
Redis 主从复制原理及雪崩 穿透问题
定义:
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。————摘自百度百科,下面街帅开始步入正题。
概述:
现在很多小作坊 游戏小公司基本上使用的是redis单机服务,这样在实际中单一的服务节点是容易出问题 面临风险的。比如容量瓶颈 机器故障 服务器线被耗子啃了,这样不就是凉凉了哦。
举例:
- 容量瓶颈:后期有需要要扩容Redis内存时,升级到64G 单机肯定满足不了,当然有钱的话当然你可以重新买个128G的新服务器。
- 机器故障:只部署到一台 Redis 服务器,当发生机器故障时,需要迁移数据到另外一台服务器并且要保证数据是同步的。而数据是最重要的,如果单机挂了那就洗白了。
- 并发:一般情况下 对处理大并发量应采用读写分离,读与写服务器数据同步等方式来做。此时如果是单结点Redis服务器那么想必效率不友好,背离了我们用redis的目的。
解决方案:
要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上。Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis的高可用,实现对数据的冗余备份,从而保证数据和服务的高可用性,提高产出效率。
 (示意图1)
(示意图1)
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制作用:
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,以至于程序不会挂掉,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 读写分离:可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库子Redis服务器的数量。
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式,也是对内存中重要数据备份的可行。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制启用:
从节点开启主从复制,有3种方式:
- 配置文件:在从服务器的配置文件中加入 ,.conf后缀的配置文件,具体什么忘了。
- 启动命令:redis-server启动命令后加入 。
- 客户端命令:Redis服务器启动后,直接通过客户端执行命令 ,则该Redis实例成为从节点。
主从复制原理:
主从复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段。
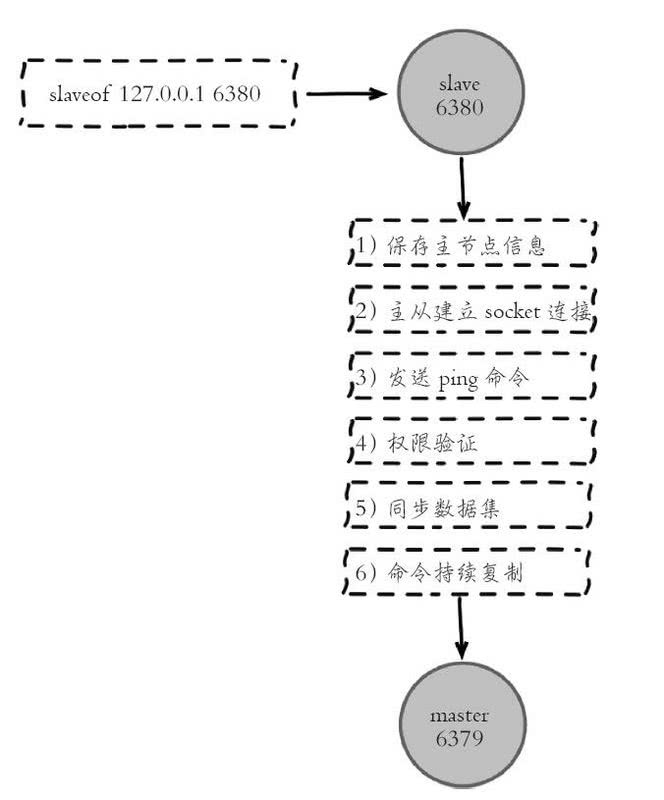
在从节点执行 命令后,复制过程便开始运作,下面图示可以看出复制过程大致分为6个过程。
 (示意图2)
(示意图2)
主从配置之后的日志记录也可以看出这个流程。
1.保存主节点(master)信息
执行 后 Redis 会打印如下日志:
2.从节点与主节点建立网络连接
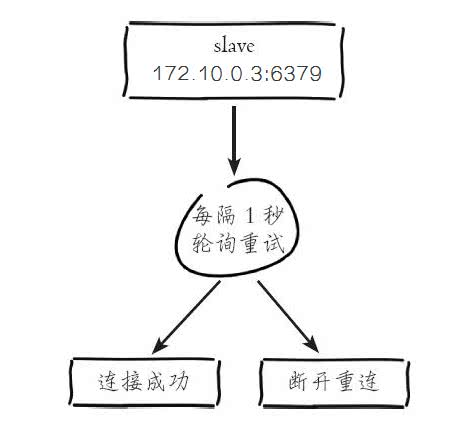
从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
从节点与主节点建立网络连接。
从节点会建立一个 套接字,从节点建立了一个端口为51234的套接字,专门用于接受主节点发送的复制命令。从节点连接成功后打印如下日志:
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行 取消复制。
