RepVGGBlock+GSConv+Bifpn+c2fca(模块融合)改进yolo5
参考论文:Exploring the Close-Range Detection of UAV-Based Images on Pine Wilt Disease by an Improved Deep Learning Method
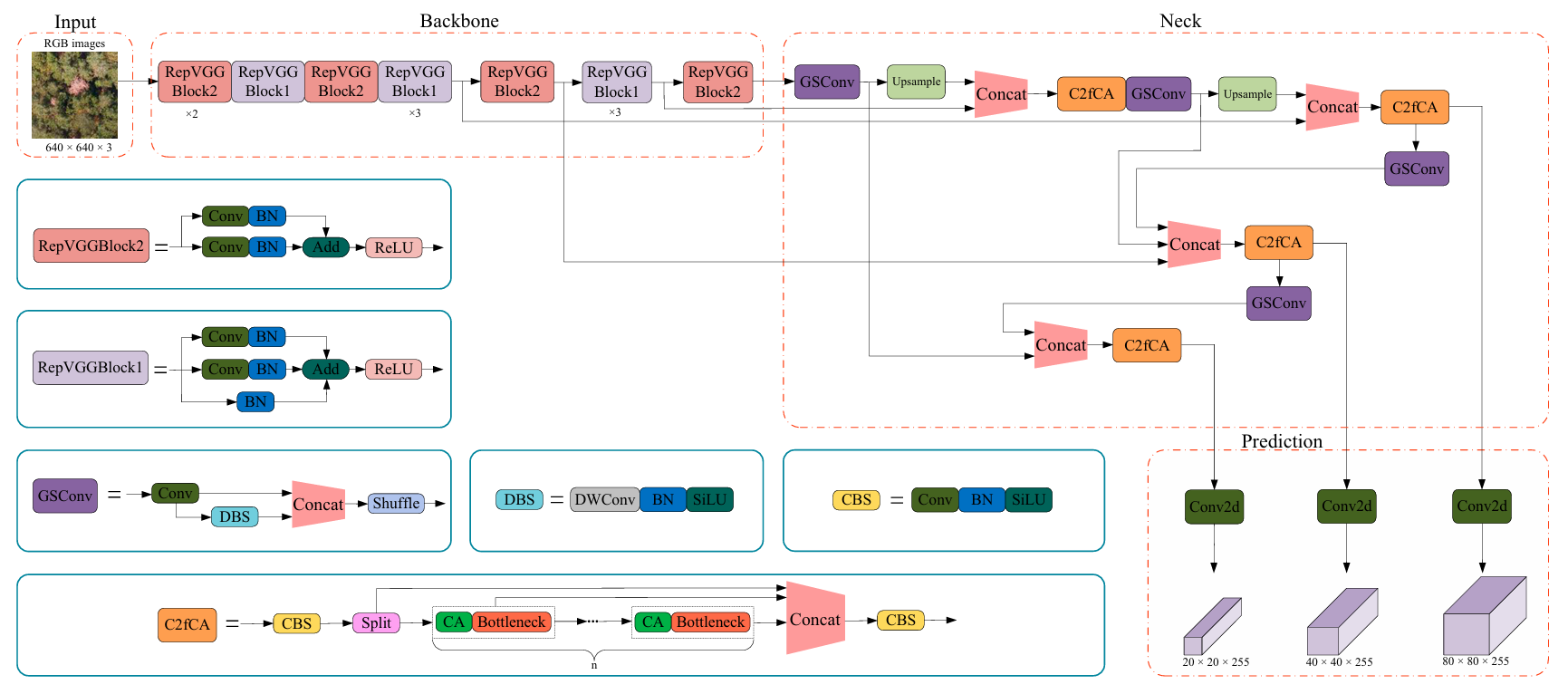
首先我们来介绍一下该文章使用的改进模块接着再来实现它
RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021) - 知乎 (zhihu.com)
YOLOv8独家改进:轻量级原创自研 | 一种多尺度的GSConv卷积变体,轻量化的同时能够实现涨点 | 新颖的轻量级网络-腾讯云开发者社区-腾讯云 (tencent.com)
特征融合(五):BiFPN-双向特征金字塔网络-CSDN博客
我们查看论文提出的repvggblock1和repvggblock2有什么区别:
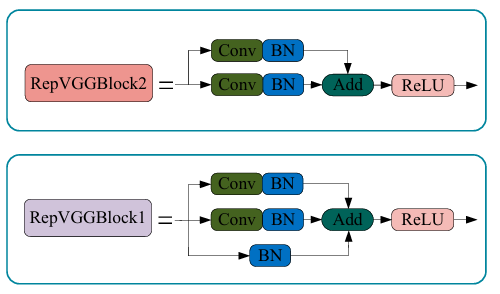
可以看到只是一个bn层的添加,但是在该论文的github上的开源文件里只有repvggblock1的模块结构,所以我们需要自己改动一下,把以下内容复制到models.commen(你也可以将原模块的BatchNorm2d替换为Identity)


def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1): result = nn.Sequential() result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False)) result.add_module('bn', nn.BatchNorm2d(num_features=out_channels)) return result def bn(in_channels, out_channels, kernel_size, stride, padding, groups=1): result = nn.Sequential() result.add_module('bn', nn.BatchNorm2d(num_features=out_channels)) return result class SEBlock(nn.Module): def __init__(self, input_channels, internal_neurons): super(SEBlock, self).__init__() self.down = nn.Conv2d(in_channels=input_channels, out_channels=internal_neurons, kernel_size=1, stride=1, bias=True) self.up = nn.Conv2d(in_channels=internal_neurons, out_channels=input_channels, kernel_size=1, stride=1, bias=True) self.input_channels = input_channels def forward(self, inputs): x = F.avg_pool2d(inputs, kernel_size=inputs.size(3)) x = self.down(x) x = F.relu(x) x = self.up(x) x = torch.sigmoid(x) x = x.view(-1, self.input_channels, 1, 1) return inputs * x class RepVGGBlock2(nn.Module): def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False): super(RepVGGBlock1, self).__init__() self.deploy = deploy self.groups = groups self.in_channels = in_channels assert kernel_size == 3 assert padding == 1 padding_11 = padding - kernel_size // 2 self.nonlinearity = nn.ReLU() if use_se: # Note that RepVGG-D2se uses SE before nonlinearity. But RepVGGplus models uses SE after nonlinearity. self.se = SEBlock(out_channels, internal_neurons=out_channels // 16) else: self.se = nn.Identity() if deploy: self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode) else: # self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None self.rbr_identity =nn.Identity() if out_channels == in_channels and stride == 1 else None self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups) self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups) # self.rbr_identity=None # self.rbr_bn= bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding, groups=groups) # print('RepVGG Block, identity = ', self.rbr_identity) def fusevggforward(self, x): # 将输入通过非线性操作和rbr_dense分支 return self.nonlinearity(self.rbr_dense(x)) def forward(self, inputs): if hasattr(self, 'rbr_reparam'): return self.nonlinearity(self.se(self.rbr_reparam(inputs))) if self.rbr_identity is None: id_out = 0 else: id_out = self.rbr_identity(inputs) # print(id_out) # print(id_out.shape) # print("input",inputs.size()) # print("rbr_1x1",(self.rbr_1x1(inputs)).shape) # print("rbr_dense1",(self.rbr_dense(inputs)).shape) # print("self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)",(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)).shape) # print("(self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)))",((self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))).shape)) return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)) # Optional. This