浅谈Meet in the middle——MITM
目测观看人数
(简称 ),顾名思义就是在中间相遇。
可以理解为就是起点跑搜索树基本一半的状态,终点也跑搜索树基本一半的状态,最后撞到中间,一种类似双向 DFS 的东西。优化还是不错的awa,减少了差不多一半。
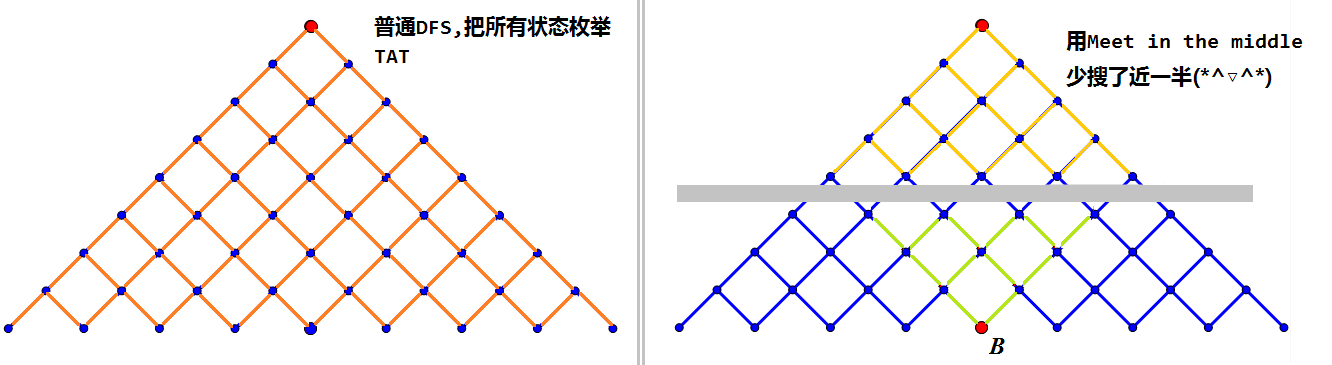
时间复杂度可如下分析:
设向外搜索 层需要的代价为 。如果不用 ,那么复杂度显然是 。
以下提供两种做法:
- 方法 :由 定义得,从起点搜索到一半的代价为 ,从终点搜索到一半的代价也为 ,总代价为 ,省略常数,得时间复杂度 。
- 方法 :设搜索树起点与终点为 连接 与搜索树左右边缘中点,再连接两个左右边缘中点,将搜索树分为四个面积相等区块, 仅搜索其中两个区块,得时间复杂度为 。
这种算法吧,对于 时,朴素算法为 , 为 ,优化了 复杂度。线性的优化,在数据大时效果明显。但是如果 ,那么朴素算法为 , 为 。
显然从一个节点出发进行搜索这题肯定会超时的
对于一个 位数,一共有 种可能的 操作(每一个数位都可以 ),一共有 种可能的交换操作,共 种操作。乘法原理得如果向外搜 层复杂度是 使用某 Windows 常用计算小工具得 假设计算机 运行 次操作还是不能 解决,显然 。
告诉起始点来个 双向就珂以了,,就算是 跑 的老爷机跑的差不多才 。
这题 可能会浪费点时间还是 好awa
注意用个 ,别 了
- 例题2
原题在 众所周知
有 个砝码,现在要称一个质量为 的物体,请问最少需要挑出几个砝码来称?
注意一个砝码最多只能挑一次。,,
看起来像是背包??(
-
解法 :暴!力!出!奇!迹!一发爆搜切!掉!!
记得优化awa- 用后缀和优化
- 用读优
- 如果当前使用的砝码数 当前最优解,(最优性剪枝);
- 深搜之前按从大到小排序(改变搜索顺序),(最优性剪枝) ,;
- 如果 ,换下一个砝码(可行性剪枝),注意不要 ;
然后就可以写出代码了:

-
解法 :用 ,如果后 发现有 的就更新答案,这个稳过,不用优化。
代码:

以下是博客签名,正文无关
本文来自博客园,作者:yspm,转载请注明原文链接:https://www.cnblogs.com/CDOI-24374/p/12741008.html
版权声明:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议(CC BY-NC-SA 4.0)进行许可。看完如果觉得有用请点个赞吧 QwQ


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】