关于连接失败,可以在从节点执行 查看 指标,它会记录与主节点连接失败的系统时间。从节点连接主节点失败时也会每秒打印如下日志,方便发现问题:
3.发送 ping 命令
连接建立成功后从节点发送 请求进行首次通信, 请求主要目的如下:
检测主从之间网络套接字是否可用。
检测主节点当前是否可接受处理命令。
如果发送 命令后,从节点没有收到主节点的 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连。
 (示意图3)
(示意图3)
从节点发送的 命令成功返回,Redis 打印如下日志,并继续后续复制流程:
4.权限验证
如果主节点设置了 参数,则需要密码验证,从节点必须配置 参数保证与主节点相同的密码才能通过验证。如果验证失败复制将终止,从节点重新发起复制流程。
5.同步数据集
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。
6.命令持续复制
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
雪崩、穿透、无底洞问题:
防雪崩的有效方法:
- 不设置过期时间(或者给缓存的过期时间加上随机值,避免集体失效),只要数据实时更新到redis,那么给用户的数据就是实时的,不影响后端数据库;
- 热数据和冷数据的区分,每天定时刷新热数据到redis中(定时任务 不建议);
- 设置redis集群和DB集群的高可用,如果redis出现宕机情况,可以立即由别的机器顶替上来。这样可以防止一部分的风险。【参考上面的主从复制】
防穿透的有效方法【缓存value为空;并发量很大去访问DB】:
- 由于在redis中找不到数据,所以会去数据库中读取,但是数据库也没有,就不会写回Redis里,导致并发访问时每次都去数据库读取,导致数据库压力过大;
- 可以给这类数据写一个null或false到redis,设置一个过期时间,比如2分钟;
- 要注意的是,这种key不能存储太长时间,key的量多起来,内存占用也会多的。
- 设置布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从避免了对底层存储系统的查询压力。【未具体研究】
无底洞问题的有效方法:
- key如果不过期,那么会一直保存在内存,内存会越来越不够用;
- key如果过期,那么过期后,怎么处理,高并发访问数据,数据库会不会挂掉?如果是分布式环境,可以用redis的setnx命令加锁方式来解决,获取到锁的就去db查询然后写回redis,而其他的请求没有获取到锁,则等待一段时间(比如10毫秒)然后再去redis读取,取到就返回,取不到数据的话可以根据业务看要不要直接返回空结果,还是再去获取锁,直到读取到数据或者尝试的次数到达指定次数。(说白了就是利用互斥锁。缓存失效的时候,得到了锁,再请求数据库。没得到锁,休眠一段时间再重试。)
感悟总结:
- Redis定位是非关系型数据库,不建议处理sql这样的关系型业务。
- Redis使用不当会造成内存的浪费,会造成阻塞等问题,虽然性能很好但还是谨慎一点。
- 应在适合的项目上用Redis,不能因为秀自己的技术而去用,适合业务即可。
- 勿在浮砂筑高塔。。。
~~~才转战博客园,几年没写了写的有点乱,请大佬们谅解,文章内容来自本街帅亲身体验加网络知识加本人体会 感悟。欢迎点赞评论~~~
附上几年前写的CSDN地址(有点low):https://blog.csdn.net/sz1103

 浙公网安备 33010602011771号
浙公网安备 33010602011771号