may improve the accuracy and facilitates quantization in some cases. # 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight. # 2. Use like this. # loss = criterion(....) # for every RepVGGBlock blk: # loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2() # optimizer.zero_grad() # loss.backward() def get_custom_L2(self): K3 = self.rbr_dense.conv.weight K1 = self.rbr_1x1.conv.weight t3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach() t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach() l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2, 1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them. eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel. l2_loss_eq_kernel = (eq_kernel ** 2 / (t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2. return l2_loss_eq_kernel + l2_loss_circle # This func derives the equivalent kernel and bias in a DIFFERENTIABLE way. # You can get the equivalent kernel and bias at any time and do whatever you want, # for example, apply some penalties or constraints during training, just like you do to the other models. # May be useful for quantization or pruning. def get_equivalent_kernel_bias(self): kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense) kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1) kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity) return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid def _pad_1x1_to_3x3_tensor(self, kernel1x1): if kernel1x1 is None: return 0 else: return torch.nn.functional.pad(kernel1x1, [1,1,1,1]) def _fuse_bn_tensor(self, branch): if branch is None: return 0, 0 if isinstance(branch, nn.Sequential): kernel = branch.conv.weight running_mean = branch.bn.running_mean running_var = branch.bn.running_var gamma = branch.bn.weight beta = branch.bn.bias eps = branch.bn.eps else: assert isinstance(branch, nn.BatchNorm2d) if not hasattr(self, 'id_tensor'): input_dim = self.in_channels // self.groups kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32) for i in range(self.in_channels): kernel_value[i, i % input_dim, 1, 1] = 1 self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device) kernel = self.id_tensor running_mean = branch.running_mean running_var = branch.running_var gamma = branch.weight beta = branch.bias eps = branch.eps std = (running_var + eps).sqrt() t = (gamma / std).reshape(-1, 1, 1, 1) return kernel * t, beta - running_mean * gamma / std def switch_to_deploy(self): if hasattr(self, 'rbr_reparam'): return kernel, bias = self.get_equivalent_kernel_bias() self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels, kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride, padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True) self.rbr_reparam.weight.data = kernel self.rbr_reparam.bias.data = bias self.__delattr__('rbr_dense') self.__delattr__('rbr_1x1') if hasattr(self, 'rbr_identity'): self.__delattr__('rbr_identity') if hasattr(self, 'id_tensor'): self.__delattr__('id_tensor') self.deploy = True
下面是Gsconv(使用方式同repvggblock)
