b=0b=0 的特殊情况。
2.3.2.3.22.3.2.3.2 形如 ax≡b(modm)ax≡b(modm) 的同余方程
当 a⊥ma⊥m 时,使用 BSGS(北上广深 百事公司 Baby Step Giant Step 大步小步)算法,复杂度 O(√p)O(√p):
设 x=pm−qx=pm−q,然后原式就成了 apm≡baq(modm)apm≡baq(modm),然后右边枚举 bb 再用 hash 存起来(用 map 也不错),左边枚举 aa 再一个个判即可。
// 核心代码
int m=sqrt(p)+1; Hash.Clear();
for (int i=0,t=z;i<m;++i,t=1ll*t*y%p) Hash.Insert(t,i);
for (int i=1,tt=fpow(y,m,p),t=tt;i<=m+1;++i,t=1ll*t*tt%p)
{
int k=Hash.Query(t);
if (k==-1) continue;
printf("%d\n",i*m-k);return ;
}
对于 a⊥̸ma⊥/m(???)时,使用 exBSGS 算法:
令 d=gcd(y,p)d=gcd(y,p),然后将方程改成等式 ax+kp=bax+kp=b,注意到 bb 必须是 dd 的倍数否则无解,所以除一下 dd 得 adax−1+kpd=bdadax−1+kpd=bd,然后无限迭代成 ykdyx−k≡bd(modpd)ykdyx−k≡bd(modpd),所以 BSGS 求一下在还原回去即可。
// 核心代码
void ex_BSGS(int y,int z,int p)
{
if (z==1){puts("0");return;}
int k=0,a=1;
while (19260817) // 变换
{
int d=__gcd(y,p);if(d==1)break;
if (z%d){NoAnswer(); return ;}
z/=d;p/=d;++k;a=1ll*a*y/d%p;
if (z==a){printf("%d\n",k); return ;}
}
Hash.clear();
int m=sqrt(p)+1; // BSGS
for (int i=0,t=z;i<m;++i,t=1ll*t*y%p) Hash.Insert(t,i);
for (int i=1,tt=fpow(y,m,p),t=1ll*a*tt%p;i<=m;++i,t=1ll*t*tt%p)
{
int B=Hash.Query(t);
if (B==-1) continue;
printf("%d\n",i*m-B+k); return ;
}
NoAnswer();
}
2.3.2.3.32.3.2.3.3 形如 xa≡b(modm)xa≡b(modm) 的高次同余方程
this,目前看不懂,等看懂了补上。
2.3.2.3.42.3.2.3.4 形如 {x≡a1(modm1)x≡a1(modm1)…x≡an(modmn)⎧⎪ ⎪ ⎪⎨⎪ ⎪ ⎪⎩x≡a1(modm1)x≡a1(modm1)…x≡an(modmn) 的线性同余方程组
33 数论函数
一般地,可把数论函数看做是整数集上定义的函数。
3.13.1 积性函数与完全积性函数
3.1.13.1.1 定义
若 ff 是一个数论函数,且对于任意 a⊥ba⊥b 均有 f(ab)=f(a)f(b)f(ab)=f(a)f(b),则称 ff 为积性函数。
若 ff 是一个数论函数,且对于任意 a,ba,b 均有 f(ab)=f(a)f(b)f(ab)=f(a)f(b),则称 ff 为完全积性函数。
3.1.23.1.2 性质
由唯一分解定理知,对于任意积性函数 ff 一定可以表示为 f(x)=ω(x)∏i=1paiif(x)=ω(x)∏i=1paii,其中 pa11pa22…pa11pa22… 是 xx 的标准分解(然后就可以直接转换递归做了)。
3.23.2 一些特殊数论函数
3.2.13.2.1 素数计数函数 π(n)π(n)
3.2.1.13.2.1.1 定义
素数计数函数 π(n)π(n) 为不超过 nn 的素数个数,即 π(n)=n∑i=1[i is a prime]π(n)=n∑i=1[i is a prime]。
3.2.23.2.2 单位函数 ϵ(n)ϵ(n)
3.2.2.13.2.2.1 定义
ϵ(n)=[n=1]ϵ(n)=[n=1],也就是 ϵ(n)={1n=10otherwise.ϵ(n)={1n=10otherwise.