class GSConv(nn.Module): # GSConv https://github.com/AlanLi1997/slim-neck-by-gsconv def __init__(self, c1, c2, k=1, s=1, g=1, act=True): super().__init__() c_ = c2 // 2 self.cv1 = Conv(c1, c_, k, s, None, g, 1, act) self.cv2 = Conv(c_, c_, 5, 1, None, c_, 1, act) def forward(self, x): x1 = self.cv1(x) x2 = torch.cat((x1, self.cv2(x1)), 1) # shuffle # y = x2.reshape(x2.shape[0], 2, x2.shape[1] // 2, x2.shape[2], x2.shape[3]) # y = y.permute(0, 2, 1, 3, 4) # return y.reshape(y.shape[0], -1, y.shape[3], y.shape[4]) b, n, h, w = x2.data.size() b_n = b * n // 2 y = x2.reshape(b_n, 2, h * w) y = y.permute(1, 0, 2) y = y.reshape(2, -1, n // 2, h, w) return torch.cat((y[0], y[1]), 1)
Bifpn根据论文结构图,我们需要两种不同的bifpn(输入量的不同)(上同,但我们会看到后续操作有一点出入)
class BiFPN_Add2(nn.Module): def __init__(self, c1, c2): super(BiFPN_Add20, self).__init__() # 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter # 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter # 从而在参数优化的时候可以自动一起优化 self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True) self.epsilon = 0.0001 self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0) self.silu = nn.SiLU() def forward(self, x): w = self.w weight = w / (torch.sum(w, dim=0) + self.epsilon) return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1])) # 三个分支add操作 class BiFPN_Add3(nn.Module): def __init__(self, c1, c2): super(BiFPN_Add3, self).__init__() self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True) self.epsilon = 0.0001 self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0) self.silu = nn.SiLU() def forward(self, x): w = self.w weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化 # Fast normalized fusion return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
最后是c2fca模块,根据内容及代码我们可以发现它将c2f和ca模块结合了一下(也就是我们所说的缝模块)

class C2f(nn.Module): # CSP Bottleneck with 2 convolutions def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() self.c = int(c2 * e) # hidden channels self.cv1 = Conv(c1, 2 * self.c, 1, 1) self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2) self.m = nn.ModuleList(Bottleneck_C2f(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) def forward(self, x): y = list(self.cv1(x).split((self.c, self.c), 1)) y.extend(m(y[-1]) for m in self.m) return self.cv2(torch.cat(y, 1)) class CABottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=32): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 # self.ca=CoordAtt(c1,c2,ratio) self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) self.pool_w = nn.AdaptiveAvgPool2d((1, None)) mip = max(8, c1 // ratio) self.conv1 = nn.Conv2d(c1, mip, kernel_size=1, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(mip) self.act = h_swish() self.conv_h = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0) self.conv_w = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0) def forward(self, x): x1 = self.cv2(self.cv1(x)) n, c, h, w = x.size() # c*1*W x_h = self.pool_h(x1) # c*H*1 # C*1*h x_w = self.pool_w(x1).permute(0, 1, 3, 2) y = torch.cat([x_h, x_w], dim=2) # C*1*(h+w) y = self.conv1(y) y = self.bn1(y) y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2) x_w = x_w.permute(0, 1, 3, 2) a_h = self.conv_h(x_h).sigmoid() a_w = self.conv_w(x_w).sigmoid() out = x1 * a_w * a_h # out=self.ca(x1)*x1 return x + out if self.add else out class C2fCA(C2f): # C2f module with CABottleneck() def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): super().__init__(c1, c2, n, shortcut, g, e) c_ = int(c2 * e) # hidden channels self.m = nn.Sequential(*(CABottleneck(c_, c_,shortcut, g, e=1.0) for _ in range(n)))
接下来我们来到YOLO.py在大致28行处()中导入我们上面提到的模块,格式如下
from models.common import ( RepVGGBlock1,RepVGGBlock2,GSConv,C2fCA,BiFPN_Add2,BiFPN_Add3
在Class basemodel中添加以下函数
def fuse(self): print('Fusing layers... ') for m in self.model.modules(): if type(m) is RepVGGBlock2: if hasattr(m, 'rbr_1x1'): # 获取等效的卷积核和偏置 kernel, bias = m.get_equivalent_kernel_bias() # 创建一个新的卷积层,用等效的卷积核和偏置进行初始化 rbr_reparam = nn.Conv2d(in_channels=m.rbr_dense.conv.in_channels, out_channels=m.rbr_dense.conv.out_channels, kernel_size=m.rbr_dense.conv.kernel_size, stride=m.rbr_dense.conv.stride, padding=m.rbr_dense.conv.padding, dilation=m.rbr_dense.conv.dilation, groups=m.rbr_dense.conv.groups, bias=True) rbr_reparam.weight.data = kernel rbr_reparam.bias.data = bias # 分离模型的参数,以便后续修改 for para in self.parameters(): para.detach_() # 替换原来的rbr_dense层为新的rbr_reparam层 m.rbr_dense = rbr_reparam # 删除不再需要的属性 m.__delattr__('rbr_1x1') if hasattr(m, 'rbr_identity'): m.__delattr__('rbr_identity') if hasattr(m, 'id_tensor'): m.__delattr__('id_tensor') # 标记该模块为已部署 m.deploy = True # 删除SE模块 delattr(m, 'se') # 更新模块的前向传播函数 m.forward = m.fusevggforward if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'): # 融合Conv和BatchNorm层,更新Conv层 m.conv = fuse_conv_and_bn(m.conv, m.bn) # 删除BatchNorm层 delattr(m, 'bn') # 更新模块的前向传播函数 m.forward = m.forward_fuse # 打印融合后的模型信息 self.info() return self # --------------------------end repvgg & shuffle refuse-------------------------------- 在def parse_model里的if m in(......)中添加我们的bifpn和c2fca并做如下添加 if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x,Dense_C3,SCConv,C2fCA,C2f, VoVGSCSP, VoVGSCSPC}: args.insert(2, n) # number of repeats#将n插入到args的索引2位置 n = 1 elif m in [BiFPN_Add2, BiFPN_Add3]: c2 = max(ch[x] for x in f)
最最后我们就可以配置yaml文件运行了
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license # Parameters nc: 3 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.5 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [ [ -1, 2, RepVGGBlock2, [ 64, 3,2 ] ],#1,64,320,320 [ -1, 1, RepVGGBlock1, [ 128,3,2 ] ],#1,128,160,160 [ -1, 1, RepVGGBlock2, [ 128 ] ],#1,128,160,160 [ -1, 3, RepVGGBlock1, [ 256, 3,2 ] ], # 3-P3/8,80 [ -1, 1, RepVGGBlock2, [ 256,3,2 ] ],#,80 [ -1, 2, RepVGGBlock1, [ 256, 3 ] ], # 5-P4/16,40 [ -1, 1, RepVGGBlock2, [ 256,3 ] ],#6,40, [ -1, 1, RepVGGBlock1, [ 256, 3,2 ] ], # 7-P5/32,20 ] # YOLOv5 v6.0 head head: [[-1, 1, GSConv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, "nearest"]], [[-1, 6], 1, BiFPN_Add2, [128, 128]], # cat backbone P4[512, 512]:[-1, 6]的通道大小乘以width_multiple [-1, 1, C2fCA, [1, False]], # 13 [-1, 1, GSConv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, "nearest"]], [[-1, 3], 1, BiFPN_Add2,[ 128, 128]], # cat backbone P3 [-1, 1, C2fCA, [1, False]], # 17 (P3/8-small) [-1, 1, GSConv, [256, 3, 2]], [[4,-1,12], 1, BiFPN_Add3, [128, 128]], # cat P4 <--- BiFPN change [-1, 1, C2fCA, [1, False]], # 20 (P4/16-medium) [-1, 1, GSConv, [256, 3, 2]], [[-1, 8], 1, BiFPN_Add2, [128, 128]], # cat head P5 [-1, 1, C2fCA, [1, False]], # 23 (P5/32-large) [[15, 18, 20], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号