显然,单位函数是完全积性函数。
3.2.33.2.3 除数函数 σk(n)σk(n)
3.2.3.13.2.3.1 定义
σk(n)σk(n) 就是 nn 的所有因子的 kk 次方和,即 σk(n)=∑d∣ndkσk(n)=∑d∣ndk。
特殊的,σ0(n)σ0(n) 为 nn 的因数个数,常记做 d(n)d(n);σ1(n)σ1(n) 为 nn 的因数和,常记做 σ(n)σ(n)。
除数函数是积性函数。
3.2.43.2.4 欧拉函数 φ(n)φ(n)
前面同余讲了
3.2.53.2.5 函数 I(n)I(n)、幂函数 Idk(n)Idk(n) 与莫比乌斯函数 μ(n)μ(n)
定义 II 为取值常为 11 的函数,定义幂函数 Idk(n)=nkIdk(n)=nk,对于 k=1k=1 时,Id1Id1 常记做 IdId。
莫比乌斯函数 μ(n)μ(n) 将在章节「3.43.4 莫比乌斯函数与莫比乌斯反演」处展开。
μ(n)μ(n) 是积性函数。
3.33.3 狄利克雷(Dirichlet)卷积
3.3.13.3.1 定义
若 f,gf,g 为数论函数,则我们称 ff 和 gg 的 Dirichlet 卷积 f∗g=∑ij=nf(i)g(j)=∑d∣nf(d)g(nd)f∗g=∑ij=nf(i)g(j)=∑d∣nf(d)g(nd),后面那个是一般用的表示形式。
3.3.23.3.2 性质
- 交换律:f∗g=g∗ff∗g=g∗f。
- 结合律:f∗g∗h=f∗(g∗h)f∗g∗h=f∗(g∗h)。
- 分配律:f∗h+g∗h=(f+g)∗hf∗h+g∗h=(f+g)∗h。
- 结合律 II:(xf)∗g=x(f∗g)(xf)∗g=x(f∗g)(xx 是一个系数)
- 单位元:ϵ∗f=fϵ∗f=f。
3.3.33.3.3 有趣的性质
- σk=1∗Idkσk=1∗Idk
- Id=φ∗1Id=φ∗1
- d=1∗1d=1∗1
- φ=μ∗Idφ=μ∗Id。
3.3.43.3.4 题目
给定 nn(1≤n≤2321≤n≤232),求 n∑i=1gcd(i,n)n∑i=1gcd(i,n)。
简单推式题:
3.43.4 莫比乌斯函数与莫比乌斯反演
3.4.13.4.1 莫比乌斯函数 μ(n)μ(n)
3.4.1.13.4.1.1 定义
莫比乌斯函数 μ(n)=∏p∈Prime(−1)[p∣n][p2∤n]μ(n)=∏p∈Prime(−1)[p∣n][p2∤n],但是主流的定义好像是 μ(n)={1n=1(−1)sn=s∏i=1pi(pi∈Prime)0otherwise.μ(n)=⎧⎪ ⎪ ⎪⎨⎪ ⎪ ⎪⎩1n=1(−1)sn=s∏i=1pi(pi∈Prime)0otherwise.
3.4.1.23.4.1.2 性质
-
μ(n)≠0μ(n)≠0 当且仅当 nn 无平方因子。
-
μμ 是积性函数(前面有)
-
μ∗1=ϵμ∗1=ϵ
3.4.1.33.4.1.3 算法
线性筛
void getMu() {
mu[1] = 1;
for (int i = 2; i <= n; ++i) {
if (!flg[i]) p[++tot] = i, mu[i] = -1;
for (int j = 1; j <= tot && i * p[j] <= n; ++j) {
flg[i * p[j]] = 1;
if (i % p[j] == 0) {
mu[i * p[j]] = 0;
break;
}
mu[i * p[j]] = -mu[i];
}
}
} //OI wiki
3.4.23.4.2 莫比乌斯反演
3.4.2.03.4.2.0 [前置] 数论分块
以下是博客签名,正文无关
本文来自博客园,作者:yspm,转载请注明原文链接:https://www.cnblogs.com/CDOI-24374/p/13378405.html
版权声明:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议(CC BY-NC-SA 4.0)进行许可。看完如果觉得有用请点个赞吧 QwQ


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】